摘要:本篇博客介紹了基于MobileNet的人臉表情識別系統,支持圖片識別、視頻識別、攝像頭識別等多種形式,通過GUI界面實作表情識別可視化展示,首先介紹了表情識別任務的背景與意義,總結近年來利用深度學習進行表情識別的相關技術和作業,在資料集選擇上,本文選擇了Fer2013和CK+兩個資料集,并使用MATLAB對這些資料進行預處理和訓練,最后通過呼叫已經訓練好的MobileNet模型對影像中存在的人臉目標進行表情識別分類,詳細介紹了實作程序中使用的代碼和設計框架,本文旨在為相關領域的研究人員和新入門的朋友提供參考,完整代碼資源檔案請轉至文末的下載鏈接,
目錄- 引言
- 1. 相關作業
- 2. 系統界面演示效果
- 3. 表情識別資料集
- 4. 網路訓練與評估
- 5. 系統實作
- 下載鏈接
- 6. 總結與展望
- 參考文獻
?點擊跳轉至文末所有涉及的完整代碼檔案下載頁?
完整代碼下載:https://mbd.pub/o/bread/mbd-ZJiYlpdu
參考視頻演示:https://www.bilibili.com/video/BV1ts4y1X71R/
引言
我此前在博客中設計了一款基于 Python 的人臉表情識別系統介紹,這是一個有趣好玩的Python專案,該博客受到了廣泛的關注和反響,經過四年的持續更新和完善,現在向大家介紹人臉表情識別系統在 MATLAB 中的實作,本文旨在幫助更多人了解和學習表情識別技術,同時展現我對于技術創新的熱忱和樂于分享的態度,很高興我的博客能夠給予入門的讀者一點啟發,現成的代碼可以省去重復造輪子的時間,但也希望讀者能真正讀懂代碼和實作思路,避免“拿來主義”,在此之上能夠有自己的見地和思考,感謝各位讀者的支持和關注,期待與大家共同探索這一有趣的領域,
隨著人工智能技術的飛速發展,計算機視覺領域也得到了長足的進步,人臉表情識別作為計算機視覺的一個重要應用,具有廣泛的應用前景,如人機互動、心理健康分析、虛擬現實等,本博客將介紹一種基于MobileNet的人臉表情識別系統,并使用MATLAB進行實作,本博客內容為博主原創,相關參考和參考文獻我已在文中標注,考慮到可能會有相關研究人員蒞臨指導,博主的博客這里盡可能以學術期刊的格式撰寫,如需參考可參考本博客格式如下:
[1] 思緒無限. 基于MobileNet的人臉表情識別系統(MATLAB GUI版+原理詳解)[J/OL]. CSDN, 2023.05. http://wuxian.blog.csdn.net/article/details/130460275.
[2] Wu, S. (2023, May 2). MobileNet-based facial expression recognition system (MATLAB GUI version + detailed principles) [Blog post]. CSDN Blog. http://wuxian.blog.csdn.net/article/details/130460275
人臉表情識別研究的現狀已經取得了一定的成果,但仍然面臨諸多挑戰,如不同光照條件、姿態變化、表情類別定義等,近年來,深度學習在計算機視覺任務中取得了巨大成功,尤其是卷積神經網路(CNN)在影像識別領域的表現尤為突出,本博客將采用MobileNet作為基礎架構,以其輕量級、高效的特點,實作一個實時的人臉表情識別系統,本博客的貢獻點主要包括以下幾個方面:
- 詳細介紹了基于MobileNet的人臉表情識別系統的實作程序;
- 使用MATLAB實作了系統,使得開發者能夠更方便地進行除錯和優化;
- 提供了多種表情識別場景,如圖片識別、視頻識別和攝像頭識別;
- 結合了兩個公開的表情識別資料集,Fer2013和CK+,進行模型訓練和評估;
