接下來是個失敗的例子 MoiblenetV3
老規矩,先下模型,轉換模型,再測benchmark
從這里下載模型https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet 下載Large dm=1 (float)這個模型,然后轉換成OpenVINO FP32模型
python "c:\Program Files (x86)\IntelSWTools\openvino\deployment_tools\model_optimizer\mo_tf.py" --reverse_input_channels --input_shape=[1,224,224,3] --input=input --mean_values=input[127.5,127.5,127.5] --scale_values=input[127.5] --output=MobilenetV3/Predictions/Softmax --input_model=v3-large_224_1.0_float.pb
Benchmark FP32模型
benchmark_app.exe -m mobilenetV3\FP32\v3-large_224_1.0_float.xml -nireq 1 -nstreams 1 -b 1 -pc
轉換INT8模型
python "c:\Program Files (x86)\IntelSWTools\openvino\deployment_tools\tools\calibration_tool\calibrate.py" -sm -m v3-large_224_1.0_float.xml -e C:\Users\???\Documents\Intel\OpenVINO\inference_engine_samples_build\intel64\Release\cpu_extension.dll
Benchmark INT8模型
benchmark_app.exe -m mobilenetV3\u8\v3-large_224_1.0_float_i8.xml -nireq 1 -nstreams 1 -b 1 -pc
直接上結果吧
FP32的
Full device name: Intel(R) Core(TM) i5-7440HQ CPU @ 2.80GHz
Count: 7882 iterations
Duration: 60011.97 ms
Latency: 6.37 ms
Throughput: 131.34 FPS
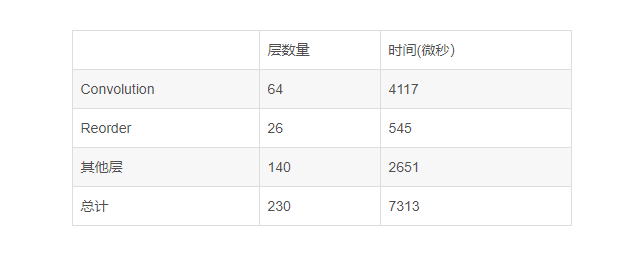
INT8
Full device name: Intel(R) Core(TM) i5-7440HQ CPU @ 2.80GHz
Count: 3529 iterations
Duration: 60022.03 ms
Latency: 16.26 ms
Throughput: 58.80 FPS
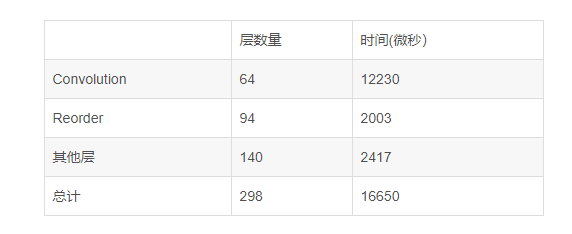
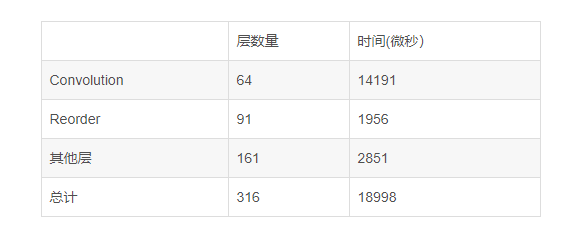
這個可是真的是大踏步的倒退啊,不僅INT8的卷積時間長,而且增加了68層的Reorder層,說明推理時在不停的在INT8和FP32間反復切換。
沒辦法,一個問題一個問題的找原因。
INT8卷積時間長
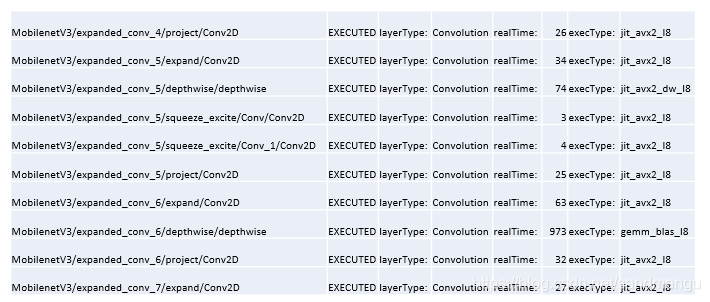
