前言
現在神經網路的運用越來越流行了,即使在結構化資料領域神經網路也隨著資料量的增大而逐漸替代傳統機器學習方法,能夠創建一個基礎的深度神經網路解決問題對一個合格的演算法工程師來說變得越來越關鍵了,我就從一個初學者的角度出發,對我們常見的回歸問題運用神經網路對和集成學習大殺器XGBoost進行預測效果對比,
氣溫資料集下載地址:https://pan.baidu.com/s/1KNYfb2S7ct4KsIJxUFz2Uw
提取碼:DJNB
資料集探索
列印前11行資料:
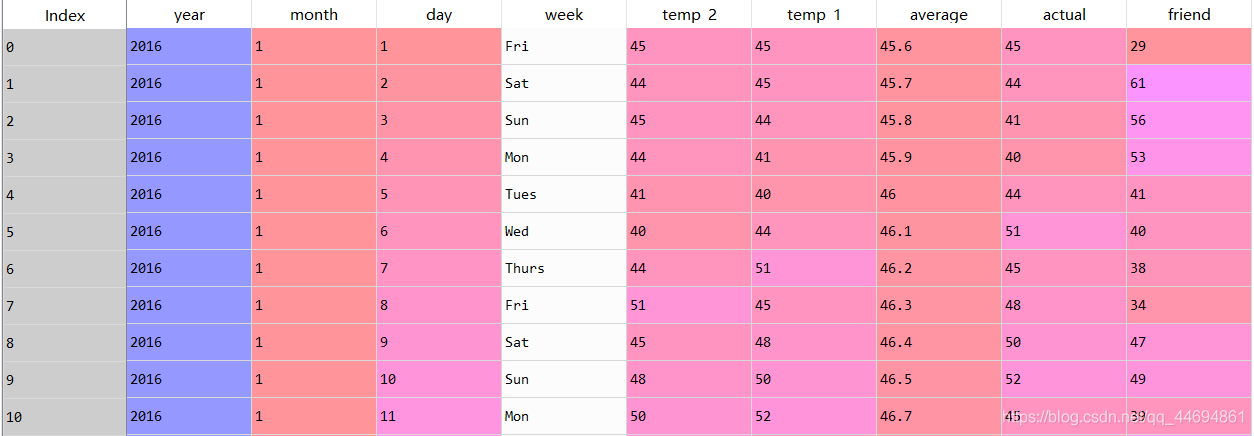
可以看到,氣溫資料集只有9個特征屬性(有year,month,day,week這樣的離散型資料,也有temp1,temp2,average,friend這樣的連續型資料),我們資料的label也就是我們需要預測的值就是actual列,屬于比較簡單的結構化資料,而且總共資料只有348條,非常小,適合新手練手,
資料預處理
這里資料預處理沒有做太多操作,因為資料集比較簡單,沒有缺失值,由于只有訓練集,所以資料的分布問題也不需要考慮,這里主要就需要對week列進行編碼,至于其他資料的標準化也可以做,這里我就沒進行標準化,
data=pd.read_csv("Temps.csv")
#獨熱編碼
data_onehot = pd.get_dummies(data['week'])
data = pd.concat([data,data_onehot],axis=1)
data=data.drop(['week'],axis=1)
#切分特征和標簽
train_x=data.drop(['actual'],axis=1)
target=data['actual']
構建模型預測
XGBoost模型
首先上我們的老大哥XGBoost,回歸問題對于xgboost來說輕而易舉,即使憑借簡單特征,也能擬合出很好的效果:
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import numpy as np
import itertools
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime
from sklearn.preprocessing import MinMaxScaler
import statsmodels.api as sm
import matplotlib.dates as dates
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import math
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
import time
import xgboost as xgb
from sklearn.model_selection import KFold, StratifiedKFold
#資料預處理
