葵花寶典------Hadoop
- 1. hdfs讀寫流程
- 2. hdfs的體系結構
- 3. 一個datanode 宕機,怎么一個流程恢復
- 4. hadoop 的 namenode 宕機,怎么解決
- 5. namenode對元資料的管理
- 6. 元資料的checkpoint
- 7. yarn資源調度流程
- 8. hadoop中combiner和partition的作用
- 9. 用mapreduce怎么處理資料傾斜問題?
- 10. shuffle 階段,你怎么理解的
- 11. Mapreduce 的 map 數量 和 reduce 數量是由什么決定的 ,怎么配置
- 12. MapReduce優化經驗
- 13. 分別舉例什么情況要使用 combiner,什么情況不使用?
- 14. 簡單描述一下HDFS的系統架構,怎么保證資料安全?
- 15. 在通過客戶端向hdfs中寫資料的時候,如果某一臺機器宕機了,會怎么處理
- 16. Hadoop優化有哪些方面
- 17. 大量資料求topN(寫出mapreduce的實作思路)
- 18. 列出正常作業的hadoop集群中hadoop都分別啟動哪些行程以及他們的作用
- 19. Hadoop總job和Tasks之間的區別是什么?
- 20. Hadoop高可用HA模式
- 21. 簡要描述安裝配置一個hadoop集群的步驟
- 22. fsimage和edit的區別
- 23. yarn的三大調度策略
1. hdfs讀寫流程
hdfs寫流程
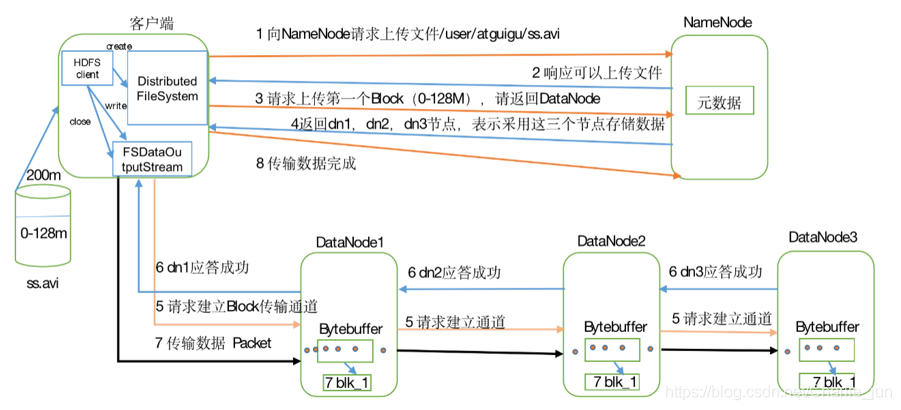
1、客戶端跟namenode通信請求上傳檔案,namenode檢查目標檔案是否已存在,父目錄是否存在
2、namenode回傳是否可以上傳
3、client請求第一個 block該傳輸到哪些datanode服務器上
4、namenode回傳3個datanode服務器ABC
5、client請求3臺dn中的一臺A上傳資料(本質上是一個RPC呼叫,建立pipeline),A收到請求會繼續呼叫B,
然后B呼叫C,將真個pipeline建立完成,逐級回傳客戶端
6、client開始往A上傳第一個block(先從磁盤讀取資料放到一個本地記憶體快取),以packet為單位,A收到一個
packet就會傳給B,B傳給C;A每傳一個packet會放入一個應答佇列等待應答
7、當一個block傳輸完成之后,client再次請求namenode上傳第二個block的服務器,
hdfs讀流程
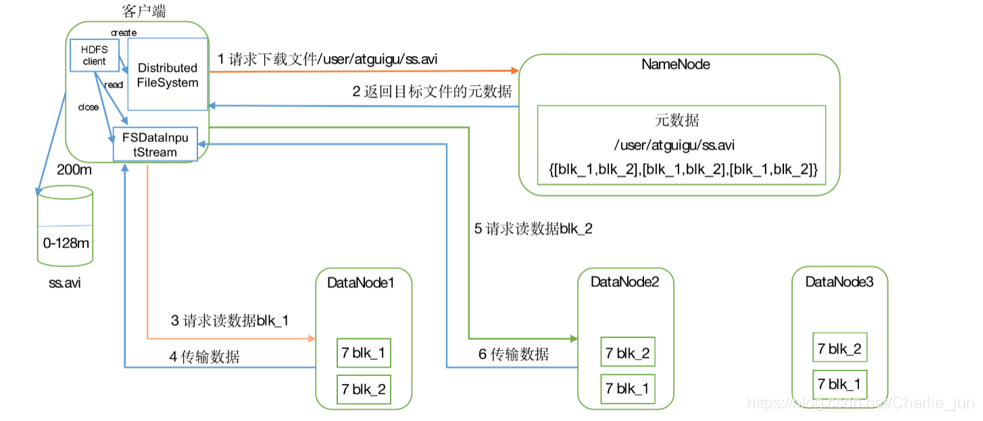
1、client跟namenode通信查詢元資料,找到檔案塊所在的datanode服務器
2、挑選一臺datanode(就近原則,然后隨機)服務器,請求建立socket流
3、datanode開始發送資料(從磁盤里面讀取資料放入流,以packet為單位來做校驗)
4、客戶端以packet為單位接收,現在本地快取,然后寫入目標檔案
2. hdfs的體系結構
1、hdfs有namenode、secondraynamenode、datanode組成,為n+1模式
2、NameNode負責管理和記錄整個檔案系統的元資料
3、DataNode 負責管理用戶的檔案資料塊,檔案會按照固定的大小(blocksize)切成若干塊后分布式存盤在若干
臺datanode上,每一個檔案塊可以有多個副本,并存放在不同的datanode上,Datanode會定期向Namenode
匯報自身所保存的檔案block資訊,而namenode則會負責保持檔案的副本數量
4、HDFS的內部作業機制對客戶端保持透明,客戶端請求訪問HDFS都是通過向namenode申請來進行
5、secondraynamenode負責合并日志
