1.當我們完成了資料獲取,資料標注,資料清洗,模型訓練,模型評估,模型優化后,我們該做什么呢?當 然是模型上線.也就是說將模型部署,封裝打包,提供給最終要使用的用戶.
2.提到模型部署,現在有好幾種方式,eg:TF_Servering,flask_web,安卓,TensorRT等.我們要根據不同的場景和需求來選擇合適部署方式.
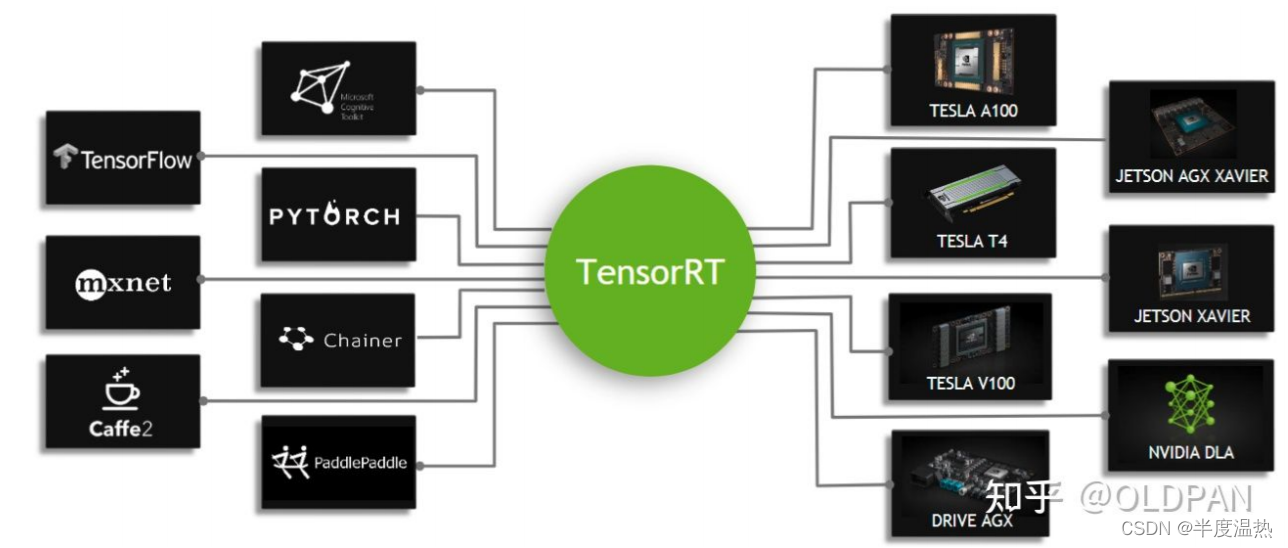
3.我比較熟悉的是TensorRT的部署.什么是tensorRT呢???它是NVIDIA(英偉達)針對自家平臺做的一個加速包.支持c++,python API介面.可以把pytorch,tensorflow或者其他框架訓練好的模型,轉換為TensorRT格式,然后利用它的推理引擎(engine檔案)去運行我們的這個模型,從而提升這個模型在NVIDIA GPU上的運行速度以及滿足特殊場景下實時性的需求.支持算力在5.0以及以上的顯卡設備.
4.場景(PC端(個人電腦),嵌入式端,服務端等...)
1)PC端:1080,2080,3080等顯卡.
2)嵌入式端: xavier NX,TX2,nano等.
3)服務器端: v100等.
5.tensorRT的加速手段
1)算子融合:通過融合一些計算操作來減少資料的流通次數,以及顯存的頻繁使用來提速.
2)量化:TensorRT支持INT8和FP16的計算.深度學習在網路訓練時一般默認采用16位的資料,trt
在網路推理時選用不那么高的精度,從而達到加速推斷的目的.
3)使用cuda steram多流技術,最大化實作并行操作.
6.CPU與GPU的區別,為何部署在GPU上?CPU主要是解釋計算機指令以及處理計算機軟體中的資料,相當于是一臺計算機的“大腦”,而GPU是一個專門的圖形核心處理器,是顯示卡的“大腦”,決定顯卡的檔次和大部分性能.

答案就在圖中!!!!!!!!!!!!!!!!!!!!
7.缺點:
1)經過優化后的模塊必須與特定的GPU系結.
2)TensorRT依賴CUDA,如果你想要更換更高版本的tensorrt,就必須更換CUDA,更換環境比較麻 煩 .
3)學習研究的資料較少.
8.準備開始研究在jetson 設備上分別以c++,python兩種API進行部署(yolov5).希望可以順利進行部署,然后做一個對比試驗,之后再給大家分享資料!
WOW!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/381900.html
標籤:AI
上一篇:服務器從0搭建-【anaconda3+cuda+cudnn+conda環境創建+修改conda源】
下一篇:改進的PID演算法