今天給大家分享一個之前完成的爬蟲實體,利用Scrapy庫和docker爬取股票資訊,
這個案例的目標是爬取股票的資訊并存放到SQL Server當中,
這應該算是爬蟲入門必學的案例了,話不多說,直接上干貨,
首先看一下我們今天要用到的庫和工具:
from scrapy import Spider, Request
from scrapy_splash import SplashRequest
import scrapy
import re
from getStock.items import GetstockItem
用到的庫有:
scrapy 爬蟲庫
re 用于匹配我們需要的網站資訊
scrapy_splash 幫助我們爬取動態網站的資訊
(如果不知道什么是動態網站的話,最簡單的說法就是不能直接用request庫爬取的網站)
需要注意scrapy_splash是要額外安裝的
pip install scrapy_splash
用到的工具:
Docker
SQL Server2019
相信大家對sql已經很熟悉了,可能對docker比較陌生,

Docker 是一個開源的應用容器引擎,基于 Go 語言 并遵從 Apache2.0 協議開源,
它的應用場景主要是:
1、Web 應用的自動化打包和發布,
2、自動化測驗和持續集成、發布,
3、在服務型環境中部署和調整資料庫或其他的后臺應用,
4、從頭編譯或者擴展現有的 OpenShift 或 Cloud Foundry 平臺來搭建自己的 PaaS 環境,
大家可以點擊下面的鏈接去對docker進行更深入的了解和學習,
Docker簡易教程
Win10下安裝Docker
SqlServer2019安裝教程
接下來就進入到我們的代碼部分吧
headers = {
'User-Agent': 'User-Agent:Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11'
}
#給我們的爬蟲加一個偽裝的header防止被網站檢測到
我們的目標是要首先要去到東方財富網中獲取我們所有股票的代碼,再去到搜狐股票網中獲取對應股票我們需要的資訊,
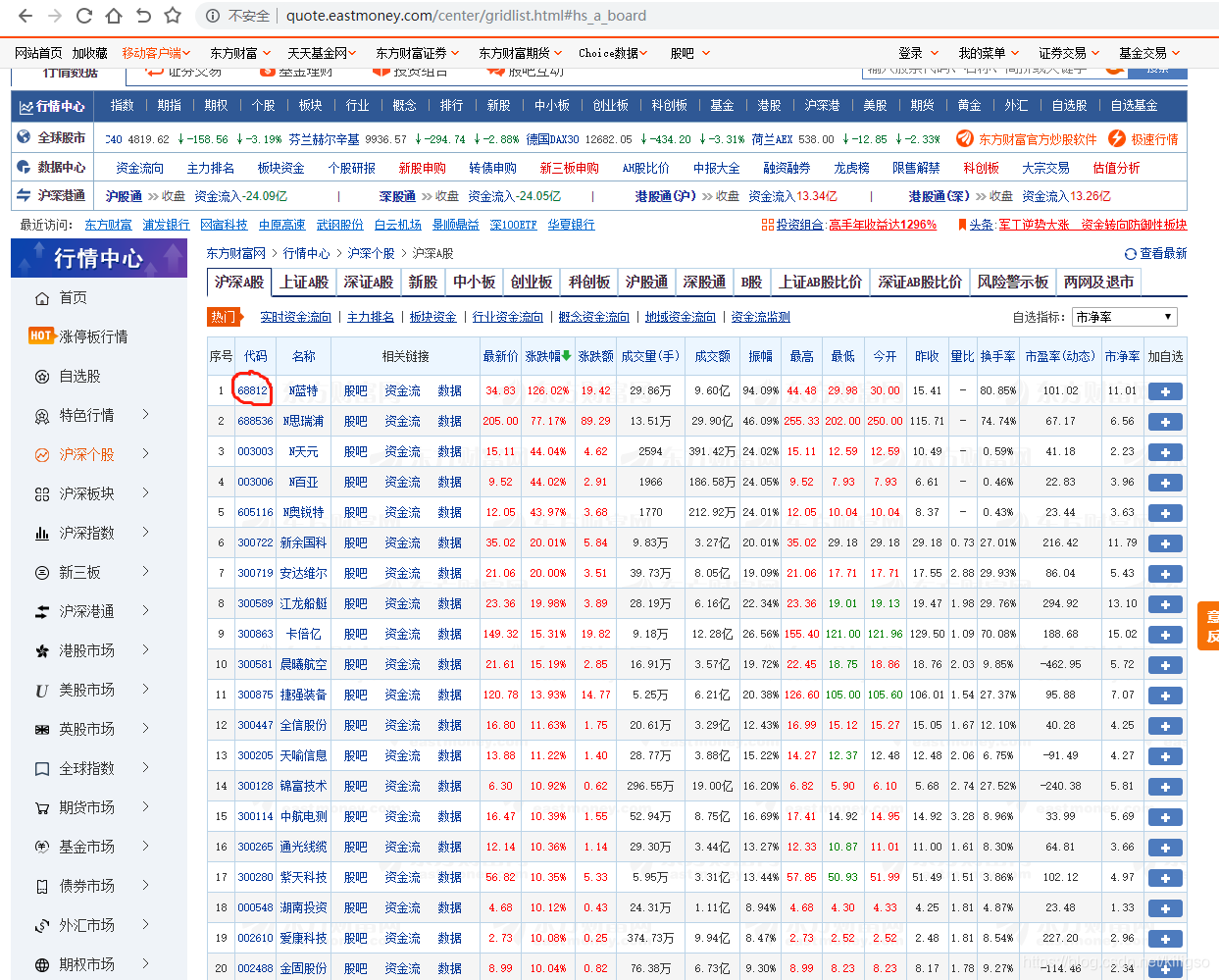
對著我們的代碼右鍵檢查,可以跳轉到代碼這個元素在網站中的位置
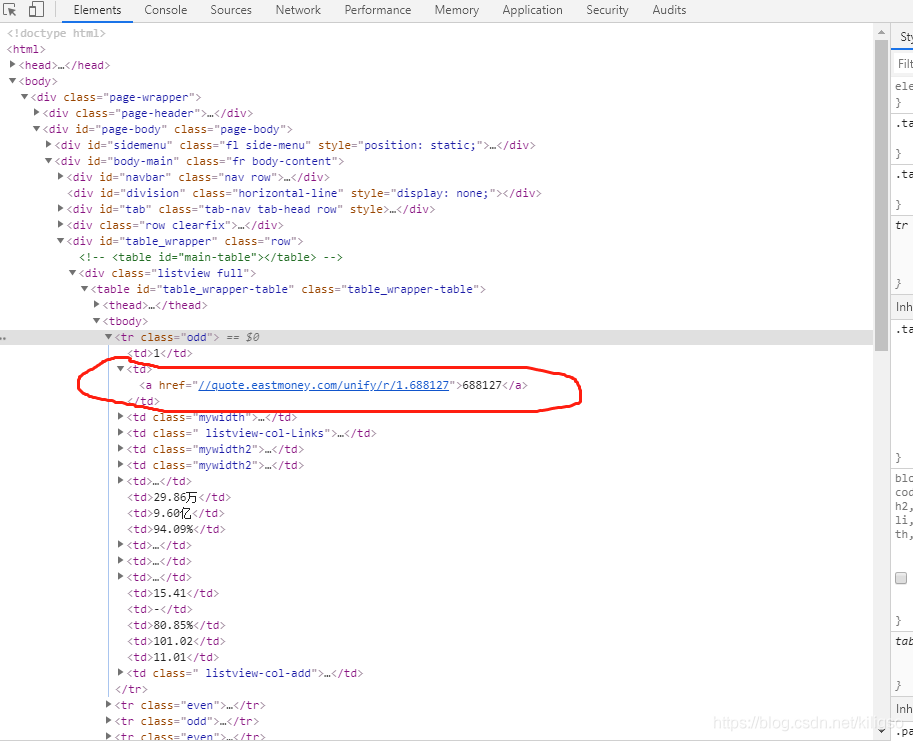
我們的目標是提取到圈圈中的股票代碼,使用re和css可以很簡單的完成這個目標