- 設計了一個簡潔的GUI界面,方便用戶進行實時表情識別,
1. 相關作業
隨著深度學習在計算機視覺領域的廣泛應用,許多研究者開始嘗試利用深度學習技術對人臉表情進行識別,在本節中,我們將回顧近年來深度學習在表情識別領域的發展,涉及不同的網路結構、優化技術以及資料增強方法等,(本部分參考文獻見文末)
首先,我們來回顧一下基于深度學習的表情識別的一些基礎作業,Goodfellow et al. [1] 提出了一種名為深度信念網路(DBN)的表情識別方法,并在Fer2013資料集上進行了測驗,Lopes et al. [2] 利用卷積神經網路(CNN)進行表情識別,實作了較高的識別準確率,這些作業為后續基于深度學習的表情識別研究奠定了基礎,隨后,研究者們開始嘗試使用不同的網路結構和優化方法來提高表情識別的性能,例如,Kahou et al. [3] 提出了一種融合卷積神經網路和回圈神經網路(RNN)的多模態表情識別方法,Mollahosseini et al. [4] 使用Inception模塊構建了一個名為FECNet的深度表情識別網路,取得了顯著的性能提升,此外,還有研究者嘗試利用遷移學習技術,如Zhang et al. [5] 利用VGG-Face預訓練模型進行表情識別任務,有效地提高了識別性能,
資料增強方法在深度學習中具有重要的作用,尤其是對于資料不足的情況,Khorrami et al. [6] 提出了一種基于生成對抗網路(GAN)的資料增強方法,以提高表情識別性能,Kaya et al. [7] 將分數融合和資料增強方法應用于表情識別任務,實作了較大的性能提升,此外,還有研究者通過多任務學習來進行表情識別,如Liu et al. [8] 提出了一種多任務學習的表情識別方法,同時學習面部屬性和表情識別任務,
近年來,輕量級神經網路在表情識別任務中也得到了廣泛關注,這些輕量級網路具有較低的計算復雜性和記憶體需求,使得它們更適用于移動設備和實時應用,Howard et al. [9] 提出了MobileNet網路,通過引入深度可分離卷積(depthwise separable convolution)減少引數數量和計算量,Sandler et al. [10] 提出了MobileNetV2,引入了線性瓶頸和逆殘差結構,進一步提高了計算效率,基于MobileNet的表情識別方法也取得了顯著的成果,例如,Hu et al. [11] 提出了一種基于MobileNetV2的輕量級表情識別網路,實作了較高的識別準確率和實時性能,
通過以上文獻綜述,我們可以看到深度學習在人臉表情識別領域的廣泛應用和發展,在本博客中,我們將基于MobileNet架構,結合Fer2013和CK+48資料集,實作一個基于MATLAB的實時人臉表情識別系統,同時提供多種表情識別場景,如圖片識別、視頻識別和攝像頭識別,以及設計一個簡潔的GUI界面,方便用戶進行實時表情識別,
2. 系統界面演示效果
在本節中,我們將展示基于MobileNet的人臉表情識別系統的界面效果,系統提供了三種識別場景:圖片識別、視頻識別和攝像頭識別,為了使用戶更好地體驗系統,我們設計了一個簡潔易用的GUI界面,
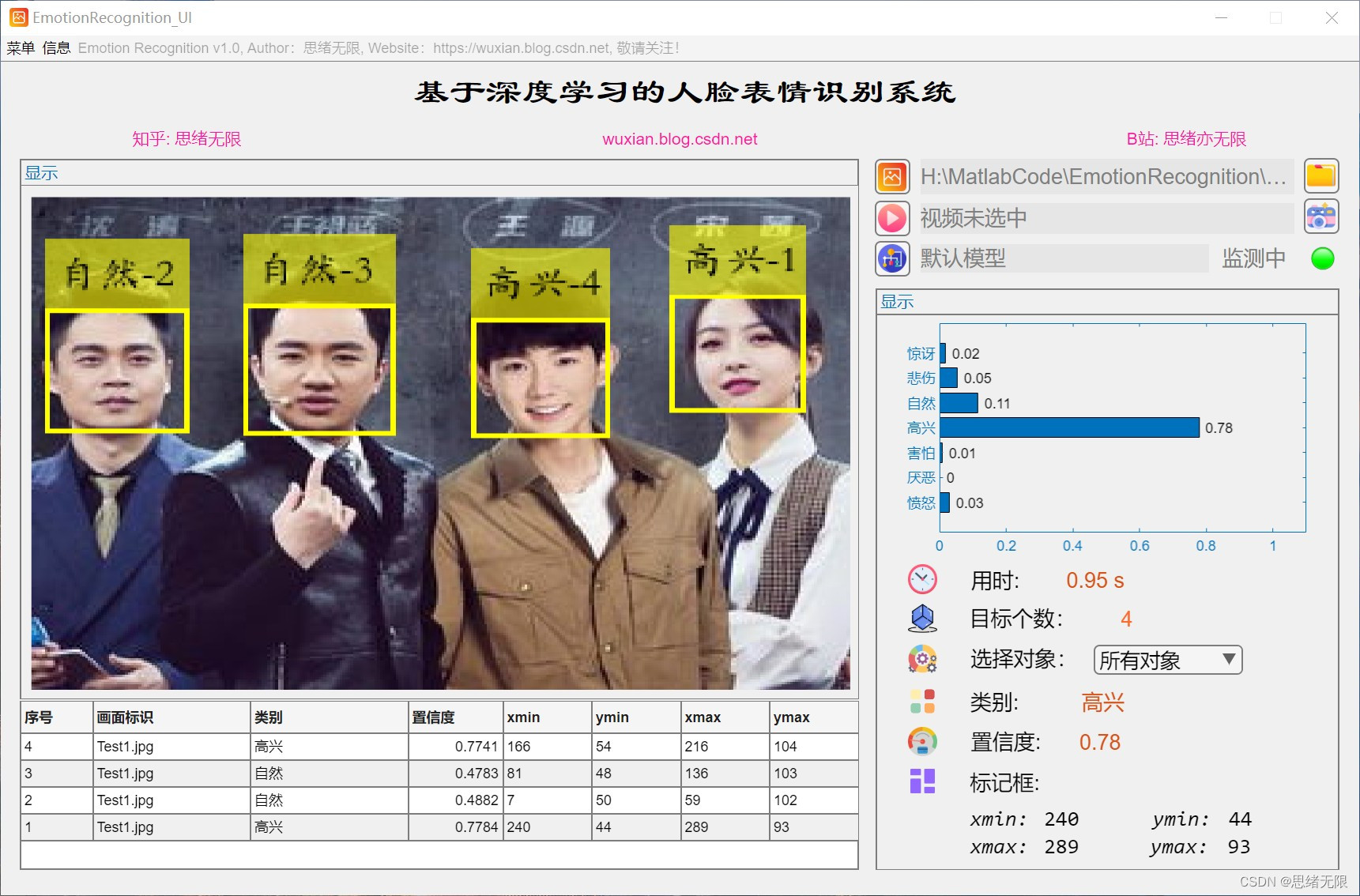
(1)圖片識別:用戶可以選擇一張包含人臉表情的圖片,系統將識別并顯示圖片中的表情,在GUI界面上,用戶可以點擊“選擇圖片”按鈕,選擇本地的一張圖片,然后系統將自動識別圖片中的表情,并在圖片旁邊顯示識別結果,
(2)批量圖片識別:用戶可以選擇圖片檔案夾實作批量圖片識別,系統將識別并顯示圖片中的表情,
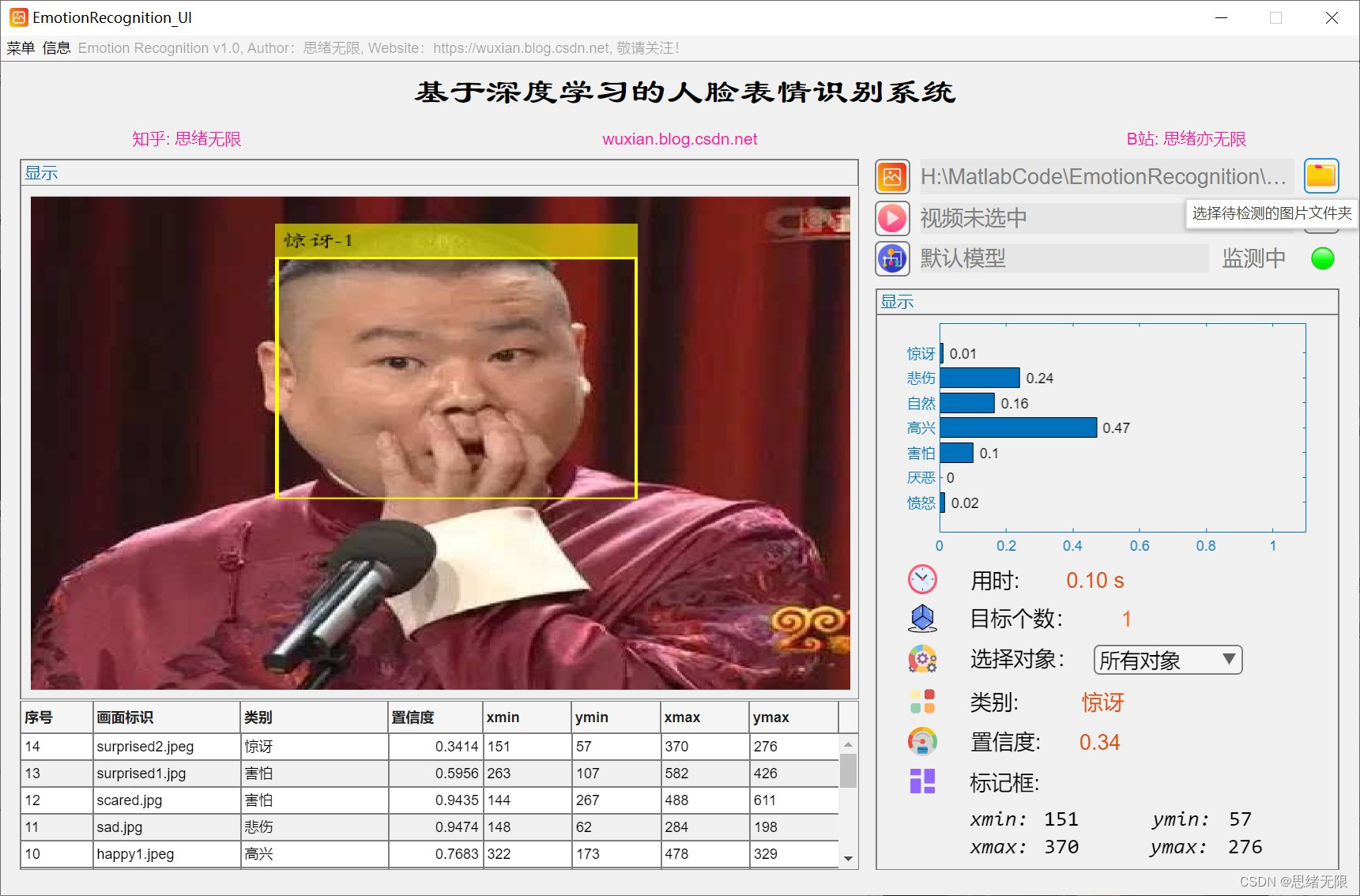