3. 一個datanode 宕機,怎么一個流程恢復
Datanode宕機了后,如果是短暫的宕機,可以實作寫好腳本監控,將它啟動起來,如果是長時間宕機了,
那么datanode上的資料應該已經被備份到其他機器了,那這臺datanode就是一臺新的datanode了,
洗掉他的所有資料檔案和狀態檔案,重新啟動,
4. hadoop 的 namenode 宕機,怎么解決
先分析宕機后的損失,宕機后直接導致client無法訪問,記憶體中的元資料丟失,但是硬碟中的元資料應該還存在,
如果只是節點掛了,重啟即可,如果是機器掛了,重啟機器后看節點是否能重啟,不能重啟就要找到原因修復了,
但是最終的解決方案應該是在設計集群的初期就考慮到這個問題,做namenode的HA,
5. namenode對元資料的管理
namenode對資料的管理采用了三種存盤形式:
1、記憶體元資料(NameSystem)
2、磁盤元資料鏡像檔案(fsimage鏡像)
3、資料操作日志檔案(可通過日志運算出元資料)(edit日志檔案)
6. 元資料的checkpoint
每隔一段時間,會由secondary namenode將namenode上積累的所有edits和一個最新的fsimage下載到本地,
并加載到記憶體進行merge(這個程序稱為checkpoint)
namenode和secondary namenode的作業目錄存盤結構完全相同,所以,當namenode故障退出需要重新恢復時
可以從secondary namenode的作業目錄中將fsimage拷貝到namenode的作業目錄,以恢復namenode的元資料
7. yarn資源調度流程
1、用戶向YARN 中提交應用程式, 其中包括ApplicationMaster 程式、啟動ApplicationMaster 的命令、
用戶程式等,
2、ResourceManager 為該應用程式分配第一個Container, 并與對應的NodeManager 通信,要求它在這個
Container 中啟動應用程式的ApplicationMaster,
3、ApplicationMaster 首先向ResourceManager 注冊, 這樣用戶可以直接通過ResourceManage 查看
應用程式的運行狀態,然后它將為各個任務申請資源,并監控它的運行狀態,直到運行結束,即重復步驟4~7
4、ApplicationMaster 采用輪詢的方式通過RPC 協議向ResourceManager 申請和領取資源,
5、一旦ApplicationMaster 申請到資源后,便與對應的NodeManager 通信,要求它啟動任務,
6、NodeManager 為任務設定好運行環境(包括環境變數、JAR 包、二進制程式等)后,將任務啟動命令
寫到一個腳本中,并通過運行該腳本啟動任務,
7、各個任務通過某個RPC 協議向ApplicationMaster 匯報自己的狀態和進度,以讓ApplicationMaster
隨時掌握各個任務的運行狀態,從而可以在任務失敗時重新啟動任務,在應用程式運行程序中,用戶可
隨時通過RPC 向ApplicationMaster 查詢應用程式的當前運行狀態,
8、應用程式運行完成后,ApplicationMaster 向ResourceManager 注銷并關閉自己,
8. hadoop中combiner和partition的作用
1、combiner是發生在map的最后一個階段,父類就是Reducer,意義就是對每一個maptask的輸出進行
區域匯總,以減小網路傳輸量,緩解網路傳輸瓶頸,提高reducer的執行效率,
2、partition的主要作用將map階段產生的所有kv對分配給不同的reducer task處理,可以將reduce階段的
處理負載進行分攤
9. 用mapreduce怎么處理資料傾斜問題?
