基于Python的理論與實作(上)
第一章 Python入門
1.Python是什么?
Python是一個簡單、易讀、易記的編程語言
2.學習深度學習為什么要用Python?
深度學習的 框架中也有很多使用Python的場景,比如Caffe、TensorFlow、Chainer、 Theano等著名的深度學習框架都提供了Python介面,因此,學習Python 對使用深度學習框架大有益處,
3.我們會用到Python的哪些知識?
除了掌握最基本的Python語法,函式,類之外,我們還會使用兩個外部庫:NumPy庫和Matplotlib 庫
NumPy是用于數值計算的庫,提供了很多高級的數學演算法和便利的數 組(矩陣)操作方法,本書中將使用這些便利的方法來有效地促進深度學習 的實作,
Matplotlib是用來畫圖的庫,使用Matplotlib能將實驗結果可視化,并 在視覺上確認深度學習運行期間的資料,
NumPy庫的使用
-
匯入NumPy
# NumPy相關的方法均可通過np來呼叫, import numpy as np -
使用:生成NumPy陣列
要生成NumPy陣列,需要使用np.array()方法,np.array()接收Python 串列作為引數,生成NumPy陣列(numpy.ndarray),
>>> x = np.array([1.0, 2.0, 3.0]) >>> y = np.array([2.0, 4.0, 6.0]) >>> x + y # 對應元素的加法 array([ 3., 6., 9.]) >>> x - y array([ -1., -2., -3.]) >>> x * y # element-wiseproduct array([ 2., 8., 18.]) >>> x / y array([ 0.5, 0.5, 0.5]) -
使用:NumPy的N維陣列
NumPy不僅可以生成一維陣列(排成一列的陣列),也可以生成多維陣列, 比如,可以生成如下的二維陣列(矩陣),
>>> A = np.array([[1, 2], [3, 4]]) >>> print(A) [[1 2] [3 4]] >>> A.shape (2, 2) >>> A.dtype dtype('int64') >>> B = np.array([[3, 0],[0, 6]]) >>> A + B array([[ 4, 2], [ 3, 10]]) >>> A * B array([[ 3, 0], [ 0, 24]]) >>> A * 10 array([[ 10, 20], [ 30, 40]])NumPy陣列(np.array)可以生成N維陣列,即可以生成一維陣列、 二維陣列、三維陣列等任意維數的陣列,數學上將一維陣列稱為向量, 將二維陣列稱為矩陣,另外,可以將一般化之后的向量或矩陣等統 稱為張量(tensor),本書基本上將二維陣列稱為“矩陣”,將三維數 組及三維以上的陣列稱為“張量”或“多維陣列”,
-
廣播功能
NumPy中,形狀不同的陣列之間也可以進行運算
A = np.array([[1, 2], [3, 4]]) >>> B = np.array([10, 20]) >>> A * B array([[ 10, 40], [ 30, 80]])一維陣列B被“巧妙地”變成了和二維數 組A相同的形狀,然后再以對應元素的方式進行運算, 綜上,因為NumPy有廣播功能,所以不同形狀的陣列之間也可以順利 地進行運算,
-
訪問元素
元素的索引從0開始,對各個元素的訪問可按如下方式進行,
>>> X = np.array([[51, 55], [14, 19], [0, 4]]) >>> print(X) [[51 55] [14 19] [ 0 4]] >>> X[0] # 第0行 array([51, 55]) >>> X[0][1] # (0,1)的元素 55使用for陳述句訪問各個元素,
>>> for row in X: >>> print(row) [51 55] [14 19] [0 4]除了前面介紹的索引操作,NumPy還可以使用陣列訪問各個元素,
>>> X = X.flatten() # 將X轉換為一維陣列 >>> print(X) [51 55 14 19 0 4] >>> X[np.array([0, 2, 4])] # 獲取索引為0、2、4的元素 array([51, 14, 0])運用這個標記法,可以獲取滿足一定條件的元素,例如,要從X中抽出 大于15的元素,可以寫成如下形式,
>>> X > 15 array([ True, True, False, True, False, False], dtype=bool) >>> X[X>15] array([51, 55, 19])
Matplotlib庫的使用
-
匯入Matplotlib
import matplotlib.pyplot as plt -
使用:用matplotlib的pyplot模塊繪制圖形
繪制sin函式曲線的例子,
# 生成資料 x = np.arange(0, 6, 0.1) # 以0.1為單位,生成0到6的資料 y = np.sin(x) # 繪制圖形 plt.plot(x, y) plt.show()**這里使用NumPy的arange方法生成了[0, 0.1, 0.2, …, 5.8, 5.9]的 資料,將其設為x,對x的各個元素,應用NumPy的sin函式np.sin(),將x、 y的資料傳給plt.plot方法,然后繪制圖形,最后,通過plt.show()顯示圖形, **
-
使用:顯示與讀入影像
pyplot中還提供了用于顯示影像的方法imshow(),另外,可以使用 matplotlib.image模塊的imread()方法讀入影像,下面我們來看一個例子,
import matplotlib.pyplot as plt from matplotlib.image import imread img = imread('lena.png') # 讀入影像(設定合適的路徑!) plt.imshow(img) plt.show()
第二章 感知機
1.感知機是什么?