(3)視頻識別:用戶可以選擇一個包含人臉表情的視頻檔案,系統將實時識別并顯示視頻中的表情,在GUI界面上,用戶可以點擊“選擇視頻”按鈕,選擇本地的一個視頻檔案,然后系統將自動播放視頻并實時識別視頻中的表情,同時在視頻畫面上顯示識別結果,
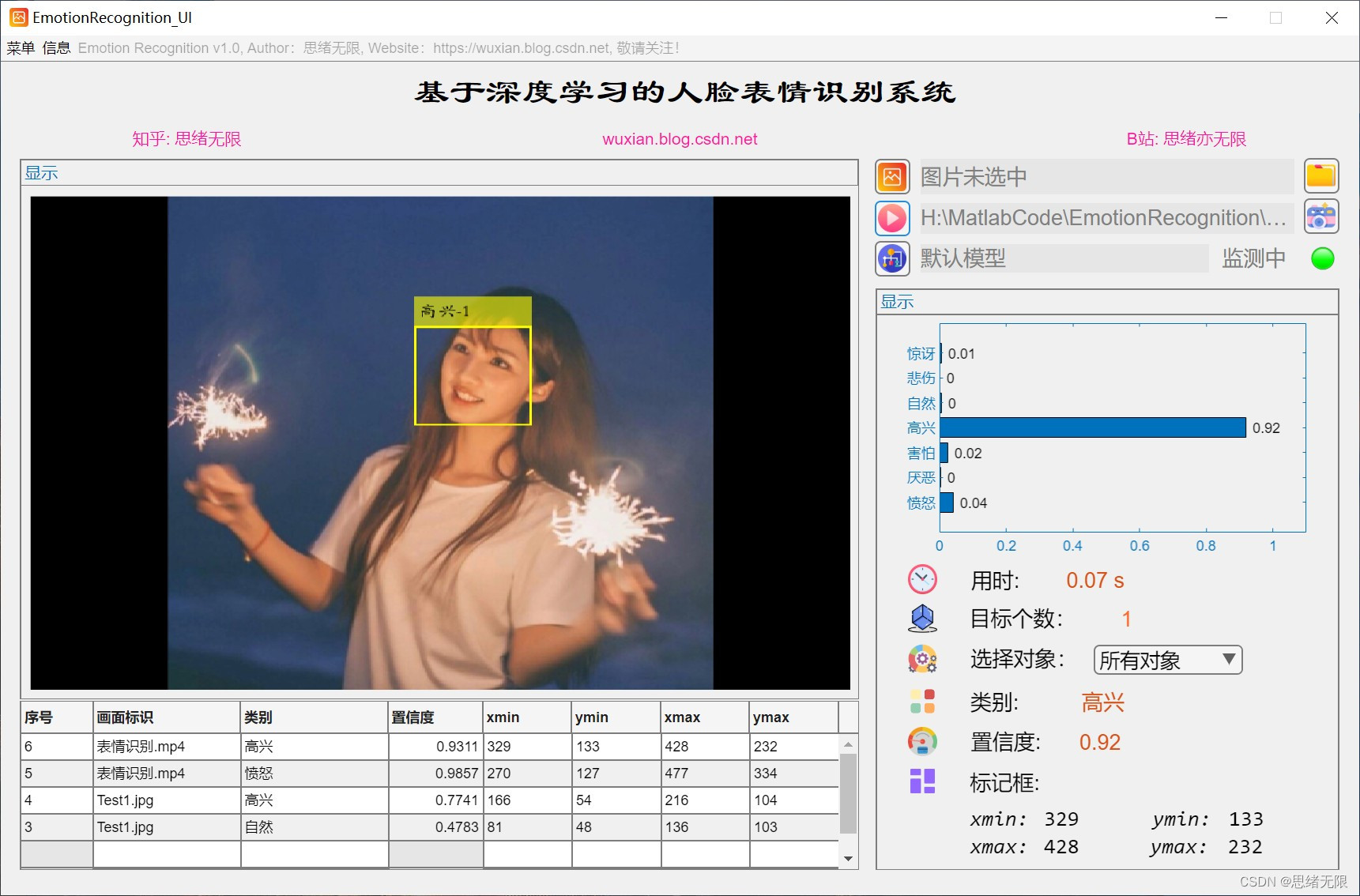
(4)攝像頭識別:用戶可以通過電腦攝像頭進行實時表情識別,在GUI界面上,用戶可以點擊“攝像頭識別”按鈕,系統將打開攝像頭并實時識別用戶的表情,同時在攝像頭畫面上顯示識別結果,
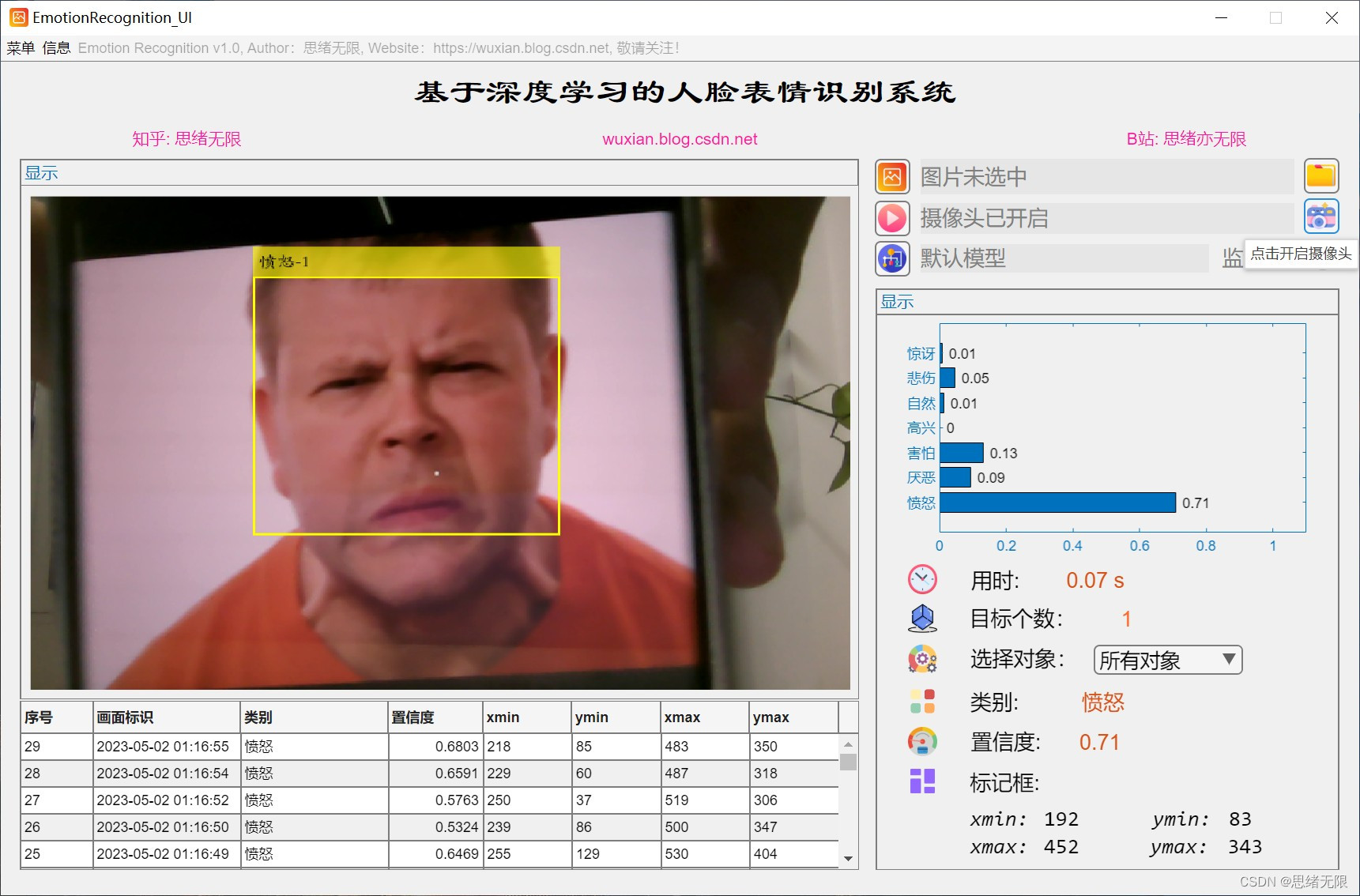
(5)更換模型和修改文字圖示:用戶可以點擊右側的模型選擇按鈕更換不同的模型,對于界面中的文字和圖示的修改請在APP設計工具中修改,
3. 表情識別資料集
為了訓練和評估所設計的人臉表情識別系統,我們需要使用表情識別相關的資料集,在本節中,我們介紹幾個公開的表情識別資料集,并給出我們最終選擇的資料集Fer2013和CK+48,
JAFFE (Japanese Female Facial Expression) 資料集:JAFFE資料集是日本女性面部表情資料集,包含了213張由10名日本女性演員表演的7種基本面部表情(憤怒、厭惡、恐懼、快樂、悲傷、驚訝和中性)的灰度影像,每種表情都有3個不同的程度,此資料集較小,但具有較高的標注準確率,官網鏈接:http://www.kasrl.org/jaffe.html
KDEF (Karolinska Directed Emotional Faces) 資料集:KDEF資料集包含了4900張由70名瑞典模特表演的7種基本面部表情(憤怒、厭惡、恐懼、快樂、悲傷、驚訝和中性)的彩色影像,每張影像均以五個不同的角度拍攝,這個資料集具有較大的樣本量和多角度表情圖片,官網鏈接:https://kdef.se/

AffectNet 資料集:AffectNet是一個大規模的面部表情資料集,包含約42萬張面部表情影像,每張影像都標注了表情類別和面部活動單元(AU)資訊,AffectNet適合訓練和評估深度學習模型,尤其是用于自然環境中的面部表情識別,官網鏈接:http://mohammadmahoor.com/affectnet/
FERG (Facial Expression Research Group) 資料集:FERG資料集是一個包含人工生成面部表情的資料集,包括6個虛擬角色的6種表情(憤怒、厭惡、恐懼、快樂、悲傷和驚訝)的影像,此資料集的優點是可以通過渲染技術生成大量樣本,但它的局限性在于不包含真實人臉影像,官網鏈接:https://grail.cs.washington.edu/projects/deepexpr/ferg-db.html
Fer2013:這是一個廣泛使用的表情識別資料集,由Goodfellow等人于2013年發布[1],Fer2013包含約35,000張灰度影像,涵蓋了7種不同的表情類別,包括憤怒、厭惡、恐懼、快樂、悲傷、驚訝和中性,Fer2013資料集具有多樣性和較大規模的優點,適合訓練深度學習模型,官網鏈接:https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data

CK+:CK+(Cohn-Kanade+)資料集是由Lucey等人于2010年發布的一個面部表情資料集,CK+資料集包含了593個視頻序列,涵蓋了8種不同的表情類別,包括憤怒、厭惡、恐懼、快樂、悲傷、驚訝、中性和輕蔑,CK+資料集具有較高的標注準確率,提供了動態表情資訊,鏈接:https://paperswithcode.com/dataset/ck
