
引言
在探究 Kafka 核心知識之前,我們先思考一個問題:什么場景會促使我們使用 Kafka? 說到這里,我們頭腦中或多或少會蹦出異步解耦和削峰填谷等字樣,是的,這就是 Kafka 最重要的落地場景,
-
異步解耦:同步呼叫轉換成異步訊息通知,實作生產者和消費者的解耦,想象一個場景,在商品交易時,在訂單創建完成之后,需要觸發一系列其他的操作,比如進行用戶訂單資料的統計、給用戶發送短信、給用戶發送郵件等等,如果所有操作都采用同步方式實作,將嚴重影響系統性能,針對此場景,我們可以利用訊息中間件解耦訂單創建操作和其他后續行為,
-
削峰填谷:利用 broker 緩沖上游生產者瞬時突發的流量,使消費者消費流量整體平滑,對于發送能力很強的上游系統,如果沒有訊息中間件的保護,下游系統可能會直接被壓垮導致全鏈路服務雪崩,想象秒殺業務場景,上游業務發起下單請求,下游業務執行秒殺業務(庫存檢查,庫存凍結,余額凍結,生成訂單等等),下游業務處理的邏輯是相當復雜的,并發能力有限,如果上游服務不做限流策略,瞬時可能把下游服務壓垮,針對此場景,我們可以利用 MQ 來做削峰填谷,讓高峰流量填充低谷空閑資源,達到系統資源的合理利用,
通過上述例子可以發現交易、支付等場景常需要異步解耦和削峰填谷功能解決問題,而交易、支付等場景對性能、可靠性要求特別高,那么,我們本文的主角 Kafka 能否滿足相應要求呢?下面我們來探討下,
Kafka 宏觀認知
在探究 Kafka 的高性能、高可靠性之前,我們從宏觀上來看下 Kafka 的系統架構:
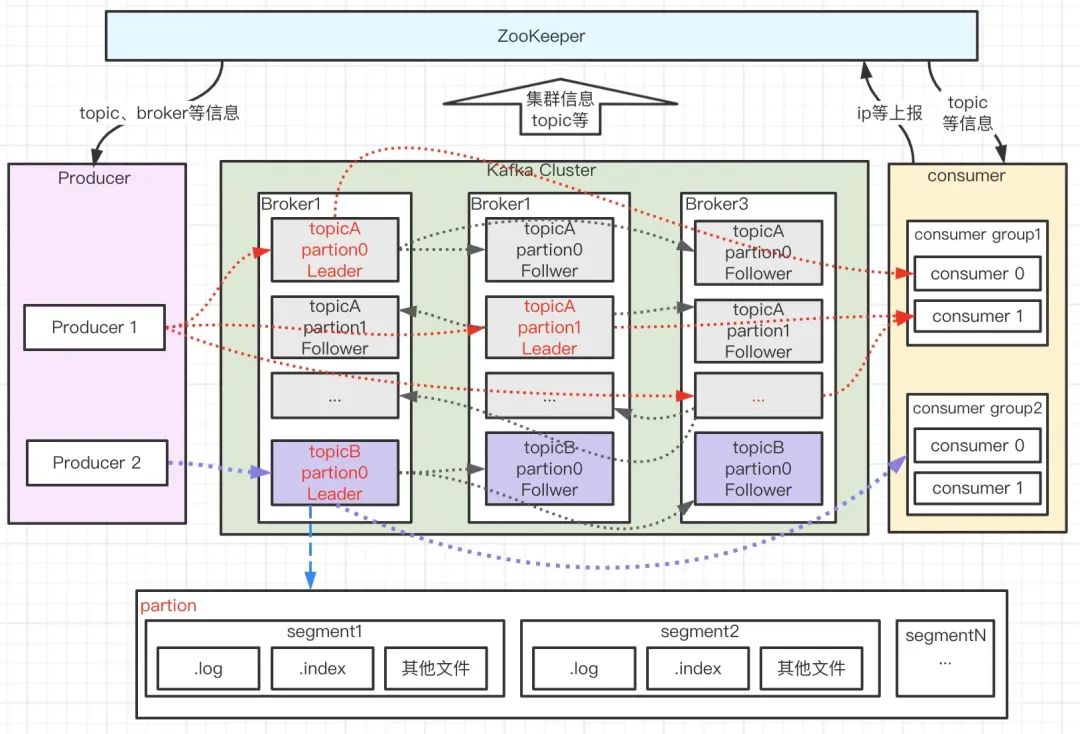
如上圖所示,Kafka 由 Producer、Broker、Consumer 以及負責集群管理的 ZooKeeper 組成,各部分功能如下:
-
Producer:生產者,負責訊息的創建并通過一定的路由策略發送訊息到合適的 Broker; -
Broker:服務實體,負責訊息的持久化、中轉等功能; -
Consumer :消費者,負責從 Broker 中拉取(Pull)訂閱的訊息并進行消費,通常多個消費者構成一個分組,訊息只能被同組中的一個消費者消費; -
ZooKeeper:負責 broker、consumer 集群元資料的管理等;(注意:Producer 端直接連接 broker,不在 zk 上存任何資料,只是通過 ZK 監聽 broker 和 topic 等資訊)
上圖訊息流轉程序中,還有幾個特別重要的概念—主題(Topic)、磁區(Partition)、分段(segment)、位移(offset),
-
topic:訊息主題,Kafka 按 topic 對訊息進行分類,我們在收發訊息時只需指定 topic, -
partition:磁區,為了提升系統的吞吐,一個 topic 下通常有多個 partition,partition 分布在不同的 Broker 上,用于存盤 topic 的訊息,這使 Kafka 可以在多臺機器上處理、存盤訊息,給 kafka 提供給了并行的訊息處理能力和橫向擴容能力,另外,為了提升系統的可靠性,partition 通常會分組,且每組有一個主 partition、多個副本 partition,且分布在不同的 broker 上,從而起到容災的作用, -
segment:分段,宏觀上看,一個 partition 對應一個日志(Log),由于生產者生產的訊息會不斷追加到 log 檔案末尾,為防止 log 檔案過大導致資料檢索效率低下,Kafka 采取了分段和索引機制,將每個 partition 分為多個 segment,同時也便于訊息的維護和清理,每個 segment 包含一個.log 日志檔案、兩個索引(.index、timeindex)檔案以及其他可能的檔案,每個 Segment 的資料檔案以該段中最小的 offset 為檔案名,當查找 offset 的 Message 的時候,通過二分查找快找到 Message 所處于的 Segment 中, -
offset:訊息在日志中的位置,訊息在被追加到磁區日志檔案的時候都會分配一個特定的偏移量,offset 是訊息在磁區中的唯一標識,是一個單調遞增且不變的值,Kafka 通過它來保證訊息在磁區內的順序性,不過 offset 并不跨越磁區,也就是說,Kafka 保證的是磁區有序而不是主題有序,
Kafka 高可靠性、高性能探究
在對 Kafka 的整體系統框架及相關概念簡單了解后,下面我們來進一步深入探討下高可靠性、高性能實作原理,
Kafka 高可靠性探究
Kafka 高可靠性的核心是保證訊息在傳遞程序中不丟失,涉及如下核心環節:
-
訊息從生產者可靠地發送至 Broker;-- 網路、本地丟資料; -
發送到 Broker 的訊息可靠持久化;-- Pagecache 快取落盤、單點崩潰、主從同步跨網路; -
