- 前言
- Instant add or drop column的主線邏輯
- 表定義的列順序與row 存盤列順序闡述
- 引入row版本的必要性
- 資料腐化問題
- 原因分析
- Bug重現與決議
- MySQL8.0.30修復方案
前言
DDL 相對于資料庫的 DML 之類的其他操作,相對來說是比較耗時、相對重型的操作; 因此對業務的影比較嚴重,MySQL 從5.6版本開始一直在持續改進其DDL性能:引入了 online DDL,inplace DDL,instant DDL 等實用性極強的功能, DDL 目前對業務的影響持續降低,
MySQL 8.0.29 引入了 instant add/drop column 功能,支持在任意位置添加 column, drop column 也不需要表資料的任何形式的移動, 只需要修改表的元資料就可以完成 add/drop column,所以 instant add/drop column 的操作是輕型操作,速度快,資源需求量少,
ALTER table drop column a, ALGORITHM=INSTANT;
8.0.29 引入了新的alter 演算法 INSTANT,
但是這個新功能目前很不穩定,導致的問題比較多; 而且通常都比較嚴重: 資料損壞,或者資料庫無法啟動等,
本文是分析其中的一個問題: 對表進行 instant drop 后,進行 update ,之后資料庫停機,而后資料庫無法啟動,
為分析這個問題, 我們會從 instant add/drop column 在 Innodb 的實作原理與細節方面來闡述這個資料腐化bug的具體原因,
Instant add or drop column的主線邏輯
因為這個功能的WorkLog無法從官方獲取,所以無法得到準確的設計出發點,通過閱讀相關代碼,得出要實作這個功能,必須要處理以下關鍵點:
-
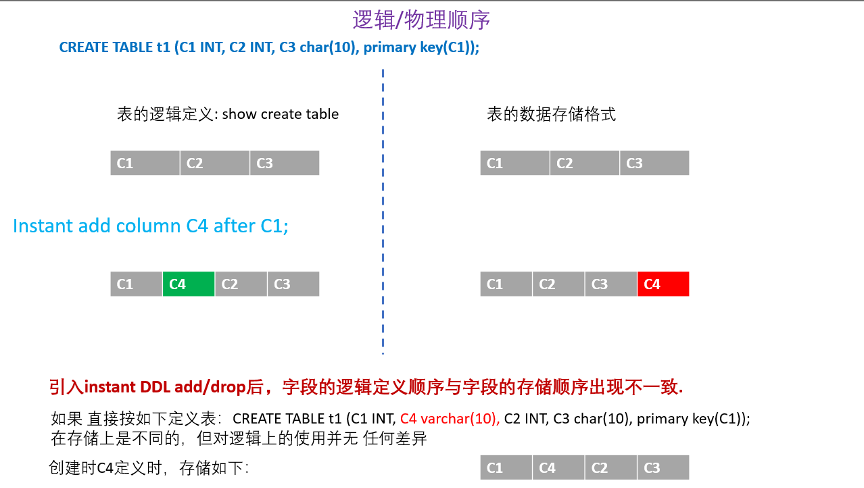
因為要支持在任意位置添加/洗掉列,同時不會更改表資料檔案,所以表的邏輯定義與row的實際存盤形式需要映射關系,不再是所見即所得的一一對應的關系,即為了實作這樣功能:
-
- 表中列的定義順序與表中行資料(row)的存盤順序是不同的,
- 同時對同一個table可以做多次instant DDL, 所以需要引入版本機制,在表的資料檔案中,不同row對應的表定義可能是不同的,需要在row中記住表定義的version,
以上可以認為是該功能的設計原則與實作的主線邏輯,
表定義的列順序與row 存盤列順序闡述
在引入這個功能之前, create table 時列定義的順序與列在 InnoDB 中存盤的順序是一致的,(這里我們不用考慮 InnoDB 添加系統隱藏列)
Instant add/drop column 要實作的亮點功能是在表定義的任意位置添加或者減少 column,同時做這樣的操作的時候,能夠做到不需要重構表資料,
我們稱 column 在表定義中出現的順序為邏輯順序;
而 column 在行資料的存盤順序為物理順序,
要做到修改表定義,而不重構表資料,就必須將邏輯順序與物理順序解耦: 不能再像MySQL 8.0.29之前的版本那樣,邏輯順序與物理順序是完全一致的;而從8.0.29開始通過表的元資料保存了邏輯順序與物理順序的映射關系,這種映射關系的構建與維護構成了 instant add/drop column 的基礎.