data=pd.read_csv("Temps.csv")
data_onehot = pd.get_dummies(data['week'])
data = pd.concat([data,data_onehot],axis=1)
data=data.drop(['week'],axis=1)
train_x=data.drop(['actual'],axis=1)
target=data['actual']
#xgb
model=xgb.XGBRegressor(max_depth=2
,learning_rate=0.01
,n_estimators=20000,
subsample=0.8)
oof1 = np.zeros(len(train_x))
answers = []
score = 0
n_fold = 5
num_epochs = 100
#五折交叉
folds = KFold(n_splits=n_fold, shuffle=True,random_state=2000) #2020 #1000
for fold_n, (train_index, valid_index) in enumerate(folds.split(train_x)):
X_train, X_valid = train_x.iloc[train_index], train_x.iloc[valid_index]
y_train, y_valid = target[train_index], target[valid_index]
model.fit(X_train,y_train,eval_set=[(X_valid, y_valid)],verbose=100,early_stopping_rounds=200)
y_pre = model.predict(X_valid)
oof1[valid_index]=y_pre.reshape(y_pre.shape[0])
print('RMSE-----------',
np.sqrt(mean_squared_error(data['actual'], oof1)))
#畫圖看看最終效果怎么樣
plt.figure(figsize=(50, 25))
plt.plot(range(len(oof1)), oof1, label='prediction', lineWidth=5)
plt.plot(range(len(target)), target, label='true', lineWidth=5)
plt.ylabel('co2')
plt.xlabel('date')
plt.legend()
plt.title("prediction and true")
plt.show()
在訓練集上面的預測效果與真實值對比(黃色是真實值,藍色是預測結果):
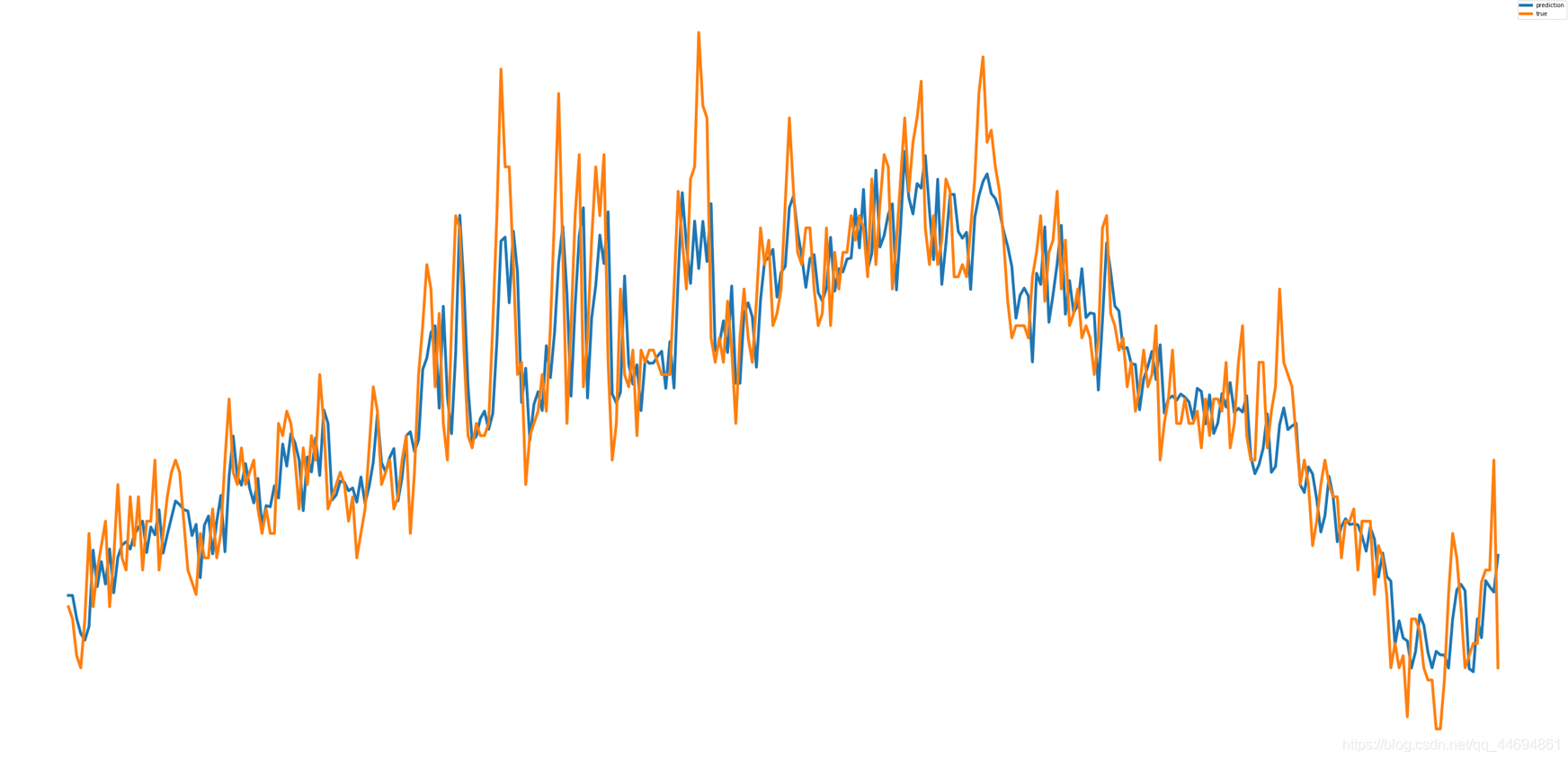
可以看到,效果還是不錯,想要更加精確可以做更加復雜的特征工程,不過由于訓練集資料非常少,容易發生過擬合,所以簡單點模型的泛化能力好點,
