根據前面2部分對benchmark_app的分析,重新改寫了一下benchmark的代碼,主要去掉了命令傳遞引數的方法,所有引數改為代碼里hard code;去掉了智能指標之類的高級用法,只使用簡單的作業系統提供的多執行緒同步介面。這么做的目的是為了以后把inference這部分作為一個模塊,可以更簡單的集成進自己的程式里 :)
首先看一下純CPU的mobilenet-ssd FP32模型的推理性能, 我手里是個i5 7440HQ的4核4執行緒的移動處理器,
首先batch size = 1,即每次推理只輸入一張圖片,
inference request(nireq) = 1時,即同時只有一個推理請求
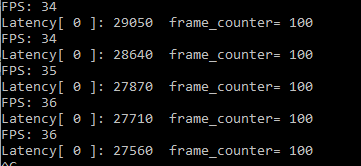
每推理100幀計算列印一下單次推理所需的時間Latency(us),以及總的推理性能throughput (FPS)
此時Latency為28ms左右, Throughtput為36FPS
inference request(nireq) = 4時,即設定CPU_THROUGHPUT_STREAMS = CPU_THROUGHPUT_AUTO時,openvino建議的并發數為4, 同時并發4個推理請求
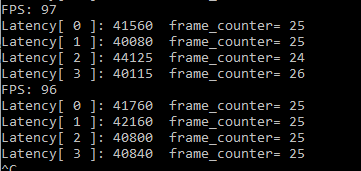
此時Latency為40ms左右, Throughtput為96FPS
可以看到同時并發4路推理時,單路推理的時間會變長,但是總的吞吐量大大提升,說明硬體被更充分的利用了。同時每路推理處理的幀數大致相同,大約25frame左右,一致性還不錯,基本上可以保證先推理先結束
接下來看看batch size = 3,inference request(nireq) = 4時。即每次推理處理三張圖片, 4路推理并發
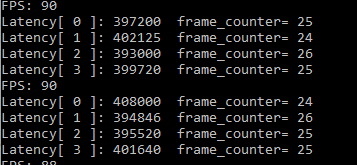
隨著單次推理資料的增大,單幀Latency略有變大(這里代碼寫錯了,真實數字應該除以9),FPS也略有下降。增大單次資料量對性能反而有負面影響。說明硬體的處理能力也就這么回事了,再多的資料也只能增加程式反復調度的開銷,無法在性能上再進一步了。
最后測一下純CPU的mobilenet-ssd FP16模型的性能,發現性能和FP32基本一致。這也印證了openvino官網上說的, CPU的推理時,如果加載FP16的模型,會在加載時把FP16轉為FP32
簡單總結一下,OpenVINO的CPU推理
推理并發數決定了Lantency的大小,如果需要快速得到推理結果,最好并發數為1,即讓openvino集中所有硬體做單次推理。如果要獲得高吞吐量,則需要增多并發數。
CPU推理時的"CPU_BIND_THREAD"基本是雞肋,因為并不能指定bind到哪顆物理內核,所以可能會造成負面影響(和其他代碼都綁到同一個物理核上)
CPU推理時加載FP32/FP16模型,推理性能是一樣的
CPU推理非常容易受到后臺程式的影響,比如后臺的病毒掃描,或者windows update執行緒,性能可能會下降超過10%
極限挖掘CPU推理性能時很容易造成CPU過熱導致降頻,這時候可以聽到風扇狂響,這時候性能也會急劇會下降
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/135568.html
標籤:英特爾技術
上一篇:qtablewidget控制元件,使用setitem,添加資料,不顯示上一行問題
下一篇:基于openvino 2019R3的推理性能優化的學習與分析 (五) 基于CPU/GPU混合運算的推理(inference)性能分析