前言
到這里計算著色器的主線學習基本結束,剩下的就是再補充兩個有關影像處理方面的應用,這里面包含了龍書11的影像模糊,以及龍書12額外提到的Sobel算子進行邊緣檢測,主要內容源自于龍書12,專案原始碼也基于此進行調整,
學習目標:
- 熟悉影像處理常用的卷積
- 熟悉高斯模糊、Sobel算子
DirectX11 With Windows SDK完整目錄
Github專案原始碼
歡迎加入QQ群: 727623616 可以一起探討DX11,以及有什么問題也可以在這里匯報,
影像卷積
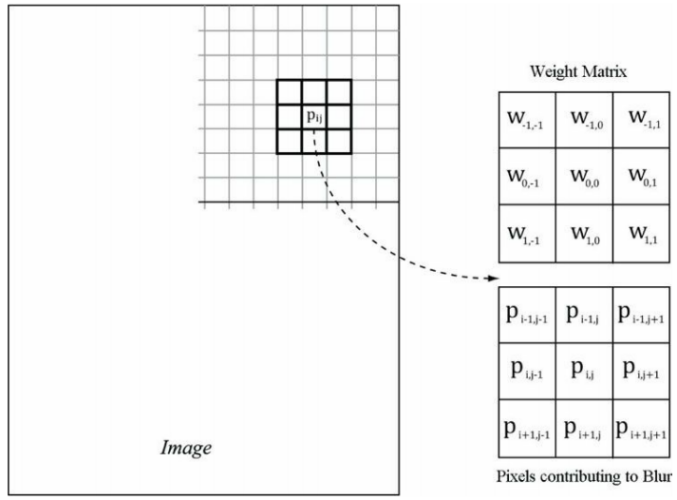
在影像處理中,經常需要用到卷積,很多效果都能夠通過卷積的形式來實作,針對源影像中的每一個像素\(P_{ij}\),計算以它為中心的m×n矩陣的加權值,此加權值便是經過處理后影像中第i行、第j列的顏色,如果寫成卷積的形式則為:
\[H_{ij}=\sum_{r=-a}^{a}\sum_{c=-b}^{b}W_{rc}P_{i-r,j-c} \]
其中,\(m=2a+1\)且\(n=2b+1\),將m與n強制為奇數,以此來保證m×n矩陣總是具有“中心”項,若a=b=r,則只需指定半徑r就可以確定矩陣的大小,\(W_{rc}\)為m×n矩陣(又稱內核、算子)中的權值,為了方便觀察計算及編碼,通常會將內核旋轉180°,這樣就得到了更加常用的計算公式:
\[H_{ij}=\sum_{r=-a}^{a}\sum_{c=-b}^{b}W_{rc}P_{i+r,j+c} \]
若內核的所有權值的和為1,則它可以用來做模糊處理;如果權值和大于0小于1,則處理后的影像會隨著顏色的缺失而變暗;如果權值和大于1,則處理后的影像會隨著顏色的增添而更加明亮,當然也會有權值和等于0甚至可能小于0的情況,比如索貝爾算子,
影像模糊
在保證權值和為1的前提下,我們就能用多種不同的方法來計算它,其中就有一種廣為人知的模糊運算:高斯模糊(Gaussian blur),該演算法借助高斯函式\(G(x)=exp(-\frac{x^2}{2\sigma^2})\)來獲取權值,下圖展示了取不同σ值時高斯函式的對應影像:
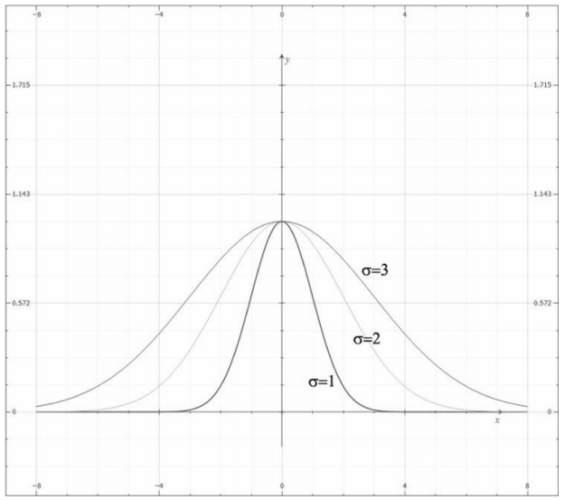
可以看到,若σ越大,則曲線越趨于平緩,給鄰近點所賦予的權值也就越大,
\[G(x)=exp(-\frac{x^2}{2\sigma^2})=e^{-\frac{x^2}{2\sigma^2}} \]
如果學過概率論的話應該知道它很像標準正態分布的概率密度,只不過缺了一個系數\(\frac{1}{\sqrt{2\pi}\;\sigma}\),
現在假設我們要進行規模為1×5的高斯模糊(即在水平方向進行1D模糊),且設σ=1,分別對x=-2,-1,0,1,2求G(x)的值,可以得到:
\[\begin{align}G(-2)&=exp(-\frac{(-2)^2}{2})=e^{-2} \\G(-1)&=exp(-\frac{(-1)^2}{2})=e^{-\frac{1}{2}} \\G(0)&=exp(0)=1 \\G(1)&=exp(-\frac{1^2}{2})=e^{-\frac{1}{2}} \\G(2)&=exp(-\frac{2^2}{2})=e^{-2}\end{align} \]
但是,這些資料還不是最終的權值,因為它們的和不為1:
\[\begin{align} \sum_{x=-2}^{x=2}G(x)&=G(-2)+G(-1)+G(0)+G(1)+G(2)\\ &=1+2e^{-\frac{1}{2}}+2e^{-2}\\ &\approx 2.48373 \end{align} \]
如果將前面5個值都除以它們的和進行規格化處理,那么我們便會基于高斯函式獲得總和為1的各個權值:
