??大家好,我是不溫卜火,是一名計算機學院大資料專業大三的學生,昵稱來源于成語—
不溫不火,本意是希望自己性情溫和,作為一名互聯網行業的小白,博主寫博客一方面是為了記錄自己的學習程序,另一方面是總結自己所犯的錯誤希望能夠幫助到很多和自己一樣處于起步階段的萌新,但由于水平有限,博客中難免會有一些錯誤出現,有紕漏之處懇請各位大佬不吝賜教!暫時只有csdn這一個平臺,博客主頁:https://buwenbuhuo.blog.csdn.net/
本片博文為大家帶來的想要快速爬取整站圖片?速進(附完整代碼),
完整代碼在Github,如有需要可自行下載,
GIthub地址:https://github.com/459804692/scrapy/tree/master/scrapy_demo
目錄
- 一. 爬取前的準備
- 二. 查看網頁
- 三. 分析與實作
- 1. 先確定我們所要爬取內容的具體位置
- 2. 存盤的具體實作 (`在pipelines中處理`)
- 3. 更新完善原始碼
- 四. 代碼

??快速爬取整個網站的圖片當然是可行的!!!但是 我們還是先從一個切入點切入,此處的切入點,博主選擇的是寶馬五系車型為切入點,同理,爬取妹子圖也是如此,
一. 爬取前的準備
汽車直接官網:https://www.autohome.com.cn/
寶馬五系網頁地址:https://www.autohome.com.cn/65/
圖片地址:https://car.autohome.com.cn/pic/series/65.html