DNN模型
我做得非常簡單,網路結構只設定了三個全連接層,而且神經元數量也比較少,主要是做個示范,網路結構可自行設定,可以更加復雜化,
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import numpy as np
import itertools
from tensorflow import keras
from tensorflow.keras import layers
import pandas as pd
import matplotlib.pyplot as plt
from datetime import datetime
from sklearn.preprocessing import MinMaxScaler
import statsmodels.api as sm
import matplotlib.dates as dates
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import math
from keras.models import Sequential
from keras.layers import Dense, Activation
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
from keras import optimizers
import time
from sklearn.model_selection import KFold, StratifiedKFold
#資料預處理
data=pd.read_csv("Temps.csv")
data_onehot = pd.get_dummies(data['week'])
data = pd.concat([data,data_onehot],axis=1)
data=data.drop(['week'],axis=1)
train_x=data.drop(['actual'],axis=1)
target=data['actual']
#DNN構建得非常簡單,完全沒有技術含量,主要是舉個例子,可以自行增加各種層
model = Sequential()
model.add(layers.Dense(64, activation='relu',
input_shape=(train_x.shape[1],)))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer=keras.optimizers.Adam(0.01), loss='mse', metrics=['mse'])
#同樣采用五折交叉
oof1 = np.zeros(len(train_x))
answers = []
score = 0
n_fold = 5
num_epochs = 100