如下圖簡單闡述了邏輯/物理順序的關系,
引入row版本的必要性
對于同一張表,Instant add/drop DDL可以執行多次;每一次執行后,邏輯/物理順序的映射關系就發生變化;同時 instant add/drop DDL 并不需要做表資料的重構操作;因此可以得出經過多次 instant add/drop DDL,InnoDB存盤的行資料與表定義存在多種邏輯/物理順序映射關系:比如說,在 ibd 檔案中,前十行資料對應原始的表定義,接下來的十行可能對應著 instant add column 后的資料,再接下來的十行,可能對應著 instant drop column 后的資料,
為了管理這種形式的邏輯/物理,在 InnoDB 中,為每一行實際存盤的資料引入了版本號的概念:每個版本號對應著一個邏輯/物理映射關系,
為存盤這個版本資訊,InnoDB 中,row 的資訊頭記錄的格式有稍微的變化:
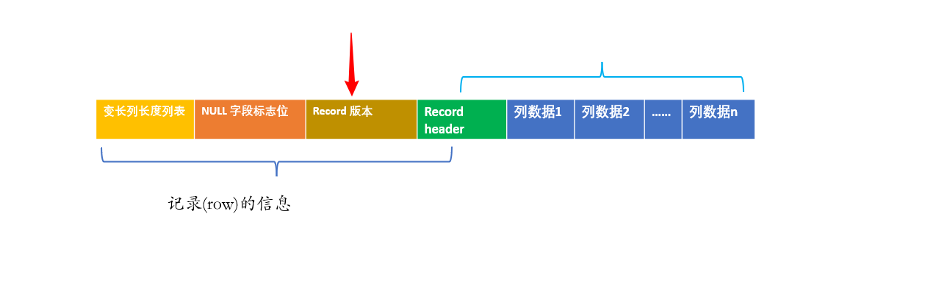
如上圖所示,在row的extra中存盤了其對應的版本號, 同時在 row header 中有標志位指示出了是否存在版本號資訊,
根據版本號獲取相應的映射關系,就可以正確的決議行資料,
目前版本號最大支持到64, instant add/drop column 到達這個限制后報錯;其后如果還需要 instant add/drop column DDL 操作,可能需要做一次能夠觸發 table rebuild 操作才可以,
資料腐化問題
由 instant add/drop column 引入了多個資料腐化問題,其中一個問題可以從:
[PS-8292] MySQL 8.0.29 fails to perform crash recovery - Percona JIRA(https://jira.percona.com/browse/PS-8292) 查看,
這個問題簡單來說:在對表進行 instant drop 后,進行update操作,之后MySQL server 重啟,在啟動階段恢復之前的 update 操作會引發 assert 崩潰(debug版本的情況下),
從代碼上看,這個bug可能會造成資料的靜默錯誤(資料完全錯亂而且不報任何錯誤),而不僅僅是崩潰這一種現象,
通過對core檔案的簡單分析,造成該問題的大概原因如下:
在通過redo做恢復的時候,欄位的邏輯順序與物理存盤順序之間的映射關系不對(錯位)導致的,在恢復期間可能會找不到對應的欄位,或者更新了錯誤的欄位,
原因分析
從原始的問題看,這個是發生在 InnoDB 啟動恢復階段,這一階段離不開 redo log的參與,前面介紹 instant add/drop 設計要點的時候,那些列出的要點,可以認為是在在 DDL 期間的作業以及編碼的基本邏輯;那么在完成 instant DDL 時候, 在 DML 的時候也需要將必要的資訊寫入 redo log 才能做到 recovery,
- 為支持 instant add/drop column,redo log 記錄的格式發生了變化,因為代碼bug,導致在決議 redo log 做恢復的時候,得到的欄位資訊錯誤,導致資料腐化,
- 問題表現出來可能是: 恢復始終無法執行,資料庫無法啟動;還可能是恢復到錯誤的資料,資料庫能夠啟動,
因為 redo log 的種類較多,資訊也比較繁雜,這里我們只關注問題本身中出現的 update 相關的 redo log ,進而較多的關注 update redo log 與該問題相關的欄位資訊,
下圖簡要的闡述了 update redo log 相關內容:
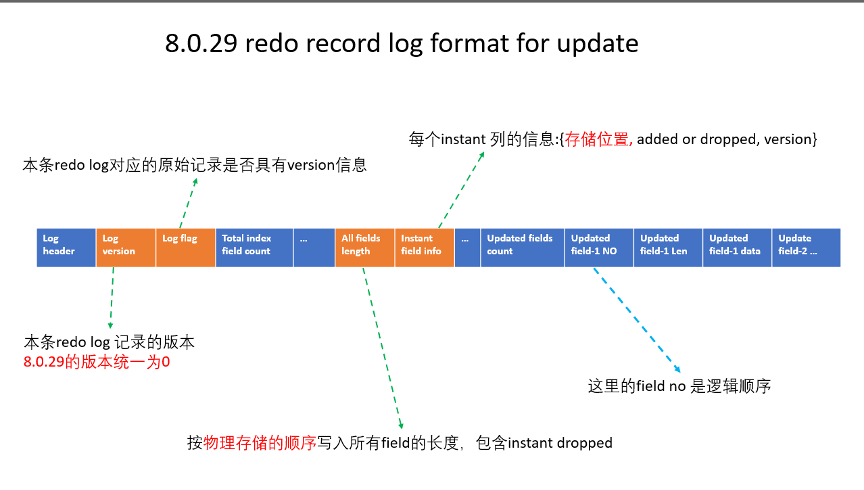
到這里,可以看到 在MySQL 8.0.29中,update redo log 引入了 instant column 的物理邏輯順序,