資料傾斜:map /reduce程式執行時,reduce節點大部分執行完畢,但是有一個或者幾個reduce節點
運行很慢,導致整個程式的處理時間很長,這是因為某一個key的條數比其他key多很多(有時是百倍或
者千倍之多),這條key所在的reduce節點所處理的資料量比其他節點就大很多,從而導致某幾個節點
遲遲運行不完,此稱之為資料傾斜,
(1)區域聚合加全域聚合,
第一次在 map 階段對那些導致了資料傾斜的 key 加上 1 到 n 的隨機前綴,這樣本來相同的 key 也
會被分到多個 Reducer 中進行區域聚合,數量就會大大降低,
第二次 mapreduce,去掉 key 的隨機前綴,進行全域聚合,
思想:二次 mr,第一次將 key 隨機散列到不同 reducer 進行處理達到負載均衡目的,第
二次再根據去掉 key 的隨機前綴,按原 key 進行 reduce 處理,
這個方法進行兩次 mapreduce,性能稍差,
(2)增加 Reducer,提升并行度
JobConf.setNumReduceTasks(int)
(3)實作自定義磁區
根據資料分布情況,自定義散列函式,將 key 均勻分配到不同 Reducer
10. shuffle 階段,你怎么理解的
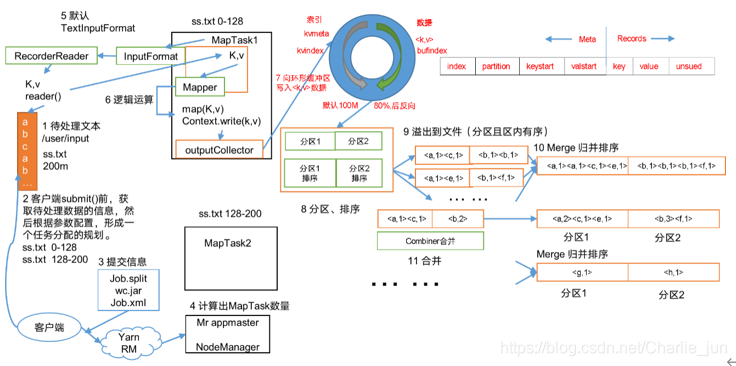
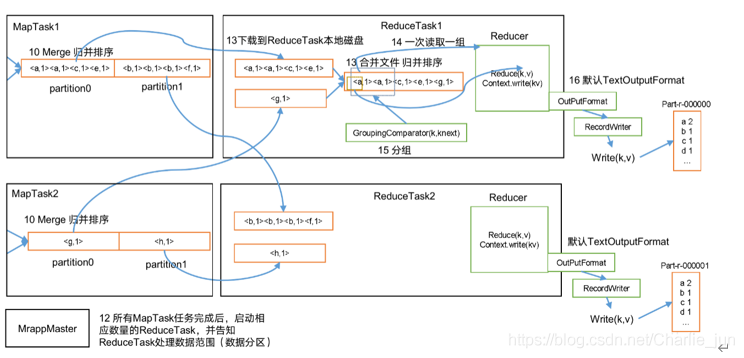
1、Map方法之后Reduce方法之前這段處理程序叫Shuffle
2、Map方法之后,資料首先進入到磁區方法,把資料標記好磁區,然后把資料發送到環形緩沖區;環形緩沖區默認
大小100m,環形緩沖區達到80%時,進行溢寫;溢寫前對資料進行排序,排序按照對key的索引進行字典順序排
序 ,排序的手段快排;溢寫產生大量溢寫檔案,需要對溢寫檔案進行歸并排序;對溢寫的檔案也可以進行
Combiner操作,前提是匯總操作,求平均值不行,最后將檔案按照磁區存盤到磁盤,等待Reduce端拉取,
3、每個Reduce拉取Map端對應磁區的資料,拉取資料后先存盤到記憶體中,記憶體不夠了,再存盤到磁盤,拉取完所
有資料后,采用歸并排序將記憶體和磁盤中的資料都進行排序,在進入Reduce方法前,可以對資料進行分組操作,
11. Mapreduce 的 map 數量 和 reduce 數量是由什么決定的 ,怎么配置
1、 map的數量由輸入切片的數量決定,128M切分一個切片,只要是檔案也分為一個切片,
有多少個切片就有多少個map Task,
2、 reduce數量自己配置,
12. MapReduce優化經驗
1、 設定合理的map和reduce的個數,合理設定blocksize
2、避免出現資料傾斜
3、 combine函式
4、對資料進行壓縮
5、小檔案處理優化:事先合并成大檔案,combineTextInputformat,在hdfs上用mapreduce將小檔案合
并成SequenceFile大檔案(key:檔案名,value:檔案內容)
6、引數優化
13. 分別舉例什么情況要使用 combiner,什么情況不使用?