class StockSpider(scrapy.Spider):
name = 'stock'
start_urls = ['http://quote.eastmoney.com']
def start_requests(self):
url = 'http://quote.eastmoney.com/stock_list.html'
yield SplashRequest(url, self.parse, headers=headers)
def parse(self, response):
for href in response.css('a::attr(href)').extract():
try:
stock = re.findall(r"\d{6}", href)[0]
url = 'http://q.stock.sohu.com/cn/' + stock
yield SplashRequest(url, self.parse1,args={'wait':5}, headers=headers )
except:
continue
注意我們這里在parse中回傳的URL是搜狐網站的鏈接加上我們的股票代碼所形成的URL,這個url可以幫助我們跳轉到每一個股票所在的資訊頁面,
例如平安銀行(000001)的URL鏈接就是:https://q.stock.sohu.com/cn/000001
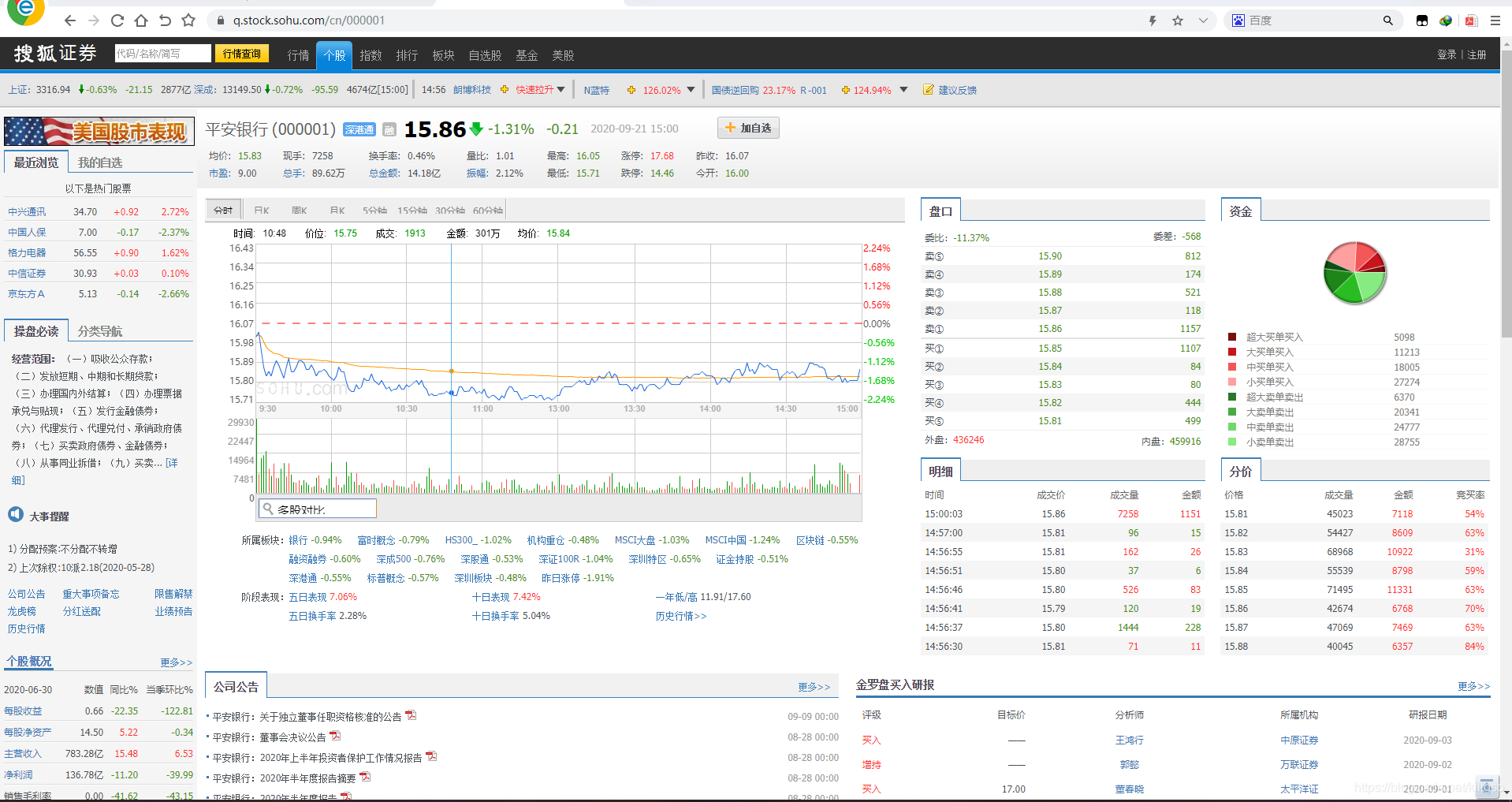
那么接下來我們就要取出每一個股票中我們所需要的資訊了,在這里博主提取了的是每一個股票的:股票代碼,股票名稱,現時價格,昨收價格,開盤價格,最高價格,最低價格,總交易額,所屬行業,日期,初步建議
同樣的我們右鍵檢查跳轉到我們需要提取的元素位置
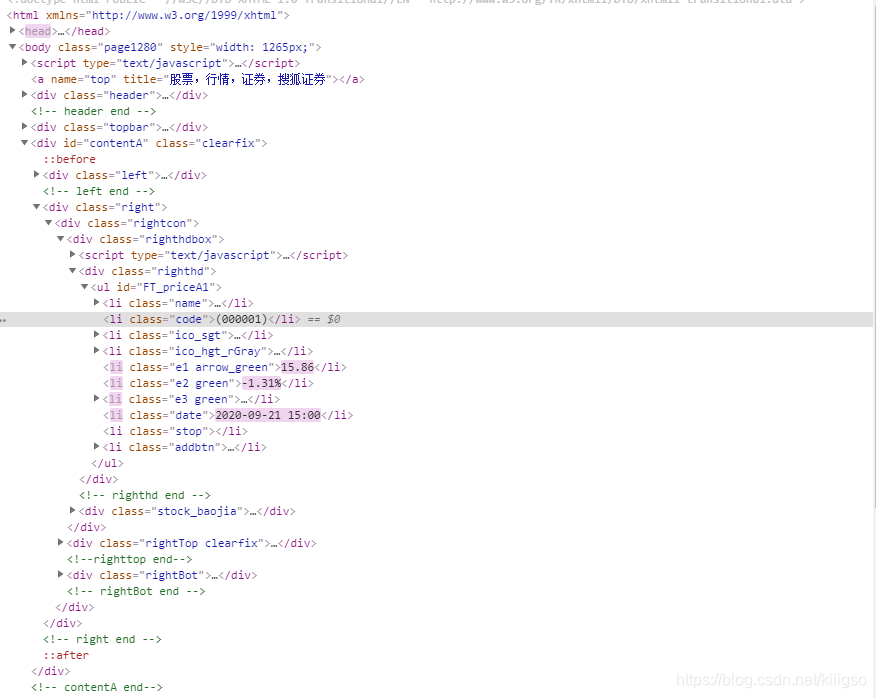
在這里可以找到我們所需要的股票資訊,接下來就可以用簡單粗暴的xpath進行提取,
def parse1(self, response):
item = GetstockItem()
try:
stockinfo = response.xpath('// *[ @ id = "contentA"] / div[2] / div / div[1]')
item['name'] = stockinfo.xpath('//*[@class="name"]/a/text()').extract()[0]