\[\begin{align} w_{-2}&=\frac{G(-2)}{\sum_{x=-2}^{x=2}G(x)}\approx 0.0545\\ w_{-1}&=\frac{G(-1)}{\sum_{x=-2}^{x=2}G(x)}\approx 0.2442\\ w_{0}&=\frac{G(0)}{\sum_{x=-2}^{x=2}G(x)}\approx 0.4026\\ w_{1}&=\frac{G(1)}{\sum_{x=-2}^{x=2}G(x)}\approx 0.2442\\ w_{2}&=\frac{G(2)}{\sum_{x=-2}^{x=2}G(x)}\approx 0.0545\\ \end{align} \]
對于二維的高斯函式,有
\[\begin{align} G(x, y) &= G(x)\cdot G(y) \\ &=exp(-\frac{x^2}{2\sigma^2})\cdot exp(-\frac{y^2}{2\sigma^2}) \\ &=e^{-\frac{x^2+y^2}{2\sigma^2}} \end{align} \]
假如我們要進行3x3的高斯模糊,且設σ=1,則未經過歸一化的內核為:
\[\begin{bmatrix} G(-1)G(-1) & G(-1)G(0) & G(-1)G(1) \\ G(0)G(-1) & G(0)G(0) & G(0)G(1) \\ G(1)G(-1) & G(1)G(0) & G(1)G(1) \\ \end{bmatrix} = \begin{bmatrix} G(-1) \\ G(0) \\ G(1) \\ \end{bmatrix}\begin{bmatrix} G(-1) & G(0) & G(1) \\ \end{bmatrix} \]
由于上面的內核矩陣可以寫成一個列向量乘以一個行向量的形式,因此在做模糊的時候可以將一個2D模糊程序分為兩個1D模糊程序,這也就說明該內核具有可分離性,
- 通過1D橫向模糊將輸入的影像I進行模糊處理:\(I_H=Blur_H(I)\)
- 對上一步輸出的結果再次進行1D縱向模糊處理:\(Blur(I)=Blur_V(I_H)\)
因此有:
\[Blur(I)=Blur_V(Blur_H(I)) \]
假如模糊核為一個9×9矩陣,我們就需要對總計81個樣本依次進行2D模糊運算,但通過將模糊程序分離為兩個1D模糊階段,便僅需要處理9+9=18個樣本!我們常常要對紋理進行模糊處理,而對紋理采樣是代價高昂的操作,因此,通過分離模糊程序來減少紋理采樣操作是一種受用戶歡迎的優化手段,盡管有些模糊方法不具備可分離性,但只要保證最終影像在視覺上足夠精準,我們往往還是能以優化性能為目的而簡化其模糊程序,
實作原理
首先,假設所運用的模糊演算法具有可分離性,據此將模糊操作分為兩個1D模糊運算:一個橫向模糊運算,一個縱向模糊運算,假定用戶提供了一個紋理A作為輸入(通常是作為SRV形參),以及一個紋理B作為輸出(通常是作為UAV形參),不過要考慮到有的用戶希望將直接修改紋理A,將紋理A的SRV和UAV都傳入,因此我們還是需要兩個存盤中間結果的紋理T0、T1,程序如下:
- 給紋理A系結SRV作為輸入,并且給紋理T0系結UAV作為輸出,
- 調度執行緒組進行橫向模糊操作,完成后,紋理T0存盤了橫向模糊的結果
- 解綁紋理T0的UAV,將它的SRV作為輸入,
- 若用戶指定了UAV,并且模糊次數為1,則將該UAV作為輸出;否則由于后續還需要進行混合,則將紋理T1的UAV作為輸出,
- 調度執行緒組進行縱向模糊操作,若當前為最后一次模糊,且用戶指定了UAV,則該UAV的紋理將保存最終的結果;否則T1保存了當前模糊的結果,解綁UAV后,若仍有剩余模糊次數,則將紋理T1系結SRV作為輸入,并給紋理T0系結UAV作為輸出,回到步驟2繼續;否則就再解綁SRV后結束,
