導讀
本文主要講解了京東百億級商品車型適配資料存盤結構設計以及怎樣實作適配介面的高性能查詢,通過京東百億級資料快取架構設計實踐案例,簡單剖析了jimdb的位圖(bitmap)函式和lua腳本應用在高性能場景,希望通過本文,讀者可以對快取的內部結構知識有一定了解,并且能夠以最小的記憶體使用代價將位圖(bitmap)靈活應用到各個高性能實際場景,
1.背景
整個汽車行業行特殊性,對于零配件有一個很強的對口特性,不同車使用的零配件(例如:輪胎、機油、三濾、雨刮、火花塞等)規格型號不一樣,在售賣汽車零配件的時候,不能像3C家電、服飾,需要結合用戶具體車輛資訊,推薦適合的配件商品,基于此原因,京東自建人車檔案模型并且利用演算法清洗出百億級的車型-零配件的適配關系資料,最終形成“人->車-〉貨”關系鏈路,解決“人不識貨”的問題, 具體使用場景如下圖:
.
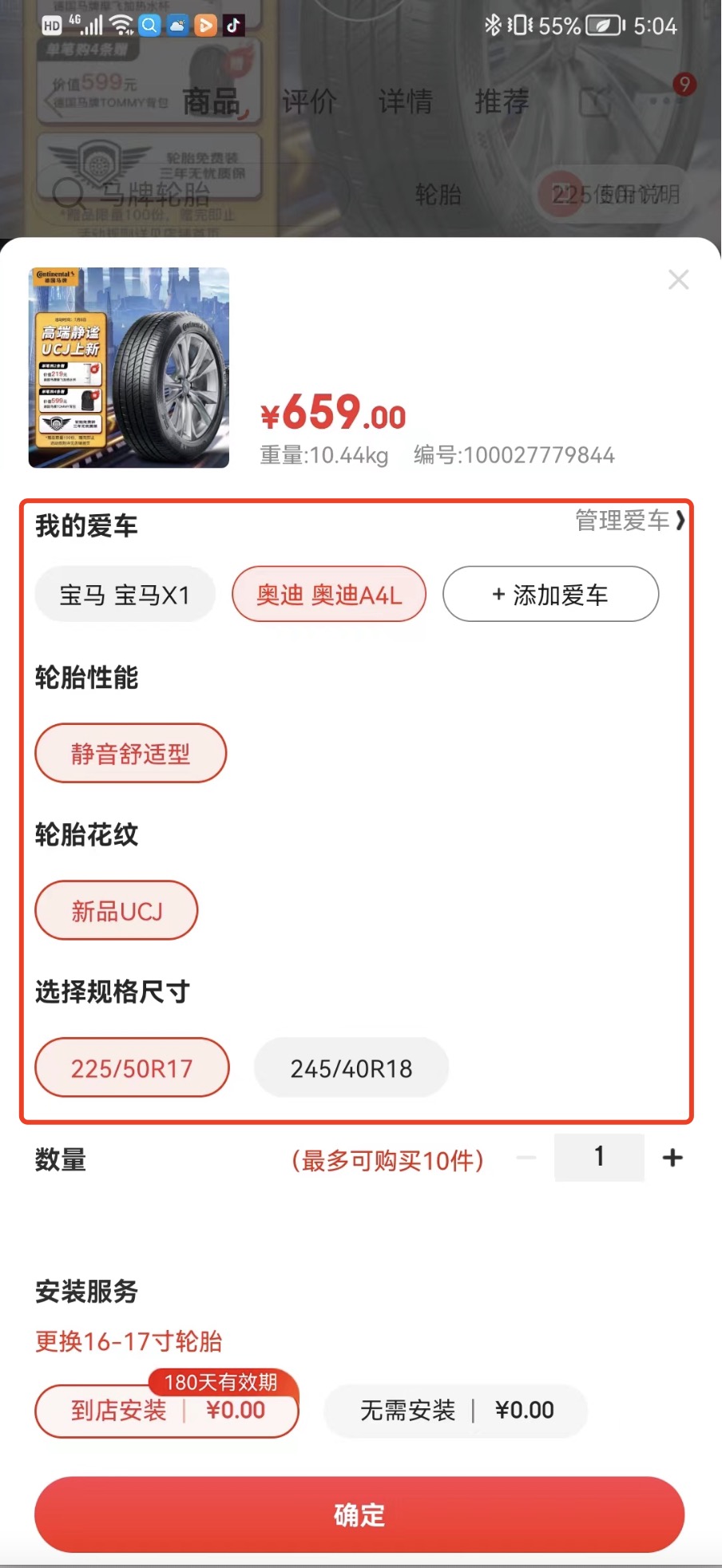
圖1.1京東商詳推薦商品 圖1.2京東加購彈窗推薦商品
2.資料模型
“人-> 車->貨”關系的核心鏈路是由人(京東用戶)、乘用車和SKU這三部分組成,
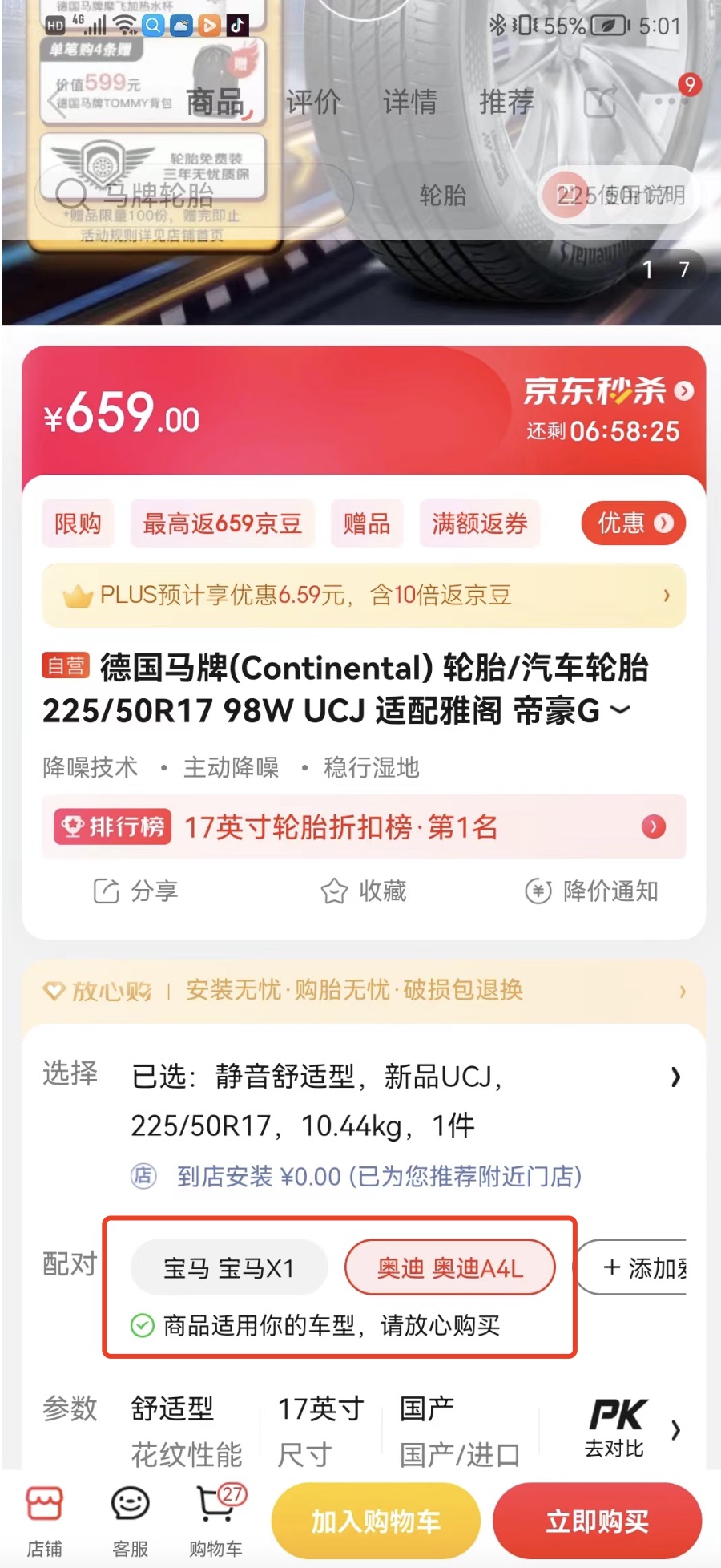