我們選擇Fer2013和CK+作為我們的資料集,原因如下:首先,Fer2013具有較大規模和多樣性,有利于訓練出泛化能力較強的模型;其次,CK+資料集雖然樣本量相對較小,但提供了動態表情資訊和較高的標注準確率,可以作為補充資料集,提高模型的表現,我們將結合這兩個資料集進行神經網路的訓練和評估,
4. 網路訓練與評估
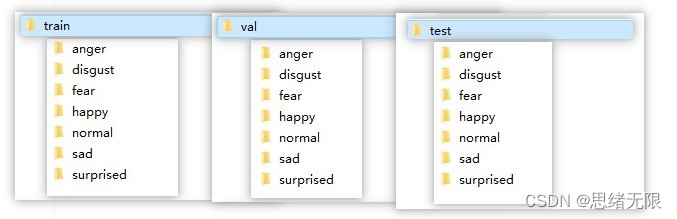
在本節中,我們將通過訓練一個神經網路來實作表情識別任務,實際上,表情識別可以被視為一個分類任務,我們需要在給定的人臉影像中識別出一種表情,為了簡化資料處理程序,我們將Fer2013資料集原本的csv檔案轉換成圖片格式,并將它們存放在train、test、val檔案夾下,
首先,我們需要清除當前環境并設定亂數種子以保證結果的一致性:
clear
clc
rng default % 保證結果運行一致
接著,我們讀取訓練、驗證和測驗影像檔案夾,創建ImageDatastore物件:
trainDir = fullfile("./train/");
valDir = fullfile("./val/");
testDir = fullfile("./test/");
imdsTrain = imageDatastore(trainDir, 'IncludeSubfolders', true, 'LabelSource', 'foldernames');
imdsValid = imageDatastore(valDir, 'IncludeSubfolders', true, 'LabelSource', 'foldernames');
imdsTest = imageDatastore(testDir, 'IncludeSubfolders', true, 'LabelSource', 'foldernames');
確定分類類別數量:
numClasses = numel(categories(imdsTrain.Labels))
% > numClasses = 7
在這里,我們選擇使用MobileNetV2作為我們的基本神經網路模型,首先,我們創建一個MobileNetV2實體,并獲取其層和輸入尺寸:
net = mobilenetv2;
layers = net.Layers
inputSize = net.Layers(1).InputSize % 網路輸入尺寸
此時列印網路的結構如下所示:
layers =
具有以下層的 154×1 Layer 陣列:
1 'input_1' 影像輸入 224×224×3 影像: 'zscore' 歸一化
2 'Conv1' 卷積 32 3×3×3 卷積: 步幅 [2 2],填充 'same'
3 'bn_Conv1' 批量歸一化 批量歸一化: 32 個通道
4 'Conv1_relu' Clipped ReLU Clipped ReLU: 上限 6
5 'expanded_conv_depthwise' 分組卷積 32 groups of 1 3×3×1 卷積: 步幅 [1 1],填充 'same'
6 'expanded_conv_depthwise_BN' 批量歸一化 批量歸一化: 32 個通道
7 'expanded_conv_depthwise_relu' Clipped ReLU Clipped ReLU: 上限 6
8 'expanded_conv_project' 卷積 16 1×1×32 卷積: 步幅 [1 1],填充 'same'
9 'expanded_conv_project_BN' 批量歸一化 批量歸一化: 16 個通道
10 'block_1_expand' 卷積 96 1×1×16 卷積: 步幅 [1 1],填充 'same'
...