由于渲染到紋理種的場景于視窗作業區要保持著相同的解析度,我們需要不時重新構建離屏紋理,而模糊演算法用的臨時紋理T也是如此,在GameApp::OnResize的時候重新調整即可,
假如要處理的影像寬度為w、寬度為h,對于1D縱向模糊而言,一個執行緒組用256個執行緒來處理水平方向上的線段,而且每個執行緒又負責影像中一個像素的模糊操作,因此,為了影像中的每個像素都能得到模糊處理,我們需要在x方向上調度\(ceil(\frac{w}{256})\)個執行緒組(ceil為上取整函式),且在y方向上調度h個執行緒組,如果w不能被256整除,則最后一次調度的執行緒組會存有多余的執行緒(見下圖),我們對于這種情況無能為力,因為執行緒組的大小固定,因此,我們只得把注意力放在著色器代碼中越界問題的鉗位檢測(clamping check)上,
1D縱向模糊于上述1D橫向模糊的情況相似,在縱向模糊程序中,執行緒組就像由256個執行緒構成的垂直線段,每個執行緒只負責影像中一個像素的模糊運算,因此,為了使影像中的每個像素都能得到模糊處理,我們需要在y方向上調度\(ceil(\frac{h}{256})\)個執行緒組,并在x方向上調度w個執行緒組,
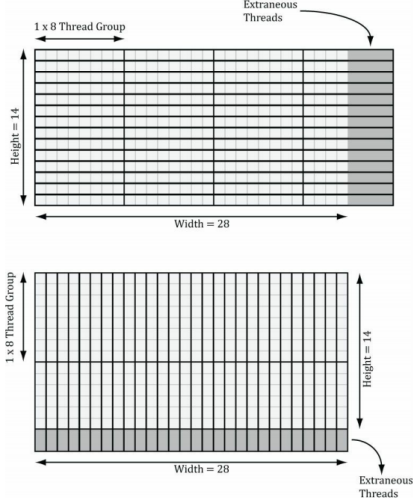
現在來考慮對一個28x14像素的紋理進行處理,我們所用的橫向、縱向執行緒組的規模分別為8x1和1x8(采用X×Y的表示格式),對于水平方向的處理程序來說,為了處理所有的像素,我們需要在x方向上調度\(ceil(\frac{w}{8})=ceil(\frac{28}{8})=4\)個執行緒組,并在y方向上調度14個線程組,由于28并不能被8整除,所以最右側的執行緒組中會有\((4\times 8-28)\times 14=56\)個執行緒宣告都不做,對于垂直方向的處理程序而言,為了處理所有的像素,我們需要在y方向上分派\(ceil(\frac{h}{8})=ceil(\frac{14}{8})=2\)個執行緒組,并在x方向上調度28個執行緒組,同理,由于14并不能被8整除,所以最下側的執行緒組中會有\((2\times 8 - 14)\times 28\)個閑置的執行緒,沿用同一思路就可以將執行緒組擴展為256個執行緒的規模來處理更大的紋理,
BlurFilter::Execute不僅計算出了每個方向要調度的執行緒組數量,還開啟了計算著色器的模糊運算:
void BlurFilter::Execute(ID3D11DeviceContext* deviceContext, ID3D11ShaderResourceView* inputTex, ID3D11UnorderedAccessView* outputTex, UINT blurTimes)
{
if (!deviceContext || !inputTex || !blurTimes)
return;
// 設定常量緩沖區
D3D11_MAPPED_SUBRESOURCE mappedData;
deviceContext->Map(m_pConstantBuffer.Get(), 0, D3D11_MAP_WRITE_DISCARD, 0, &mappedData);
memcpy_s(mappedData.pData, sizeof m_CBSettings, &m_CBSettings, sizeof m_CBSettings);
deviceContext->Unmap(m_pConstantBuffer.Get(), 0);
deviceContext->CSSetConstantBuffers(0, 1, m_pConstantBuffer.GetAddressOf());
ID3D11UnorderedAccessView* nullUAV[1] = { nullptr };
ID3D11ShaderResourceView* nullSRV[1] = { nullptr };