消費者從 Broker 消費到訊息且最好只消費一次 -- 跨網路訊息傳輸 ,
訊息從生產者可靠地發送至 Broker
為了保障訊息從生產者可靠地發送至 Broker,我們需要確保兩點;
-
Producer 發送訊息后,能夠收到來自 Broker 的訊息保存成功 ack; -
Producer 發送訊息后,能夠捕獲超時、失敗 ack 等例外 ack 并做處理,
ack 策略
針對問題 1,Kafka 為我們提供了三種 ack 策略,
-
Request.required.acks = 0:請求發送即認為成功,不關心有沒有寫成功,常用于日志進行分析場景; -
Request.required.acks = 1:當 leader partition 寫入成功以后,才算寫入成功,有丟資料的可能; -
Request.required.acks= -1:ISR 串列里面的所有副本都寫完以后,這條訊息才算寫入成功,強可靠性保證;
為了實作強可靠的 kafka 系統,我們需要設定 Request.required.acks= -1,同時還會設定集群中處于正常同步狀態的副本 follower 數量 min.insync.replicas>2,另外,設定 unclean.leader.election.enable=false 使得集群中 ISR 的 follower 才可變成新的 leader,避免特殊情況下訊息截斷的出現,
訊息發送策略
針對問題 2,kafka 提供兩類訊息發送方式:同步(sync)發送和異步(async)發送,相關引數如下:

以 sarama 實作為例,在訊息發送的程序中,無論是同步發送還是異步發送都會涉及到兩個協程--負責訊息發送的主協程和負責訊息分發的 dispatcher 協程,
異步發送
對于異步發送(ack != 0 場景,等于 0 時不關心寫 kafka 結果,后文詳細講解)而言,其流程大概如下:
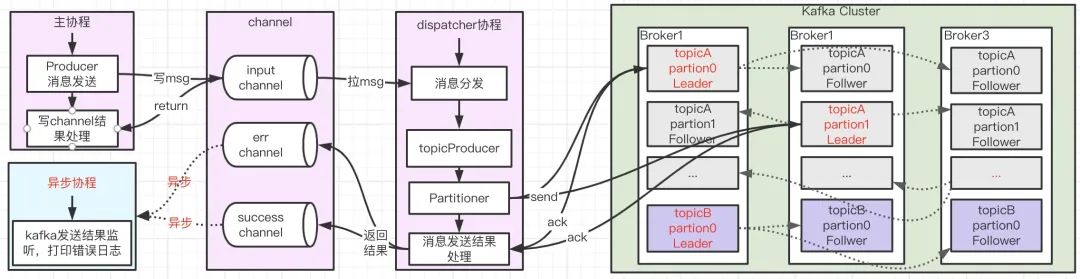
-
在主協程中呼叫異步發送 kafka 訊息的時候,其本質是將訊息體放進了一個 input 的 channel,只要入 channel 成功,則這個函式直接回傳,不會產生任何阻塞,相反,如果入 channel 失敗,則會回傳錯誤資訊,因此呼叫 async 寫入的時候回傳的錯誤資訊是入 channel 的錯誤資訊,至于具體最終訊息有沒有發送到 kafka 的 broker,我們無法從回傳值得知, -
當訊息進入 input 的 channel 后,會有另一個dispatcher 的協程負責遍歷 input,來真正發送訊息到特定 Broker 上的主 Partition 上,發送結果通過一個異步協程進行監聽,回圈處理 err channel 和 success channel,出現了 error 就記一個日志,因此異步寫入場景時,寫 kafka 的錯誤資訊,我們暫時僅能夠從這個錯誤日志來得知具體發生了什么錯,并且也不支持我們自建函式進行兜底處理,這一點在 trpc-go 的官方也得到了承認,
同步發送
同步發送(ack != 0 場景)是在異步發送的基礎上加以條件限制實作的,同步訊息發送在 newSyncProducerFromAsyncProducer 中開啟兩個異步協程處理訊息成功與失敗的“回呼”,并使用 waitGroup 進行等待,從而將異步操作轉變為同步操作,其流程大概如下:
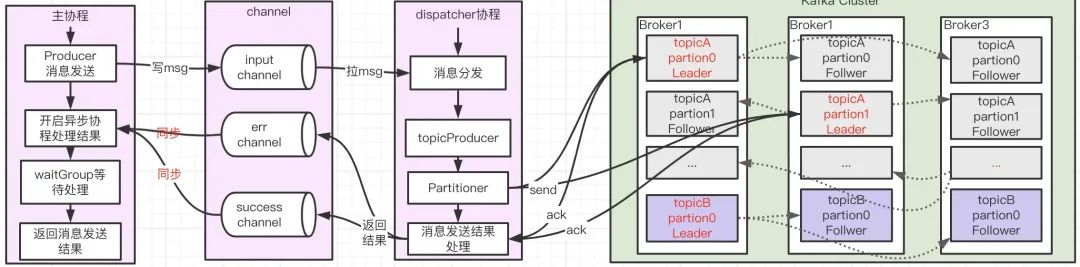
通過上述分析可以發現,kafka 訊息發送本質上都是異步的,不過同步發送通過 waitGroup 將異步操作轉變為同步操作,同步發送在一定程度上確保了我們在跨網路向 Broker 傳輸訊息時,訊息一定可以可靠地傳輸到 Broker,因為在同步發送場景我們可以明確感知訊息是否發送至 Broker,若因網路抖動、機器宕機等故障導致訊息發送失敗或結果不明,可通過重試等手段確保訊息至少一次(at least once) 發送到 Broker,另外,Kafka(0.11.0.0 版本后)還為 Producer 提供兩種機制來實作精確一次(exactly once) 訊息發送:冪等性(Idempotence)和事務(Transaction),
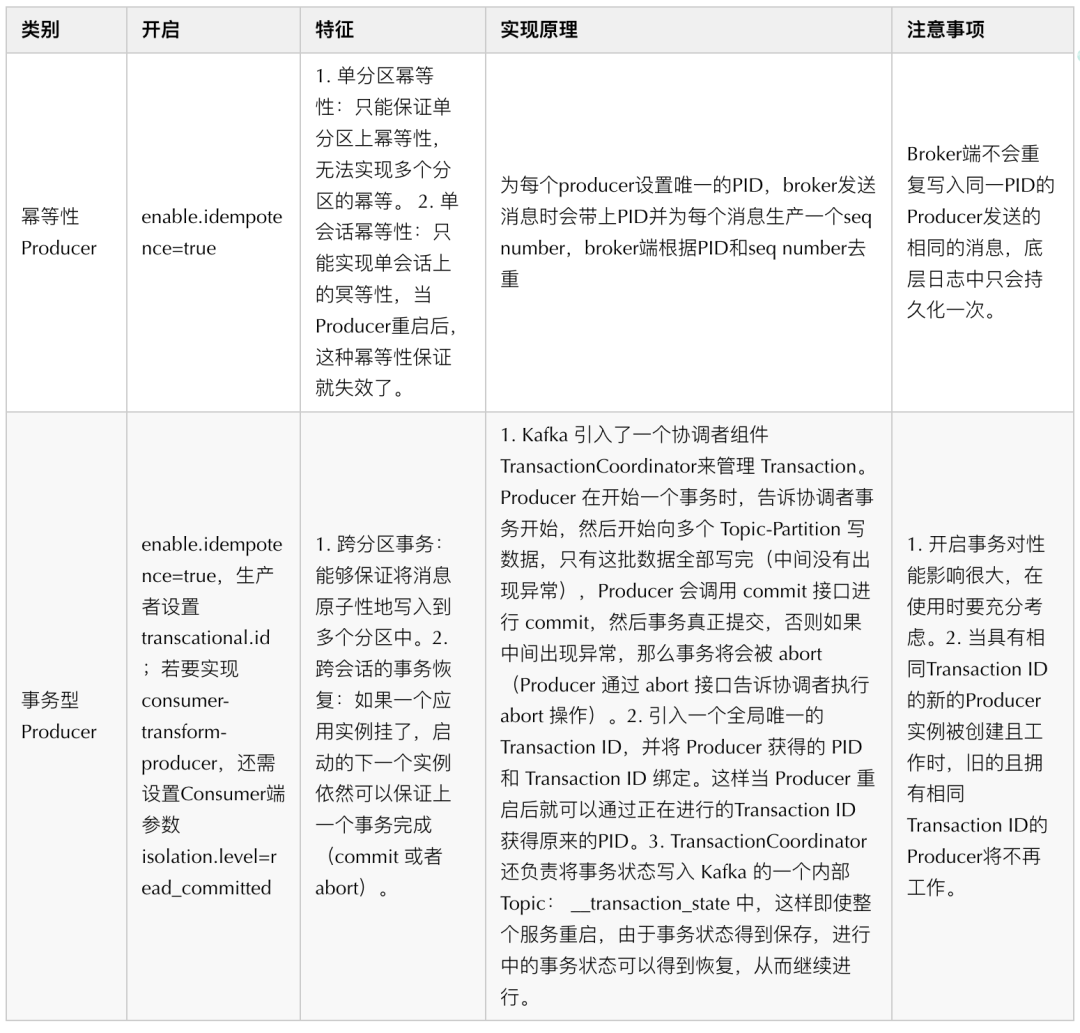
小結
通過 ack 策略配置、同步發送、事務訊息組合能力,我們可以實作exactly once 語意跨網路向 Broker 傳輸訊息,但是,Producer 收到 Broker 的成功 ack,訊息一定不會丟失嗎?為了搞清這個問題,我們首先要搞明白 Broker 在接收到訊息后做了哪些處理,
發送到 Broker 的訊息可靠持久化
為了確保 Producer 收到 Broker 的成功 ack 后,訊息一定不在 Broker 環節丟失,我們核心要關注以下幾點:
-
Broker 回傳 Producer 成功 ack 時,訊息是否已經落盤; -
Broker 宕機是否會導致資料丟失,容災機制是什么; -
Replica 副本機制帶來的多副本間資料同步一致性問題如何解決;
Broker 異步刷盤機制
kafka 為了獲得更高吞吐,Broker 接收到訊息后只是將資料寫入 PageCache 后便認為訊息已寫入成功,而 PageCache 中的資料通過 linux 的 flusher 程式進行異步刷盤(刷盤觸發條:主動呼叫 sync 或 fsync 函式、可用記憶體低于閥值、dirty data 時間達到閥值),將資料順序寫到磁盤,訊息處理示意圖如下:
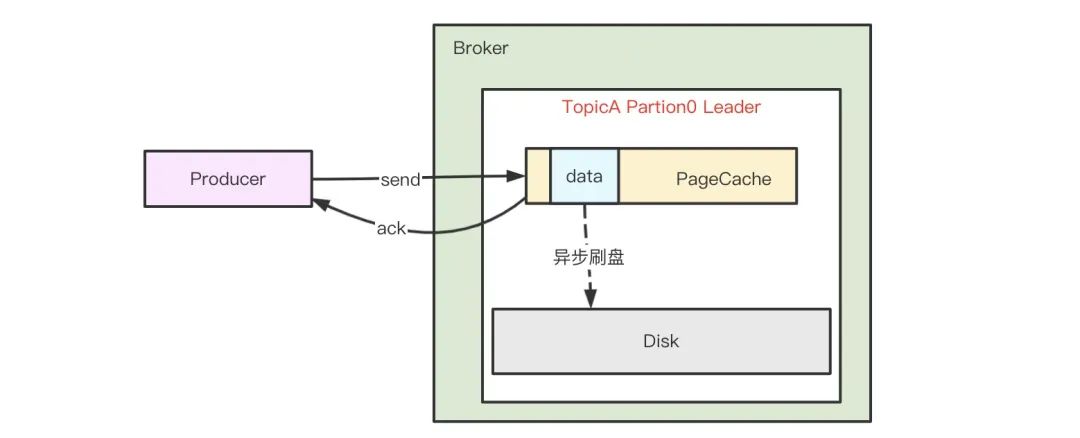
由于訊息是寫入到 pageCache,單機場景,如果還沒刷盤 Broker 就宕機了,那么 Producer 產生的這部分資料就可能丟失,為了解決單機故障可能帶來的資料丟失問題,Kafka 為磁區引入了副本機制,
Replica 副本機制
Kafka 每組磁區通常有多個副本,同組磁區的不同副本分布在不同的 Broker 上,保存相同的訊息(可能有滯后),副本之間是“一主多從”的關系,其中 leader 副本負責處理讀寫請求,follower 副本負責從 leader 拉取訊息進行同步,磁區的所有副本統稱為 AR(Assigned Replicas),其中所有與 leader 副本保持一定同步的副本(包括 leader 副本在內)組成 ISR(In-Sync Replicas),與 leader 同步滯后過多的副本組成 OSR(Out-of-Sync Replicas),由此可見,AR=ISR+OSR,
follower 副本是否與 leader 同步的判斷標準取決于 Broker 端引數 replica.lag.time.max.ms(默認為 10 秒),follower 默認每隔 500ms 向 leader fetch 一次資料,只要一個 Follower 副本落后 Leader 副本的時間不連續超過 10 秒,那么 Kafka 就認為該 Follower 副本與 leader 是同步的,在正常情況下,所有的 follower 副本都應該與 leader 副本保持一定程度的同步,即 AR=ISR,OSR 集合為空,
當 leader 副本所在 Broker 宕機時,Kafka 會借助 ZK 從 follower 副本中選舉新的 leader 繼續對外提供服務,實作故障的自動轉移,保證服務可用,為了使選舉的新 leader 和舊 leader 資料盡可能一致,當 leader 副本發生故障時,默認情況下只有在 ISR 集合中的副本才有資格被選舉為新的 leader,而在 OSR 集合中的副本則沒有任何機會(可通過設定 unclean.leader.election.enable 改變),
當 Kafka 通過多副本機制解決單機故障問題時,同時也帶來了多副本間資料同步一致性問題,Kafka 通過高水位更新機制、副本同步機制、 Leader Epoch 等多種措施解決了多副本間資料同步一致性問題,下面我們來依次看下這幾大措施,
HW 和 LEO
首先,我們來看下兩個和 Kafka 中日志相關的重要概念 HW 和 LEO:
-
HW: High Watermark,高水位,表示已經提交(commit)的最大日志偏移量,Kafka 中某條日志“已提交”的意思是 ISR 中所有節點都包含了此條日志,并且消費者只能消費 HW 之前的資料; -
LEO: Log End Offset,表示當前 log 檔案中下一條待寫入訊息的 offset; 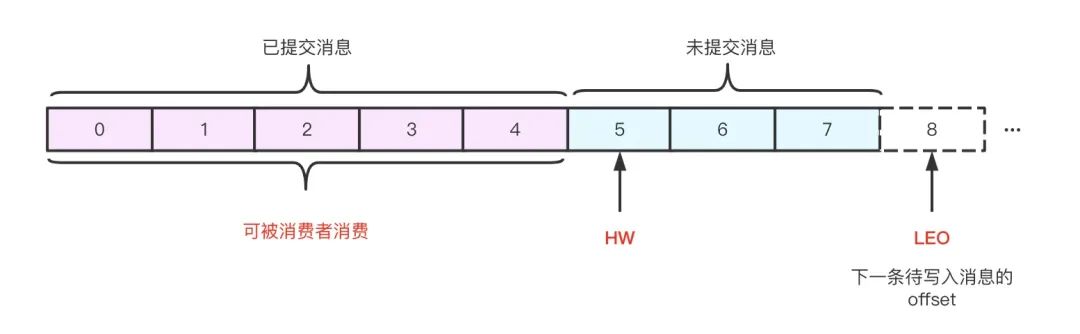
如上圖所示,它代表一個日志檔案,這個日志檔案中有 8 條訊息,0 至 5 之間的訊息為已提交訊息,5 至 7 的訊息為未提交訊息,日志檔案的 HW 為 6,表示消費者只能拉取到 5 之前的訊息,而 offset 為 5 的訊息對消費者而言是不可見的,日志檔案的 LEO 為 8,下一條訊息將在此處寫入,
注意:所有副本都有對應的 HW 和 LEO,只不過 Leader 副本比較特殊,Kafka 使用 Leader 副本的高水位來定義所在磁區的高水位,換句話說,磁區的高水位就是其 Leader 副本的高水位,Leader 副本和 Follower 副本的 HW 有如下特點:
-
Leader HW:min(所有副本 LEO),為此 Leader 副本不僅要保存自己的 HW 和 LEO,還要保存 follower 副本的 HW 和 LEO,而 follower 副本只需保存自己的 HW 和 LEO; -
Follower HW:min(follower 自身 LEO,leader HW),