首先,用戶在京東APP的商搜頁、商詳頁多個位置都可以選擇自己的車型資訊進行系結(例如:圖2.1,京東商詳綁車入口位置“+添加愛車”按鈕),建立“人車檔案”資料,
.
圖2.1.京東商詳綁車入口位置 圖2.2.京東商搜綁車入口位置
其次,運營在后臺管理系統中將商品與車型進行系結,建立“商品與車型關系”資料(商品與車型的關系資料量級在百億級別),
最終,購買商品的時候,京東推薦系統可以通過用戶自己系結的車型推薦出適合該車型的商品,具體商品適配車型資料模型,見圖2.3,
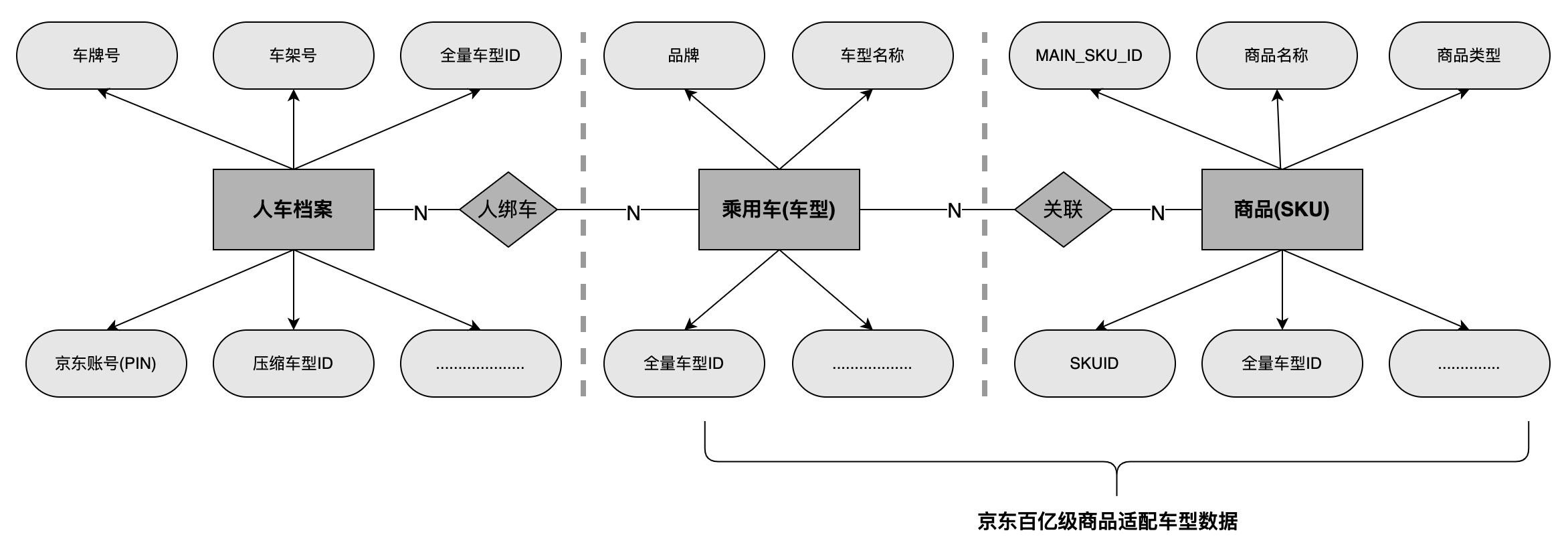
圖2.3京東商品適配車型資料模型
3.快取結構設計
基于前面兩個部分的介紹,我們可以了解到整個商品搜索適配推薦存在兩個最核心問題,第一、百億級商品適配車型資料的存盤結構設計,盡可能的占用資源成本最小;第二、商詳通過用戶車型來搜索適配商品時,必須保證介面性能的TP99位于毫秒級,最終技術選型的時候,采用了jimdb的位圖(bitmap)函式來進行資料存盤,
3.1位圖(bitmap)結構