感知機是一種人工神經網路,由Frank Rosenblatt于1957年發明,他也提出了相應的感知機學習演算法,
感知機接收多個輸入信號,輸出一個信號,
2.為什么要學習感知機?
因為感知機也是作為神經網路(深度學習)的起源的演算法,因此, 學習感知機的構造也就是學習通向神經網路和深度學習的一種重要思想,
3.學習感知機的哪些內容?
- 感知機是具有輸入和輸出的演算法,給定一個輸入后,將輸出一個既 定的值,
x1、x2是輸入信號, y是輸出信號,w1、w2是權重(w是weight的首字母),圖中的○稱為**“神經元”或者“節點”,輸入信號被送往神經元時,會被分別乘以固定的權重(w1x1、w2x2),神經元會計算傳送過來的信號的總和,只有當這個總和超過了某個界限值時,才會輸出1,這也稱為“神經元被激活” ,這里將這個界 限值稱為閾值**,用符號θ表示,
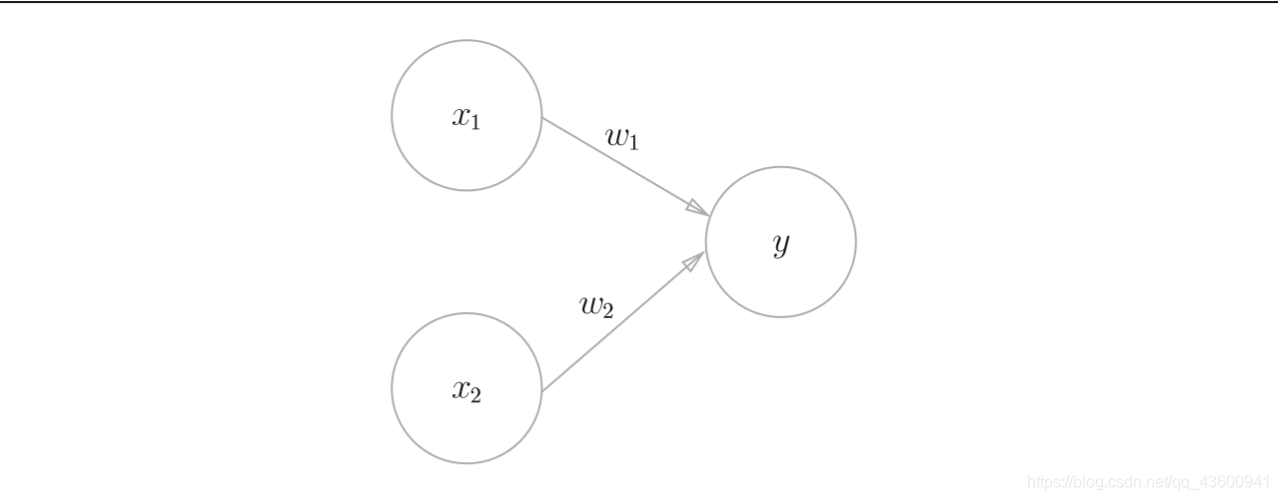
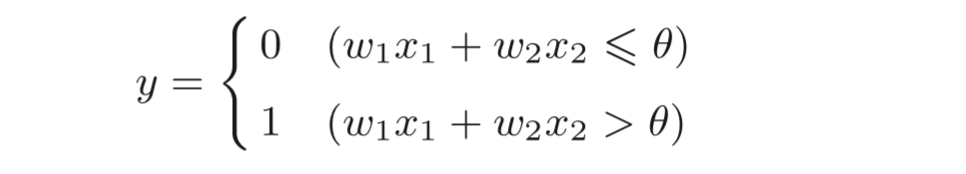
- 感知機將權重和偏置設定為引數,
θ換成?b,于 是就可以用下面的式子來表示感知機的行為,
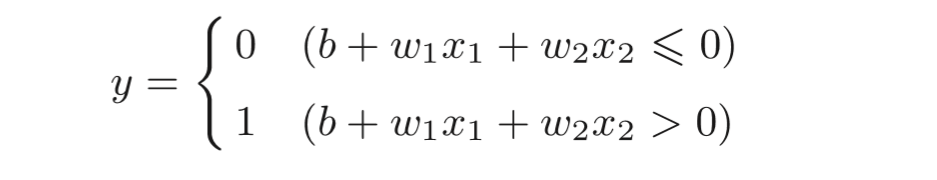
此處,b稱為偏置,w1和w2稱為權重
感知機的多個輸入信號都有各自固有的權重,這些權重發揮著控制各個 信號的重要性的作用,也就是說,權重越大,對應該權重的信號的重要性就越高,感知機會計算輸入 信號和權重的乘積,然后加上偏置,如果這個值大于0則輸出1,否則輸出0,
具體地說,w1和w2是控制輸入信號的重要性的引數,而偏置是調 整神經元被激活的容易程度(輸出信號為1的程度)的引數,
#用感知機實作與門
def AND(x1, x2):
x = np.array([x1, x2])
w = np.array([0.5, 0.5])
b = -0.7
tmp = np.sum(w*x) + b
if tmp <= 0:
return 0
else:
return 1
#用感知機實作與非門
def NAND(x1, x2):
x = np.array([x1, x2])
w = np.array([-0.5, -0.5]) # 僅權重和偏置與AND不同!
b = 0.7
tmp = np.sum(w*x) + b
if tmp <= 0:
return 0
else:
return 1
#用感知機實作或門
def OR(x1, x2):
x = np.array([x1, x2])
w = np.array([0.5, 0.5]) # 僅權重和偏置與AND不同!
b = -0.2
tmp = np.sum(w*x) + b
if tmp <= 0:
return 0
else:
return 1-
使用感知機可以表示與門和或門等邏輯電路.
現在,我們用Python來實作剛才的邏輯電路,這里,先定義一個接收 引數x1和x2的AND函式,
def AND(x1, x2): w1, w2, theta = 0.5, 0.5, 0.7 tmp = x1*w1 + x2*w2 if tmp <= theta: return 0 elif tmp > theta: return 1 AND(0, 0) # 輸出0 AND(1, 0) # 輸出0 AND(0, 1) # 輸出0 AND(1, 1) # 輸出1在函式內初始化引數w1、w2、theta,當輸入的加權總和超過閾值時回傳1, 否則回傳0