item['code'] = stockinfo.xpath('//*[@class="code"]/text()').extract()[0].replace('(','').replace(')','')
item['date'] = stockinfo.xpath('//*[@class="date"]/text()').extract()[0]
item['nprice'] = float(stockinfo.xpath('//li[starts-with(@class,"e1 ")]/text()').extract()[0])
item['high'] = float(response.xpath('//*[@id="FT_priceA2"]/tbody/tr[1]/td[5]/span/text()').extract()[0])
item['low'] = float(response.xpath('//*[@id="FT_priceA2"]/tbody/tr[2]/td[5]/span/text()').extract()[0])
item['ed'] = float(response.xpath('//*[@id="FT_priceA2"]/tbody/tr[1]/td[7]/span/text()').extract()[0])
item['op'] = float(response.xpath('//*[@id="FT_priceA2"]/tbody/tr[2]/td[7]/span/text()').extract()[0])
item['volume'] = float(response.xpath('//*[@id="FT_priceA2"]/tbody/tr[2]/td[3]/span/text()').extract()[0].replace('億',''))
item['hangye'] = response.xpath('//*[@id="FT_sector"] / div / ul / li[1]/a/text()').extract()[0]
suggests = response.xpath('//*[@id="contentA"]/div[2]/div/div[3]/div[2]/div[2]/div[1]/div[2]/table/tbody/tr[1]')
item['suggest'] = suggests.xpath('//td[starts-with(@class,"td1 ")]/span/text()').extract()[0]