位圖(bitmap)是通過最小的單位bit來進行0或者1的設定,表示某個元素對應的值或者狀態,一個bit的值是0或者1;也就是說一個bit能存盤的最多資訊是2,
? 位(bit):計算機內部資料存盤的最小單位,例如:11001100是一個八位二進制數,
? 位元組(byte):計算機中資料處理的基本單位,習慣上用大寫B來表示,1B(byte,位元組)=8bit,
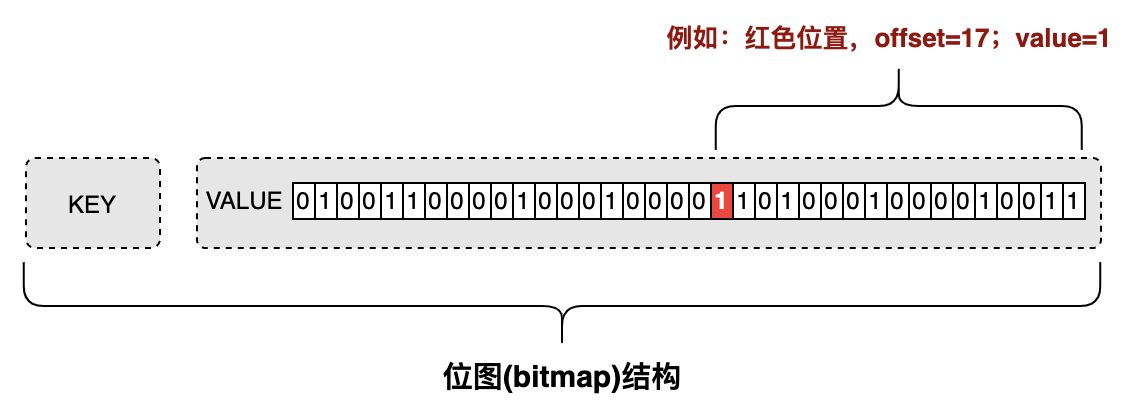
圖3.1位圖(bitmap)內部結構
3.2位圖(bitmap)資料寫流程
位圖(bitmap)是基于jimdb的SDS(簡單動態字串)型別的一系列位操作,遵循jimdb的SDS特性,例如:位圖(bitmap)最大長度512M,最大可以存盤232位,以下是“big”字串的SDS結構示例:
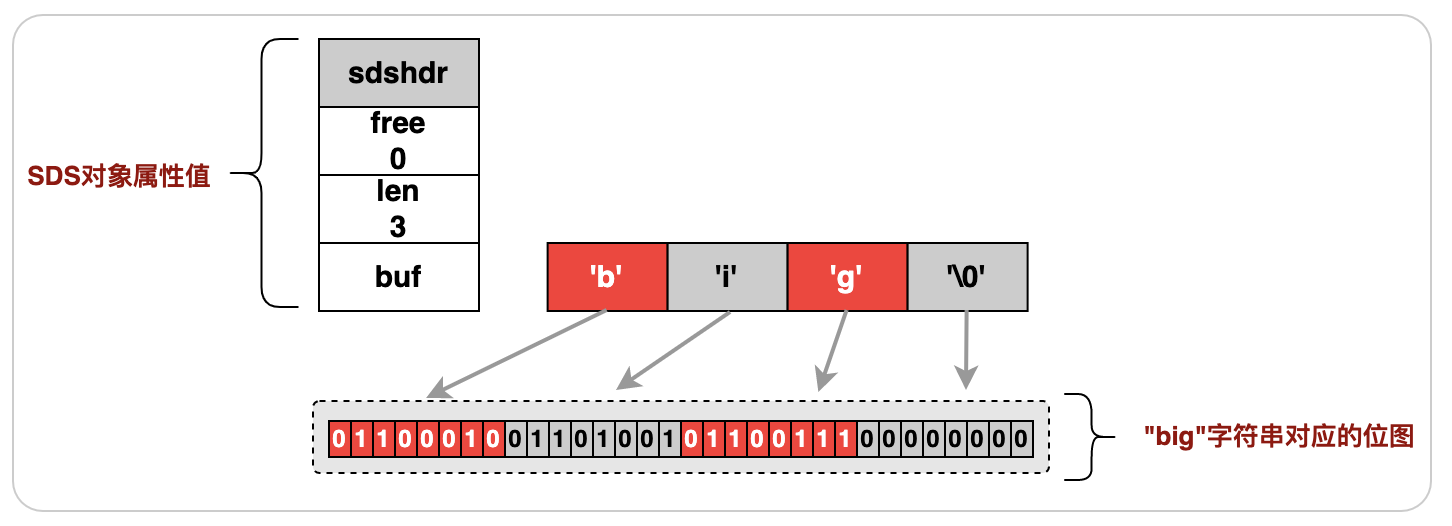
圖3.2.1“big”字串的SDS結構
SDS(簡單動態字串)為了保證性能采用了空間預分配的策略:空間預分配用于優化SDS的字串增長操作,SDS的API對一個SDS進行修改并且需要對SDS進行空間擴展的時候,程式不僅會為SDS分配修改所必須要的空間,還會為SDS分配額外的未使用空,具體預分配流程圖如下:
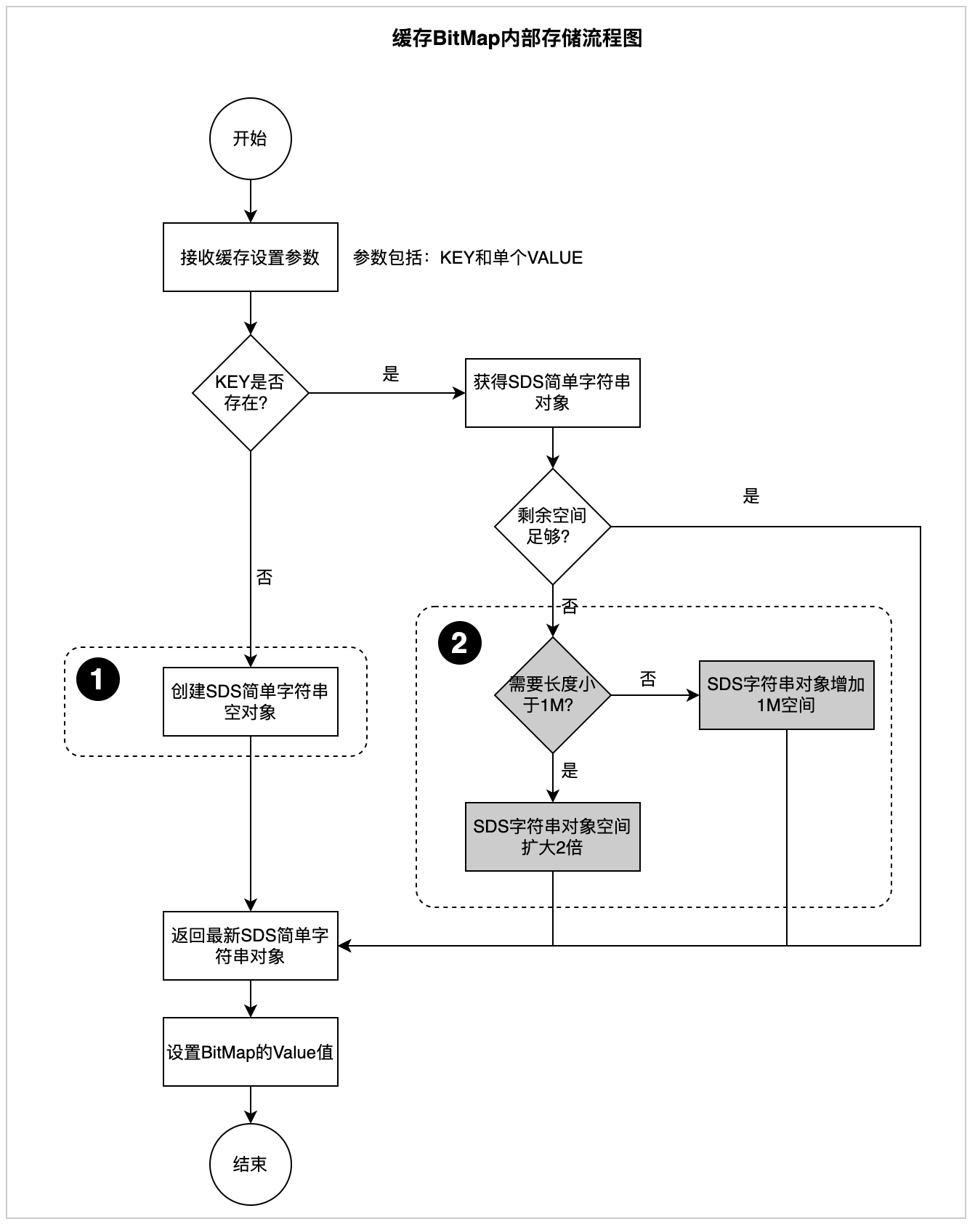
圖3.2.2SDS預分配流程圖
位置1:創建SDS簡單字串預分配空間為:偏移量/8+1,
位置2:剩余空間不足時,預分配空間流程,
3.3壓縮商品與車關系快取
| 偏移量(自增ID) | 全量車型 | 商品SKU |
|---|---|---|
| 1 | 1165788 | 101362 |
| 2 | 1165793 | 101362 |
商品適配車型關系(百億級資料量)
商品與車關系快取存盤程序中,采用了商品SKU作為KEY,全量車型ID的偏移量(采用偏移量是為降低記憶體消耗)作為VALUE值來進行存盤,
全量車型ID大約有幾十萬的資料量,極限情況下一個商品SKU可以適配幾十萬輛車,很容易造成快取大KEY的問題,為此我們進行了偏移量(全量車型ID對應的自增ID)的分段處理,具體是按照:SKU作為快取KEY的基礎上,追加一個分段標記數字作為新KEY,每個偏移量都會按照分段范圍對應一個分段標記數字,例如:偏移量1~50000,對應快取KEY為SKU+0;偏移量50001~100000,對應快取KEY為SKU+1,其它偏移量以此類推,這樣就保證了一個SKU即使適配所有車輛也不會出現快取大KEY的情況,