二. 查看網頁
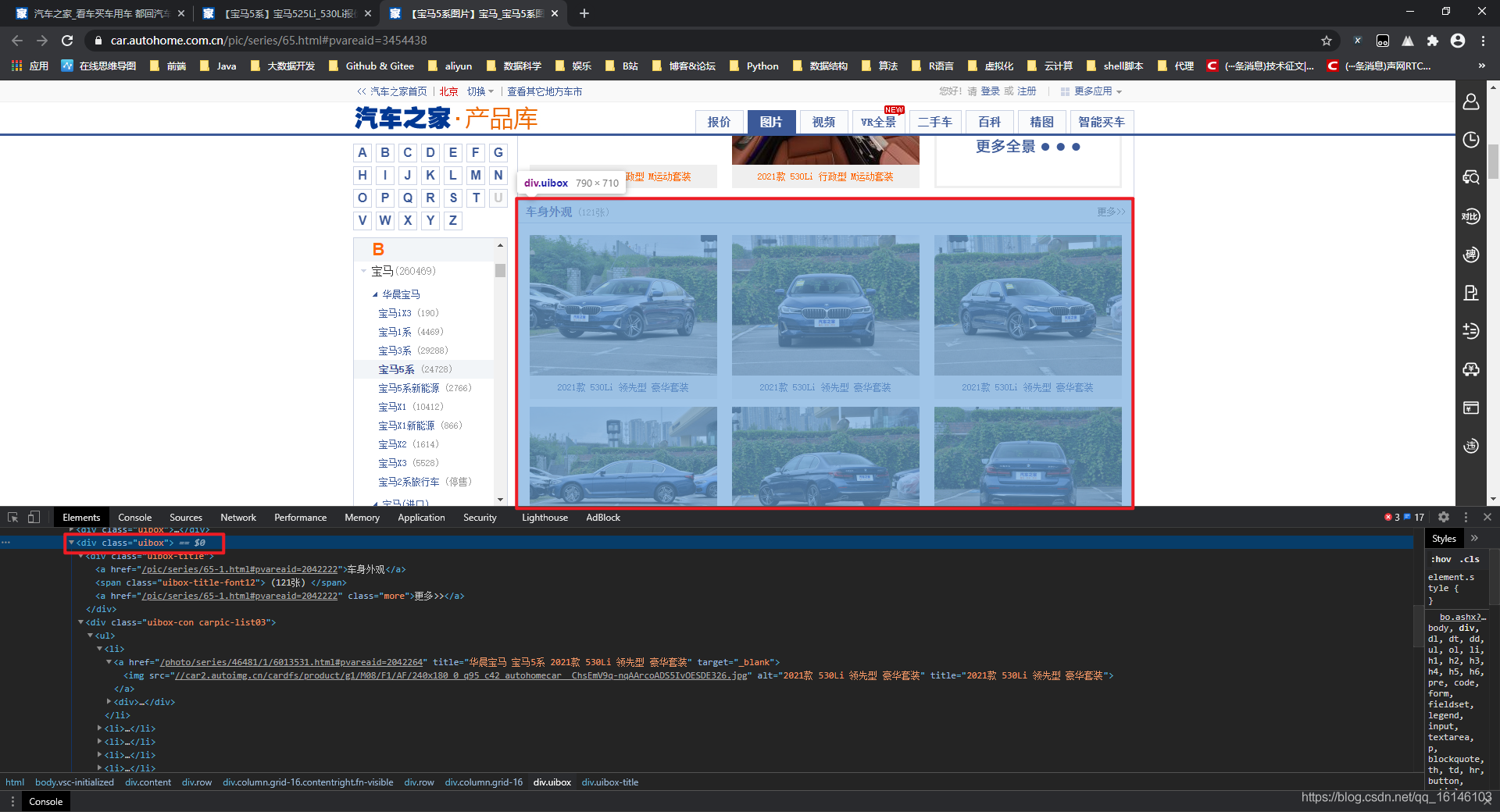
根據上圖,可以發現我們所要爬取的部分都在<div class="uibox">xxx</div>這個父標簽內,
好了,既然已經知道我們的切入點在哪了,那么我們下面就要對此部分進行決議了
上一張圖片可能不是太直觀,那么我們可以通過查看原始碼,來進行決議:
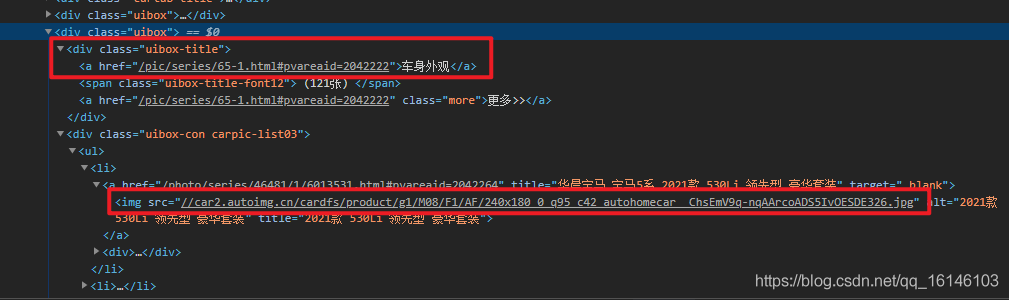
根據上圖我們可以知道第一個標記處為我們所要爬取部分的title,
而我們所要爬取的圖片則為標記的第二部分<img src>xxxx</img>
三. 分析與實作
1. 先確定我們所要爬取內容的具體位置
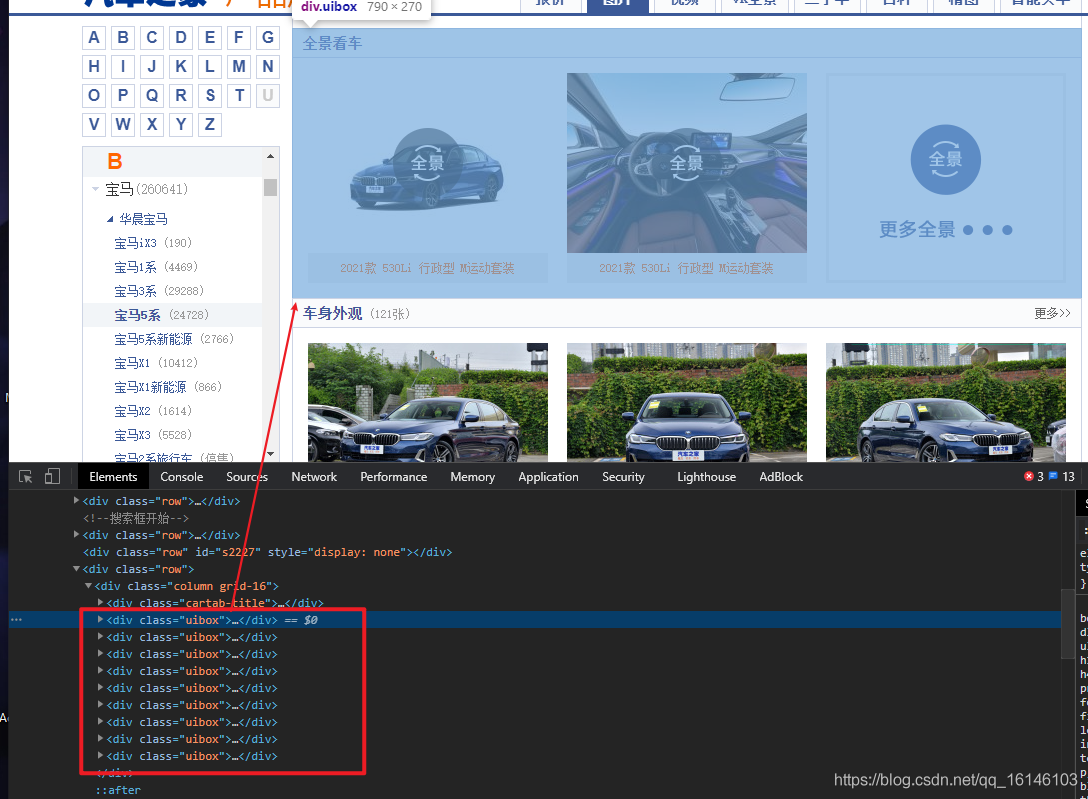
好了,根據上圖我們可以看到我們準備爬取的內容都在<div class="uibox"></div>中,這時,我們應該想到的是先把這部分全部獲取下來,然后通過回圈遍歷,把我們所需要的部分分別提取出來,
首先我們先來實作獲取所有“uibox”中的內容,通過xpath進行決議,決議式如下:
uiboxs = response.xpath("//div[@class='uibox']")[1:] # 使用切片操作
下圖為所獲取到的所有結果(通過scrapy shell 決議所得到的結果)

至于為什么會用到接片操作,我們可以看下圖