-
感知機的局限性:異或門無法通過單層感知機來表示,
感知機的局限性就在于它只能表示由一條直線分割的空間,
彎曲的曲線無法用感知機表示,另外,由曲線分割而成的空間稱為 非線性空間,由直線分割而成的空間稱為線性空間
-
使用2層感知機可以表示異或門,
使用之前定義的 AND函式、NAND函式、OR函式,可以像下面這樣(輕松地)實作,
def XOR(x1, x2): s1 = NAND(x1, x2) s2 = OR(x1, x2) y = AND(s1, s2) return y XOR(0, 0) # 輸出0 XOR(1, 0) # 輸出1 XOR(0, 1) # 輸出1 XOR(1, 1) # 輸出0
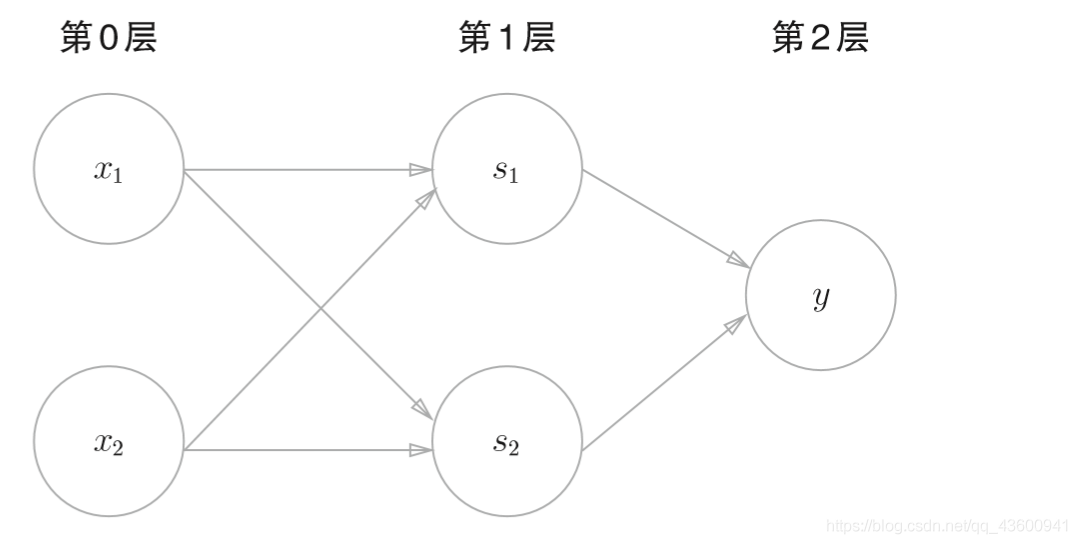
感知機總共由3層構成,但是因為擁有權重的層實質 上只有2層(第0層和第1層之間,第1層和第2層之間),所以稱 為“2層感知機”,不過,有的文獻認為圖2-13的感知機是由3層 構成的,因而將其稱為“3層感知機”,
-
單層感知機只能表示線性空間,而多層感知機可以表示非線性空間,
-
多層感知機(在理論上)可以表示計算機,
第三章 神經網路
1.神經網路是什么?
神經網路是一種計算模型,由大量的節點(或神經元)直接相互關聯而構成
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-BIAJwFae-1600781438228)(../Pictures/Saved Pictures/神經網路.jpg)]](https://img.uj5u.com/2020/09/24/100140241135505.jpg)
2.為什么還要學習神經網路?
回顧:感知機的缺陷
設定權重的作業,即確定合適的、能符合預期的輸 入與輸出的權重,現在還是由人工進行的,上一章中,我們結合與門、或門 的真值表人工決定了合適的權重,
神經網路的出現就是為了解決剛才的壞訊息,具體地講,神經網路的一 個重要性質是它可以自動地從資料中學習到合適的權重引數,
3.學習神經網路的哪些知識?
3.1激活函式
神經網路中的激活函式使用平滑變化的sigmoid函式或ReLU函式,
激活函式的作用在于決定如何來激活輸入信號的總和,
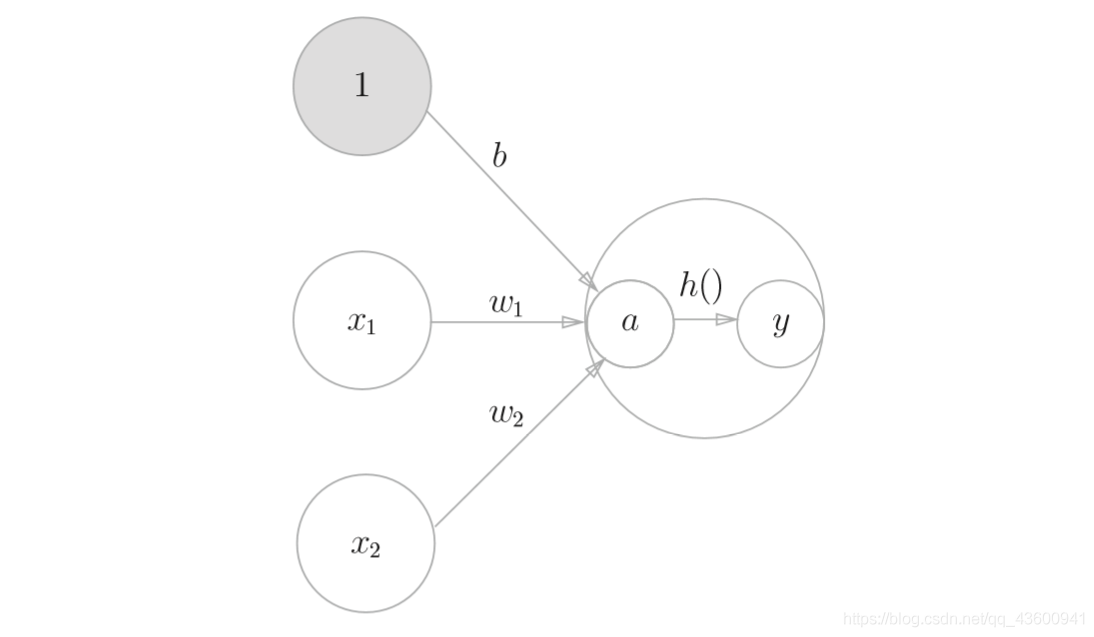
首先,式(3.4)計算加權輸入信號和偏置的總和,記為a,然后,式(3.5) 用h()函式將a轉換為輸出y,
如果要在圖中明確表示出式(3.4) 和式(3.5),則可以像圖3-4這樣做,
? ![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-2jQez129-1600781438232)(../Pictures/Saved Pictures/激活函式式子.png)]](https://img.uj5u.com/2020/09/24/100140241135506.png)