// 第一次模糊
// 橫向模糊
deviceContext->CSSetShader(m_pBlurHorzCS.Get(), nullptr, 0);
deviceContext->CSSetShaderResources(0, 1, &inputTex);
deviceContext->CSSetUnorderedAccessViews(0, 1, m_pTempUAV0.GetAddressOf(), nullptr);
deviceContext->Dispatch((UINT)ceilf(m_Width / 256.0f), m_Height, 1);
deviceContext->CSSetUnorderedAccessViews(0, 1, nullUAV, nullptr);
// 縱向模糊
deviceContext->CSSetShader(m_pBlurVertCS.Get(), nullptr, 0);
deviceContext->CSSetShaderResources(0, 1, m_pTempSRV0.GetAddressOf());
if (blurTimes == 1 && outputTex)
deviceContext->CSSetUnorderedAccessViews(0, 1, &outputTex, nullptr);
else
deviceContext->CSSetUnorderedAccessViews(0, 1, m_pTempUAV1.GetAddressOf(), nullptr);
deviceContext->Dispatch(m_Width, (UINT)ceilf(m_Height / 256.0f), 1);
deviceContext->CSSetUnorderedAccessViews(0, 1, nullUAV, nullptr);
// 剩余模糊次數
while (--blurTimes)
{
// 橫向模糊
deviceContext->CSSetShader(m_pBlurHorzCS.Get(), nullptr, 0);
deviceContext->CSSetShaderResources(0, 1, m_pTempSRV1.GetAddressOf());
deviceContext->CSSetUnorderedAccessViews(0, 1, m_pTempUAV0.GetAddressOf(), nullptr);
deviceContext->Dispatch((UINT)ceilf(m_Width / 256.0f), m_Height, 1);
deviceContext->CSSetUnorderedAccessViews(0, 1, nullUAV, nullptr);
// 縱向模糊
deviceContext->CSSetShader(m_pBlurVertCS.Get(), nullptr, 0);
deviceContext->CSSetShaderResources(0, 1, m_pTempSRV0.GetAddressOf());
if (blurTimes == 1 && outputTex)
deviceContext->CSSetUnorderedAccessViews(0, 1, &outputTex, nullptr);
else
deviceContext->CSSetUnorderedAccessViews(0, 1, m_pTempUAV1.GetAddressOf(), nullptr);
deviceContext->Dispatch(m_Width, (UINT)ceilf(m_Height / 256.0f), 1);
deviceContext->CSSetUnorderedAccessViews(0, 1, nullUAV, nullptr);