except:
pass
yield item
這就是我們爬蟲部分所有代碼了,看起來是不是很簡單,但是scrapy庫要完成這個功能,還需要設定它本身包含的組態檔,
Settings.py設定:
ROBOTSTXT_OBEY = False #原本為True
DOWNLOADER_MIDDLEWARES = {
'scrapy_splash.SplashCookiesMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810
}
#更改DOWNLOADER_MIDDLEWARES中的配置
ITEM_PIPELINES = {
'getStock.pipelines.GetstockPipeline': 300,
}
#這里的ITEM要對應item.py中的item類的名字,否則會報錯
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
SPLASH_URL = "http://192.168.5.185:8050/"
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
RETRY_HTTP_CODES = [500, 502, 503, 504, 400, 403, 404, 408]
#SPLASH_URL要改成自己電腦的docker默認地址
item.py設定:
import scrapy
class GetstockItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field()
code = scrapy.Field()
nprice = scrapy.Field()
op = scrapy.Field()
ed = scrapy.Field()
high = scrapy.Field()
low = scrapy.Field()
volume = scrapy.Field()
date = scrapy.Field()
hangye = scrapy.Field()
suggest = scrapy.Field()
#你在網站中要取多少個資訊,就要有相應的item,不然資訊無法回傳給爬蟲
最后的配置是pipelines.py,要實作將我們得到的資訊存入到資料庫中,就要在這里進行配置,大家在自己實作的時候要記得將資訊調整為自己的資料庫資訊,
先在我們的SQL中創建一個用來存放的表