神經網路中經常使用的一個激活函式就是式(3.6)表示的sigmoid函式 (sigmoid function),
? ![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-lHyy4eYC-1600781438238)(../Pictures/Saved Pictures/sigmoid函式.png)]](https://img.uj5u.com/2020/09/24/100140241135508.png)
神經網路中用sigmoid函式作為激活函式,進行信號的轉換,轉換后的信號被傳送給下一個神經元,實際上,上一章介紹的感知機 和接下來要介紹 的神經網路的主要區別就在于這個激活函式,
sigmoid函式很早就開始被使用了,而最近則主要 使用ReLU(Rectified Linear Unit)函式,
ReLU函式在輸入大于0時,直接輸出該值;在輸入小于等于0時,輸 出0(圖 3-9),
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-03wscLGe-1600781438239)(../Pictures/Saved Pictures/ReLU函式.png)]](https://img.uj5u.com/2020/09/24/100140241135509.png)
3.2 多維陣列的運算
通過巧妙地使用NumPy多維陣列,可以高效地實作神經網路,
np.dot():接收兩個NumPy陣列作為參 數,并回傳陣列的乘積,這里要注意的是,np.dot(A, B)和np.dot(B, A)的 值可能不一樣,
(做矩陣乘法)
2×3的矩陣A和3×2的矩陣B的乘積可按以上方式實作,這里需要 注意的是矩陣的形狀(shape),具體地講,矩陣A的第1維的元素個數(列數) 必須和矩陣B的第0維的元素個數(行數)相等
下面我們使用NumPy矩陣來實作3層神經網路,
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-kHAZfJU9-1600781438242)(../Pictures/Saved Pictures/NumPy實作神經網路.png)]](https://img.uj5u.com/2020/09/24/1001402411355010.png)
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-7dEAriHJ-1600781438244)(../Pictures/Saved Pictures/符號確認.png)]](https://img.uj5u.com/2020/09/24/1001402411355011.png)
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-pEA7enGK-1600781438247)(../Pictures/Saved Pictures/從輸入層到第1層的信號傳遞.png)]](https://img.uj5u.com/2020/09/24/1001402411355012.png)
? 從輸入層到第1層的信號傳遞
