目錄導讀
- 資料庫與資料倉庫與資料湖泊的介紹
- 圖資料庫與圖資料倉庫的區別
- 圖庫發展與現狀
- HOLAP(ROLAP+MOLAP)圖數倉的優點
- HOLAP數倉資料攝入方式
- HOLAP數倉資料存盤方式
- 總結
最近,第一款面向大規模實時資料分析的HOLAP知識圖譜資料倉庫AbutionGraph發布了,同時也可以當作一款面向多種資料格式共同存盤的資料湖系統(即湖倉一體架構),支持如圖譜、時序資料、空間資料、文本、機器學習特征等,它們都是從圖數倉中拆分出來基于HDFS的資料存盤與管理子系統,在后續文章中會做介紹,以下篇幅內容均出自AbutionGraph的設計架構拆分,
既然是圖譜資料倉庫,那咱們先來了解一下:
資料庫(Data Base)與資料倉庫(Data Warehouse)與資料湖泊(Data Lake)的介紹
<資料庫>一般指聯機操作資料系統(Online Transaction Processing)OLTP定義:面向事務操作、資料增刪改查,存盤既定的歷史資料,
<資料倉庫>一般指聯機分析處理系統(Online Analytical Processing)OLAP定義:面向分析、管理、決策、一般只進行讀寫操作的有組織的資料集合,可按時間區分資料,
<資料湖泊>一般指可以存盤海量任意型別且有能管理這些資料能力的資料系統,我們熟知的HDFS就是一個很好的資料湖底座,
如定義所述,三者最主要的區別是用途不同,即面向的業務場景不同,一些經典熱門的資料庫的特性比較如下:
| 特征\產品 | 資料庫(OLTP) | 資料倉庫(OLAP) |
| 離線 | MySQL、Oracle | Apache Hive/Presto |
| 實時 | Hbase、Tikv | Apache Druid/Kylin |
| 用戶 | 初級的 | 決策者/高級的 |
| 功能 | 基本查詢 | 分析決策 |
| 架構 | 面向應用 | 面向主題 |
| 資料 | 當前的,二維的 | 歷史的,多維的 |
| 存取 | 百千條 | 上百萬條 |
| 場景 | 簡單事務 | 復雜查詢 |
| 用戶數 | 上千個 | 上百萬個 |
| 資料量 | MB ~ GB | GB、TD、PB、EB |
通過概念和表格對比之后,相信我們已經了解了資料庫和資料倉庫的區別,接下來將會很好區分圖資料庫和圖資料倉庫,
圖資料庫(Graph DataBase)與圖資料倉庫(Graph Data Warehouse)的區別
<圖譜-資料庫>是資料庫的延伸,也指OLTP操作資料系統:在面向事務操作、資料增刪改查,存盤既定的歷史資料的同時,可高效地管理大量關聯資料,挖掘資料之間的深層關系,相當于給資料庫中的每一條資料加上了物體和關系的資料結構,構成一個存盤所有歷史資料的“資料圖譜”,
<圖譜-資料倉庫>是資料倉庫+圖資料庫的延伸,也指OLAP分析處理系統:在面向分析、管理、決策的有組織的資料集合,可按時間區分資料,實時依據歷史資料得出總結的同時,可高效地管理超大規模關聯資料,挖掘資料之間的深層關系,相當于給知識圖譜加了多維立方體“動效”,每一個物體/關系上的 每一個時間維度上的 每一個屬性 都是“實時動態”在線更新的,決策者可以快速的得知事件的原因和動向,進行下一步動作,