接下來,我們需要對網路進行微調,以便將其應用于我們的表情識別任務,我們首先使用全連接層替換原始網路中的Logits層,并為其設定權重和偏置的學習率因子:
newLearnableLayer = fullyConnectedLayer(numClasses, ...
'Name','new_fc', ...
'WeightLearnRateFactor',10, ...
'BiasLearnRateFactor',10);
lgraph = replaceLayer(lgraph,'Logits',newLearnableLayer);
然后,我們將分類層替換為一個新的分類層:
newClassLayer = classificationLayer('Name','new_classoutput');
lgraph = replaceLayer(lgraph,'ClassificationLayer_Logits',newClassLayer);
接下來,我們設定資料增強選項,并創建增強后的ImageDatastore物件:
pixelRange = [-30 30];
imageAugmenter = imageDataAugmenter( ...
'RandXReflection',true, ...
'RandXTranslation',pixelRange, ...
'RandYTranslation',pixelRange);
augimdsTrain = augmentedImageDatastore(inputSize(1:2),imdsTrain, ...
'DataAugmentation',imageAugmenter, 'ColorPreprocessing','gray2rgb');
augimdsValidation = augmentedImageDatastore(inputSize(1:2), imdsValid, 'ColorPreprocessing','gray2rgb');
augimdsTest = augmentedImageDatastore(inputSize(1:2), imdsTest, 'ColorPreprocessing','gray2rgb');
我們選擇使用隨機梯度下降優化器(SGDM)作為我們的訓練優化器,并設定訓練選項,包括MiniBatchSize、MaxEpochs、InitialLearnRate等,我們還設定驗證資料和驗證頻率,以便在訓練程序中評估網路性能:
options = trainingOptions('sgdm', ...
'MiniBatchSize',64, ...
'MaxEpochs',300, ...
'InitialLearnRate',1e-4, ...
'Shuffle','every-epoch', ...
'ValidationData',augimdsValidation, ...
'ValidationFrequency',60, ...
'Verbose', true, ...
'Plots','training-progress', ...
'OutputNetwork', 'best-validation-loss');
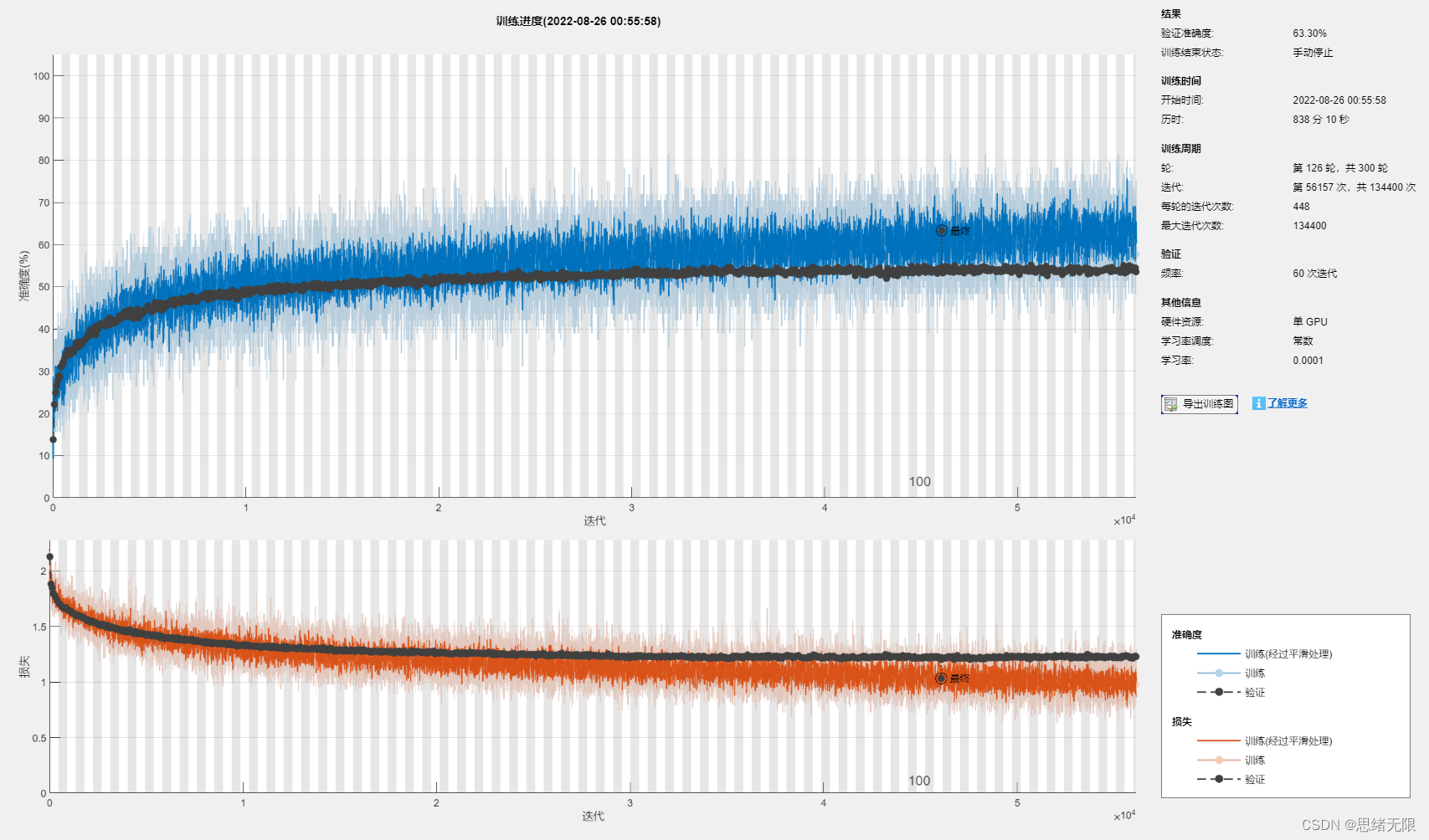
現在我們已經準備好訓練我們的神經網路了,使用以下代碼進行訓練:
model = trainNetwork(augimdsTrain,lgraph,options);
訓練程序中的輸出如下:
在單 GPU 上訓練,
正在初始化輸入資料歸一化,
|=============================================================================|
| 輪 | 迭代 | 經過的時間 | 小批量準確度 | 驗證準確度 | 小批量損失 | 驗證損失 | 基礎學習率 |
| | | (hh:mm:ss) | | | | | |
|=============================================================================|
| 1 | 1 | 00:00:15 | 9.38% | 13.74% | 2.1997 | 2.1275 | 1.0000e-04 |
| 1 | 50 | 00:00:57 | 18.75% | | 1.8871 | | 1.0000e-04 |
| 1 | 60 | 00:01:16 | 25.00% | 22.12% | 1.9477 | 1.8843 | 1.0000e-04 |
| 1 | 100 | 00:01:50 | 23.44% | | 1.8143 | | 1.0000e-04 |
| 1 | 120 | 00:02:12 | 31.25% | 24.85% | 1.6894 | 1.8497 | 1.0000e-04 |
...