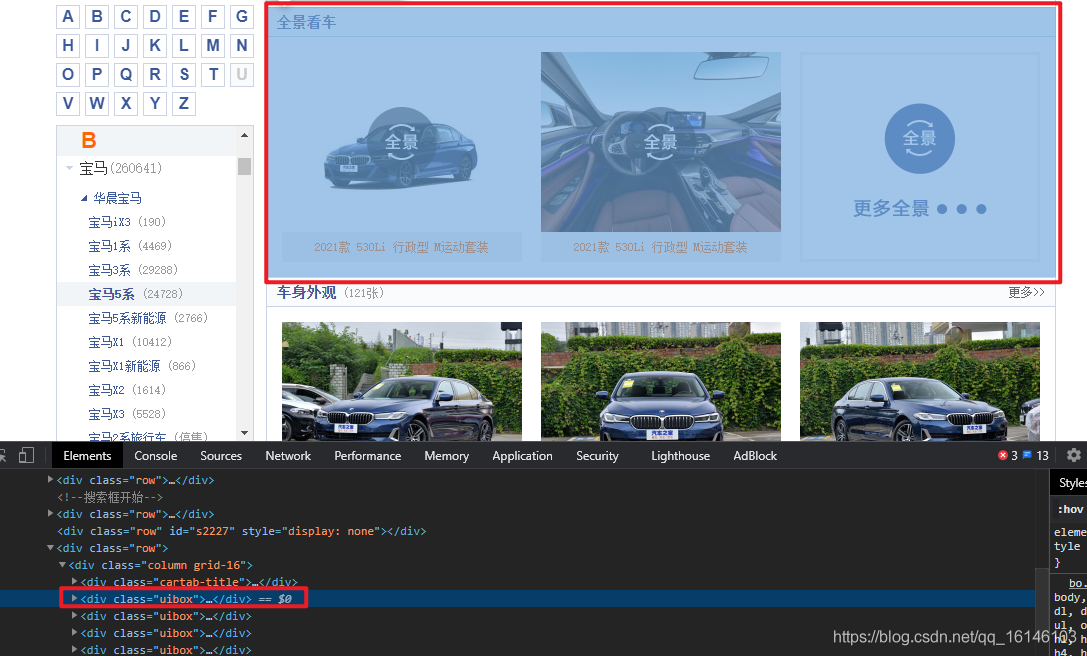 由上圖我們可以看到爬取圖片的時候全景看車這部分是不需要爬取的,由于其不是我們所需要的,那么我們就需要把它排除掉,而排除操作我選擇的是切片操作,
由上圖我們可以看到爬取圖片的時候全景看車這部分是不需要爬取的,由于其不是我們所需要的,那么我們就需要把它排除掉,而排除操作我選擇的是切片操作,
切片操作完成后,我們通過回圈遍歷可以分別得到我們所需要的圖片名稱及圖片鏈接,
怎樣得到的?我們先看下HTML原始碼結構:


根據上面兩張圖片,我們可以分別進行xpath決議,決議式如下:
for uibox in uiboxs:
category = uibox.xpath(".//div[@class = 'uibox-title']/a/text()").get()
print(category)
urls = uibox.xpath(".//ul/li/a/img/@src").getall()
print(urls)
決議完成后,我們通過輸出列印看下效果:

根據上圖我們可以看到圖片的網址是不完全的,這時候我們可以通過添加https:使其形式成為url = "https:"+url這種形式,最終可以的到下圖的效果:
for url in urls:
url = "https:"+url
print(url)

上述代碼用的是最原始的遍歷方法讓每一個圖片地址輸出成我們想要的,那么還有其他方法沒有?