}
// 解除剩余系結
deviceContext->CSSetShaderResources(0, 1, nullSRV);
}
其余C++端原始碼則直接去專案原始碼看即可,
HLSL代碼
由于水平模糊與垂直模糊的實作原理相仿,這里我們只討論水平模糊,
在上面的代碼中,我們可以看到調度的執行緒組是由256個執行緒構成的水平“線段”,每個執行緒都負責影像中一個像素的模糊操作,一種低效的實作方案是,每個執行緒都簡單地計算出以正在處理的像素為中心的行矩陣(因為我們現在正在進行的是1D橫向模糊處理,所以要針對行矩陣進行計算)的加權平均值,這種辦法的缺點是需要多次拾取同一紋素,
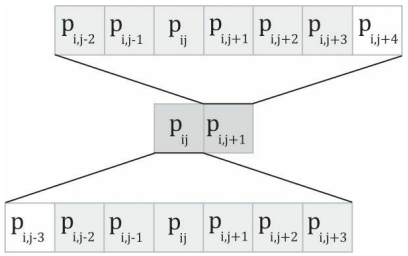
僅考慮輸入影像中的這兩個相鄰像素,假設模糊核為1×7,光是在對這兩個像素進行模糊的程序中,8個不同的像素中就已經有6個被采集了2次,而且要考慮到訪問設備記憶體的效率在GPU記憶體模型中是屬于比較慢的一種,
我們可以根據前面一節提到的模糊處理策略,利用共享記憶體來優化上述演算法,這樣一來,每個執行緒就可以在共享記憶體中讀取或存盤所需的紋素資料,待所有執行緒都從共享記憶體讀取到它們所需的紋素后,就能夠執行模糊運算了,不得不說,從共享記憶體中讀取資料的速度飛快,除此之外,還有一件棘手的事情,就是利用具有n = 256個執行緒的執行緒組行模糊運算的時候,卻需要n + 2R個紋素資料,這里的R就是模糊半徑:

由于模糊半徑的原因,在處理執行緒組邊界附近的像素時,可能會讀取執行緒組以外存在“越界”情況的像素,解決辦法其實也并不復雜,我們只需要分配出能容納n + 2R個元素的共享記憶體,并且有2R個執行緒要各獲取兩個紋素資料,唯一麻煩的地方就是在共享記憶體時要多花心思,因為組內執行緒ID此時不能于共享記憶體中的元素一一對應了,下圖演示了當R=4時,從執行緒到共享記憶體的映射程序,
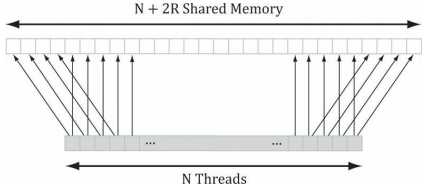
在此例中,R = 4,最左側的4個執行緒以及最右側的4個執行緒,每個都要讀取2個紋素資料,并將它們存于共享記憶體之中,而這8個執行緒之外的所有執行緒都只需要讀取1個像素,并將其存于共享記憶體之中,這樣一來,我們即可以得到以模糊半徑R對N個像素進行模糊處理所需的所有紋素資料,
現在要討論的是最后一種情況,即下圖中所示的最左側于最右側的執行緒組在索引輸入影像時會發生越界的情形,
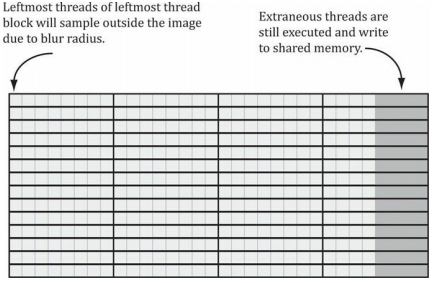
前面提到,從越界的索引處讀取資料并不是非法操作,而是回傳0(對越界索引處進行寫入是不會執行任何操作的,即no-op),然而,我們在讀取越界資料時并不希望得到資料0,因為這意味著值為0的顏色(即黑色)會影響到邊界處的模糊結果,我們此時期盼能實作出類似于鉗位(clamp)紋理尋址模式的效果,即在讀取越界的資料時,能夠獲得一個與邊界紋素相同的資料,這個方案可以通過對索引進行鉗位來加以實作,在下面完整的著色器代碼可以看到(這里將模糊半徑調大了):
// Blur.hlsli
cbuffer CBSettings : register(b0)
{
int g_BlurRadius;
// 最多支持19個模糊權值
float w0;
float w1;
float w2;
float w3;
float w4;
float w5;
float w6;
float w7;
float w8;
float w9;
float w10;
float w11;
float w12;
float w13;
float w14;
float w15;
float w16;
float w17;
float w18;
}
Texture2D g_Input : register(t0);
RWTexture2D<float4> g_Output : register(u0);