注意:為方便描述,下面Leader HW簡記為HWL,Follower HW簡記為F,Leader LEO簡記為LEOL ,Follower LEO簡記為LEOF,
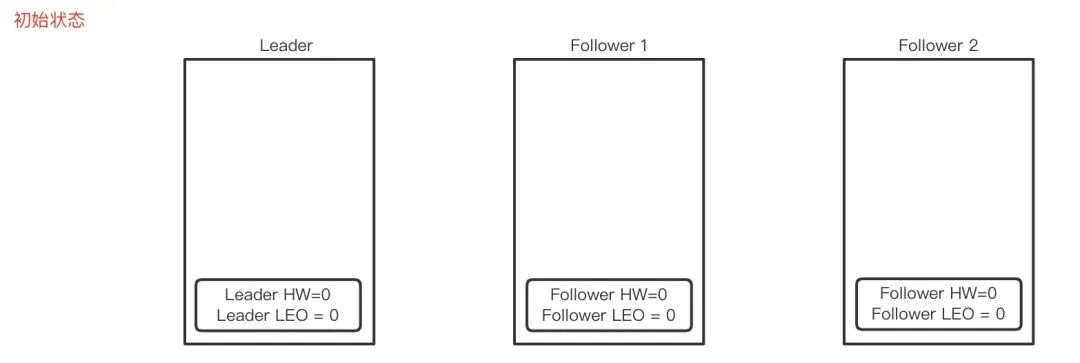
下面我們演示一次完整的 HW / LEO 更新流程:
-
初始狀態
HWL=0,LEOL=0,HWF=0,LEOF=0,
-
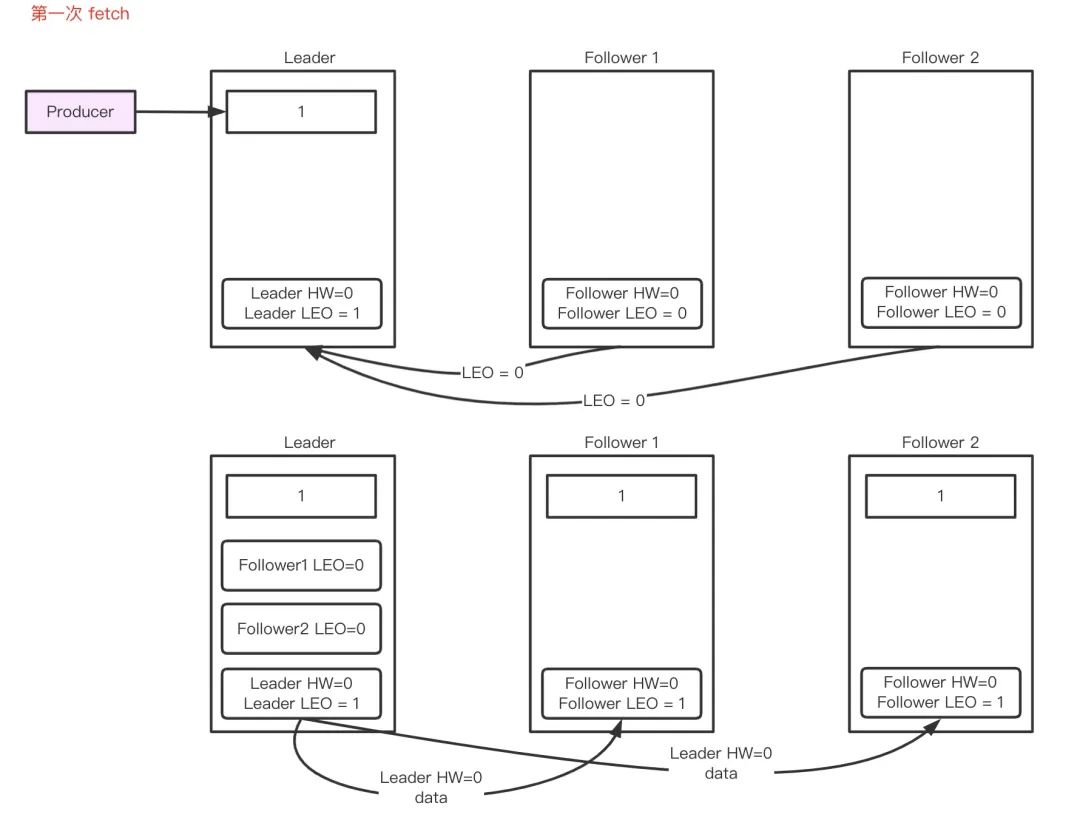
Follower 第一次 fetch
-
Leader收到Producer發來的一條訊息完成存盤, 更新LEOL=1; -
Follower從Leader fetch資料, Leader收到請求,記錄follower的LEOF =0,并且嘗試更新HWL =min(全部副本LEO)=0; -
eade回傳HWL=0和LEOL=1給Follower,Follower存盤訊息并更新LEOF =1, HW=min(LEOF,HWL)=0,
-
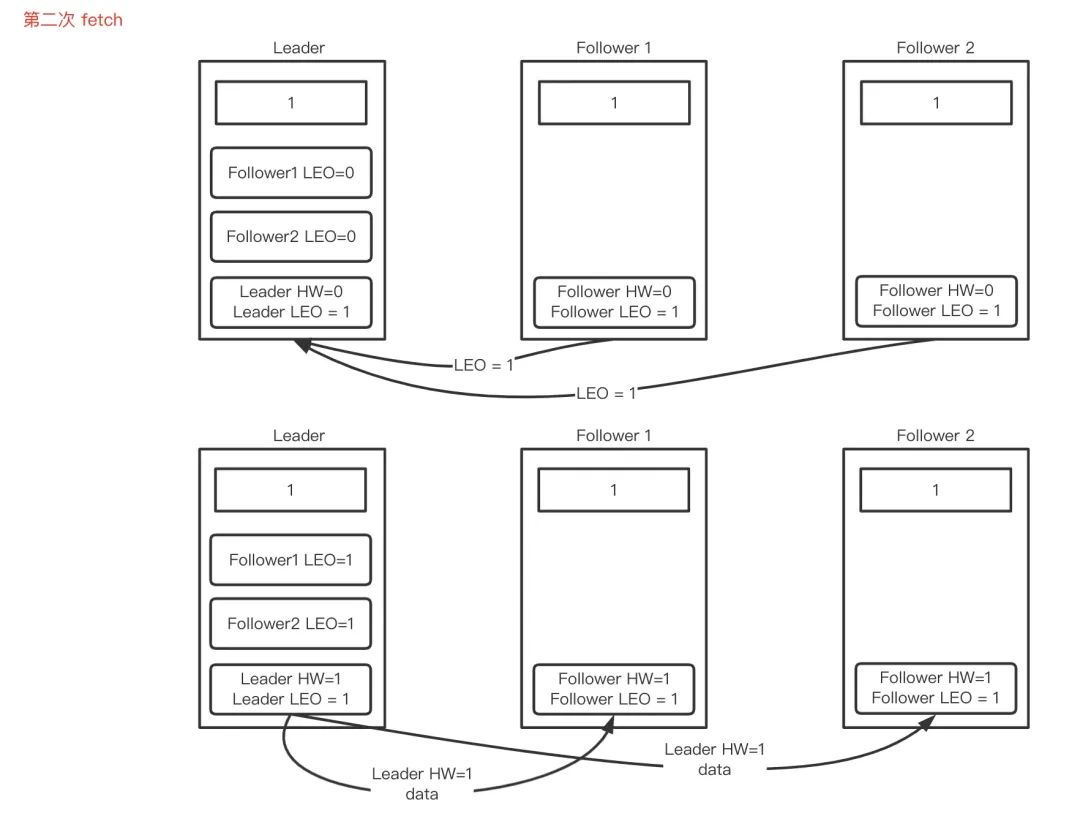
Follower 第二次 fetch
-
Follower再次從Leader fetch資料, Leader收到請求,記錄follower的LEOF =1,并且嘗試更新HWL =min(全部副本LEO)=1;
-
leade回傳HWL=1和LEOL=1給Follower,Leader收到請求,更新自己的 HW=min(LEOF,HWL)=1,
上述更新流程中 Follower 和 Leader 的 HW 更新有時間 GAP,如果 Leader 節點在此期間發生故障,則 Follower 的 HW 和 Leader 的 HW 可能會處于不一致狀態,如果 Followe 被選為新的 Leader 并且以自己的 HW 為準對外提供服務,則可能帶來資料丟失或資料錯亂問題,
KIP-101 問題:資料丟失&資料錯亂 ^參 5^
資料丟失
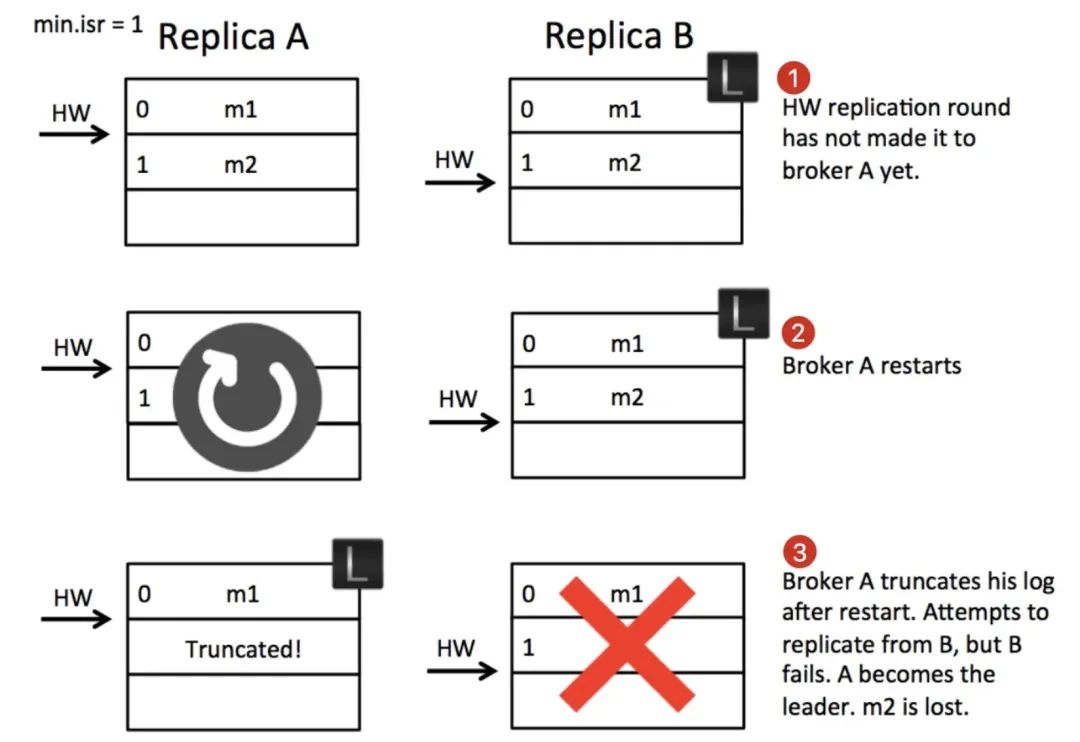
第 1 步:
-
副本 B 作為 leader 收到 producer 的 m2 訊息并寫入本地檔案,等待副本 A 拉取, -
副本 A 發起訊息拉取請求,請求中攜帶自己的最新的日志 offset(LEO=1),B 收到后更新自己的 HW 為 1,并將 HW=1 的資訊以及訊息 m2 回傳給 A, -
A 收到拉取結果后更新本地的 HW 為 1,并將 m2 寫入本地檔案,發起新一輪拉取請求(LEO=2),B 收到 A 拉取請求后更新自己的 HW 為 2,沒有新資料只將 HW=2 的資訊回傳給 A,并且回復給 producer 寫入成功,此處的狀態就是圖中第一步的狀態,
第 2 步:
此時,如果沒有例外,A 會收到 B 的回復,得知目前的 HW 為 2,然后更新自身的 HW 為 2,但在此時 A 重啟了,沒有來得及收到 B 的回復,此時 B 仍然是 leader,A 重啟之后會以 HW 為標準截斷自己的日志,因為 A 作為 follower 不知道多出的日志是否是被提交過的,防止資料不一致從而截斷多余的資料并嘗試從 leader 那里重新同步,
第 3 步:
B 崩潰了,min.isr 設定的是 1,所以 zookeeper 會從 ISR 中再選擇一個作為 leader,也就是 A,但是 A 的資料不是完整的,從而出現了資料丟失現象,
問題在哪里?在于 A 重啟之后以 HW 為標準截斷了多余的日志,不截斷行不行?不行,因為這個日志可能沒被提交過(也就是沒有被 ISR 中的所有節點寫入過),如果保留會導致日志錯亂,
資料錯亂
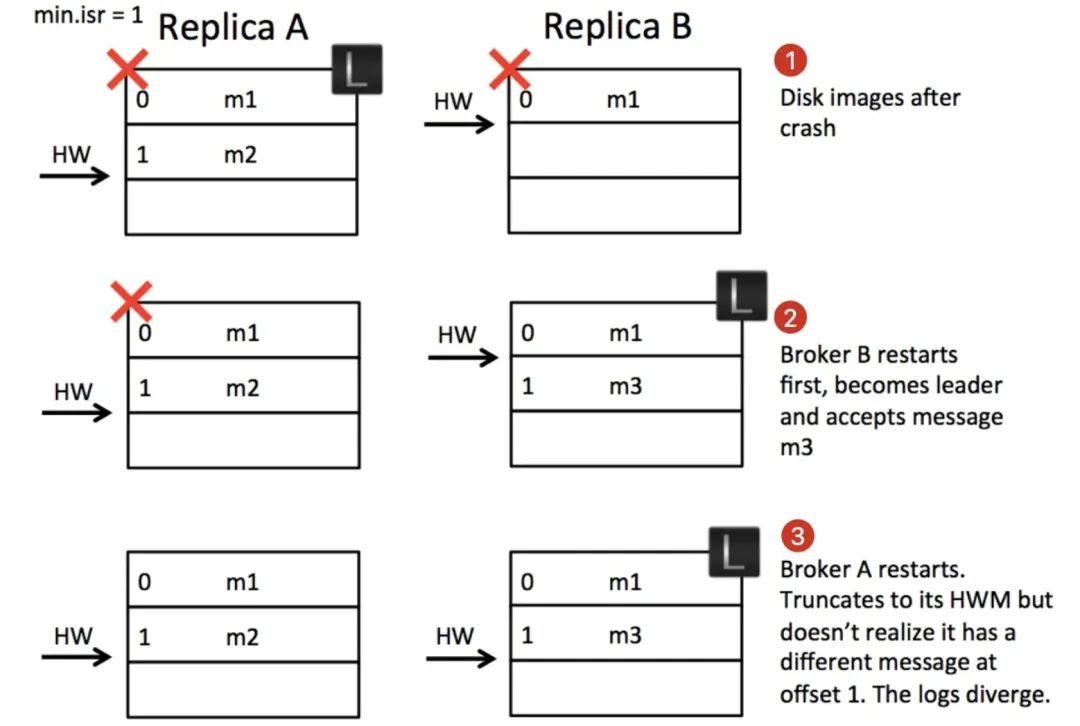
在分析日志錯亂的問題之前,我們需要了解到 kafka 的副本可靠性保證有一個前提:在 ISR 中至少有一個節點,如果節點均宕機的情況下,是不保證可靠性的,在這種情況會出現資料丟失,資料丟失是可接受的,這里我們分析的問題比資料丟失更加槽糕,會引發日志錯亂甚至導致整個系統例外,而這是不可接受的,
第 1 步:
-
A 和 B 均為 ISR 中的節點,副本 A 作為 leader,收到 producer 的訊息 m2 的請求后寫入 PageCache 并在某個時刻重繪到本地磁盤, -
副本 B 拉取到 m2 后寫入 PageCage 后(尚未刷盤)再次去 A 中拉取新訊息并告知 A 自己的 LEO=2,A 收到更新自己的 HW 為 1 并回復給 producer 成功, -
此時 A 和 B 同時宕機,B 的 m2 由于尚未刷盤,所以 m2 訊息丟失,此時的狀態就是第 1 步的狀態,
第 2 步:
由于 A 和 B 均宕機,而 min.isr=1 并且 unclean.leader.election.enable=true(關閉 unclean 選擇策略),所以 Kafka 會等到第一個 ISR 中的節點恢復并選為 leader,這里不幸的是 B 被選為 leader,而且還接收到 producer 發來的新訊息 m3,注意,這里丟失 m2 訊息是可接受的,畢竟所有節點都宕機了,
第 3 步:
A 恢復重啟后發現自己是 follower,而且 HW 為 2,并沒有多余的資料需要截斷,所以開始和 B 進行新一輪的同步,但此時 A 和 B 均沒有意識到,offset 為 1 的訊息不一致了,
問題在哪里?在于日志的寫入是異步的,上面也提到 Kafka 的副本策略的一個設計是訊息的持久化是異步的,這就會導致在場景二的情況下被選出的 leader 不一定包含所有資料,從而引發日志錯亂的問題,
Leader Epoch
為了解決上述缺陷,Kafka 引入了 Leader Epoch 的概念,leader epoch 和 raft 中的任期號的概念很類似,每次重新選擇 leader 的時候,用一個嚴格單調遞增的 id 來標志,可以讓所有 follower 意識到 leader 的變化,而 follower 也不再以 HW 為準,每次奔潰重啟后都需要去 leader 那邊確認下當前 leader 的日志是從哪個 offset 開始的,下面看下 Leader Epoch 是如何解決上面兩個問題的,
資料丟失解決
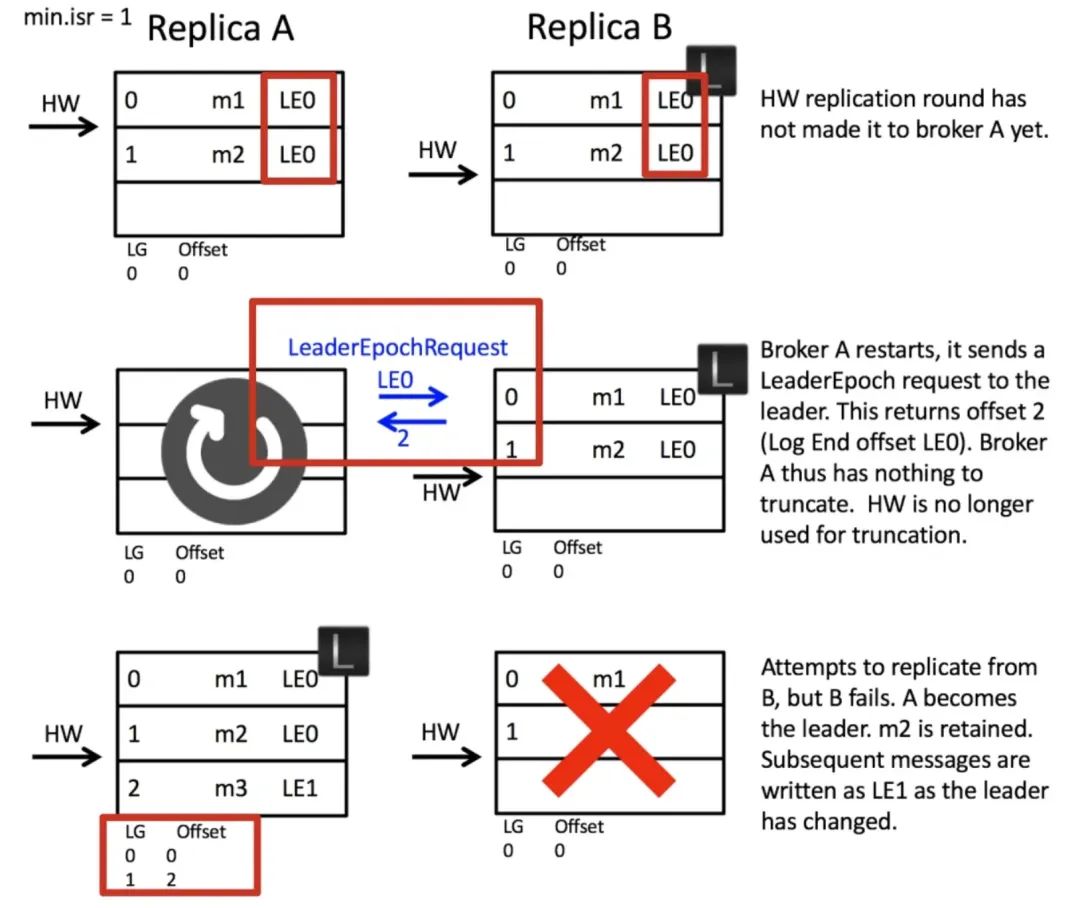
這里的關鍵點在于副本 A 重啟后作為 follower,不是忙著以 HW 為準截斷自己的日志,而是先發起 LeaderEpochRequest 詢問副本 B 第 0 代的最新的偏移量是多少,副本 B 會回傳自己的 LEO 為 2 給副本 A,A 此時就知道訊息 m2 不能被截斷,所以 m2 得到了保留,當 A 選為 leader 的時候就保留了所有已提交的日志,日志丟失的問題得到解決,
如果發起 LeaderEpochRequest 的時候就已經掛了怎么辦?這種場景下,不會出現日志丟失,因為副本 A 被選為 leader 后不會截斷自己的日志,日志截斷只會發生在 follower 身上,
資料錯亂解決
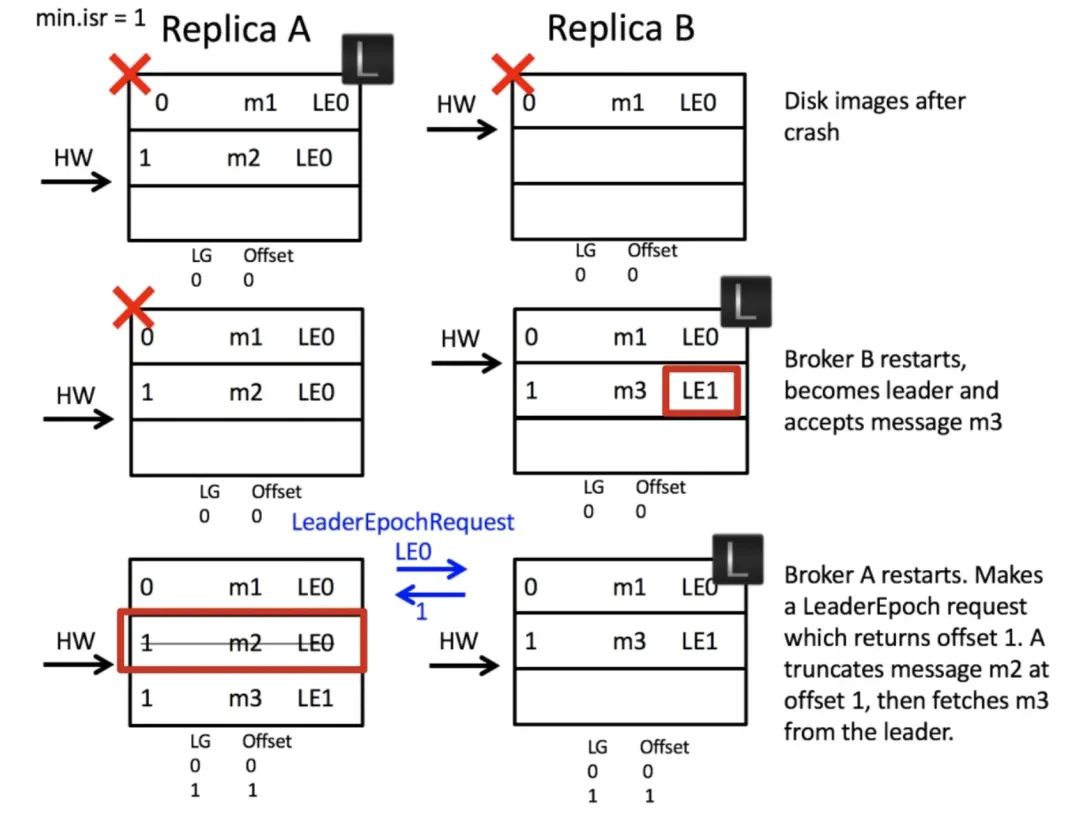
這里的關鍵點還是在第 3 步,副本 A 重啟作為 follower 的第一步還是需要發起 LeaderEpochRequest 詢問 leader 當前第 0 代最新的偏移量是多少,由于副本 B 已經經過換代,所以會回傳給 A 第 1 代的起始偏移(也就是 1),A 發現沖突后會截斷自己偏移量為 1 的日志,并重新開始和 leader 同步,副本 A 和副本 B 的日志達到了一致,解決了日志錯亂,
小結
Broker 接收到訊息后只是將資料寫入 PageCache 后便認為訊息已寫入成功,但是,通過副本機制并結合 ACK 策略可以大概率規避單機宕機帶來的資料丟失問題,并通過 HW、副本同步機制、 Leader Epoch 等多種措施解決了多副本間資料同步一致性問題,最終實作了 Broker 資料的可靠持久化,
消費者從 Broker 消費到訊息且最好只消費一次
Consumer 在消費訊息的程序中需要向 Kafka 匯報自己的位移資料,只有當 Consumer 向 Kafka 匯報了訊息位移,該條訊息才會被 Broker 認為已經被消費,因此,Consumer 端訊息的可靠性主要和 offset 提交方式有關,Kafka 消費端提供了兩種訊息提交方式:
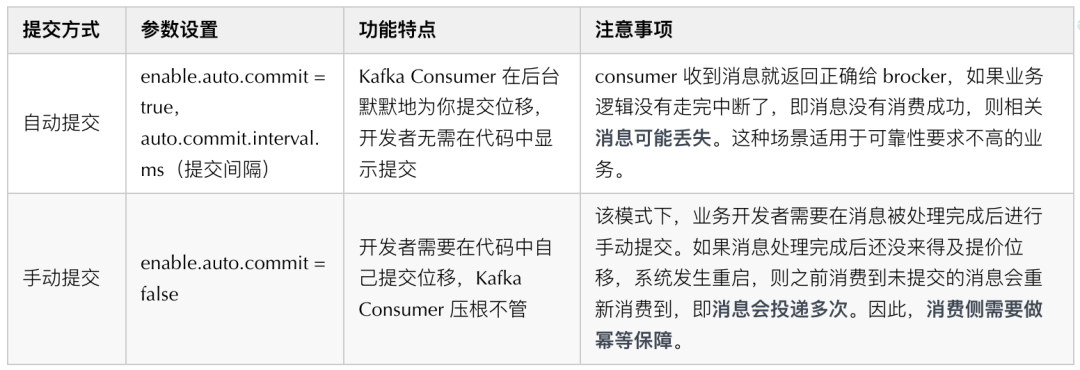
正常情況下我們很難實作 exactly once 語意的訊息,通常是通過手動提交+冪等實作訊息的可靠消費,
Kafka 高性能探究
Kafka 高性能的核心是保障系統低延遲、高吞吐地處理訊息,為此,Kafaka 采用了許多精妙的設計:
-
異步發送 -
批量發送 -
壓縮技術 -
Pagecache 機制&順序追加落盤 -
零拷貝 -
稀疏索引 -
broker & 資料磁區 -
多 reactor 多執行緒網路模型
異步發送
如上文所述,Kafka 提供了異步和同步兩種訊息發送方式,在異步發送中,整個流程都是異步的,呼叫異步發送方法后,訊息會被寫入 channel,然后立即回傳成功,Dispatcher 協程會從 channel 輪詢訊息,將其發送到 Broker,同時會有另一個異步協程負責處理 Broker 回傳的結果,同步發送本質上也是異步的,但是在處理結果時,同步發送通過 waitGroup 將異步操作轉換為同步,使用異步發送可以最大化提高訊息發送的吞吐能力,
批量發送
Kafka 支持批量發送訊息,將多個訊息打包成一個批次進行發送,從而減少網路傳輸的開銷,提高網路傳輸的效率和吞吐量,Kafka 的批量發送訊息是通過以下兩個引數來控制的:
-