folds = KFold(n_splits=n_fold, shuffle=True,random_state=2000) #2020 #1000
for fold_n, (train_index, valid_index) in enumerate(folds.split(train_x)):
X_train, X_valid = train_x.iloc[train_index], train_x.iloc[valid_index]
y_train, y_valid = target[train_index], target[valid_index]
model.fit(X_train, y_train,epochs=num_epochs, batch_size=1, verbose=1)
y_pre = model.predict(X_valid)
oof1[valid_index]=y_pre.reshape(y_pre.shape[0])
print('RMSE-----------',
np.sqrt(mean_squared_error(data['actual'], oof1)))
plt.figure(figsize=(50, 25))
plt.plot(range(len(oof1)), oof1, label='prediction', lineWidth=5)
plt.plot(range(len(target)), target, label='true', lineWidth=5)
plt.legend()
plt.title("prediction and true")
plt.show()
神經網路預測結構和真實值對比效果(黃色是真實值,藍色是預測值):
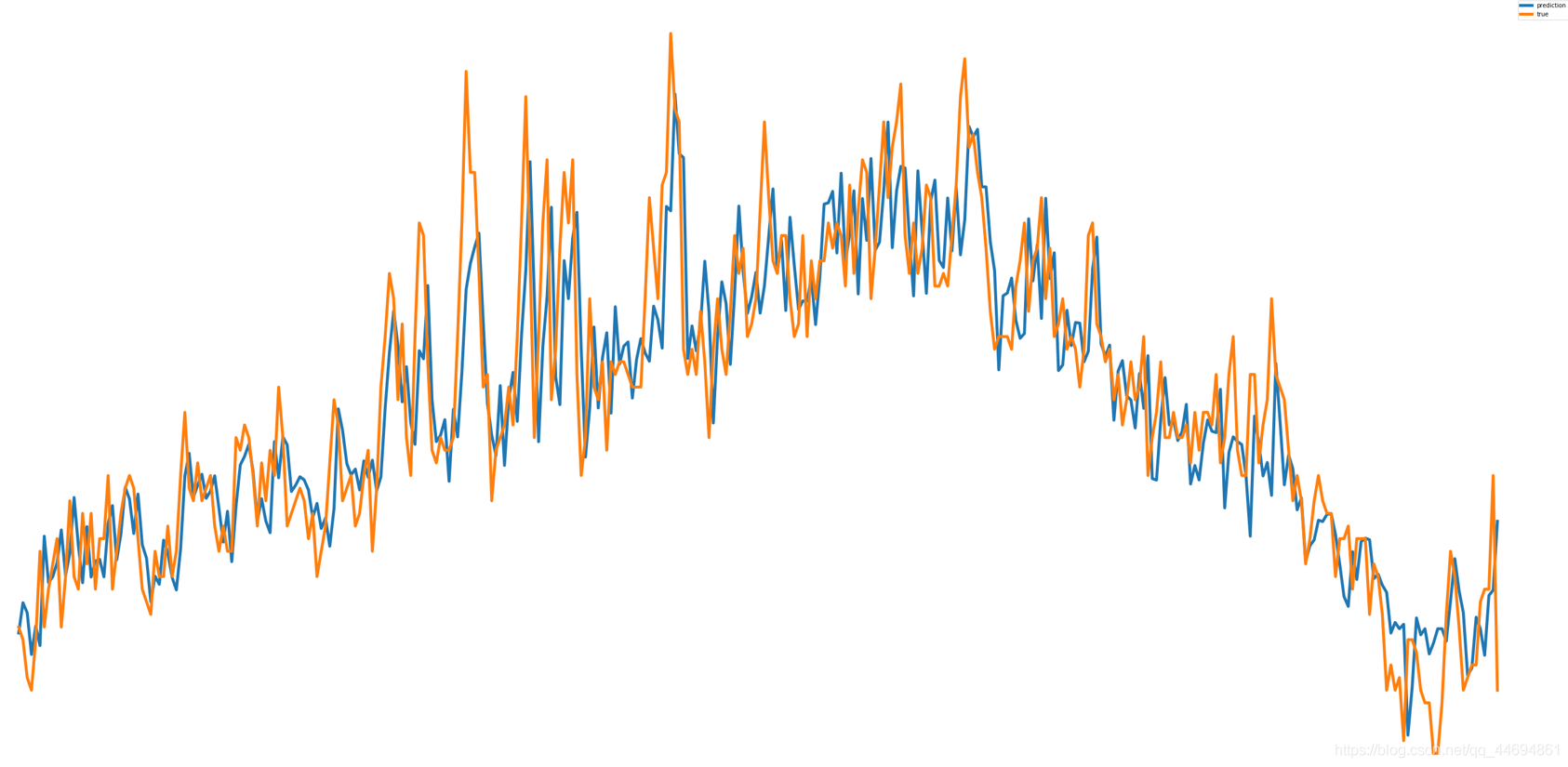
可以看到,一個簡單結構的神經網路的預測能力也還不錯,在峰值的預測上面好像比XGBoost還要稍微好一點點,而且大家還可以進行網路結構的復雜化,比如增加網路層數,比如添加卷積層,或者使用embedding操作進行資料關系映射,但是一定要防止神經網路模型的過擬合,由于神經網路的強大學習能力,它很容易學傻,所以要注意過擬合問題,
總結
神經網路非常強大,在這個資料集上面效果其實都還可以,但是它的優勢在這個資料集上面還體現不出來,神經網路的優勢在于能在大量資料里面比傳統機器學習更能找到資料之間微妙的關系,通過訓練大量的引數更能發現海量資料里面的潛在規律,本次資料集只有幾百條資料,優勢體現不明顯,而在實際工業生產中大量資料能讓神經網路模型的準確性和學習能力比機器學習方法更加出色!
寫在最后
本人才疏學淺,如果有理解錯誤或者理解不到位的地方請指正!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/295082.html
標籤:AI
上一篇:地平線機器人—ISP演算法崗位面試(2022秋招一面)
下一篇:【游戲開發寶藏】Unity學習路線,三萬字大綱,從基礎到大神(面試題大綱 | 知識圖譜 | Unity游戲開發工程師)