訓練完成后,我們將訓練好的模型保存到一個名為MobileNet_emotion.mat的檔案中:
save('MobileNet_emotion.mat', 'model');
接下來,我們使用測驗資料集評估模型的性能:
[YPred,scores] = classify(model, augimdsTest);
隨機選擇4個測驗影像并顯示它們的預測結果:
idx = randperm(numel(imdsTest.Files),4);
figure
for i = 1:4
subplot(2,2,i)
I = readimage(imdsTest,idx(i));
imshow(I)
label = YPred(idx(i));
title(string(label));
end

計算模型在測驗集上的準確率:
YTest = imdsTest.Labels;
accuracy = mean(YPred == YTest)
% > accuracy = 0.6450
最后,繪制混淆矩陣以直觀地展示模型的分類性能:
figure
plotconfusion(imdsTest.Labels, YPred); % 繪制混淆矩陣圖
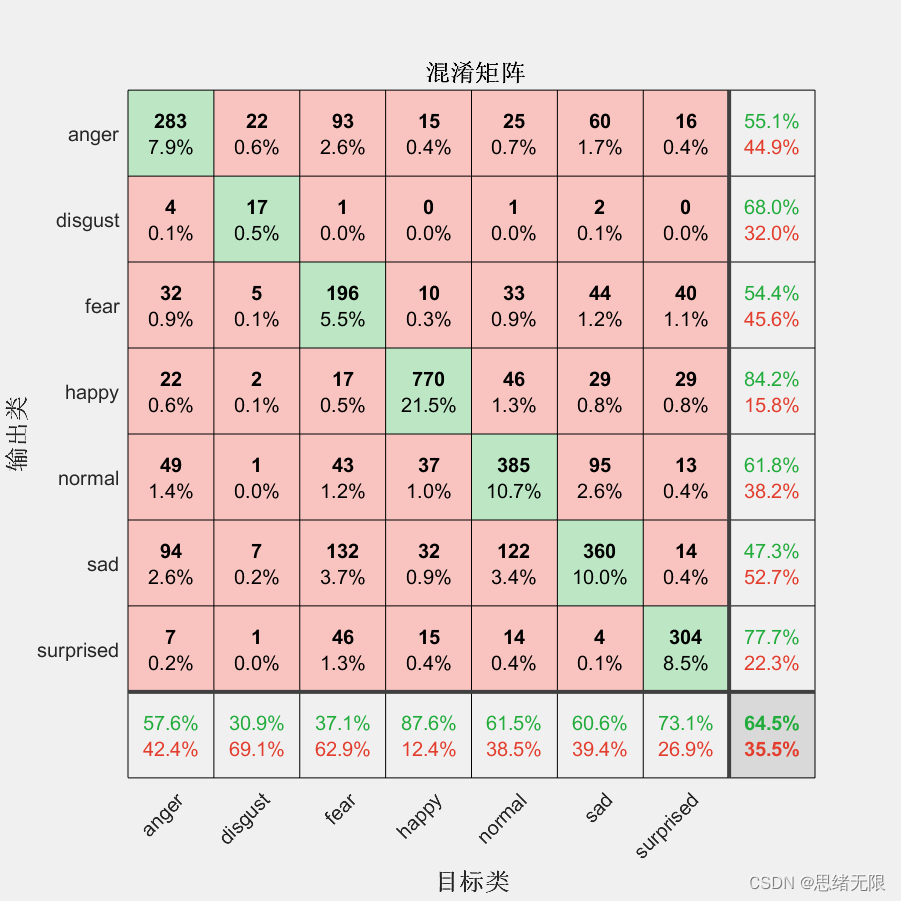
至此,我們已經成功地訓練了一個基于MobileNetV2的表情識別神經網路,并對其進行了性能評估,在下一節中,我們將介紹如何將這個模型整合到一個完整的系統中,
5. 系統實作
在本節中,我們將介紹如何將已訓練好的模型整合到一個完整的表情識別系統中,首先,我們將展示如何使用訓練好的模型對攝像頭畫面進行實時檢測并標注表情,然后結合GUI界面設計框架和實作,
值得注意的是,表情識別模型只對人臉部分進行表情分類,因此,在處理攝像頭捕獲的實時畫面之前,我們需要先檢測畫面中的人臉,為此,我們使用了vision.CascadeObjectDetector()函式來實作人臉檢測,該函式創建了一個級聯物件檢測器,用于檢測影像中的人臉,
% 由于表情識別模型只對人臉部分進行表情分類,我們需要先檢測畫面中的人臉,
% 使用vision.CascadeObjectDetector()函式創建一個級聯物件檢測器,用于檢測影像中的人臉,
faceDetector = vision.CascadeObjectDetector();
首先,我們加載所需的依賴項和模型,并獲取模型的輸入尺寸和定義類別名稱:
load('MobileNet_emotion.mat', 'model');
inputSize = model.Layers(1).InputSize;
class_name = {'anger', 'disgust', 'fear', 'happy','normal', 'sad', 'surprised';...
'憤怒', '厭惡', '害怕', '高興', '自然', '悲傷', '驚訝'};
然后,我們創建一個攝像頭物件、一個用于顯示實時視頻的視窗以及一個用于保存帶標簽的視頻的VideoWriter物件:
cap = webcam();
player = vision.DeployableVideoPlayer();
image = cap.snapshot();
step(player, image);
writer = VideoWriter('labeled_camera.avi'); % 要輸出的視頻
open(writer);
figure
在回圈中,我們不斷從攝像頭捕獲影像,然后使用emoRec函式對影像中的人臉進行表情識別,接著,我們將識別到的表情標簽添加到影像上,并將結果顯示在視窗中:
while player.isOpen()
Img = cap.snapshot();
Img = imresize(Img, [500, 700]);
[bboxes, scores, labels] = emoRec(faceDetector, model, Img);
num = size(bboxes, 1);
if num >= 1
label_text = cell(num, 1);
labels = cellstr(labels);
for i = 1: num
for cls_n=1:size(class_name, 2)
if strcmp(class_name{1, cls_n}, labels(i))
score = round(max(scores(i, :) * 100), 2);
label_text{i, 1} = [class_name{2, cls_n}, ' - ' , num2str(score), '%'];
break;
end
end
end
Img = insertObjectAnnotation(Img,'rectangle',bboxes, cellstr(label_text), ...