static const int g_MaxBlurRadius = 9;
#define N 256
#define CacheSize (N + 2 * g_MaxBlurRadius)
// Blur_Horz_CS.hlsl
#include "Blur.hlsli"
groupshared float4 g_Cache[CacheSize];
[numthreads(N, 1, 1)]
void CS(int3 GTid : SV_GroupThreadID,
int3 DTid : SV_DispatchThreadID)
{
// 放在陣列中以便于索引
float g_Weights[19] =
{
w0, w1, w2, w3, w4, w5, w6, w7, w8, w9,
w10, w11, w12, w13, w14, w15, w16, w17, w18
};
// 通過填寫本地執行緒存盤區來減少帶寬的負載,若要對N個像素進行模糊處理,根據模糊半徑,
// 我們需要加載N + 2 * BlurRadius個像素
// 此執行緒組運行著N個執行緒,為了獲取額外的2*BlurRadius個像素,就需要有2*BlurRadius個
// 執行緒都多采集一個像素資料
if (GTid.x < g_BlurRadius)
{
// 對于影像左側邊界存在越界采樣的情況進行鉗位(Clamp)操作
int x = max(DTid.x - g_BlurRadius, 0);
g_Cache[GTid.x] = g_Input[int2(x, DTid.y)];
}
if (GTid.x >= N - g_BlurRadius)
{
// 對于影像左側邊界存在越界采樣的情況進行鉗位(Clamp)操作
// 震驚的是Texture2D居然能通過屬性Length訪問寬高
int x = min(DTid.x + g_BlurRadius, g_Input.Length.x - 1);
g_Cache[GTid.x + 2 * g_BlurRadius] = g_Input[int2(x, DTid.y)];
}
// 將資料寫入Cache的對應位置
// 針對圖形邊界處的越界采樣情況進行鉗位處理
g_Cache[GTid.x + g_BlurRadius] = g_Input[min(DTid.xy, g_Input.Length.xy - 1)];
// 等待所有執行緒完成任務
GroupMemoryBarrierWithGroupSync();
// 開始對每個像素進行混合
float4 blurColor = float4(0.0f, 0.0f, 0.0f, 0.0f);
for (int i = -g_BlurRadius; i <= g_BlurRadius; ++i)
{
int k = GTid.x + g_BlurRadius + i;
blurColor += g_Weights[i + g_BlurRadius] * g_Cache[k];
}
g_Output[DTid.xy] = blurColor;
}
Blur_Vert_CS.hlsl與上面的代碼類似,就不再放出,
最右側的執行緒組可能存有一些多余的執行緒,但輸出的紋理中并沒有與之對應的元素(意味著它們根本無需輸出任何資料,見上圖),此時DTid.xy即為輸出紋理之外的一個越界索引,但是我們無需為此而擔心,因為向越界處寫入資料的效果是不進行任何操作(no-op),
索貝爾算子