batch.size:控制批量發送訊息的大小,默認值為 16KB,可適當增加 batch.size 引數值提升吞吐,但是,需要注意的是,如果批量發送的大小設定得過大,可能會導致訊息發送的延遲增加,因此需要根據實際情況進行調整, -
linger.ms:控制訊息在批量發送前的等待時間,默認值為 0,當 linger.ms 大于 0 時,如果有訊息發送,Kafka 會等待指定的時間,如果等待時間到達或者批量大小達到 batch.size,就會將訊息打包成一個批次進行發送,可適當增加 linger.ms 引數值提升吞吐,比如 10 ~ 100,
在 Kafka 的生產者客戶端中,當發送訊息時,如果啟用了批量發送,Kafka 會將訊息快取到緩沖區中,當緩沖區中的訊息大小達到 batch.size 或者等待時間到達 linger.ms 時,Kafka 會將緩沖區中的訊息打包成一個批次進行發送,如果在等待時間內沒有達到 batch.size,Kafka 也會將緩沖區中的訊息發送出去,從而避免訊息積壓,
壓縮技術
Kafka 支持壓縮技術,通過將訊息進行壓縮后再進行傳輸,從而減少網路傳輸的開銷(壓縮和解壓縮的程序會消耗一定的 CPU 資源,因此需要根據實際情況進行調整,),提高網路傳輸的效率和吞吐量,Kafka 支持多種壓縮演算法,在 Kafka2.1.0 版本之前,僅支持 GZIP,Snappy 和 LZ4,2.1.0 后還支持 Zstandard 演算法(Facebook 開源,能夠提供超高壓縮比),這些壓縮演算法性能對比(兩指標都是越高越好)如下:
-
吞吐量:LZ4>Snappy>zstd 和 GZIP,壓縮比:zstd>LZ4>GZIP>Snappy,
在 Kafka 中,壓縮技術是通過以下兩個引數來控制的:
-
compression.type:控制壓縮演算法的型別,默認值為 none,表示不進行壓縮, -
compression.level:控制壓縮的級別,取值范圍為 0-9,默認值為-1,當值為-1 時,表示使用默認的壓縮級別,
在 Kafka 的生產者客戶端中,當發送訊息時,如果啟用了壓縮技術,Kafka 會將訊息進行壓縮后再進行傳輸,在消費者客戶端中,如果訊息進行了壓縮,Kafka 會在消費訊息時將其解壓縮,注意:Broker 如果設定了和生產者不通的壓縮演算法,接收訊息后會解壓后重新壓縮保存,Broker 如果存在訊息版本兼容也會觸發解壓后再壓縮,
Pagecache 機制&順序追加落盤
kafka 為了提升系統吞吐、降低時延,Broker 接收到訊息后只是將資料寫入PageCache后便認為訊息已寫入成功,而 PageCache 中的資料通過 linux 的 flusher 程式進行異步刷盤(避免了同步刷盤的巨大系統開銷),將資料順序追加寫到磁盤日志檔案中,由于 pagecache 是在記憶體中進行快取,因此讀寫速度非常快,可以大大提高讀寫效率,順序追加寫充分利用順序 I/O 寫操作,避免了緩慢的隨機 I/O 操作,可有效提升 Kafka 吞吐,
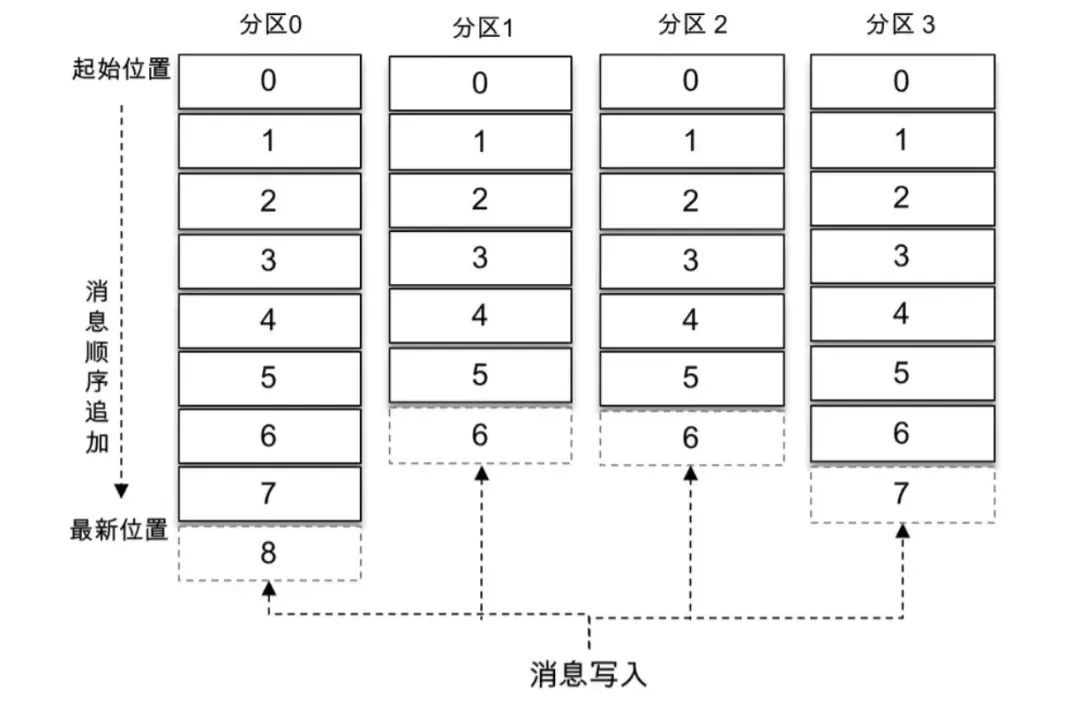
如上圖所示,訊息被順序追加到每個磁區日志檔案的尾部,
零拷貝
Kafka 中存在大量的網路資料持久化到磁盤(Producer 到 Broker)和磁盤檔案通過網路發送(Broker 到 Consumer)的程序,這一程序的性能直接影響 Kafka 的整體吞吐量,傳統的 IO 操作存在多次資料拷貝和背景關系切換,性能比較低,Kafka 利用零拷貝技術提升上述程序性能,其中網路資料持久化磁盤主要用 mmap 技術,網路資料傳輸環節主要使用 sendfile 技術,
索引加速之 mmap
傳統模式下,資料從網路傳輸到檔案需要 4 次資料拷貝、4 次背景關系切換和兩次系統呼叫,如下圖所示:
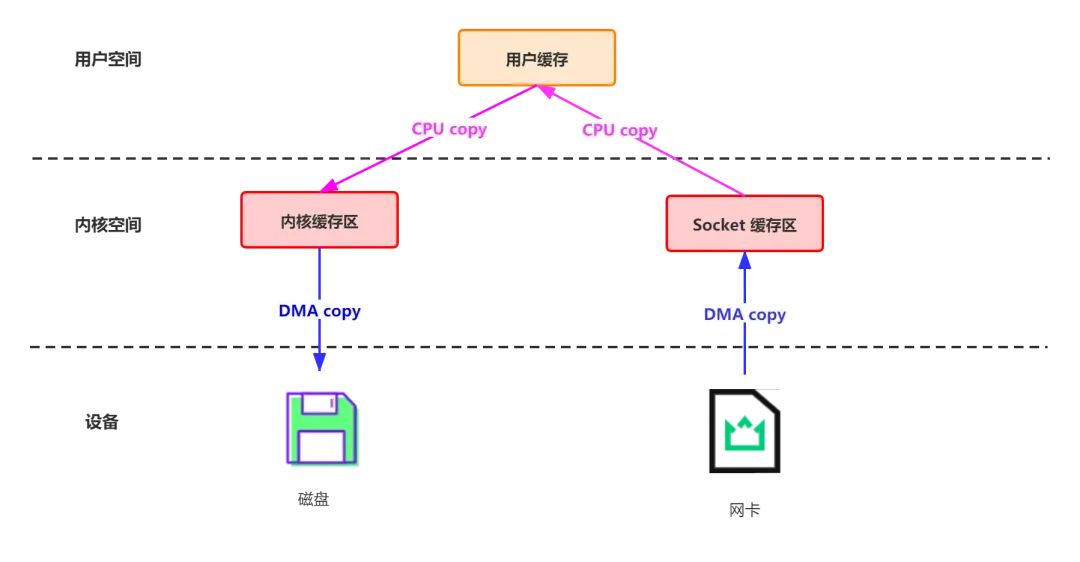
為了減少背景關系切換以及資料拷貝帶來的性能開銷,Kafka使用mmap來處理其索引檔案,Kafka中的索引檔案用于在提取日志檔案中的訊息時進行高效查找,這些索引檔案被維護為記憶體映射檔案,這允許Kafka快速訪問和搜索記憶體中的索引,從而加速在日志檔案中定位訊息的程序,mmap 將內核中讀緩沖區(read buffer)的地址與用戶空間的緩沖區(user buffer)進行映射,從而實作內核緩沖區與應用程式記憶體的共享,省去了將資料從內核讀緩沖區(read buffer)拷貝到用戶緩沖區(user buffer)的程序,整個拷貝程序會發生 4 次背景關系切換,1 次CPU 拷貝和 2次 DMA 拷貝,
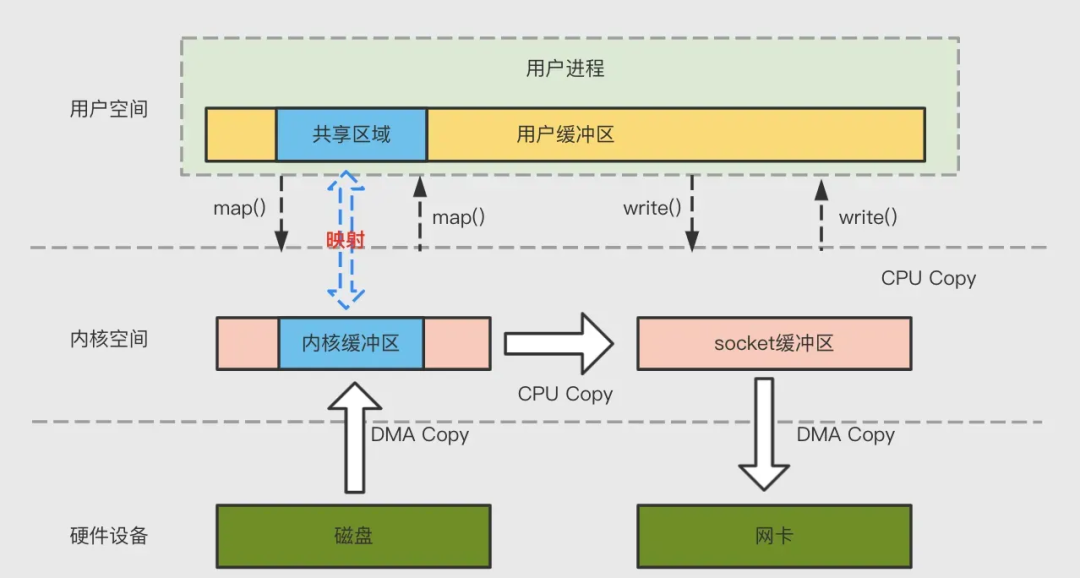
網路資料傳輸之 sendfile
傳統方式實作:先讀取磁盤、再用 socket 發送,實際也是進過四次 copy,如下圖所示:
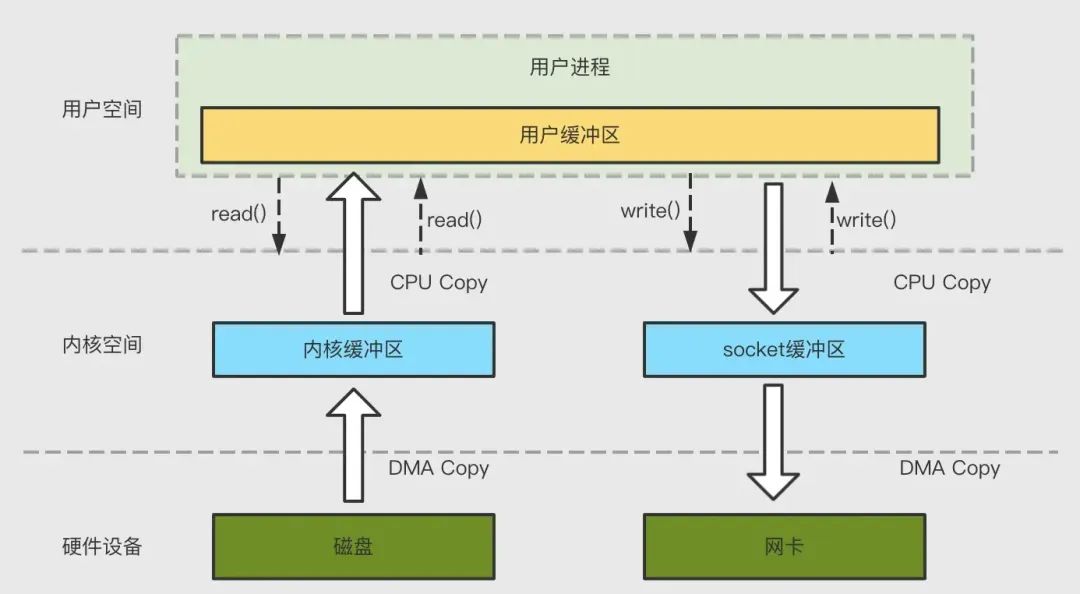
為了減少背景關系切換以及資料拷貝帶來的性能開銷,Kafka 在 Consumer 從 Broker 讀資料程序中使用了 sendfile 技術,具體在這里采用的方案是通過 NIO 的 transferTo/transferFrom 呼叫作業系統的 sendfile 實作零拷貝,總共發生 2 次內核資料拷貝、2 次背景關系切換和一次系統呼叫,消除了 CPU 資料拷貝,如下:
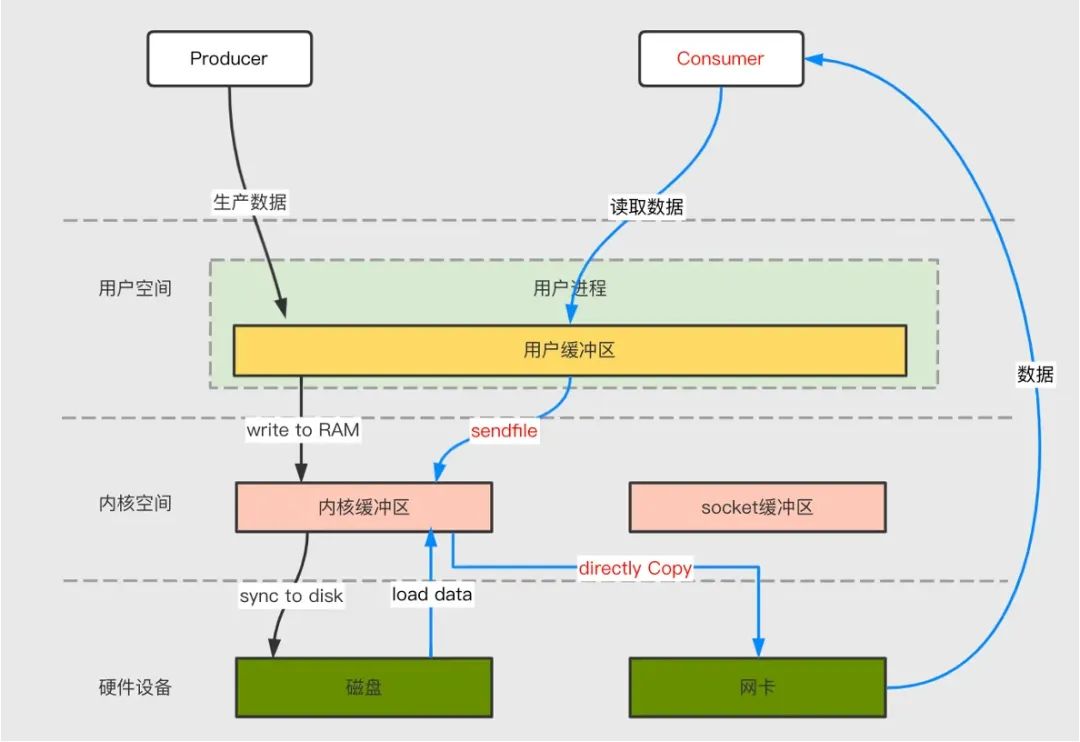
稀疏索引
為了方便對日志進行檢索和過期清理,kafka 日志檔案除了有用于存盤日志的.log 檔案,還有一個位移索引檔案.index和一個時間戳索引檔案.timeindex 檔案,并且三檔案的名字完全相同,如下:
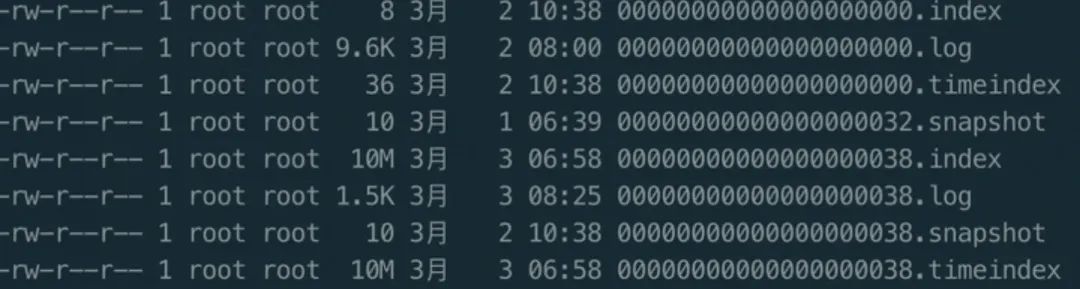
Kafka 的索引檔案是按照稀疏索引的思想進行設計的,稀疏索引的核心是不會為每個記錄都保存索引,而是寫入一定的記錄之后才會增加一個索引值,具體這個間隔有多大則通過 log.index.interval.bytes 引數進行控制,默認大小為 4 KB,意味著 Kafka 至少寫入 4KB 訊息資料之后,才會在索引檔案中增加一個索引項,可見,單條訊息大小會影響 Kakfa 索引的插入頻率,因此 log.index.interval.bytes 也是 Kafka 調優一個重要引數值,由于索引檔案也是按照訊息的順序性進行增加索引項的,因此 Kafka 可以利用二分查找演算法來搜索目標索引項,把時間復雜度降到了 O(lgN),大大減少了查找的時間,
位移索引檔案.index
位移索引檔案的索引項結構如下:
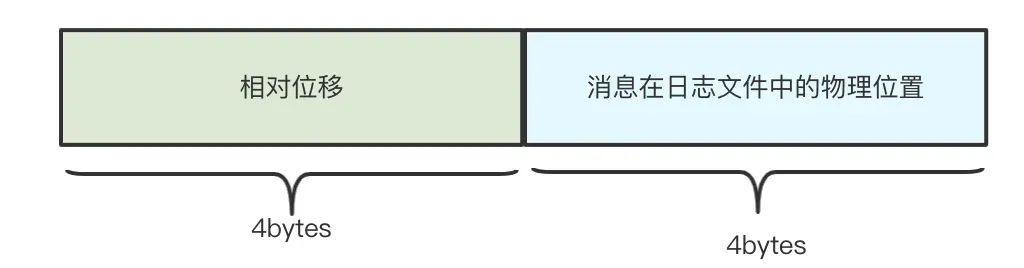
相對位移:保存于索引檔案名字上面的起始位移的差值,假設一個索引檔案為:00000000000000000100.index,那么起始位移值即 100,當存盤位移為 150 的訊息索引時,在索引檔案中的相對位移則為 150 - 100 = 50,這么做的好處是使用 4 位元組保存位移即可,可以節省非常多的磁盤空間,
檔案物理位置:訊息在 log 檔案中保存的位置,也就是說 Kafka 可根據訊息位移,通過位移索引檔案快速找到訊息在 log 檔案中的物理位置,有了該物理位置的值,我們就可以快速地從 log 檔案中找到對應的訊息了,下面我用圖來表示 Kafka 是如何快速檢索訊息:
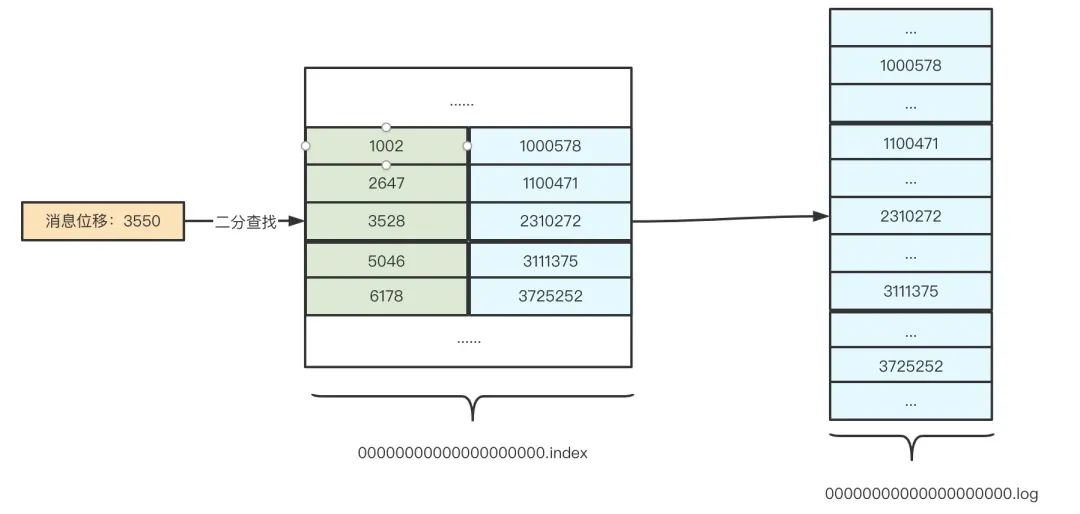
假設 Kafka 需要找出位移為 3550 的訊息,那么 Kafka 首先會使用二分查找演算法找到小于 3550 的最大索引項:[3528, 2310272],得到索引項之后,Kafka 會根據該索引項的檔案物理位置在 log 檔案中從位置 2310272 開始順序查找,直至找到位移為 3550 的訊息記錄為止,
時間戳索引檔案.timeindex
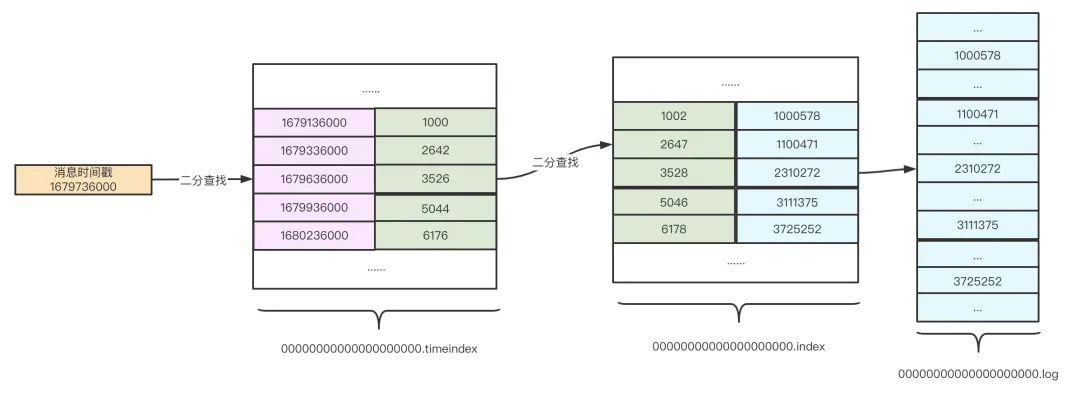
Kafka 在 0.10.0.0 以后的版本當中,訊息中增加了時間戳資訊,為了滿足用戶需要根據時間戳查詢訊息記錄,Kafka 增加了時間戳索引檔案,時間戳索引檔案的索引項結構如下:

時間戳索引檔案的檢索與位移索引檔案類似,如下快速檢索訊息示意圖:
broker & 資料磁區
Kafka 集群包含多個 broker,一個 topic 下通常有多個 partition,partition 分布在不同的 Broker 上,用于存盤 topic 的訊息,這使 Kafka 可以在多臺機器上處理、存盤訊息,給 kafka 提供給了并行的訊息處理能力和橫向擴容能力,
多 reactor 多執行緒網路模型
多 Reactor 多執行緒網路模型 是一種高效的網路通信模型,可以充分利用多核 CPU 的性能,提高系統的吞吐量和回應速度,Kafka 為了提升系統的吞吐,在 Broker 端處理訊息時采用了該模型,示意如下:
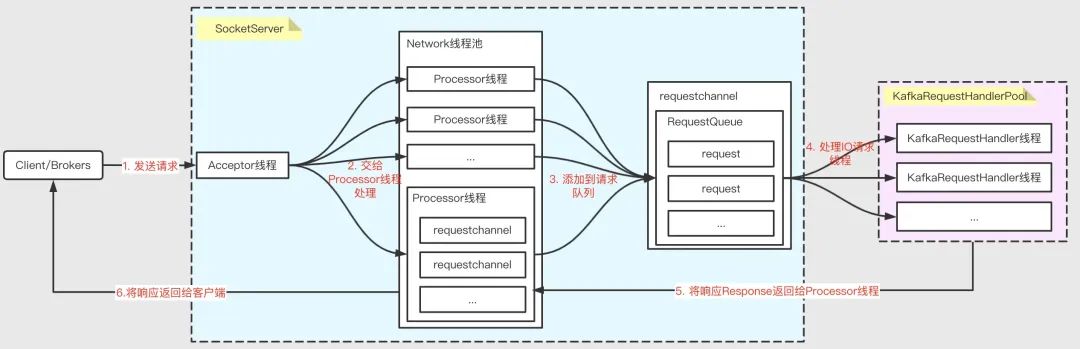
SocketServer和KafkaRequestHandlerPool是其中最重要的兩個組件:
-
SocketServer:實作 Reactor 模式,用于處理多個 Client(包括客戶端和其他 broker 節點)的并發請求,并將處理結果回傳給 Client -
KafkaRequestHandlerPool:Reactor 模式中的 Worker 執行緒池,里面定義了多個作業執行緒,用于處理實際的 I/O 請求邏輯,
整個服務端處理請求的流程大致分為以下幾個步驟:
-
Acceptor 接收客戶端發來的請求 -
輪詢分發給 Processor 執行緒處理 -