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-gDlO4Zft-1600781438250)(../Pictures/Saved Pictures/第1層到第2層的信號傳遞.png)]](https://img.uj5u.com/2020/09/24/1001402411355013.png)
? 第1層到第2層的信號傳遞
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-c39Gtd1D-1600781438253)(../Pictures/Saved Pictures/從第2層到輸出層的信號傳遞.png)]](https://img.uj5u.com/2020/09/24/1001402411355014.png)
? 從第2層到輸出層的信號傳遞
實作該神經網路時,要注意X、W、Y的形狀,特別是X和W的對應 維度的元素個數是否一致,這一點很重要,
3.3輸出層的設計
關于輸出層的激活函式,回歸問題中一般用恒等函式,分類問題中 一般用softmax函式,
分類問題中使用的softmax函式可以用下面的式(3.10)表示,
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-6uxEHzn2-1600781438254)(../Pictures/Saved Pictures/softmax運算式.png)]](https://img.uj5u.com/2020/09/24/1001402411355015.png)
exp(x)是表示ex的指數函式(e是納皮爾常數2.7182…),式( 3.10)表示 假設輸出層共有n個神經元,計算第k個神經元的輸出yk,如式(3.10)所示, softmax函式的分子是輸入信號ak的指數函式,分母是所有輸入信號的指數 函式的和,
輸出總和為1是softmax函式的一個重要性質,正 因為有了這個性質,我們才可以把softmax函式的輸出解釋為“概率”,
上面的softmax函式的實作雖然正確描述了式(3.10),但在計算機的運算 上有一定的缺陷,這個缺陷就是溢位問題
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-HJESrh2G-1600781438256)(../Pictures/Saved Pictures/softmax.png)]](https://img.uj5u.com/2020/09/24/1001402411355016.png)
分類問題中,輸出層的神經元的數量設定為要分類的類別數,
3.4 運用:手寫數字識別
資料集的準備:這里使用的資料集是MNIST手寫數字影像集,
步驟:先用訓練影像進行學習,再用學習到的模型度量能在多大程度 上對測驗影像進行正確的分類,
關于具體內容,詳見《深度學習入門:基于Python的理論與實作》一書中的P69~P75(3.6節)及配套的代碼,
3.5 批處理
上面的應用實體是只輸入一張影像資料時的處理流程,現在我們來考慮打包輸入多張影像的情形,比如,我們想用predict() 函式一次性打包處理100張影像,這時該怎么辦呢?