下面從 InnoDB 的恢復流程跟蹤問題發生的原因,其中主要需要關注的是恢復程序中的表(索引)定義,
- 應用 redo log 是在資料庫啟動階段最開始就執行,此時資料字典無法打開,獲取不到待恢復表的定義資訊
- 但是此時需要表的定義資訊去決議 redo log 中的相關資料
- 此時就會根據redo log中記錄的長度資訊,以及記錄長度的順序構建臨時的表定義,此時僅僅是為了恢復,并不需要精確的表定義,此時只需要知道field的長度和位置即可,
- 同時如果 redo log 中如果有instant DDL 的資訊,那么也會用這些資訊去修改臨時構建的表定義:這是問題發生的初始錯誤的地方,
- 恢復程序中,構建出的臨時表實際上表中列的邏輯順序,這是符合正常運行的需求的,
- 但是實際上8.0.29中欄位長度的記錄順序是按欄位(列)的物理存盤順序寫入的,
- 如果帶有 instant DDL 的資訊,那么修改表定義時就會按物理順序去修改邏輯順序的表定義,這樣會修改到非預期的欄位,導致錯誤發生!
Bug重現與決議
CREATE TABLE `tb1` (
`col1` VARCHAR(10) NOT NULL,
`col2` char(13),
`col3` varchar(11),
PRIMARY KEY (`col1`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
INSERT INTO tb1 VALUES ('4000','50','100');
--echo # the FIRST INSTANT ALTER
ALTER TABLE tb1 DROP COLUMN col2, LOCK=DEFAULT;
INSERT INTO tb1 VALUES( '4545', '52' );
UPDATE tb1 SET col3 = '46' WHERE col1 = '4545';
--echo # crash and restart 1
--source include/kill_and_restart_mysqld.inc
CHECK TABLE tb1;
DROP TABLE tb1;
以上MySQL MTR 測例可以重現 InnoDB 啟動恢復期間始終 core 的問題,我們從這個例子出發,結合上面解釋的 instant drop DDL 代碼行為看看問題是如何一步步發生的,
- 首先說明一下,在測例運行期間邏輯順序與物理順序的變化, 如下圖所示稍微展示了 table 的邏輯定于與 InnoDB row 存盤的以下細節,這里注意的是 被 dropped column 仍然會以隱藏列的形式存在于表定于中:因為 drop 之前存在的 row 還是需要這樣資訊決議欄位,

-
結合 redo log 的恢復程序看看問題發生的第一現場,這里針對這個測例摘取相關 redo log 的部分資訊:

2.1 按照欄位長度串列(8.0.29中是物理順序寫入的串列)創建的專門用于恢復的表,類似于: create table dummy_table (d1:10, d2:13, d3:11)
2.2 按照 instant 欄位資訊修改 dummy 表:按照 physical pos=1 去修改后,結果類似于:create table dummy_table (d1:10, d2:13[dropped], d3:11)
2.3 期望的正確的表應該類似于:create table dummy_table(d1:10, d3:11, d2:13[dropped]);
2.4 Redo log中的Field_no=1, 去恢復時期望用到的是 #2.3 的表,但是程序中創建的是#2.2中錯誤的表,這樣當Field_no=1去恢復資料時,會錯誤的發現對應的field(column)已經dropped, 導致core!