索貝爾算子(Sobel Operator)用于影像的邊緣檢測,它會針對每一個像素估算其梯度(gradient)的大小,梯度值較大的像素則表明它與周圍像素的顏色差異極大,因而此像素一定位于影像的邊緣,相反,具有較小梯度的像素則意味著它與臨近像素的顏色趨同,即該像素并不處于影像邊沿之上,需要注意的是,索貝爾算子回傳的并非是像素是否位于影像邊緣的二元結果,而是一個范圍在[0.0, 1.0]內表示邊緣“陡峭”程度的灰度值:值為0表示非常平坦,與周圍像素并沒有顏色差異;值為1表示非常陡峭,與周圍像素顏色差異很大,通常索貝爾逆影像(1-c)往往會更加直觀有效,這時白色表示平坦且不位于影像邊緣,而黑色則代表陡峭且處于影像邊緣,
運用索貝爾算子后的結果:
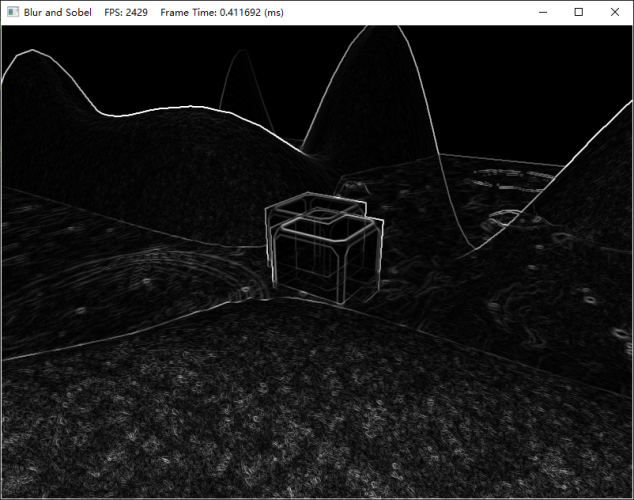
索貝爾算子的逆影像的結果:
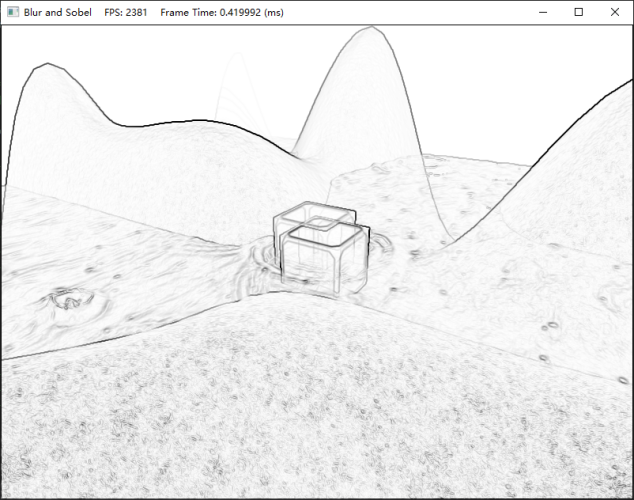
如果將原始影像與其經過索貝爾算子生成的逆影像兩者間的對應顏色值相乘,我們將獲得類似于卡通畫或動漫書中那樣,其邊緣就像用黑色的筆勾描后的圖片效果,哪怕待處理的影像首先經過模糊處理后已經隱去了部分細節,依舊可以恢復其相對粗獷的畫風,令其邊緣清晰起來,
索貝爾算子所采用的演算法是先進行加權平均,然后進行近似求導運算,計算方法如下:
\[G_x = \Delta_x f(x, y) = [f(x-1,y+1)+2f(x,y+1)+f(x+1,y+1)]-[f(x-1,y-1)+2f(x,y-1)+f(x+1,y-1)] \\ G_y = \Delta_y f(x, y) = [f(x-1,y-1)+2f(x-1,y)+f(x-1,y+1)]-[f(x+1,y-1)+2f(x+1,y)+f(x+1,y+1)] \]
因此我們就得到了梯度向量\((\Delta_x f(x, y), \Delta_y f(x, y))\),然后求出它的長度\(\parallel \sqrt{G_{x}^{2} + G_{y}^{2}}\parallel\)即為變化方向最大處的變化率,
HLSL代碼
索貝爾算子的HLSL代碼實作如下:
// Sobel_CS.hlsl
Texture2D g_Input : register(t0);
RWTexture2D<float4> g_Output : register(u0);
// 將RGB色轉化為灰色
float3 RGB2Gray(float3 color)
{
return (float3) dot(color, float3(0.299f, 0.587f, 0.114f));
}
[numthreads(16, 16, 1)]
void CS(int3 DTid : SV_DispatchThreadID)
{
// 采集當前待處理像素及相鄰的八個像素
float4 colors[3][3];
for (int i = 0; i < 3; ++i)
{
for (int j = 0; j < 3; ++j)
{
int2 xy = DTid.xy + int2(-1 + j, -1 + i);
colors[i][j] = g_Input[xy];
}
}
// 針對每個顏色通道,利用索貝爾算子估算出關于x的偏導數近似值
float4 Gx = -1.0f * colors[0][0] - 2.0f * colors[1][0] - 1.0f * colors[2][0] +
1.0f * colors[0][2] + 2.0f * colors[1][2] + 1.0f * colors[2][2];
// 針對每個顏色通道,利用索貝爾算子估算出關于y的偏導數的近似值
float4 Gy = -1.0f * colors[2][0] - 2.0f * colors[2][1] - 1.0f * colors[2][2] +
1.0f * colors[0][0] + 2.0f * colors[0][1] + 1.0f * colors[0][2];
// 梯度向量即為(Gx, Gy),針對每個顏色通道,計算出梯度大小(即梯度的模擬)
// 以找到最大的變化率
float4 mag = sqrt(Gx * Gx + Gy * Gy);