BitMap快取結構底層使用SDS簡單字串,為了保證性能采用了預分配空間的策略(圖3.2.2,“快取BitMap內部存盤流程圖”的“位置2”中虛線框圈選),這樣在快取商品與車關系的時候浪費了大量的快取空間,為此我們調整了偏移量存盤順序,首先獲取到需要快取的車型內最大的偏移量,保證同一個快取KEY第1次創建SDS簡單字串(圖3.2.2,“快取BitMap內部存盤流程圖”的“位置1”中虛線框圈選)后,不再進行第2次空間擴容,這樣來最大限度的提升快取利用率,起到壓縮空間目的,快取資料關系流程如下:
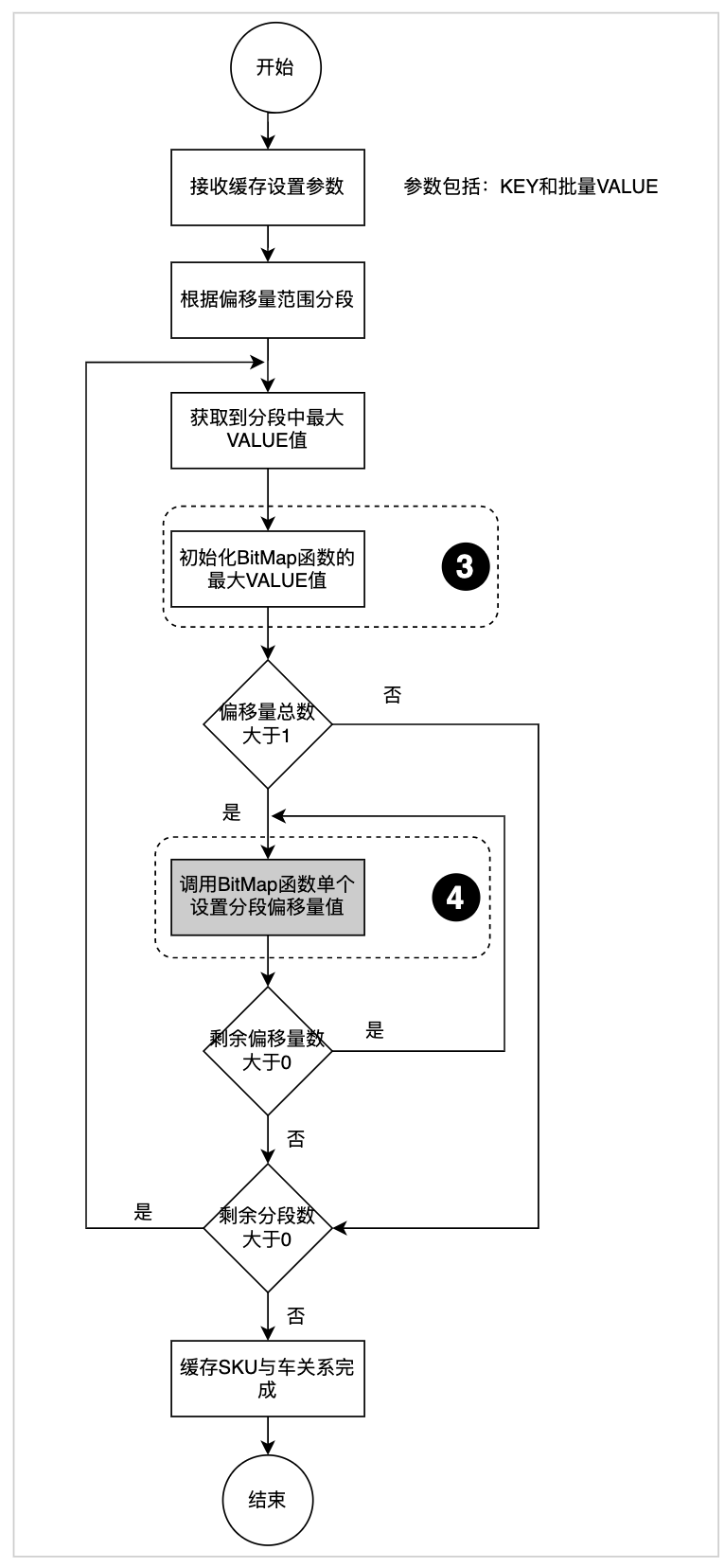
圖3.3.1快取資料關系流程
位置3:設定分段最大的偏移量,保證后續新增偏移量不再擴容空間,
位置4:設定分段較小的偏移量,
全量車型ID是定長7位的數字,如果用它作為偏移量將消耗記憶體巨大,所以采用對應自增ID作為偏移量,最終在bitmap快取的商品SKU與車的適配關系快取結構如下圖:
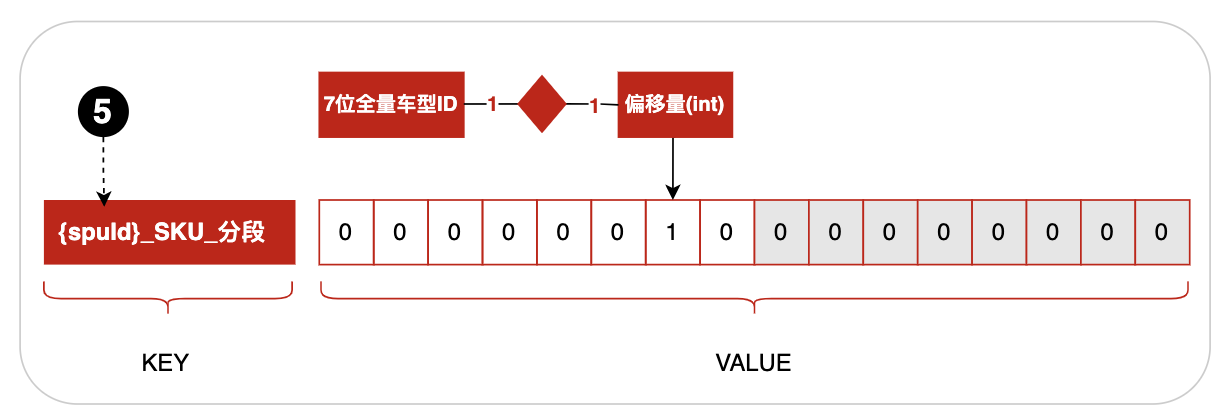