Processor 將請求封裝成 Request 物件,放到 RequestQueue 佇列 -
KafkaRequestHandlerPool 分配作業執行緒,處理 RequestQueue 中的請求 -
KafkaRequestHandler 執行緒處理完請求后,將回應 Response 回傳給 Processor 執行緒 -
Processor 執行緒將回應回傳給客戶端
其他知識探究
負載均衡
生產者負載均衡
Kafka 生產端的負載均衡主要指如何將訊息發送到合適的磁區,Kafka 生產者生產訊息時,根據磁區器將訊息投遞到指定的磁區中,所以 Kafka 的負載均衡很大程度上依賴于磁區器,Kafka 默認的磁區器是 Kafka 提供的 DefaultPartitioner,它的磁區策略是根據 Key 值進行磁區分配的:
-
如果 key 不為 null:對 Key 值進行 Hash 計算,從所有磁區中根據 Key 的 Hash 值計算出一個磁區號;擁有相同 Key 值的訊息被寫入同一個磁區,順序訊息實作的關鍵; -
如果 key 為 null:訊息將以輪詢的方式,在所有可用磁區中分別寫入訊息,如果不想使用 Kafka 默認的磁區器,用戶可以實作 Partitioner 介面,自行實作磁區方法,
消費者負載均衡
在 Kafka 中,每個磁區(Partition)只能由一個消費者組中的一個消費者消費,當消費者組中有多個消費者時,Kafka 會自動進行負載均衡,將磁區均勻地分配給每個消費者,在 Kafka 中,消費者負載均衡演算法可以通過設定消費者組的 partition.assignment.strategy 引數來選擇,目前主流的磁區分配策略以下幾種:
-
range: 在保證均衡的前提下,將連續的磁區分配給消費者,對應的實作是 RangeAssignor; -
round-robin:在保證均衡的前提下,輪詢分配,對應的實作是 RoundRobinAssignor; -
0.11.0.0 版本引入了一種新的磁區分配策略 StickyAssignor,其優勢在于能夠保證磁區均衡的前提下盡量保持原有的磁區分配結果,從而避免許多冗余的磁區分配操作,減少磁區再分配的執行時間,
集群管理
Kafka 借助 ZooKeeper 進行集群管理,Kafka 中很多資訊都在 ZK 中維護,如 broker 集群資訊、consumer 集群資訊、 topic 相關資訊、 partition 資訊等,Kafka 的很多功能也是基于 ZK 實作的,如 partition 選主、broker 集群管理、consumer 負載均衡等,限于篇幅本文將不展開陳述,這里先附一張網上截圖大家感受下:
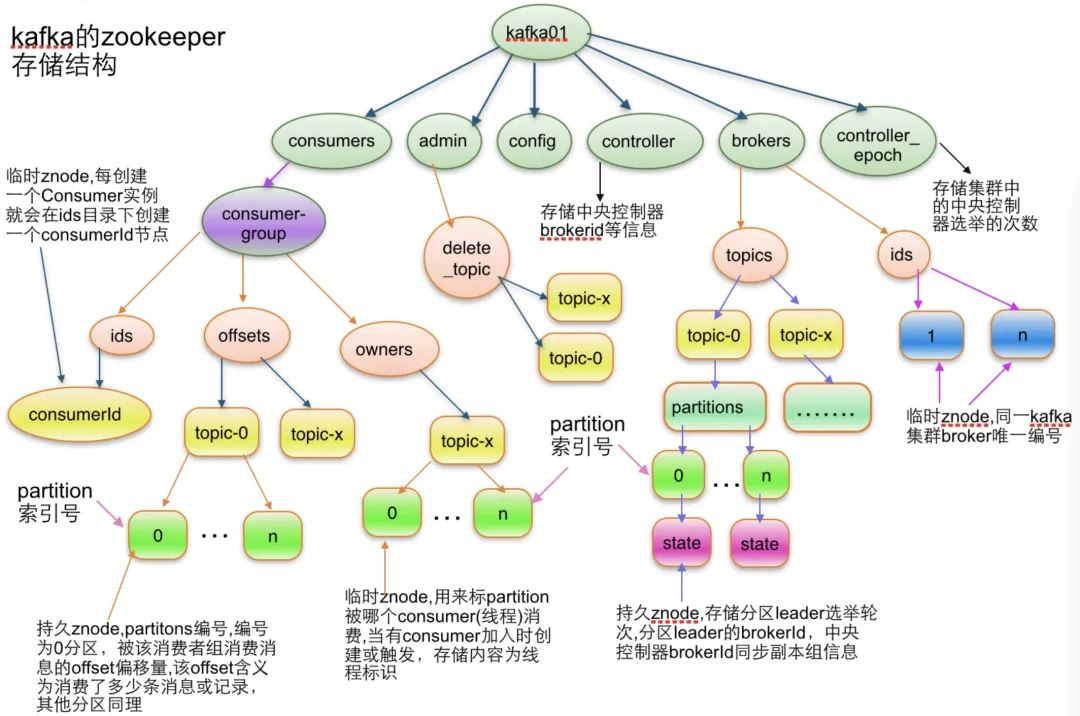
參考文獻
-
https://www.cnblogs.com/arvinhuang/p/16437948.html -
https://segmentfault.com/a/1190000039133960 -
http://matt33.com/2018/11/04/kafka-transaction/ -
https://blog.51cto.com/u_14020077/5836698 -
https://t1mek1ller.github.io/2020/02/15/kafka-leader-epoch/ -
https://cwiki.apache.org/confluence/display/KAFKA/KIP-101+-+Alter+Replication+Protocol+to+use+Leader+Epoch+rather+than+High+Watermark+for+Truncation -
https://xie.infoq.cn/article/c06fea629926e2b6a8073e2f0 -
https://xie.infoq.cn/article/8191412c8da131e78cbfa6600 -
https://mp.weixin.qq.com/s/iEk0loXsKsMO_OCVlUsk2Q -
https://cloud.tencent.com/developer/article/1657649 -
https://www.cnblogs.com/vivotech/p/16347074.html
作者:mo
本文來自博客園,作者:古道輕風,轉載請注明原文鏈接:https://www.cnblogs.com/88223100/p/Exploration-of-Kafka-High-Reliability-and-High-Performance-Principle.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/552571.html
標籤:架構設計
下一篇:返回列表