為此,可以把x的形狀改為100×784,將 100張影像打包作為輸入資料,
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-v67xVBRx-1600781438259)(../Pictures/Saved Pictures/批處理.png)]](https://img.uj5u.com/2020/09/24/1001402411355017.png)
這種打包式的輸入資料稱為批(batch),批有“捆”的意思,影像就如同 紙幣一樣扎成一捆,
x, t = get_data()
network = init_network()
batch_size = 100 # 批數量
accuracy_cnt = 0
for i in range(0, len(x), batch_size):
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1)
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
Tips: ① 通過x[i:i+batch_size]從輸入數 據中抽出批資料,x[i:i+batch_n]會取出從第i個到第i+batch_n個之間的資料,
? ② 通過argmax()獲取值最大的元素的索引,
? ③ 比較一下以批為單位進行分類的結果和實際的答案,
? NumPy陣列之間使用比較運算子(==)生成由True/False構成的布爾 型陣列,并計算True的個數,
輸入資料的集合稱為批,通過以批為單位進行推理處理,能夠實作 高速的運算,
批處理一次性計算大型陣列要比分開逐步計算 各個小型陣列速度更快,
這是因為大多數處理 數值計算的庫都進行了能夠高效處理大型陣列運算的最優化
小結:本章介紹了神經網路的前向傳播,本章介紹的神經網路和上一章的感知 機在信號的按層傳遞這一點上是相同的,但是,向下一個神經元發送信號時, 改變信號的激活函式有很大差異,神經網路中使用的是平滑變化的sigmoid 函式,而感知機中使用的是信號急劇變化的階躍函式,這個差異對于神經網 絡的學習非常重要,我們將在下一章介紹,
第四章 神經網路學習
1.神經網路學習是什么?
這里所說的**“學習”**是指從訓練資料中 自動獲取最優權重引數的程序,
為了使神經網路能進行學習,將導 入損失函式這一指標,
而學習的目的就是以該損失函式為基準,找出能使它 的值達到最小的權重引數,
為了找出盡可能小的損失函式的值,本章我們將 介紹利用了函式斜率的梯度法,
2.為什么要引入神經網路的學習?
在第2章介紹的感知機的例 子中,我們對照著真值表,人工設定了引數的值,但是那時的引數只有3個, 而在實際的神經網路中,引數的數量成千上萬,在層數更深的深度學習中, 引數的數量甚至可以上億,想要人工決定這些引數的值是不可能的,
3.學習哪些內容?
3.1資料驅動(資料是機器學習的命根子)
從零開始想出一個可以識別的演算法,
使用特征量和機器學習的方法,
神經網路直接學習影像本身,
以上的三種方式中:第1個方法完全是有人從零開始想出的演算法;
? 在第2個方法,即利用特征量和機器學習的方法中,特征量仍是由人工設計的,
? 而在神經網路中,連影像中包含的重要特征量也都是由機器來學習的,沒有人為介入,
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-0KwgKmzz-1600781438262)(../Pictures/Saved Pictures/資料驅動.png)]](https://img.uj5u.com/2020/09/24/1001402411355018.png)
神經網路的優點是對所有的問題都可以用同樣的流程來解決,
也就是說,與 待處理的問題無關,神經網路可以將資料直接作為原始資料,進行“端對端” 的學習,
3.2 訓練資料和測驗資料
機器學習中使用的資料集分為訓練資料和測驗資料,
首先,使用訓練資料進行學習,尋找最優的引數;然后,使用測驗資料評價訓練得到的模型的實際能力
Q:為什么需要將資料分為訓練資料和測 試資料呢?