'LineWidth',2, 'Font','華文楷體','FontSize',16);
end
imshow(Img)
writeVideo(writer, Img); % 寫入檔案
end
最后,在用戶關閉視頻視窗時,我們關閉視頻寫入、釋放視頻視窗并洗掉攝像頭物件:
close(writer); % 關閉檔案寫入
release(player); % 釋放畫面視窗
delete(cap); % 關閉相機
這樣,我們就成功地將訓練好的表情識別模型整合到一個實時的人臉表情識別系統中,系統將不斷捕獲攝像頭畫面,對畫面中的人臉進行表情識別,并實時顯示識別結果,演示的效果如下:

接下來,我們將設計一個基于MATLAB App Designer的GUI界面,以便用戶可以更方便地使用我們的表情識別系統,以下是一個簡單的設計框架:創建一個新的MATLAB App Designer專案,在設計界面中,添加以下組件:
- 選擇圖片按鈕:用戶可以通過單擊此按鈕來選擇要進行表情識別的圖片檔案,
- 播放視頻按鈕:用戶可以通過單擊此按鈕來播放要進行表情識別的視頻檔案,
- 攝像頭開啟按鈕:用戶可以通過單擊此按鈕來開啟計算機上的攝像頭,并開始進行實時的表情識別,
- 選擇識別模型:用戶可以通過此選項選擇要使用的表情識別模型(例如,我們可以提供MobileNet和EfficientNet等不同的模型),
- 顯示結果:此處顯示表情識別的結果,例如識別出的表情類別、置信度等資訊,
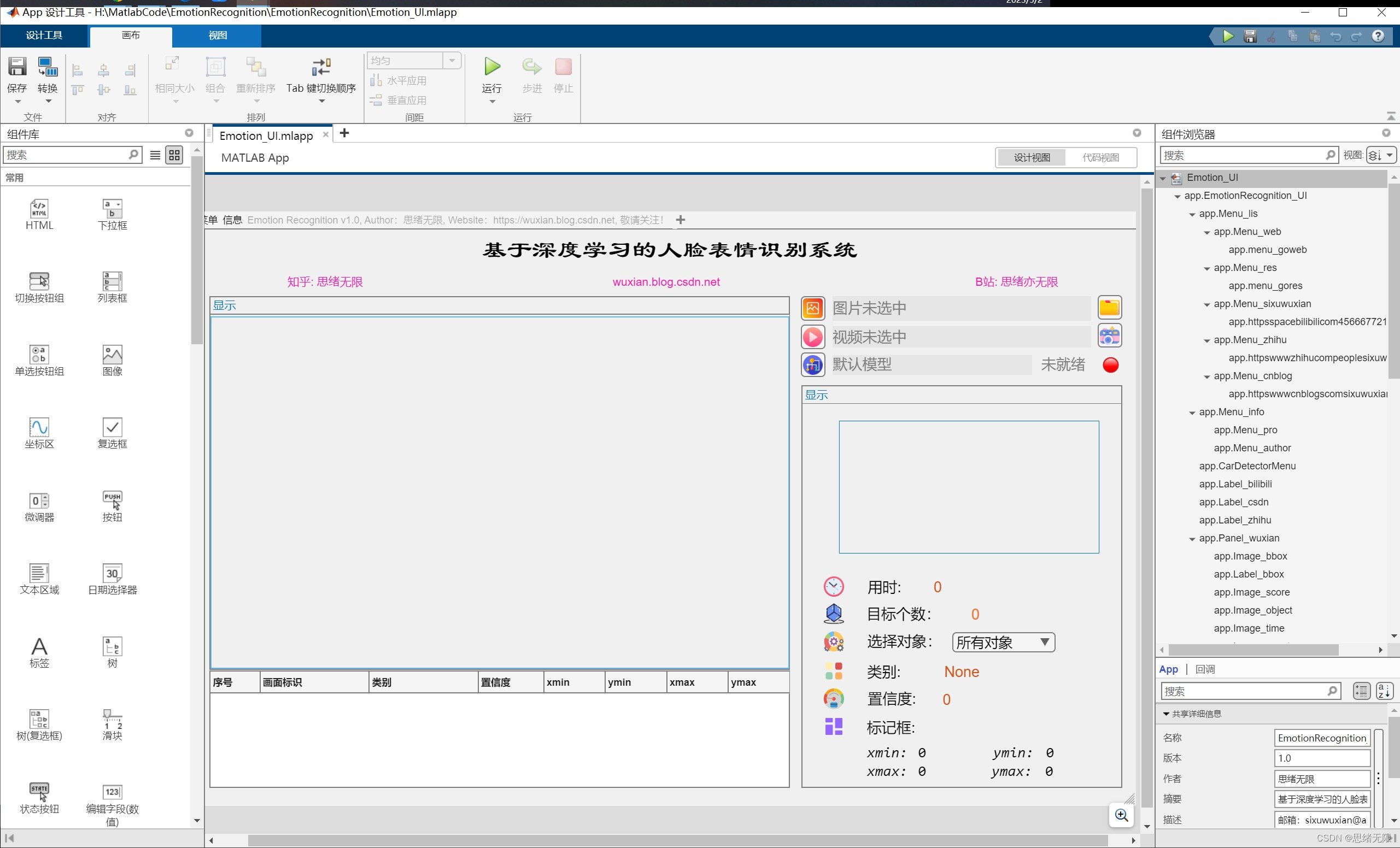
分別為打開圖片、視頻、攝像頭、模型的按鈕添加一個回呼函式,以便在用戶單擊該按鈕時執行相應的操作,在此回呼函式中,可以使用上面提供的代碼片段進行圖片讀取、預處理、表情識別和結果顯示,至此,我們已經成功地將訓練好的表情識別模型整合到一個完整的系統中,用戶可以通過GUI界面選擇圖片,然后系統將對圖片中的人臉進行表情識別,并顯示識別結果,
下載鏈接
若您想獲得博文中涉及的實作完整全部程式檔案(包括測驗圖片、視頻,mlx, mlapp檔案等,如下圖),這里已打包上傳至博主的面包多平臺,見可參考博客與視頻,已將所有涉及的檔案同時打包到里面,點擊即可運行,完整檔案截圖如下:
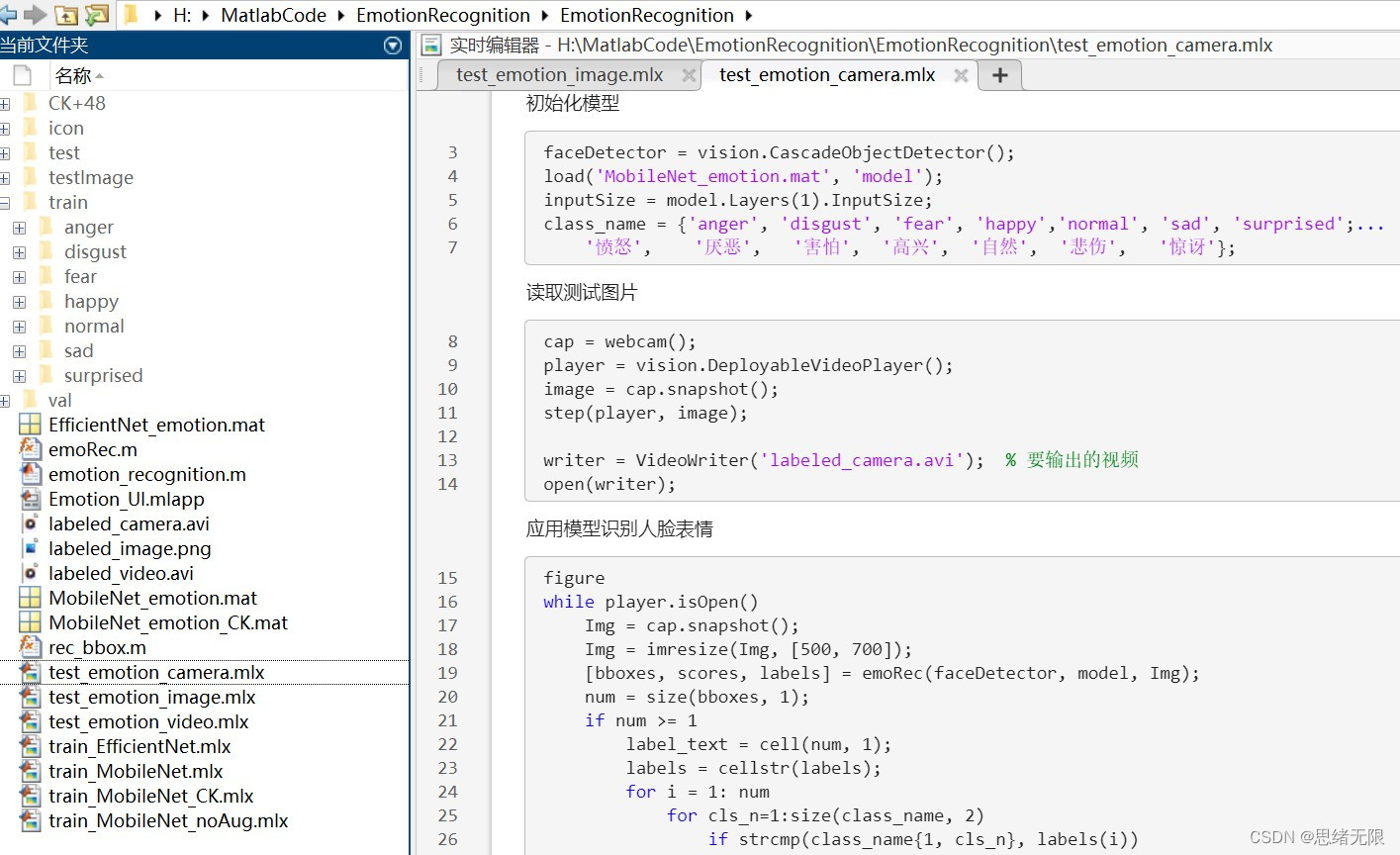
在檔案夾下的資源顯示如下圖所示:

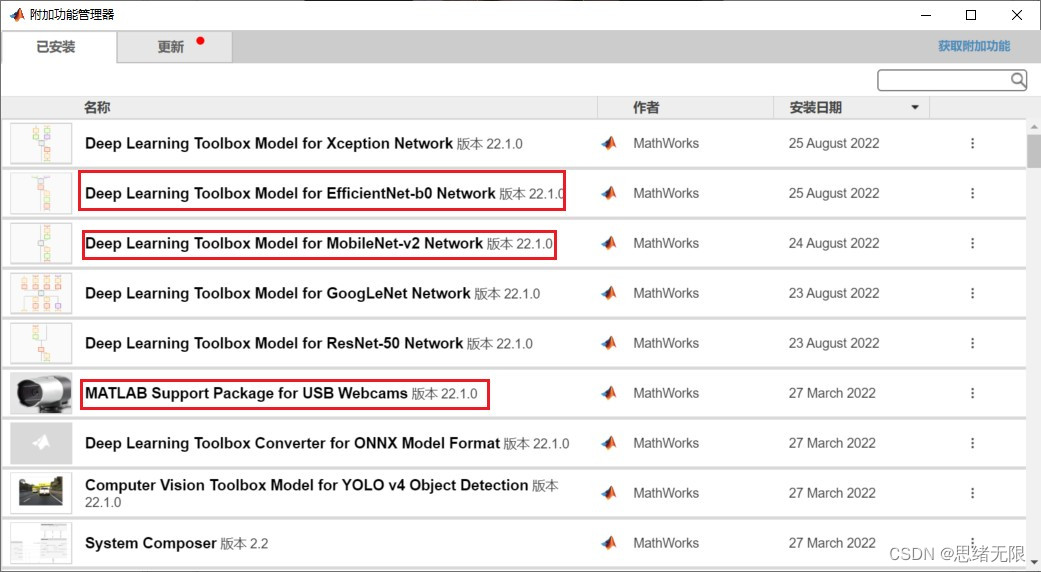
注意:該代碼采用MATLAB R2022a開發,經過測驗能成功運行,運行界面的主程式為Emotion_UI.mlapp,測驗視頻腳本可運行test_emotion_video.py,測驗攝像頭腳本可運行test_emotion_camera.mlx,為確保程式順利運行,請使用MATLAB2022a運行并在“附加功能管理器”(MATLAB的上方選單欄->主頁->附加功能->管理附加功能)中添加有以下工具,
完整資源中包含資料集及訓練代碼,環境配置與界面中文字、圖片、logo等的修改方法請見視頻,專案完整檔案下載請見參考博客文章里面,或參考視頻的簡介處給出:???
完整代碼下載:https://mbd.pub/o/bread/mbd-ZJiYlpdu
參考視頻演示:https://www.bilibili.com/video/BV1ts4y1X71R/
6. 總結與展望
本文詳細介紹了基于MobileNet的人臉表情識別系統的設計與實作,包括資料集的選擇、模型訓練、GUI界面的設計等方面,通過本文的介紹,我們可以了解到如何使用深度學習技術實作人臉表情識別,以及如何構建一個GUI界面來實作人臉表情的實時檢測,同時,本文也提供了詳細的代碼實作和資源檔案,為相關領域的研究人員和新入門者提供了一個參考,未來的研究可以進一步改進模型的準確性和魯棒性,并應用于更廣泛的領域和應用場景中,
由于博主能力有限,博文中提及的方法即使經過試驗,也難免會有疏漏之處,希望您能熱心指出其中的錯誤,以便下次修改時能以一個更完美更嚴謹的樣子,呈現在大家面前,同時如果有更好的實作方法也請您不吝賜教,
參考文獻
[1] Goodfellow, I., et al. "Challenges in Representation Learning: A report on three machine learning contests." Neural Networks 64 (2015): 59-63.