3.3.2商品與車快取結構圖
位置5:spuId用{}括起來表示快取路由(Lua腳本中同一次請求,資料必須在快取同一個分片上,否則會丟失資料),POP商品spuId是SKU的產品ID,自營商品spuId是SKU的MainSkuId,
備注:
1、自營商品MainSkuId可能發生變化,所以我們接入了商品變化MQ訊息,實時調整SKU與車適配關系的存盤位置,
2、京東商詳頁面中每個不同的規格/型號分別對應不同的SKU,但是它們都對應同一個SpuId或者MainSkuId,
4.快取架構設計
商品與車的關系資料量每天都在不斷增長,要求快取架構設計,需要支持集群橫向/縱向擴容和來滿足業務發展以及高可用性,整個快取架構體系主要有前端、京東養車商品與車關系層和存盤三部分組成,
“商品與車關系快取架構”層核心包括:1、“集群路由”層,實作了集群橫向擴容,保證資料量增漲的時候,快取容量也能跟上,2、“分片路由”層,保證搜索的底層資料的分片相同,避免資料丟失,
“存盤”層核心包括:1、實作了快取壓縮,參見3.3壓縮商品與車關系快取,2、單元化實作跨區域災備,保障大促系統穩定性,具體商品與車關系快取架構如下:
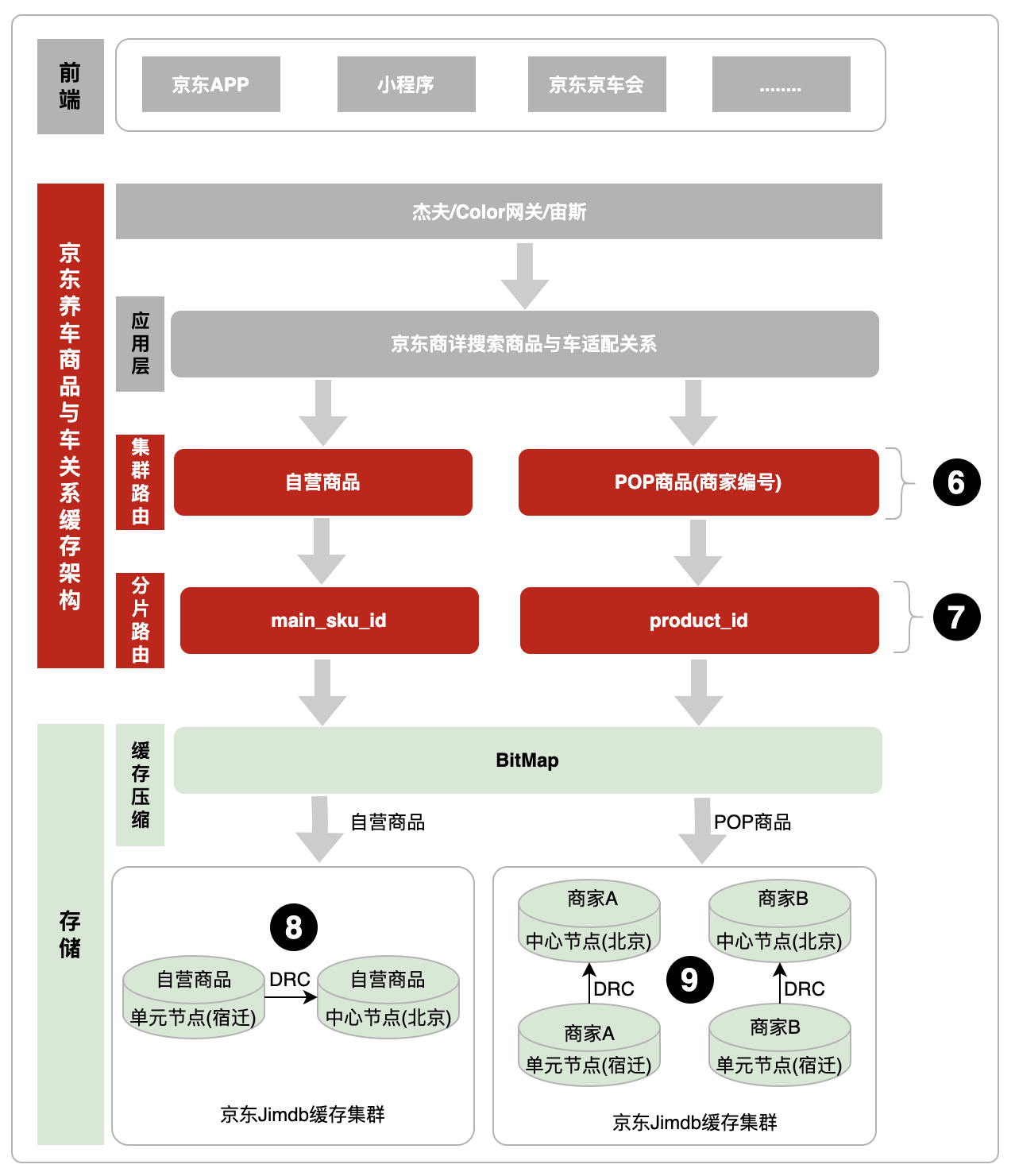
4.1商品與車關系快取架構圖
位置6:集群路由,通過商品型別或者商品編號(POP商品)路由到不同快取集群,便于橫向擴展,每個集群單分片限制,解決分片超過限制問題,
位置7:分片路由,保障Lua腳本搜索資料的底層資料集群分片相同,避免資料丟失,其中自營商品和POP商品的路由分別是main_sku_id和product_id,
位置8:自營商品快取集群,單元化實作跨區域災備,采用自研DRC(Data Replication Center)資料同步機制,
位置9:POP商品快取集群,通過商家編號拆分為兩個子集群,
5.高性能搜索
基于BitMap(位圖)快取的商品與車關系資料,商詳呼叫介面的內部實作采用了Lua腳本來降低網路開銷,保障整個介面的性能,以下是搜索介面的流程圖:
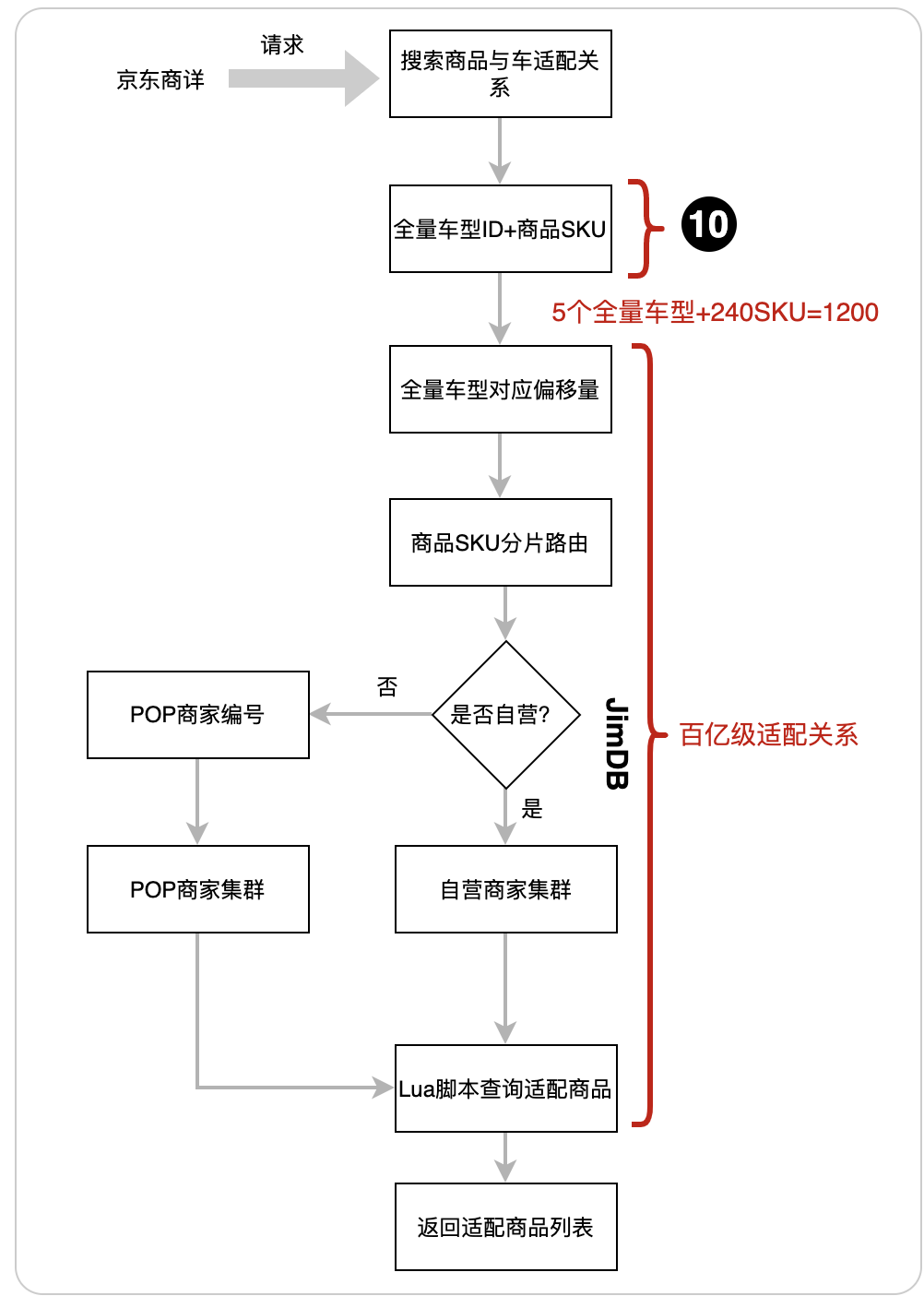
5.1商詳搜索商品與車適配關系流程圖
位置10:商詳呼叫介面的時候,要傳兩個引數,第1個引數是全量車型ID串列,大約5個全量車型ID,第2個引數是商品SKU串列,SKU的數量極限超過200個,最后全量車型ID與商品SKU組合為上千個商品與車的關系后,再到百億級適配關系去搜索看是否匹配的,如果不匹配回傳適配商品,反之則回傳不適配,