求平均數的時候就不需要用combiner,因為不會減少reduce執行數量,在其他的時候,可以依據情況,使用
combiner,來減少map的輸出數量,減少拷貝到reduce的檔案,從而減輕reduce的壓力,節省網路開銷,提升
執行效率
14. 簡單描述一下HDFS的系統架構,怎么保證資料安全?
1、存盤在HDFS系統上的檔案,會分割成128M大小的block存盤在不同的節點上,block的副本數默認3份,也可配置
成更多份;
2、第一個副本一般放置在與client(客戶端)所在的同一節點上(若客戶端無datanode,則隨機放),第二個副本
放置到與第一個副本同一機架的不同節點,第三個副本放到不同機架的datanode節點,當取用時遵循就近原則;
3、datanode已block為單位,每3s報告心跳狀態,做10min內不報告心跳狀態則namenode認為block已死掉,
namonode會把其上面的資料備份到其他一個datanode節點上,保證資料的副本數量;
4、datanode會默認每小時把自己節點上的所有塊狀態資訊報告給namenode;
5、采用safemode模式:datanode會周期性的報告block資訊,Namenode會計算block的損壞率,當閥值
<0.999f時系統會進入安全模式,HDFS只讀不寫,HDFS元資料采用secondaryname備份或者HA備份
15. 在通過客戶端向hdfs中寫資料的時候,如果某一臺機器宕機了,會怎么處理
在寫入的時候不會重新重新分配datanode,如果寫入時,一個datanode掛掉,會將已經寫入的資料放置到
queue的頂部,并將掛掉的datanode移出pipline,將資料寫入到剩余的datanode,在寫入結束后,
namenode會收集datanode的資訊,發現此檔案的replication沒有達到配置的要求(default=3),
然后尋找一個datanode保存副本
16. Hadoop優化有哪些方面
0)HDFS小檔案影響
(1)影響NameNode的壽命,因為檔案元資料存盤在NameNode的記憶體中
(2)影響計算引擎的任務數量,比如每個小的檔案都會生成一個Map任務
1)資料輸入小檔案處理:
(1)合并小檔案:對小檔案進行歸檔(Har)、自定義Inputformat將小檔案存盤成SequenceFile檔案,
(2)采用ConbinFileInputFormat來作為輸入,解決輸入端大量小檔案場景,
(3)對于大量小檔案Job,可以開啟JVM重用,
2)Map階段
(1)增大環形緩沖區大小,由100m擴大到200m
(2)增大環形緩沖區溢寫的比例,由80%擴大到90%
(3)減少對溢寫檔案的merge次數,
(4)不影響實際業務的前提下,采用Combiner提前合并,減少 I/O,
3)Reduce階段
(1)合理設定Map和Reduce數:兩個都不能設定太少,也不能設定太多,太少,會導致Task等待,延長處理時間
太多,會導致 Map、Reduce任務間競爭資源,造成處理超時等錯誤,
(2)設定Map、Reduce共存:調整slowstart.completedmaps引數,使Map運行到一定程度后,Reduce也開
始運行,減少Reduce的等待時間,
(3)規避使用Reduce,因為Reduce在用于連接資料集的時候將會產生大量的網路消耗,
(4)增加每個Reduce去Map中拿資料的并行數
(5)集群性能可以的前提下,增大Reduce端存盤資料記憶體的大小,
4)IO傳輸
(1)采用資料壓縮的方式,減少網路IO的的時間,安裝Snappy和LZOP壓縮編碼器,
(2)使用SequenceFile二進制檔案