MySQL8.0.30修復方案
知道了問題發生的原因,修復起來就比較簡單了:
-
MySQL 8.0.30的代碼修復方案
-
- Redo log中欄位的長度串列,按照欄位的邏輯順序寫入,不再按存盤順序寫入,
- 在 redo log 的 instant column 資訊中也包含了欄位的邏輯位置,
- Redo log 的記錄本身的版本設定為 1 ,與8.0.29的版本為 0 ,做出差別,
- 8.0.30的修復代碼本身也是不能正確決議8.0.29產生的 redo log ,只是根據版本號檢測出8.0.29 redo log,進而報錯防止資料進一步惡化,實際上8.0.29的 redo log ,在 instant DDL 后,是不可能正確決議的,因為沒有邏輯/物理的映射關系,
-
修復的邏輯比較簡單:
-
-
Redo log中欄位的長度串列,按照欄位的邏輯順序寫入:
保證在恢復階段構建的臨時表是按正確的邏輯定義順序構建的,
-
在redo log 的 instant column 資訊中也包含欄位的邏輯位置:
保證在更新臨時表的欄位時,按照邏輯順序,不會出現錯誤更新的情況,
-
下面是MySQL 8.0.30 update redo log 相關欄位資訊:
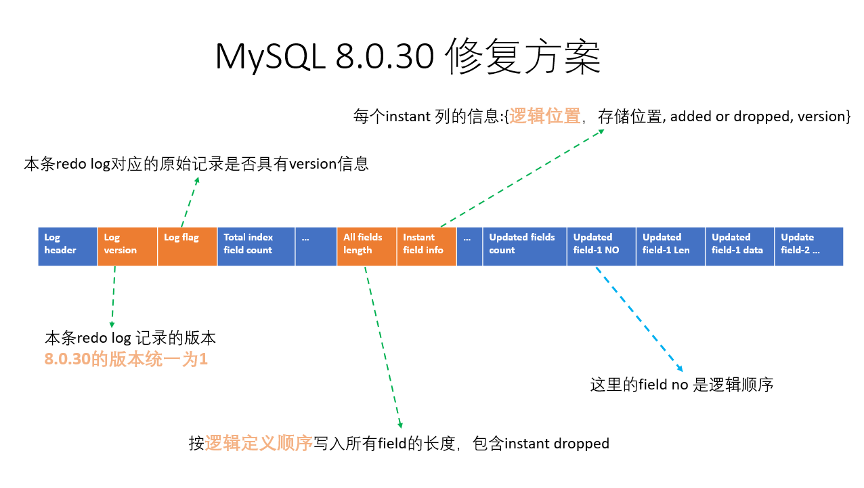
從上圖可以看出,MySQL 8.0.30 redo log 中已經不存盤物理位置相關的資訊了,全部是邏輯位置相關的資訊;這樣就和MySQL 8.0.29 redo log 這種有問題的記錄方式是曇花一現了,
附帶的這個測例可以重現資料的靜默錯誤(恢復程序沒問題, 但是資料實際上錯了)
CREATE TABLE `tb2` ( `c1` char(4) NOT NULL, `c2` char(4), `c3` char(4), PRIMARY KEY (`c1`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
begin;
INSERT INTO tb2 VALUES ('1000','2000','3000');
commit;
--echo # the FIRST INSTANT ALTER
ALTER TABLE tb2 add COLUMN c4 char(4) after c1, LOCK=DEFAULT;
INSERT INTO tb2 VALUES ('1001','4001', '2001', '3001');
SELECT * FROM tb2;
UPDATE tb2 set c4='4002' WHERE c1='1001';
--echo # crash and restart 1
--source include/kill_and_restart_mysqld.inc
select * from tb2;
CHECK TABLE tb2;
需要把這個測例放到innodb test case suite中,
Enjoy GreatSQL ??
關于 GreatSQL
GreatSQL是由萬里資料庫維護的MySQL分支,專注于提升MGR可靠性及性能,支持InnoDB并行查詢特性,是適用于金融級應用的MySQL分支版本,
相關鏈接: GreatSQL社區 Gitee GitHub Bilibili
GreatSQL社區:
社區博客有獎征稿詳情:https://greatsql.cn/thread-100-1-1.html

技術交流群:
微信:掃碼添加
GreatSQL社區助手微信好友,發送驗證資訊加群,

轉載請註明出處,本文鏈接:https://www.uj5u.com/shujuku/555024.html
標籤:MySQL
下一篇:返回列表