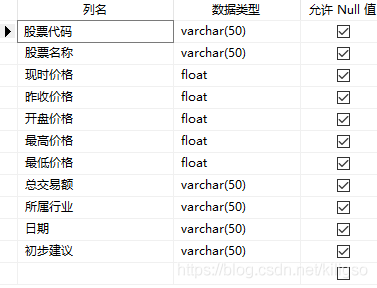
import pyodbc
class GetstockPipeline(object):
def __init__(self):
self.conn = pyodbc.connect("DRIVER={SQL SERVER};SERVER=服務器名;UID=用戶名;PWD=密碼;DATABASE=資料庫名")
self.cursor = self.conn.cursor()
def process_item(self,item,spider):
try:
sql = "INSERT INTO dbo.stock_data(股票代碼,股票名稱,現時價格,昨收價格,開盤價格,最高價格,最低價格,總交易額,所屬行業,日期) VALUES('%s','%s','%.2f','%.2f','%.2f','%.2f','%.2f','%.2f','%s','%s')"
data = (item['code'],item['name'],item['nprice'],item['ed'],item['op'],item['high'],item['low'],item['volume'],item['hangye'],item['date'])
self.cursor.execute(sql % data)
try:
sql = "update dbo.stock_data set 初步建議='%s' where dbo.stock_data.股票代碼=%s"
data = (item['suggest'],item['code'])
self.cursor.execute(sql % data)
print('success')
except:
sql = "update dbo.stock_data set 初步建議='該股票暫無初步建議' where dbo.stock_data.股票代碼=%s"
data = item['code']
self.cursor.execute(sql % data)
print("該股票暫無初步建議")
self.conn.commit()
print('資訊寫入成功')
#這里填入初步建議的時候使用了try和expect,因為有的股票沒有這個初步建議,爬蟲爬取不到會報錯
except Exception as ex:
print(ex)
return item
以上就是代碼部分的所有內容了,接下來我們只需要運行我們的爬蟲就可以了!