答案是肯定! 下面博主給的代碼即為優化方法:
優化1:自動拼接成完整的URL
for url in urls:
url = response.urljoin(url)
print(url)
優化2: 使用map()
在使用map()優化前,我們需要先設定好item.py
class BmwItem(scrapy.Item):
category = scrapy.Field()
urls= scrapy.Field()
urls = list(map(lambda url:response.urljoin(url),urls))
item = BmwItem(category = category , urls = urls)
yield item
上述兩種優化方法得到的結果和第一個是一樣的,效果圖如下:

2. 存盤的具體實作 (在pipelines中處理)
在使用pipelines的時候,我們需要先從設定里打開選項,把默認的注釋去掉

去掉注釋以后,我們就把圖片保存到本地這一想法從理論成為現實:
怎樣實作?
在此博主總共分成兩步進行實作,首先是先判斷是否有目錄,如果有的話就直接進行下一步,如果沒有的話,則會進行自動創建,原始碼部分如下:
def __init__(self):
# 獲取并創建當前目錄,沒有自行創建
self.path = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'images')
if not os.path.exists(self.path):
os.mkdir(self.path)
else:
print('images檔案夾存在')
檔案夾創建完成后,就需要對圖片進行保存了,原始碼如下:
def process_item(self, item, spider):
category = item['category']
urls = item['urls']
category_path = os.path.join(self.path,category)
if not os.path.exists(category_path):
os.mkdir(category_path)
for url in urls:
image_name = url.split('_')[-1]
request.urlretrieve(url,os.path.join(category_path,image_name))
return item
對上述原始碼,博主只對image_name = url.split('_')[-1]這一句做詳細解釋,至于為什么要這樣操作,看下圖:

根據上圖,我們不難看出所有圖片地址的_之前基本上都是一樣的,那么我們就以_為分割線 ,通過切片的方式選取最后一部分當作我們所要保存的圖片的名稱!
下面查看一下運行的結果:
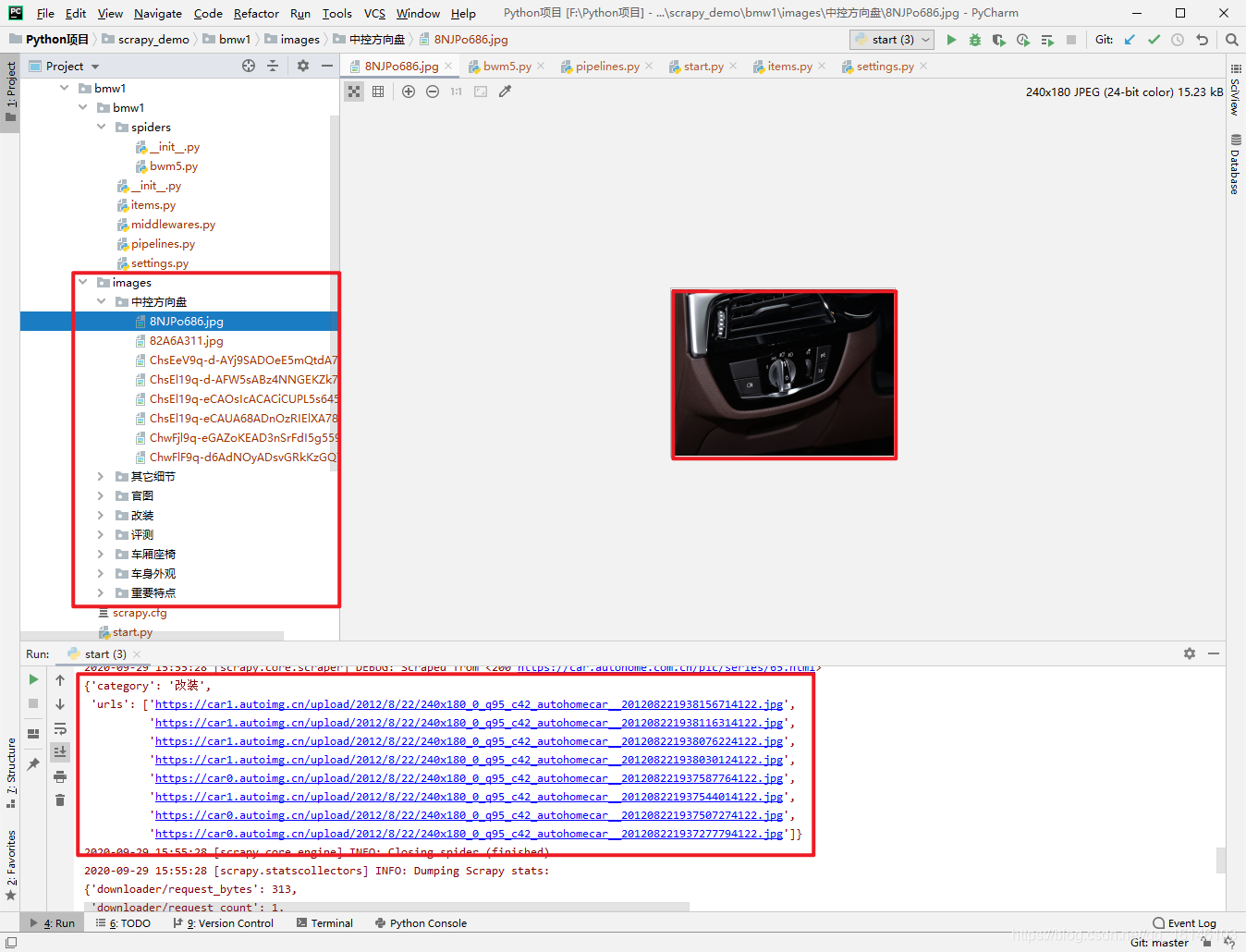
通過圖片我們可以看到我們已經成功的把理想編程了現實,
3. 更新完善原始碼
雖然通過以上的步驟我們已經完成了圖片的爬取,但是我們要知道我們用的是不同的回圈遍歷的方法一張一張的下載,初次之外,上述的方法也沒有用到異步下載,效率較為低下,
在這個時候我們就可以使用scrapy框架自帶的item pipelines了,
為什么要選擇使用scrapy內置的下載檔案的方法:
- 避免重新下載最近已經下載過的資料,
- 可以方便的指定檔案存盤的路徑,
- 可以將下載的圖片轉換成通用的格式,比如png或jpg,
- 可以方便的生成縮略圖,
- 可以方便的檢測圖片的寬和高,確保他們滿足最小限制,
- 異步下載,效率非常高
下載檔案的Files Pipeline與下載圖片的Images Pipeline:
當使用Files Pipeline下載檔案的時候,按照以下步驟來完成:
- 定義好一個Item,然后在這個item中定義兩個屬性,分別為file_urls以及files = file_urls是用來存盤需要下載的檔案的url鏈接,需要給一個串列,