5)整體
(1)MapTask默認記憶體大小為1G,可以增加MapTask記憶體大小為4-5g
(2)ReduceTask默認記憶體大小為1G,可以增加ReduceTask記憶體大小為4-5g
(3)可以增加MapTask的cpu核數,增加ReduceTask的CPU核數
(4)增加每個Container的CPU核數和記憶體大小
(5)調整每個Map Task和Reduce Task最大重試次數
17. 大量資料求topN(寫出mapreduce的實作思路)
1.維持一個逆序的list(LinkedList)
2.新加入資料,判斷是否達到最大topn,
如果沒有超過topn最大值,直接加入,重新排序;
如果大于topn,比較和最后一個值的大小,如果小于最后一個值,不做任何處理
如果大于最后一個值,替換最后一個值,重新排序
(實作代碼包括回復內容,兩種實作方式,第一種List實作,第二種TreeSet實作)
18. 列出正常作業的hadoop集群中hadoop都分別啟動哪些行程以及他們的作用
1.NameNode它是hadoop中的主服務器,管理檔案系統名稱空間和對集群中存盤的檔案的訪問,保存有metadate
2.SecondaryNameNode它不是namenode的冗余守護行程,而是提供周期檢查點和清理任務,幫助NN合并
editslog,減少NN啟動時間,
3.DataNode它負責管理連接到節點的存盤(一個集群中可以有多個節點),每個存盤資料的節點運行一個
datanode守護行程,
4.ResourceManager(JobTracker)JobTracker負責調度DataNode上的作業,每個DataNode有一個
TaskTracker它們執行實際作業,
5.NodeManager(TaskTracker)執行任務
6.DFSZKFailoverController高可用時它負責監控NN的狀態,并及時的把狀態資訊寫入ZK,它通過一個獨立
執行緒周期性的呼叫NN上的一個特定介面來獲取NN的健康狀態,FC也有選擇誰作為Active NN的權利,因為
最多只有兩個節點,目前選擇策略還比較簡單(先到先得,輪換),
7.JournalNode 高可用情況下存放namenode的editlog檔案.
19. Hadoop總job和Tasks之間的區別是什么?
1、Job是我們對一個完整的mapreduce程式的抽象封裝
2、Task是job運行時,每一個處理階段的具體實體,如map task,reduce task,maptask和reduce
task都會有多個并發運行的實體
20. Hadoop高可用HA模式
HDFS高可用原理:
Hadoop HA(High Available)通過同時配置兩個處于Active/Passive模式的Namenode來解決上述問題,
狀態分別是Active和Standby. Standby Namenode作為熱備份,從而允許在機器發生故障時能夠快速進行故
障轉移,同時在日常維護的時候使用優雅的方式進行Namenode切換,Namenode只能配置一主一備,不能多于兩個
Namenode,
主Namenode處理所有的操作請求(讀寫),而Standby只是作為slave,維護盡可能同步的狀態,使得故障時能夠
快速切換到Standby,為了使Standby Namenode與Active Namenode資料保持同步,兩個Namenode都與一組
Journal Node進行通信,當主Namenode進行任務的namespace操作時,都會確保持久會修改日志到
Journal Node節點中,Standby Namenode持續監控這些edit,當監測到變化時,將這些修改同步到自己的