Lua腳本減少了應用服務器與快取服務器的互動,降低了網路開銷的時間,達到提升搜索服務的性能,以下是Lua腳本具體代碼:

5.2商詳搜索商品與車適配關系Lua代碼
基于以上快取設計和Lua腳本的使用,整個介面T999小于13ms,具體的介面性能監控如下圖:
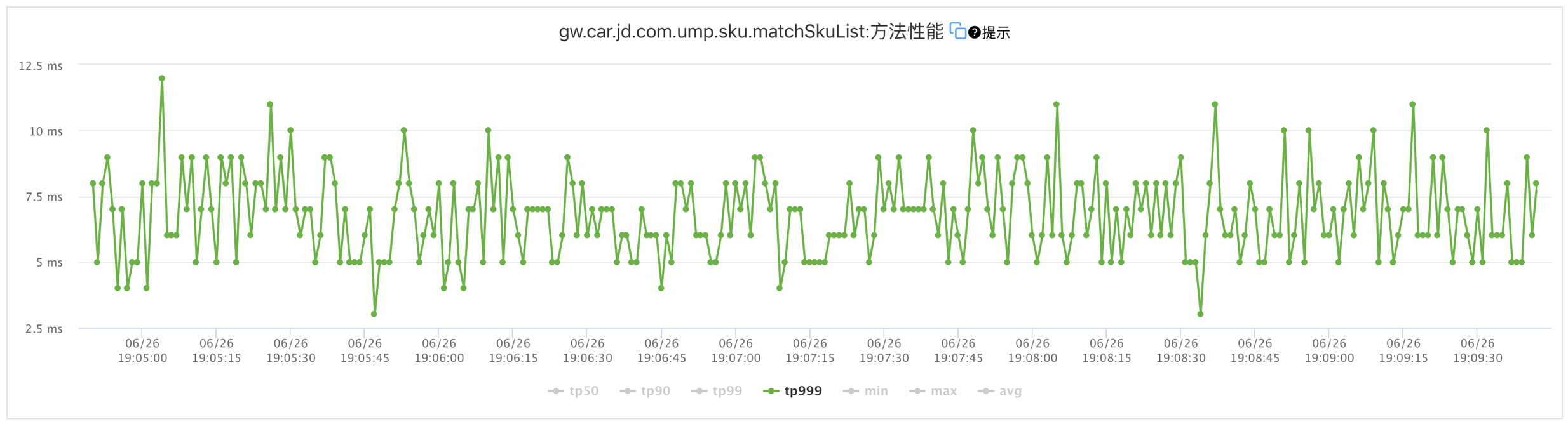
5.3商詳搜索商品與車適配關系介面性能
6.總結
整個快取結構設計的時候,使用BitMap(位圖)來存盤資料,決議SDS的內部存盤流程,通過存盤流程機制避開預分配空間節點,最大限度的利用快取空間,避免資源浪費,采用Lua腳本來實作資料的適配搜索,降低網路開銷,進一步提升介面的性能,希望此文對大家后續設計類似場景有一定的幫助和啟發,
作者:京東零售 張強
內容來源:京東云開發者社區
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/551965.html
標籤:架構設計
上一篇:git~分支管理規范
下一篇:返回列表