- 當檔案下載完成后,會把檔案下載的相關資訊存盤到item的fileds屬性中,比如下載路徑、下載的url和檔案的校驗碼等,
- 在組態檔settings.py中配置FILES_STORE,這個配置是用來設定檔案下載下來的路徑,
- 啟動pipeline:在ITEM_PIPELINES中設定scrapy.pipelines.files.FilesPipelines:1,
當使用Images Pipeline下載檔案的時候,按照以下步驟來完成:
- 定義好一個Item,然后在這個item中定義兩個屬性,分別為image_urls以及images = image_urls是用來存盤需要下載的圖片的url鏈接,需要給一個串列,
- 當檔案下載完成后,會把檔案下載的相關資訊存盤到item的images屬性中,比如下載路徑、下載的url和檔案的校驗碼等,
- 在組態檔settings.py中配置IMAGES_STORE,這個配置是用來設定檔案下載下來的路徑,
- 啟動pipeline:在ITEM_PIPELINES中設定scrapy.pipelines.images.ImagesPipelines:1,
- 1. 修改完善items.py
class BmwItem(scrapy.Item):
category = scrapy.Field()
image_urls= scrapy.Field()
images = scrapy.Field()
- 2. 修改主程式
# 修改此部分
item = BmwItem(category = category , image_urls = urls)
- 3. 呼叫scrapy自帶的image Pipelines及images_store
ITEM_PIPELINES = {
# 'bmw1.pipelines.Bmw1Pipeline': 300,
# 系統自帶的Pipeline 可以實作異步
'scrapy.pipelines.images.ImagesPipeline': 1
}
# 圖片下載的路徑,供image pipelines使用
IMAGES_STORE = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'images')
好了,修改完成,下面我們來看下效果
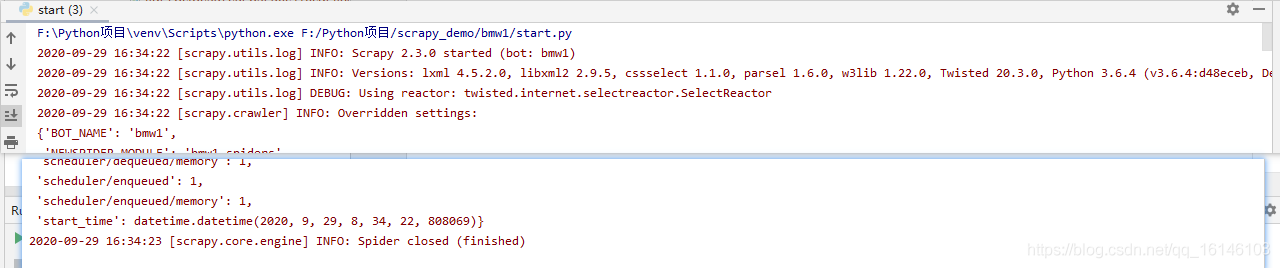
我們可以看到現在下載速度很快,只用了兩秒就完成了整個寶馬五系車型圖片的下載,但是這樣還是有弊端的,因為這樣我們下載所有圖片都在一個默認的full檔案夾下,而沒有任何分類,
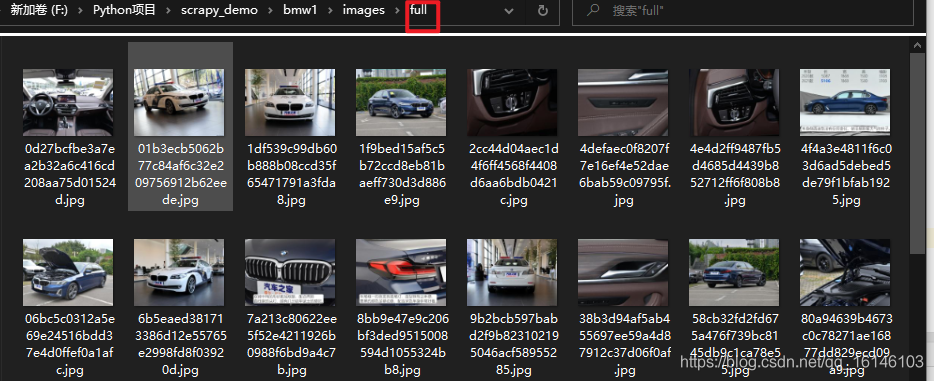
這時候可能會有讀者問:這能按分類進行排序么!答案是能的,看博主下面操作:
為了實作上述讀者所說的需求,其實很簡單,只需要我們再次在pipelines.py中重寫一個類即可
- 4. 重寫類
# 重寫一個新類,使其能夠分類下載
class BMWImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 這個方法是在發送下載請求之前呼叫
# 其實這個方法本身就是去發送下載請求的
request_objs = super(BMWImagesPipeline, self).get_media_requests(item,info)
for request_obj in request_objs:
request_obj.item = item
return request_objs
def file_path(self, request, response=None, info=None):
# 這個方法是在圖片將要被存盤的時候呼叫,來獲取這個圖片存盤的路徑
path = super(BMWImagesPipeline, self).file_path(request,response,info)