A:因為我們追求的是模型的泛化能力,為了正確評價模型的泛化能 力,就必須劃分訓練資料(監督資料)和測驗資料,
Tips: 泛化能力 是指處理未被觀察過的資料(不包含在訓練資料中的資料)的 能力,
? 獲得泛化能力是機器學習的最終目標,
神經網路用訓練資料進行學習,并用測驗資料評價學習到的模型的泛化能力,
3.3 損失函式
損失函式是什么?
損失函式是表示神經網路性能的**“惡劣程度”的指標,即當前的 神經網路對監督資料在多大程度上不擬合**,在多大程度上不一致,
均方誤差
可以用作損失函式的函式有很多,其中最有名的是均方誤差(mean squared error),均方誤差如下式所示,
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-wwsmpI7I-1600781438264)(../Pictures/Saved Pictures/均方誤差.png)]](https://img.uj5u.com/2020/09/24/1001402411355019.png)
? yk是表示神經網路的輸出,tk表示監督資料,k表示資料的維數,
交叉熵誤差
除了均方誤差之外,交叉熵誤差(cross entropy error)也經常被用作損 失函式,交叉熵誤差如下式所示,
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-2R5xB77z-1600781438266)(../Pictures/Saved Pictures/交叉熵誤差.png)]](https://img.uj5u.com/2020/09/24/1001402411355020.png)
? 這里,log表示以e為底數的自然對數(log e), yk是神經網路的輸出,tk是 正確解標簽,
交叉熵誤差的值是由正確解標簽所對應的輸出結果決定的,
mini-batch學習
神經網路的學習是從訓練資料中選出一批資料(稱為mini-batch,小批量),然后對每個mini-batch進行學習,
比如,從60000個訓練資料中隨機選擇10筆,再用這10筆資料進行學習,這種學習方式稱為mini-batch學習,
Q:如何從這個訓練資料中隨機抽取10筆資料呢?
A:可以使用 NumPy的np.random.choice()
使用np.random.choice()可以從指定的數字中隨機選擇想要的數字,
比如, np.random.choice(60000, 10)會從0到59999之間隨機選擇10個數字,
mini-batch的損失函式也是利用 一部分樣本資料來近似地計算整體,也就是說,用隨機選擇的小批 量資料(mini-batch)作為全體訓練資料的近似值,
為何要設定損失函式?為什么不以識別精度為指標?
- 在進行神經網路的學習時,不能將識別精度作為指標,因為如果以 識別精度為指標,則引數的導數在絕大多數地方都會變為0,
- 識別精度對微小的引數變化基本上沒有什么反應,即便有反應,它的值 也是不連續地、突然地變化,
拓展:
作為激活函式的階躍函式也有同樣的情況,出 于相同的原因,如果使用階躍函式作為激活函式,神經網路的學習將無法進行,
如果使用了階躍函式,那么即便將損失函式作為指標,引數的微小變化也會被階躍函式抹殺,導致損失函式的值不會產生任何變化,
也就是說,sigmoid函式的導數在任何地方都不為0,這對 神經網路的學習非常重要,得益于這個斜率不會為0的性質,神經網路的學 習得以正確進行,
神經網路的學習以損失函式為指標,更新權重引數,以使損失函式 的值減小,
3.4 數值微分
利用某個給定的微小值的差分求導數的程序,稱為數值微分,
偏導數和單變數的導數一樣,都是求某個地方的斜率,不過, 偏導數需要將多個變數中的某一個變數定為目標變數,并將其他變數固定為 某個值,
3.5 梯度
另外,像 這樣的由全部變數的偏導數匯總 而成的向量稱為梯度(gradient),
比如,我們來考慮求x0 = 3,x1 = 4時(x0,x1) 的偏導數
利用數值微分,可以計算權重引數的梯度,
f(x0+x1)=x0**2+x1**2的梯度呈現為有向向量(箭頭),觀 察圖4-9,我們發現梯度指向函式f(x0,x1)的“最低處”(最小值),就像指南針 一樣,所有的箭頭都指向同一點,其次,我們發現離“最低處”越遠,箭頭越大,
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-Uw60FGzt-1600781438270)(../Pictures/Saved Pictures/梯度.png)]](https://img.uj5u.com/2020/09/24/1001402411355021.png)
更嚴格地講,梯度指示的方向 是各點處的函式值減小最多的方向A
梯度法 : 通過巧妙地使用梯度來尋找函式最小值 (或者盡可能小的值)的方法就是梯度法,
? 機器學習的主要任務是在學習時尋找最優引數,同樣地,神經網路也必 須在學習時找到最優引數(權重和偏置),