我們從下表中看看都有那些不同:
| 特征\產品 | 圖資料庫(OLTP) | 圖資料倉庫(OLAP) |
| 離線 | Neo4J、JanusGraph | 無 |
| 實時 | TigerGraph | AbutionGraph(唯一) |
| 用戶 | 初級的 | 決策者/高級的 |
| 功能 | 基本查詢 | 分析決策 |
| 架構 | 面向應用 | 面向主題 |
| 資料 | 當前的,二維的 | 歷史的,多維的 |
| 存取 | 百千條 | 上百萬條 |
| 場景 | 簡單事務 | 復雜查詢 |
| 用戶數 | 上千個 | 上百萬個 |
| 資料量 | MB ~ GB | GB、TD、PB、EB |
| 聚合回應 | 秒~次天 | 亞秒~秒 |
圖庫發展與現狀
圖資料庫是目前市場的應用主流,因為知識圖譜技識訓處于新興領域,圖庫產品屈指可數,都屬于OLTP系統,部分功能也相對落后,如:Neo4J與JanusGraph,這兩款離線的圖庫占據了國內90%以上的市場,實時入庫性能較好的TigerGraph,因其高昂的售價,多為大企使用,而在OLAP圖數倉領域目前只有圖特摩斯科技的AbutionGraph這一款產品,是一款HybridOLAP圖庫,在性能和各方面功能上,都做了很多顛覆性的圖庫技術,
鑒于知識圖譜優秀的知識檢索和推理能力,可廣泛應用于智能問答、關系搜索、個性化推薦、欺詐檢測、金融風控、軍工情報、供應鏈管理、loT監控、企業畫像、線上零售、醫療保健等場景,因圖庫產品的缺少,圖技術認知不夠,性能等各方面技術落后于工業場景的需求,知識圖譜資料庫的落地案例還很少,為了大力發展知識圖譜技術,國家科技部也把“時序動態知識圖譜技術”納入到了2030年的重大人工智能技術發展目標中,“時序動態”其實是我們接下來章節中介紹的MOLAP架構,也是AbutionGraph中使用的架構之一,相信在未來實時圖資料倉庫會和實時資料倉庫一樣成為企業的硬核底座,
HybridOLAP(ROLAP+MOLAP)圖數倉的優點
使用AbutionGraph作為OLAP服務的常見的應用場景包括:BI報表, 監控系統、用戶行為分析、在線分析,特征分析, Ad-hoc, DataFlow, ETL等場景,絕大多數OLAP場景需要查詢最近一段時間的資料(過去一分鐘,過去三天,過去一周,過去一個月等) ,它使分析人員能夠迅速、一致、互動地從各個方面觀察資訊,以達到深入理解資料的目的,OLAP按存盤的資料存盤格式分為ROLAP、MOLAP和HOLAP,前兩者都有明顯的優缺點,面向的應用場景也有所不同,HOLAP則是ROLAP和MOLAP的混合形式,
| 種類\介紹 | 介紹 | 產品 | 優點 | 缺點 |
| MOLAP (Multi-dimensional)
| 以多維陣列(Multi-dim Array)為存盤模型的OLAP,