category = request.item.get('category')
images_store = settings.IMAGES_STORE
category_path = os.path.join(images_store,category)
if not os.path.exists(category_path):
os.mkdir(category_path)
images_name = path.replace("full/","")
images_path = os.path.join(category_path,images_name)
return images_path
- 6.修改item_pipelines
ITEM_PIPELINES = {
# 'bmw1.pipelines.Bmw1Pipeline': 300,
# 系統自帶的Pipeline 可以實作異步
# 'scrapy.pipelines.images.ImagesPipeline': 1
# 使用自己創建的類物件
'bmw1.pipelines.BMWImagesPipeline': 1
}
- 7. 運行查看結果

- 8. 大圖img保存
你以為到這里就大功告成了嘛!如果真的這樣認為那你就大錯特錯了,因為現在保存的還只是小圖,我們需要保存的是大圖,下面我們先來看看大圖與小圖的區別:
大圖網址:https://car3.autoimg.cn/cardfs/product/g26/M08/5A/55/autohomecar__ChcCP12J_XGAXP0pAAtylyqMfeQ144.jpg
小圖網址:https://car3.autoimg.cn/cardfs/product/g26/M08/5A/55/240x180_0_q95_c42_autohomecar__ChcCP12J_XGAXP0pAAtylyqMfeQ144.jpg

根據上圖,我們可以發現,大圖只是比小圖少了240x180_0_q95_c42_這一部分,既然得到了這樣一則比較有用的資訊,那么我們就可以通過替換發把原來的小圖網址轉換成大圖網址,說干就干,上才藝:
srcs = list(map(lambda x:response.urljoin(x.replace("240x180_0_q95_c42_","")),srcs))
此部分到這里大體就完成了,剩下一點博主就直接把此部分的代碼放上:
rules = (
Rule(LinkExtractor(allow=r"https://car.autohome.com.cn/pic/series/65.+"),callback="parse_page",follow=True),
)
def parse_page(self, response):
category = response.xpath("//div[@class='uibox']/div/text()").get()
srcs = response.xpath('//div[contains(@class,"uibox-con")]/ul/li//img/@src').getall()
srcs = list(map(lambda x:response.urljoin(x.replace("240x180_0_q95_c42_","")),srcs))
# 得到整個狀態串列
# urls = []
# for src in srcs:
# url = response.urljoin(src)
# urls.append(url)
# srcs = list(map(lambda x:response.urljoin(x),srcs))
yield BmwItem(category=category,image_urls = srcs)
- 9. 最終運行結果
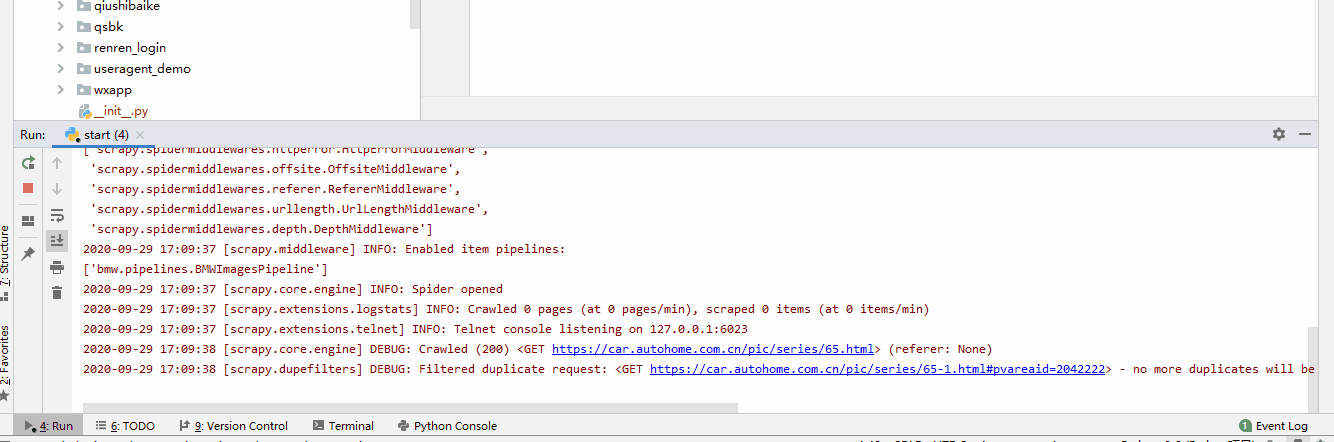
四. 代碼
- 1. bmw5