namespace,
當進行故障轉移時,Standby在成為Active Namenode之前,會確保自己已經讀取了Journal Node中的所有
edit日志,從而保持資料狀態與故障發生前一致,
為了確保故障轉移能夠快速完成,Standby Namenode需要維護最新的Block位置資訊,即每個Block副本存放
在集群中的哪些節點上,為了達到這一點,Datanode同時配置主備兩個Namenode,并同時發送Block報告和心跳
到兩臺Namenode,
確保任何時刻只有一個Namenode處于Active狀態非常重要,否則可能出現資料丟失或者資料損壞,當兩臺
Namenode都認為自己的Active Namenode時,會同時嘗試寫入資料(不會再去檢測和同步資料),為了防止這種
腦裂現象,Journal Nodes只允許一個Namenode寫入資料,內部通過維護epoch數來控制,從而安全地進行故障
轉移,
21. 簡要描述安裝配置一個hadoop集群的步驟
1、使用root賬戶登錄,
2、 修改IP,
3、修改Host主機名,
4、 配置SSH免密碼登錄,
5、關閉防火墻,
6、 安裝JDK,
7、上傳解壓Hadoop安裝包,
8、配置Hadoop的核心組態檔hadoop-evn.sh,core-site.xml,mapred-site.xml,hdfs-site.xml,yarn-site.xml
9、配置hadoop環境變數
10、格式化hdfs # bin/hadoop namenode -format
11、啟動節點start-all.sh
22. fsimage和edit的區別
fsimage:filesystem image 的簡寫,檔案鏡像,
客戶端修改檔案時候,先更新記憶體中的metadata資訊,只有當對檔案操作成功的時候,才會寫到editlog,
fsimage是檔案meta資訊的持久化的檢查點,secondary namenode會定期的將fsimage和editlog合并dump成
新的fsimage
23. yarn的三大調度策略
1)Hadoop調度器重要分為三類:
FIFO 、Capacity Scheduler(容量調度器)和Fair Sceduler(公平調度器),
Hadoop2.7.2默認的資源調度器是 容量調度器
2)區別:
FIFO調度器:先進先出,同一時間佇列中只有一個任務在執行,
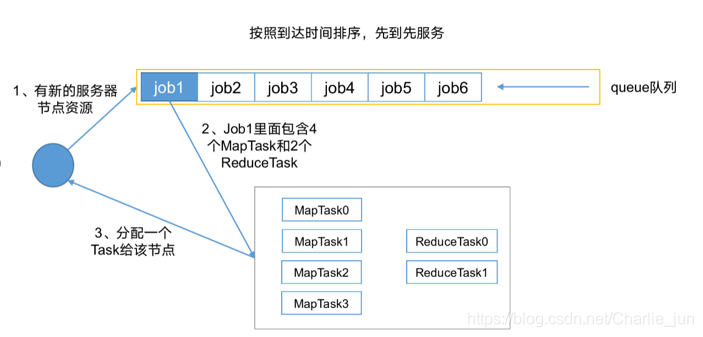
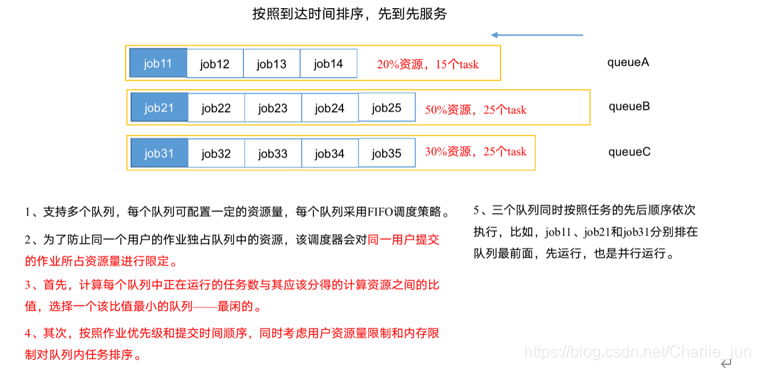
容量調度器:多佇列;每個佇列內部先進先出,同一時間佇列中只有一個任務在執行,佇列并行度為佇列的個數
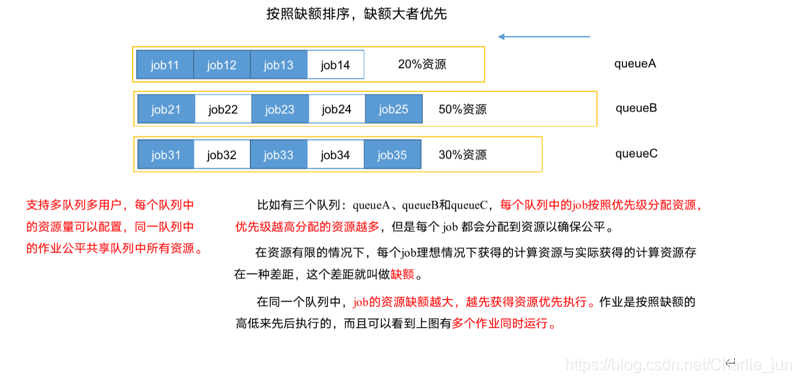
公平調度器:多佇列;每個佇列內部按照缺額大小分配資源啟動任務,同一時間佇列中有多個任務執行,佇列的并行度大于等于佇列的個數,
一定要強調生產環境中不是使用的FifoScheduler,面試的時侯會發現候選人大概了解這幾種調度器的區別,但是問在生產環境用哪種,卻說使用的FifoScheduler(企業生產環境一定不會用這個調度的)
大資料面試題之葵花寶典------flume
大資料面試題之葵花寶典------Flink初級
大資料面試題之葵花寶典------Flink中級
大資料面試題之葵花寶典------Flink高級

轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/1441.html
標籤:其他