特點:資料預計算(pre-computaion),然后把預計算結果(cube)存在多維陣列里, | Apache Druid
Apache Kylin
| cube包含所有維度的聚合(aggregate)結果,所以查詢速度非常快,
相對關系型資料庫,計算結果資料的磁盤空間占用更小,擴展性強,適用于維度數量多的模型 | 對于維度多的模型預計算慢,空間占用大,update cube的時間跟計算維度(group)相關,隨著維度增加計算時間大幅增加,此外預計算還會造成資料庫占用急劇膨脹,需要提前設計維度模型,查詢分析的內容僅限于這些指定維度,增加維度需要重新計算, |
| ROLAP (Relational)
| 基于關系模型存放資料,一般要求事實表(fact table)和維度表(dimensition table)按一定關系設計,它不需要預計算,使用標準SQL查詢不同維度資料, | ApacheHive
ClickHouse
SparkSQL
Impala
Greeplum
Presto |
更適合處理non-aggregate資料,例如文本描述
基于row資料更容易做權限管理 | 因為是即時計算,查詢回應時間一般比預計算的MOLAP長 |
| HybridOLAP
| MOLAP和ROLAP型別的混合運用
細節的資料以ROLAP的形式存放,更加方便靈活,而高度聚合的資料以MOLAP的形式展現 | Thutmose AbutionGraph | 更適合于高效的分析處理,公司使用HOLAP的目的是根據不同場景來利用不同OLAP的特性, |
|
AbutionGraph的存盤形式即是采用了HOLAP這種混合模式,因為在圖分析場景中,我們都會去計算節點的出度入度等指標,一個節點關聯的鄰居節點數量是非常多的,采用OLTP或者ROLAP的存盤形式每次都計算一遍,對于一個百億資料量的圖譜,查詢回應時間和資源消耗都是無法估量的,很容易資源不足而導致OOM例外,這種指標計算的場景則非常適合MOLAP,即pre-aggregate事件,只存放聚集值(count,sum等)大于某個最小支持度閾值的立方體單元,而對于MOLAP得出的報表結果,我們通常需要深入查看其中的每一條歷史資料,即non-aggregate事件,這種需要得知歷史事件的查詢則是ROLAP的應用場景,在大規模的事件圖譜中,任其一都無法及時滿足復雜的業務需求,時序動態圖庫AbutionGraph結合了MOLAP與ROLAP兩者的優點,使原本我們熟知的關系型“資料圖譜”(OLTP)變成了多維度資料存盤的“cube graph”(MOLAP)和可實時聚合的“動態圖譜”(MOLAP),
HOLAP數倉資料攝入方式
AbutionGraph與其它數倉類似,可以覆寫如下兩種場景:
- 實時:資料流可以通過kafka/MQ或者flink實時處理之后,通過JDBC方式批量匯入到AButionGraph中
- 離線:資料落地HDFS ODS層,離線通過Spark或MR的batch形式批量匯入到AButionGraph中
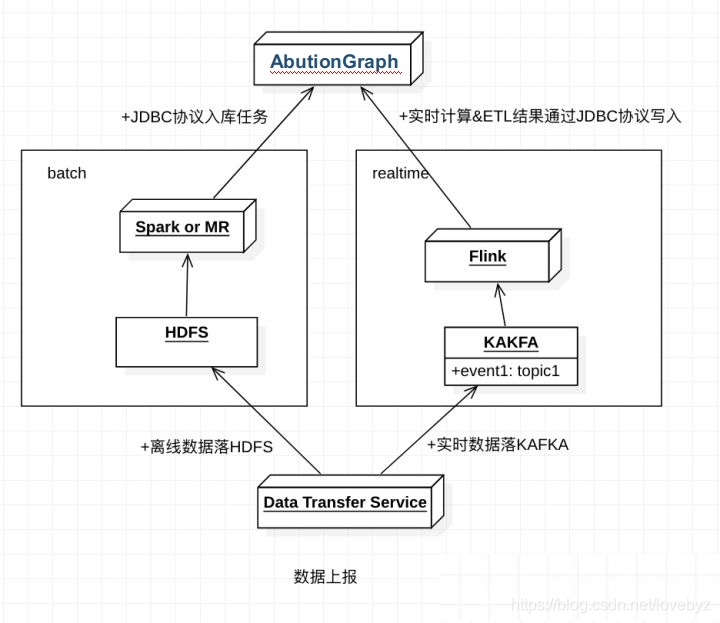
HOLAP數倉資料存盤方式