// 將梯度陡峭的邊緣處繪制為黑色,梯度平坦的非邊緣處繪制為白色
mag = 1.0f - float4(saturate(RGB2Gray(mag.xyz)), 0.0f);
g_Output[DTid.xy] = mag;
}
// VS使用Basic_VS_2D
// Composite_PS.hlsl
Texture2D g_BaseMap : register(t0); // 原紋理
Texture2D g_EdgeMap : register(t1); // 邊緣紋理
SamplerState g_SamLinearWrap : register(s0); // 線性過濾+Wrap采樣器
SamplerState g_SamPointClamp : register(s1); // 點過濾+Clamp采樣器
float4 PS(float4 posH : SV_Position, float2 tex : TEXCOORD) : SV_Target
{
float4 c = g_BaseMap.SampleLevel(g_SamPointClamp, tex, 0.0f);
float4 e = g_EdgeMap.SampleLevel(g_SamPointClamp, tex, 0.0f);
// 將原始圖片與邊緣圖相乘
return c * e;
}
在C++端的代碼可以直接去原始碼中尋找SobelFilter,
演示
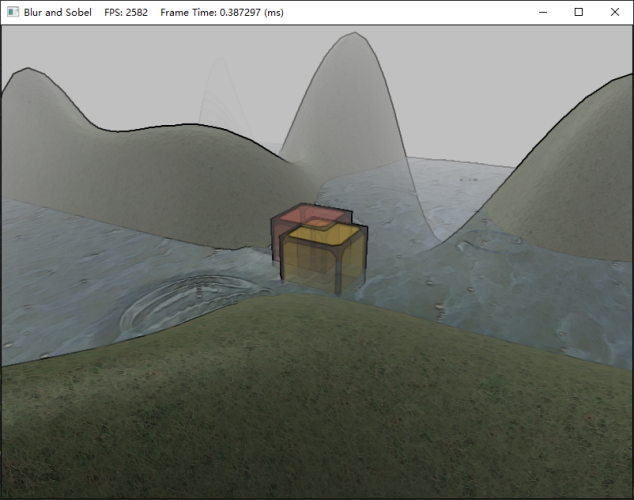
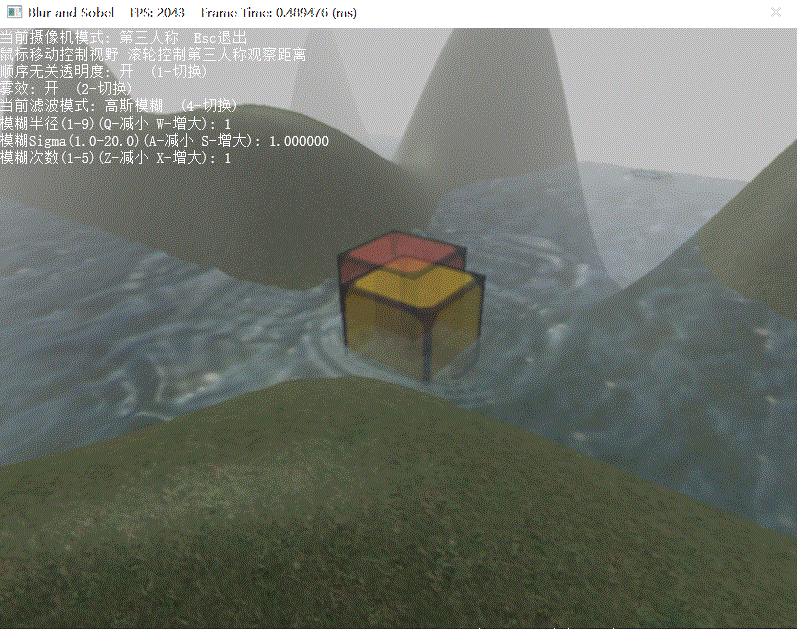
本樣例為高斯模糊提供了調整模糊半徑、Sigma和次數的功能,模糊半徑越大,模糊次數越大,幀數會越低,如果你的電腦配置承受不住,建議關掉OIT來觀察模糊效果會更好一些,至于Sobel算子則無法調整,
整個計算著色器的內容就到此結束了,
除錯問題
該專案無法圖形除錯,就和DirectX SDK Samples中OIT樣例一樣,遇到了未知問題,如果要除錯,需要把OIT相關的代碼撤走才能除錯,

此外,龍書12中的Composite.hlsl頂點著色器用到了SV_VertexID,一旦用了該系統值作為輸入,就無法在最終結果選擇像素觀察運行程序了,因此本專案并沒有使用內置于著色器的頂點資料,
練習題
-
對影像進行模糊處理是一種昂貴的操作,它所花費的時間于待處理的影像大小息息相關,一般情況下,在把場景渲染到離屏紋理的時候,我們通常會將離屏紋理的大小設為后備緩沖區尺寸的1/4.也就是說,假如后備緩沖區的大小為800x600,則離屏紋理的尺寸將為400x300.這樣一來不僅能加快離屏紋理的繪制速度(即減少了需要填充的像素數量),而且能同時提升模糊影像的處理速度(需要模糊的像素也就更少),另外,當紋理從1/4的螢屏解析度拉伸為完整大螢屏解析度時,紋理放大過濾器也會執行一些額外的模糊操作,
現在嘗試修改專案,讓BlurFilter的解析度為400x300,實作上述內容,
提示:TextureRender開啟mipmaps,并將mip等級為1的紋理子資源作為SRV, -
嘗試添加
Composite_VS.hlsl,將繪制整個螢屏的6個頂點直接放在頂點著色器中,然后只使用SV_VertexID作為頂點著色器的形參來繪制, -
研究雙邊模糊(雙邊濾波器,bilateral blur)計數,并用計算著色器加以實作,
DirectX11 With Windows SDK完整目錄
Github專案原始碼
歡迎加入QQ群: 727623616 可以一起探討DX11,以及有什么問題也可以在這里匯報,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/5310.html
標籤:其他
上一篇:lua學習之型別與值篇
下一篇:lua學習之基礎概念篇