這里所說的最優引數是指損失函式取最小值時的引數,
這里需要注意的是,梯度表示的是各點處的函式值減小最多的方向,因此, 無法保證梯度所指的方向就是函式的最小值或者真正應該前進的方向,實際 上,在復雜的函式中,梯度指示的方向基本上都不是函式值最小處,
函式的極小值、最小值以及被稱為鞍點(saddle?point)的地方, 梯度為0,
極小值:是區域最小值,也就是限定在某個范圍內的最小值,
鞍點:是從某個方向上看是極大值,從另一個方向上看則是 極小值的點,
雖然梯度法是要尋找梯度為0的地方,但是那個地方不一定就是最小值(也有可能是極小值或者鞍點),
此外,當函式很復雜且呈扁平狀時,學習可能會進入一個(幾乎)平坦的地區, 陷入被稱為“學習高原”的無法前進的停滯期,
梯度法的思路:在梯度法中,函式的取值從當前位置沿著梯度方向前進一定距離,然后在新的地方重新求梯度,再沿著新梯度方向前進, 如此反復,不斷地沿梯度方向前進,
尋找最小值的梯度法稱為梯度下降法(gradient?descent?method) , 尋找最大值的梯度法稱為梯度上升法(gradient?ascent?method),一般來說,**神經網路**(深度學習)中,梯度法主要是指**梯度下降法**,
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-GCawuc3z-1600781438272)(../Pictures/Saved Pictures/梯度法數學式.png)]](https://img.uj5u.com/2020/09/24/1001402411355022.png)
η表示更新量,在神經網路的學習中,稱為學習率(learning rate),
學習率決定在一次學習中,應該學習多少,以及在多大程度上更新引數,
下面,我們用Python來實作梯度下降法,如下所示,這個實作很簡單,
def gradient_descent(f, init_x, lr=0.01, step_num=100):
x = init_x
for i in range(step_num):
grad = numerical_gradient(f, x)
x -= lr * grad
return x 引數f是要進行最優化的函式,init_x是初始值,lr是學習率learning rate,
step_num是梯度法的重復次數,
numerical_gradient(f,x)會求函式的梯度,用該梯度乘以學習率得到的值進行更新操作,由step_num指定重復的次數,
問題:請用梯度法求f(x0+x1)的最小值,
>>> def function_2(x):
>>> return x[0]**2 + x[1]**2
>>> init_x = np.array([-3.0, 4.0])
>>> gradient_descent(function_2, init_x=init_x, lr=0.1, step_num=100)
array([ -6.11110793e-10, 8.14814391e-10])
這里,設初始值為(-3.0, 4.0),開始使用梯度法尋找最小值,最終的結 果是(-6.1e-10, 8.1e-10),非常接近(0,0),實際上,真的最小值就是(0,0), 所以說通過梯度法我們基本得到了正確結果,
![[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-A1XwsQXX-1600781438275)(../Pictures/Saved Pictures/梯度法.png)]](https://img.uj5u.com/2020/09/24/1001402411355023.png)
實驗結果表明,學習率過大的話,會發散成一個很大的值;反過來,學 習率過小的話,基本上沒怎么更新就結束了,也就是說,設定合適的學習率 是一個很重要的問題,
Tips: 像學習率這樣的引數稱為超引數,學習率這樣的超引數則是人工設定的,
3.6 神經網路的學習步驟
前提 神經網路存在合適的權重和偏置,***調整權重和偏置***以便擬合訓練資料的 程序稱為“學習”,
? 神經網路的學習分成下面4個步驟,
步驟1(mini-batch) 從訓練資料中隨機選出一部分資料,這部分資料稱為mini-batch,我們 的目標是減小mini-batch的損失函式的值,
步驟2(計算梯度) 為了減小mini-batch的損失函式的值,需要求出各個權重引數的梯度, 梯度表示損失函式的值減小最多的方向,
步驟3(更新引數) 將權重引數沿梯度方向進行微小更新,
步驟4(重復) 重復步驟1、步驟2、步驟3,
練習:手寫數字識別的神經網路
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/118670.html
標籤:其他
上一篇:用QT設定主板IP
下一篇:演算法競賽入門 — 素數篩