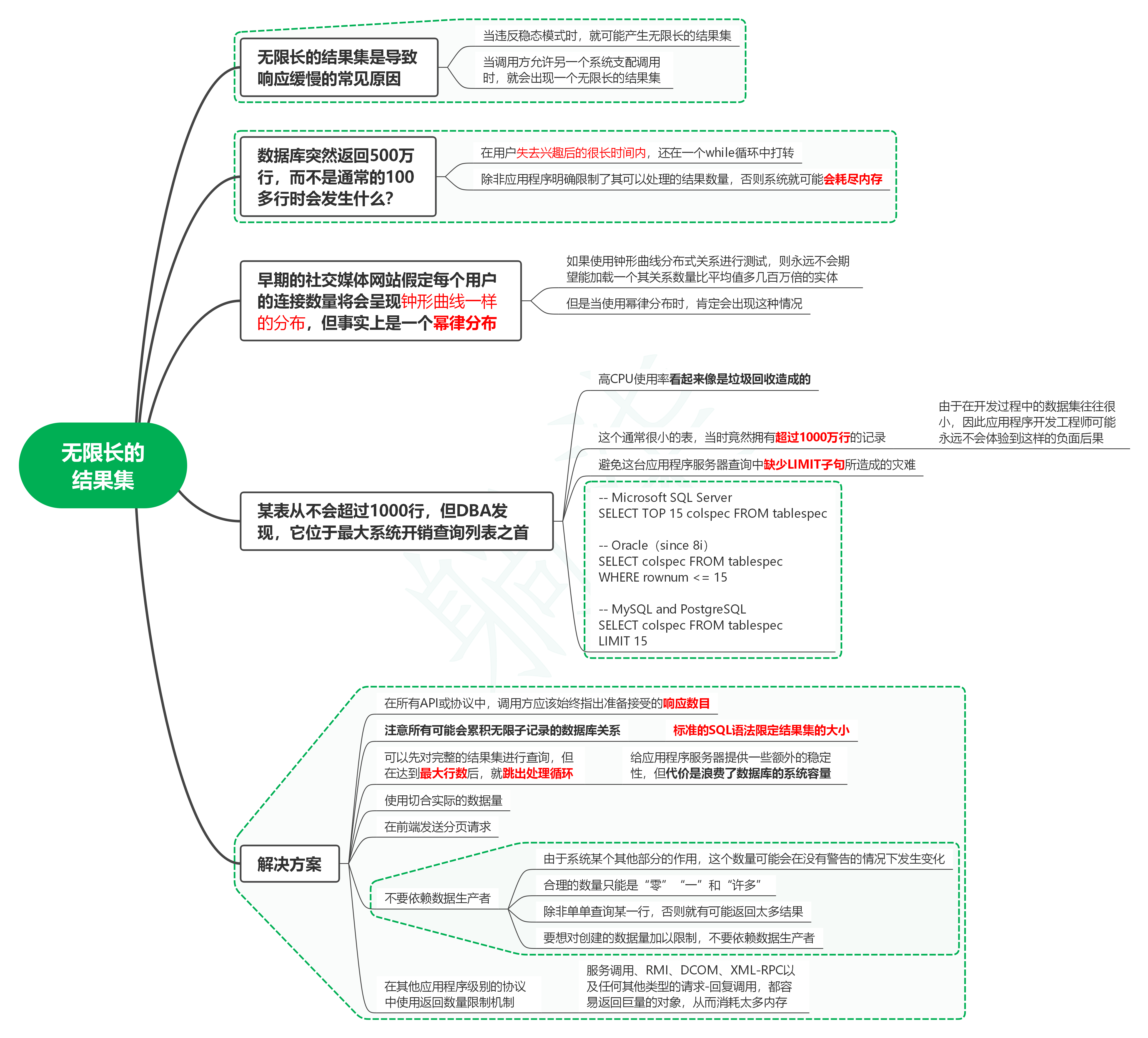
1. 無限長的結果集是導致回應緩慢的常見原因
1.1. 當違反穩態模式時,就可能產生無限長的結果集
1.2. 當呼叫方允許另一個系統支配呼叫時,就會出現一個無限長的結果集
2. 資料庫突然回傳500萬行,而不是通常的100多行時會發生什么?
2.1. 在用戶失去興趣后的很長時間內,還在一個while回圈中打轉
2.2. 除非應用程式明確限制了其可以處理的結果數量,否則系統就可能會耗盡記憶體
3. 早期的社交媒體網站假定每個用戶的連接數量將會呈現鐘形曲線一樣的分布,但事實上是一個冪律分布
3.1. 如果使用鐘形曲線分布式關系進行測驗,則永遠不會期望能加載一個其關系數量比平均值多幾百萬倍的物體
3.2. 但是當使用冪律分布時,肯定會出現這種情況
4. 某表從不會超過1000行,但DBA發現,它位于最大系統開銷查詢串列之首
4.1. 高CPU使用率看起來像是垃圾回收造成的
4.2. 這個通常很小的表,當時竟然擁有超過1000萬行的記錄
4.2.1. 由于在開發程序中的資料集往往很小,因此應用程式開發工程師可能永遠不會體驗到這樣的負面后果
4.3. 避免這臺應用程式服務器查詢中缺少LIMIT子句所造成的災難
4.4. sql
-- Microsoft SQL Server
SELECT TOP 15 colspec FROM tablespec
-- Oracle(since 8i)
SELECT colspec FROM tablespec
WHERE rownum <= 15
-- MySQL and PostgreSQL
SELECT colspec FROM tablespec
LIMIT 15
5. 解決方案
5.1. 在所有API或協議中,呼叫方應該始終指出準備接受的回應數目
5.2. 注意所有可能會累積無限子記錄的資料庫關系
5.2.1. 標準的SQL語法限定結果集的大小
5.3. 可以先對完整的結果集進行查詢,但在達到最大行數后,就跳出處理回圈
5.3.1. 給應用程式服務器提供一些額外的穩定性,但代價是浪費了資料庫的系統容量
5.4. 使用切合實際的資料量
5.5. 在前端發送分頁請求
5.6. 不要依賴資料生產者
5.6.1. 由于系統某個其他部分的作用,這個數量可能會在沒有警告的情況下發生變化
5.6.2. 合理的數量只能是“零”“一”和“許多”
5.6.3. 除非單單查詢某一行,否則就有可能回傳太多結果
5.6.4. 要想對創建的資料量加以限制,不要依賴資料生產者
5.7. 在其他應用程式級別的協議中使用回傳數量限制機制
5.7.1. 服務呼叫、RMI、DCOM、XML-RPC以及任何其他型別的請求-回復呼叫,都容易回傳巨量的物件,從而消耗太多記憶體
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/555888.html
標籤:其他
上一篇:讀發布!設計與部署穩定的分布式系統(第2版)筆記10_自動化和緩慢的回應
下一篇:返回列表