class Bmw5Spider(CrawlSpider):
name = 'bmw5'
allowed_domains = ['car.autohome.com.cn']
start_urls = ['https://car.autohome.com.cn/pic/series/65.html']
rules = (
Rule(LinkExtractor(allow=r"https://car.autohome.com.cn/pic/series/65.+"),callback="parse_page",follow=True),
)
def parse_page(self, response):
category = response.xpath("//div[@class='uibox']/div/text()").get()
srcs = response.xpath('//div[contains(@class,"uibox-con")]/ul/li//img/@src').getall()
srcs = list(map(lambda x:response.urljoin(x.replace("240x180_0_q95_c42_","")),srcs))
# 得到整個狀態串列
# urls = []
# for src in srcs:
# url = response.urljoin(src)
# urls.append(url)
# srcs = list(map(lambda x:response.urljoin(x),srcs))
yield BmwItem(category=category,image_urls = srcs)
# 爬取縮略圖用此部分
def parse(self, response):
# SelectorList -> list (可進行遍歷)
uiboxs = response.xpath("//div[@class='uibox']")[1:] # 使用切片操作
for uibox in uiboxs:
category = uibox.xpath(".//div[@class = 'uibox-title']/a/text()").get()
urls = uibox.xpath(".//ul/li/a/img/@src").getall()
# for url in urls:
# url = "https:"+url
# print(url)
# 優化1:自動拼接成完整的URL
# for url in urls:
# url = response.urljoin(url)
# print(url)
# 優化2: 使用map()
urls = list(map(lambda url:response.urljoin(url),urls))
item = BmwItem(category = category , image_urls = urls)
yield item
- 2. items
class BmwItem(scrapy.Item):
category = scrapy.Field()
image_urls= scrapy.Field()
images = scrapy.Field()
- 3. pipelines
class BmwPipeline:
def __init__(self):
# 獲取并創建當前目錄,沒有自行創建
self.path = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'images')
if not os.path.exists(self.path):
os.mkdir(self.path)
def process_item(self, item, spider):
category = item['category']
urls = item['urls']
category_path = os.path.join(self.path,category)