[2] Lopes, A. T., et al. "Facial expression recognition with convolutional neural networks: coping with few data and the training sample order." Pattern Recognition 61 (2017): 610-628.
[3] Kahou, S. E., et al. "EmoNets: Multimodal deep learning approaches for emotion recognition in video." Journal on Multimodal User Interfaces 10.2 (2016): 99-111.
[4] Mollahosseini, A., et al. "AffectNet: A database for facial expression, valence, and arousal computing in the wild." IEEE Transactions on Affective Computing 10.1 (2019): 18-31.
[5] Zhang, K., et al. "Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks." IEEE Signal Processing Letters 23.10 (2016): 1499-1503.
[6] Khorrami, P., et al. "Do deep neural networks learn facial action units when doing expression recognition?" Proceedings of the IEEE International Conference on Computer Vision Workshops (2015): 19-27.
[7] Kaya H, Gürp?nar F, Salah A A. Video-based emotion recognition in the wild using deep transfer learning and score fusion[J]. Image and Vision Computing, 2017, 65: 66-75.
[8] Liu, Z., et al. "Joint face detection and alignment using multitask cascaded convolutional networks." IEEE Signal Processing Letters 23.10 (2016): 1499-1503.
[9] Howard, A. G., et al. "MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications." arXiv preprint arXiv:1704.04861 (2017).
[10] Sandler, M., et al. "MobileNetV2: Inverted Residuals and Linear Bottlenecks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018): 4510-4520.
[11] Hu L, Ge Q. Automatic facial expression recognition based on MobileNetV2 in Real-time[C]//Journal of Physics: Conference Series. IOP Publishing, 2020, 1549(2): 022136.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/551647.html
標籤:其他
上一篇:從功能測驗轉型測驗開發,薪資漲了20K,1000字講述轉型必經之路...
下一篇:返回列表