把Convolution層的時間都拉出來,發現里面depthwise Convolution都是基于gemm_blas_I8的計算, 時間超長。查了下OpenVINO 2019 Release Notes Known issue 23有這個問題,估計在2020版本里會解決

增加了68層的Reorder層
參照一下卷積的計算型別,再查一下MKL-DNN的檔案,MKL-DNN在做FP32卷積的時候,首選的記憶體排列方式是nChw8c,而INT8卷積喜歡的記憶體排列是nhwc,所以為了提高卷積計算的效率,不同精度的卷積計算間都要插入一個Reorder來重新調整資料格式。
為什么MobilenetV2沒有這個問題?再對比一下mobilenet v2/v3的網路架構
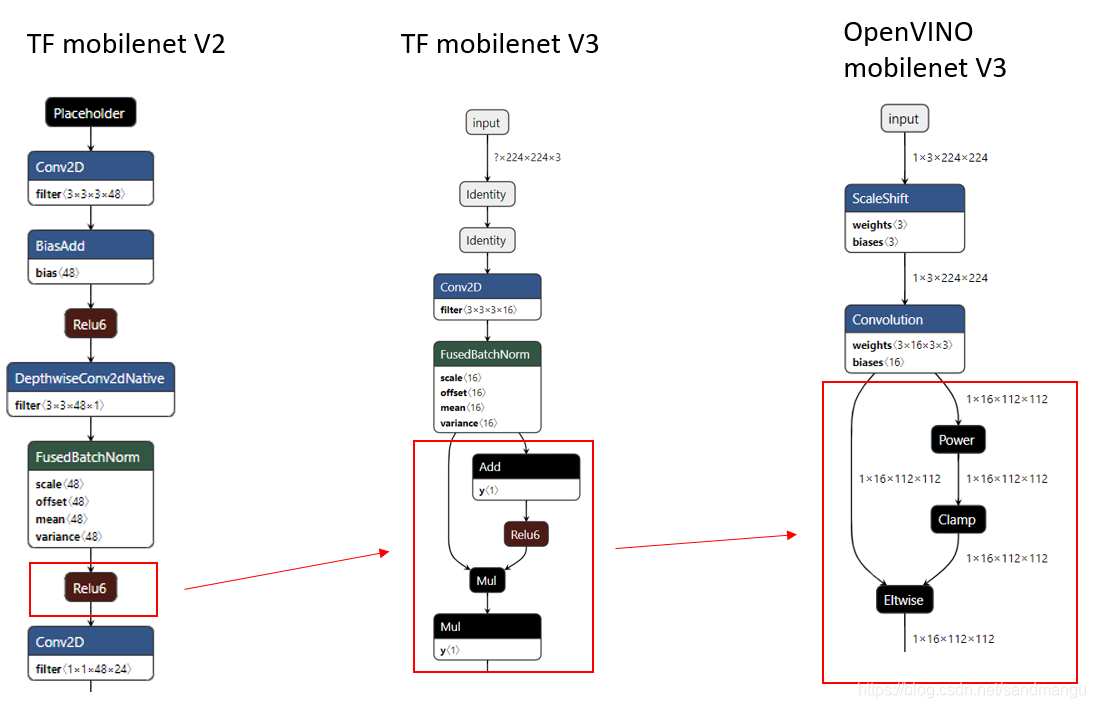
原來是mobilnetV3換了新的激活函式 h-swish[x] (MobilenetV2是Relu6)
估計OpenVINO和MKL-DNN還沒有對這種新的演算法做處理,導致卷積出來的基于INT8的x不知道怎么加那個3 (同樣需要轉成INT8). 所以沒辦法, INT8的x只能轉回到FP32域去繼續做激活函式,沒辦法像mobilenetV2一樣利用MKL-DNN的post-ops做合并和優化。
到這里,基本上就可以放棄了,看來OpenVINO 2019R3在演算法上就缺少對mobilenetV3新激活函式演算法的支持,只能等今后的更新了 :)
最后手欠了一下, 直接從官網下載了8-bit的模型Large dm=1 (8-bit) ,轉出來看看效率,直接上結果:比calibration tool轉出來的int8模型效率還低。一樣的原因, 基于gemm_blas_I8的卷積和過多的Reorder層小號了大量的時間
tensorflow 8-bit模型直轉:
最后總結一下目前看到的評估OpenVINO2019R3 INT8模型效率的基本邏輯
首先這個模型需要包含大量的卷積層,并且占模型推理的主要時間,這種模型才有轉INT8提高性能的可能性
用calibration tool(calibrate.py -sm) 快速轉出一個INT8模型
轉換后網路層不能增加太多,標志著沒有過多的FP32/INT8之間的資料轉換,這樣的模型通常比較適合INT8優化
用benchmark -api sync跑一下, 對比FP32模型實際看看有沒有實際性能提升
3. 如果上述2步有很好的性能提升結果的話再做完整的calibrate轉換,最終模型因為要保證精度,可能會有一些性能下降
4. 有時候直接轉換原始的int8模型并不能帶來太好的性能提升
5. 如果不介意OpenVINO版本,可以同步測驗一下OpenVINO 最新版本的性能,從2020版的Release notes上看,INT8的部分的演算法改動比較大,另外Calibration Tool也升級到了POT,需要重新學習, 那個Gemm_blas_l8卷積速度慢的問題可能也會在某個新版本里解決 (我個人喜歡用老的穩定版本,新版本出來以后通常等幾個月再玩,以免趟雷)
6. 等OpenVINO支持GPU int8計算以后,需要重新研究一下性能,因為GPU做卷積可能不需要reorder, 也不需要那個gemm_blas_I8的演算法
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/135600.html
標籤:英特爾技術
上一篇:QT使用自定義控制元件的問題