scrapy crawl stock
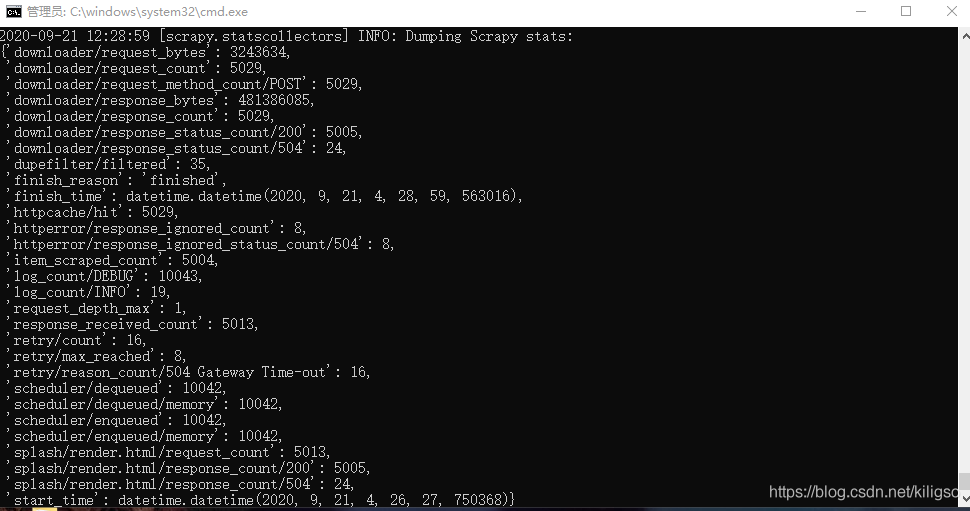
成功地爬取了所有的股票資訊,來看看我們是否能在資料庫中看到這些資訊吧,
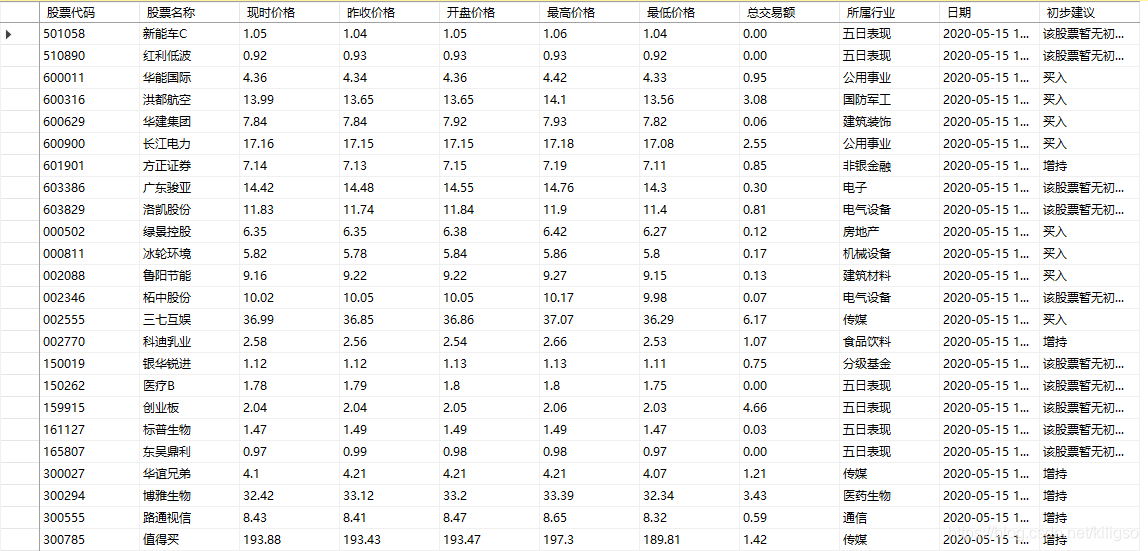
所有資訊都已經成功的存放到資料庫當中了!
以上就是這個案例的所有內容了,主要的難點其實在docker的安裝實作當中,博主當時弄了很長一段時間才將docker成功跑起來,大家如果有疑問或者有更好的做法的話可以在評論區提出,博主看到的話會及時回復的,
謝謝你們的閱讀!
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/111392.html
標籤:其他
上一篇:【Python網路爬蟲】150講輕松搞定Python網路爬蟲付費課程筆記 篇十三——資料存盤:JSON 字串格式