HOLAP的資料模型是一個多維(group)立方體(cube)的存盤模型,圖譜中每個物體與每條關系都是一個cube,整個圖譜就好比一個全視角的“宇宙星際”,

立方體(Cube):圖譜中物體與關系下的360度多維度標簽,是一個多維陣列包含著groups,
維(Group):人們觀察事物的視角,如時間、地理位置、年齡和性別等,是單一角度概念,
維的層次(Lever):表示維度概念基礎上進一步的細分,如時間可以細分為年、季度、月三個層次,
維的成員(Member):表示維不可再細分的原子取值,即維中的屬性集,如時間維2020年10月的成員可以有出度、入度、對手集等(MOLAP),再如張某的基礎屬性維成員可以有age、name、occupation等(ROLAP),
度量(Measure):表示在這個維成員上的取值,Count、Max、Sum、Cardinality、Last、TimeSeries、TopN....,
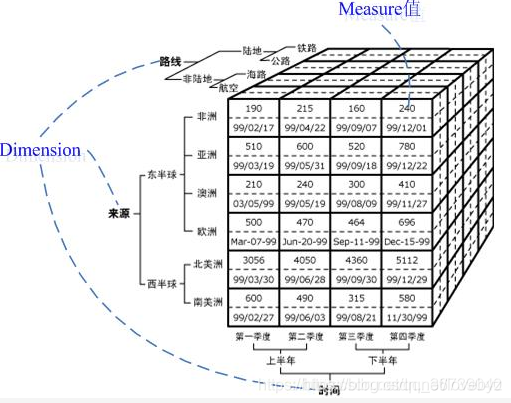
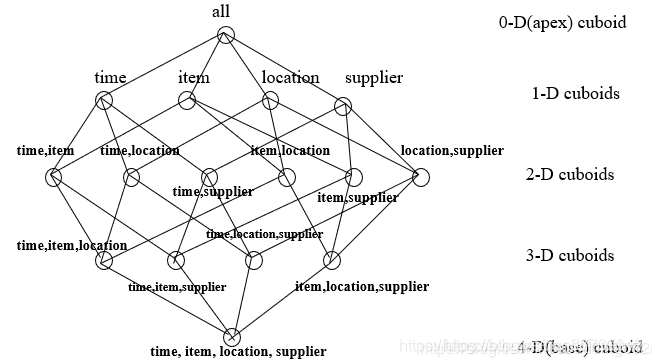
Ps:圖片來源于網路
總結
傳統的 OLAP 需要做各種 pipeline、ETL 匯入資料,這樣的架構會存盤多份資料,冗余并且一致性不好保證,也引入過多的技術堆疊和復雜度,也不能滿足實時分析,即使 mini-batch 的處理仍然需要最快數分鐘,業界的趨勢在于賦予 OLAP 高吞吐實時寫,提供實時查詢能力,例如上游資料源,經過流計算系統,老的架構基于 lambda,寫歷史資料到存盤再清洗,實時資料入一些 NoSQL,使用方需要做各種資料源 merge 操作,流行的方式是流計算系統直接寫 OLAP,這樣避免了資料孤島,保證了鏈路簡單,圖特摩斯科技的AbutionGDB正如阿里云團隊提出的 HSAP (Hybrid Serving/Analytical Processing)這種理念,
OLAP 領域經歷了從 RDBMS 建立起來的 SQL + OLAP,到 ETL + 專有 OLAP 的數倉,ROLAP,MOLAP,再到我們當前領先探索的 Know-How + HOLAP 的知識圖譜數倉階段,將Know-How與OLAP兩個前沿領域進行碰撞、融合,讓OLAP/GraphDB突破傳統,以更數智化的架構應對刁鉆復雜的業務場景,
目前OLAP系統仍在不斷演進,也正在被更多企業的高級場景所應用,從傳統數倉到實時數倉架構的演進、資料中臺的搭建..... 更多的大資料廠商、云廠商、人工智能廠商、資料治理廠商... 也在嘗試進入這個領域,為知識圖譜和資料倉庫的解決方案帶來更多的靈感與實際的好處,
出品 | 北京圖特摩斯科技 (www.thutmose.cn)
合作 | 聯系方式
試用 | 您有任何業務場景想要用到知識圖譜都可以與我們聯系 免費給您提供先進的且和以往不同的解決方案
技術交流群:

轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/147061.html
標籤:其他