摘要:本文介紹了實作分頁串列快取的三種方式,
本文分享自華為云社區《分頁串列快取,你真的會嗎》,作者: 勇哥java實戰分享 ,
1 直接快取分頁串列結果
顯而易見,這是最簡單易懂的方式,
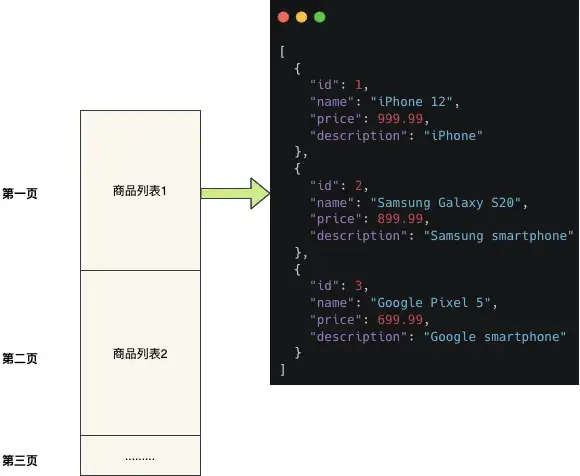
我們按照不同的分頁條件來快取分頁結果 ,偽代碼如下:
public List<Product> getPageList(String param,int page,int size) { String key = "productList:page:" + page + ”size:“ + size + "param:" + param ; List<Product> dataList = cacheUtils.get(key); if(dataList != null) { return dataList; } dataList = queryFromDataBase(param,page,size); if(dataList != null) { cacheUtils.set(key , dataList , Constants.ExpireTime); } }
這種方案的優點是工程簡單,性能也快,但是有一個非常明顯的缺陷基因:串列快取的顆粒度非常大,
假如串列中資料發生增刪,為了保證資料的一致性,需要修改分頁串列快取,
有兩種方式 :
1、依靠快取過期來惰性的實作 ,但業務場景必須包容;
2、使用 Redis 的 keys 找到該業務的分頁快取,執行洗掉指令, 但 keys 命令對性能影響很大,會導致 Redis 很大的延遲 ,
生產環境使用 keys 命令比較危險,發生事故的幾率高,非常不推薦使用,
2 查詢物件ID串列,再快取每個物件條目
快取分頁結果雖然好用,但快取的顆粒度太大,保證資料一致性比較麻煩,
所以我們的目標是更細粒度的控制快取 ,
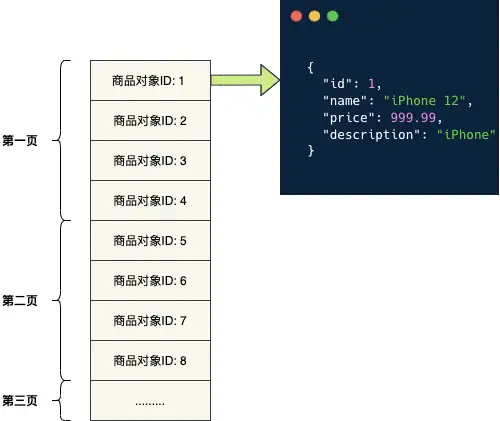
我們查詢出商品分頁物件ID串列,然后為每一個商品物件創建快取 , 通過商品ID和商品物件快取聚合成串列回傳給前端,
偽代碼如下:
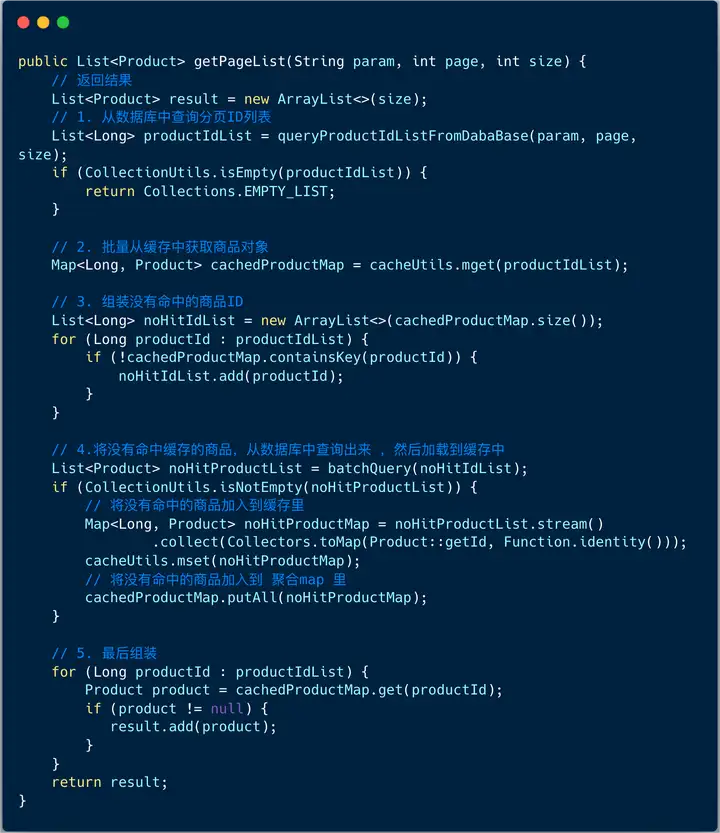
核心流程:
1、從資料庫中查詢分頁 ID 串列
// 從資料庫中查詢分頁商品 ID 串列 List<Long> productIdList = queryProductIdListFromDabaBase( param, page, size);
對應的 SQL 類似:
SELECT id FROM products ORDER BY id LIMIT (page - 1) * size , size
2、批量從快取中獲取商品物件
Map<Long, Product> cachedProductMap = cacheUtils.mget(productIdList);
假如我們使用本地快取,直接一條一條從本地快取中聚合也極快,
假如我們使用分布式快取,Redis 天然支持批量查詢的命令 ,比如 mget ,hmget ,
3、組裝沒有命中的商品ID
List<Long> noHitIdList = new ArrayList<>(cachedProductMap.size()); for (Long productId : productIdList) { if (!cachedProductMap.containsKey(productId)) { noHitIdList.add(productId); } }
因為快取中可能因為過期或者其他原因導致快取沒有命中的情況,所以我們需要找到哪些商品沒有在快取里,
4、批量從資料庫查詢未命中的商品資訊串列,重新加載到快取
首先從資料庫里批量查詢出未命中的商品資訊串列 ,請注意是批量,
List<Product> noHitProductList = batchQuery(noHitIdList);引數是未命中快取的商品ID串列,組裝成對應的 SQL,這樣性能更快 :
SELECT * FROM products WHERE id IN (1, 2, 3, 4);
然后這些未命中的商品資訊存盤到快取里 , 使用 Redis 的 mset 命令,
//將沒有命中的商品加入到快取里 Map<Long, Product> noHitProductMap = noHitProductList.stream() .collect( Collectors.toMap(Product::getId, Function.identity()) ); cacheUtils.mset(noHitProductMap); //將沒有命中的商品加入到聚合map里 cachedProductMap.putAll(noHitProductMap);
5、 遍歷商品ID串列,組裝物件串列
for (Long productId : productIdList) { Product product = cachedProductMap.get(productId); if (product != null) { result.add(product); } }
當前方案里,快取都有命中的情況下,經過兩次網路 IO ,第一次資料庫查詢 IO ,第二次 Redis 查詢 IO , 性能都會比較好,
所有的操作都是批量操作,就算有快取沒有命中的情況,整體速度也較快,
”查詢物件ID串列,再快取每個物件條目“ 這個方案比較靈活,當我們查詢物件ID串列,可以不限于資料庫,還可以是搜索引擎,Redis 等等,
下圖是開源中國的搜索流程:

精髓在于:搜索的分頁結果只包含業務物件 ID ,物件的詳細資料需要從快取 + MySQL 中獲取,
3 快取物件ID串列,同時快取每個物件條目
筆者曾經重構過類似朋友圈的服務,進入班級頁面 ,瀑布流的形式展示班級成員的所有動態,
我們使用推模式將每一條動態 ID 存盤在 Redis ZSet 資料結構中 ,Redis ZSet 是一種型別為有序集合的資料結構,它由多個有序的唯一的字串元素組成,每個元素都關聯著一個浮點數分值,
ZSet 使用的是 member -> score 結構 :
- member : 被排序的標識,也是默認的第二排序維度( score 相同時,Redis 以 member 的字典序排列)
- score : 被排序的分值,存盤型別是 double
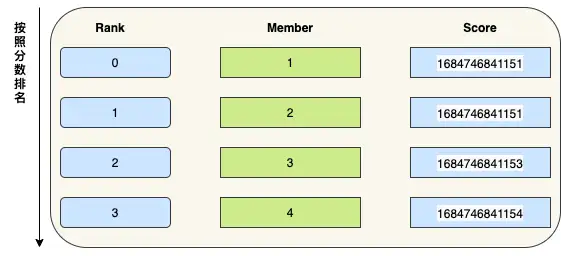
如上圖所示:ZSet 存盤動態 ID 串列 , member 的值是動態編號 , score 值是創建時間,
通過 ZSet 的 ZREVRANGE 命令就可以實作分頁的效果,
ZREVRANGE 是 Redis 中用于有序集合(sorted set)的命令之一,它用于按照成員的分數從大到小回傳有序集合中的指定范圍的成員,

為了達到分頁的效果,傳遞如下的分頁引數 :

通過 ZREVRANGE 命令,我們可以查詢出動態 ID 串列,
查詢出動態 ID 串列后,還需要快取每個動態物件條目,動態物件包含了詳情,評論,點贊,收藏這些功能資料 ,我們需要為這些資料提供單獨做快取配置,

無論是查詢快取,還是重新寫入快取,為了提升系統性能,批量操作效率更高,
若快取物件結構簡單,使用 mget 、hmget 命令;若結構復雜,可以考慮使用 pipleline,Lua 腳本模式 ,筆者選擇的批量方案是 Redis 的 pipleline 功能,
我們再來模擬獲取動態分頁串列的流程:
- 使用 ZSet 的 ZREVRANGE 命令 ,傳入分頁引數,查詢出動態 ID 串列 ;
- 傳遞動態 ID 串列引數,通過 Redis 的 pipleline 功能從快取中批量獲取動態的詳情,評論,點贊,收藏這些功能資料 ,組裝成串列 ,
4 總結
本文介紹了實作分頁串列快取的三種方式:
- 直接快取分頁串列結果
- 查詢物件ID串列,只快取每個物件條目
- 快取物件ID串列,同時快取每個物件條目
這三種方式是一層一層遞進的,要訣是:細粒度的控制快取和批量加載物件,
點擊關注,第一時間了解華為云新鮮技術~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/553384.html
標籤:其他
上一篇:學系統集成專案管理工程師(中項)系列26_新興資訊技術
下一篇:返回列表