if not os.path.exists(category_path):
os.mkdir(category_path)
for url in urls:
image_name = url.split('_')[-1]
request.urlretrieve(url,os.path.join(category_path,image_name))
return item
# 重寫一個新類,使其能夠分類下載
class BMWImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 這個方法是在發送下載請求之前呼叫
# 其實這個方法本身就是去發送下載請求的
request_objs = super(BMWImagesPipeline, self).get_media_requests(item,info)
for request_obj in request_objs:
request_obj.item = item
return request_objs
def file_path(self, request, response=None, info=None):
# 這個方法是在圖片將要被存盤的時候呼叫,來獲取這個圖片存盤的路徑
path = super(BMWImagesPipeline, self).file_path(request,response,info)
category = request.item.get('category')
images_store = settings.IMAGES_STORE
category_path = os.path.join(images_store,category)
if not os.path.exists(category_path):
os.mkdir(category_path)
images_name = path.replace("full/","")
images_path = os.path.join(category_path,images_name)
return images_path
- 4. settings
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 1
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'
}
ITEM_PIPELINES = {
# 雖然能夠下載,但是不能實作異步
# 'bmw.pipelines.BmwPipeline': 300,
# 系統自帶的Pipeline 可以實作異步
# 'scrapy.pipelines.images.ImagesPipeline': 1
# 使用自己創建的類物件
'bmw.pipelines.BMWImagesPipeline' : 1
}
# 圖片下載的路徑,供image pipelines使用
IMAGES_STORE = os.path.join(os.path.dirname(os.path.dirname(__file__)), 'images')
美好的日子總是短暫的,雖然還想繼續與大家暢談,但是本篇博文到此已經結束了,如果還嫌不夠過癮,不用擔心,我們下篇見!

??好書不厭讀百回,熟讀課思子自知,而我想要成為全場最靚的仔,就必須堅持通過學習來獲取更多知識,用知識改變命運,用博客見證成長,用行動證明我在努力,
??如果我的博客對你有幫助、如果你喜歡我的博客內容,請“點贊” “評論”“收藏”一鍵三連哦!聽說點贊的人運氣不會太差,每一天都會元氣滿滿呦!如果實在要白嫖的話,那祝你開心每一天,歡迎常來我博客看看,
??碼字不易,大家的支持就是我堅持下去的動力,點贊后不要忘了關注我哦!

轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/147783.html
標籤:其他