再看看純集成顯卡GPU的mobilenet-ssd 的推理性能, 測驗平臺是i5 7440HQ, 4核4執行緒, GPU是Gen9 的GT2, 24EU, 屬于純大白菜集成顯卡
首先是FP32模型
當Batch size =1時
inference request(nireq) = 1時,即同時只有一個推理請求
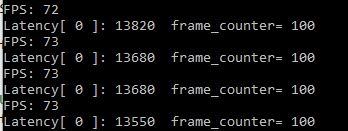
Latency = 13.6ms, Throughtput = 73FPS, 性能還不錯,是CPU的2倍多
inference request(nireq) = 4時,即設定GPU_THROUGHPUT_STREAMS = GPU_THROUGHPUT_AUTO時,openvino建議number of stream數為2, 對應的number of ireq并發數為4 , 同時并發4個推理請求
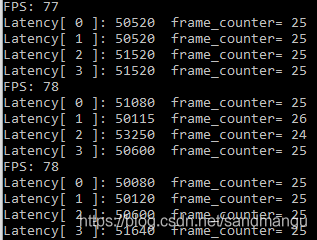
這個就有點尷尬了,Throughtput = 78FPS, 提升不大, 對應的CPU推理是96FPS。這時候的性能表現不如CPU。這時候每路推理的一致性還不錯,每路的作業量基本一致
接下來看看batch size = 3,inference request(nireq) = 4時。即每次推理處理三張圖片, 4路推理并發的情況
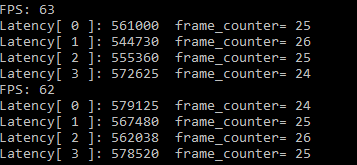
63FPS, 看來集成顯卡資源有限,資料量一旦超出硬體的能力范圍性能就會大打折扣
接下來是FP16模型
當Batch size =1時
inference request(nireq) = 1時,即同時只有一個推理請求
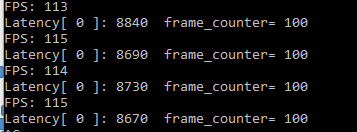
Latency: 9ms, Throughtput: 113FPS, 這個數字大大高于CPU FP32的最好表現
inference request(nireq) = 4時,即設定GPU_THROUGHPUT_STREAMS = GPU_THROUGHPUT_AUTO時,openvino建議number of stream數為2, 對應的number of ireq并發數為4 , 同時并發4個推理請求
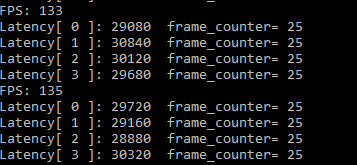
133FPS,看來GPU相對于CPU確實更適合做推理。同時相對于FP32的模型,因為FP16模型對記憶體帶寬的需求減半,所以性能也是大大的提升。
還是看batch size = 3,inference request(nireq) = 4時。即每次推理處理三張圖片, 4路推理并發的情況
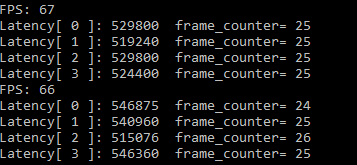
看來還是硬體資源有限,資料一多以后處理能力就會大幅度下降。
前面都是用GPU_THROUGHPUT_STREAMS = GPU_THROUGHPUT_AUTO來測驗,最后看一下手工設定GPU_THROUGHPUT_STREAMS = 1,即nstream = 1, nireq =2的情況,看看性能會不會減半
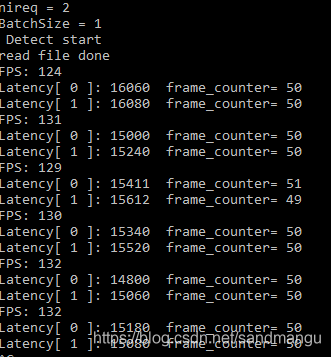
這個FPS幾乎和GPU_THROUGHPUT_AUTO一樣了,只有不到2%的下降,看來前2路的推理就占了GPU絕大多數的資源,GPU_THROUGHPUT_AUTO多出來的2路nireq就是為了再從蚊子腿里再找一些肉。
簡單總結一下,OpenVINO的GPU推理
對GPU推理來說,FP16的性能大大好于FP32, 基本可以翻倍
batch size一定要設為1,因為GPU的資源限制比CPU還多,所以一定要精打細算,少食多餐
推理并發數不一定非要按照GPU_THROUGHPUT_AUTO的建議值來設,并發數稍微少一些也能獲得很好的性能,同時也能給其他系統應用保留更多的資源調度
GPU推理不容易造成CPU過熱降頻而引起性能下降,同時也不怎么受Windows后臺程式的影響。只要有足夠的CPU資源給GPU喂資料,處理速度都會比較穩定
GPU推理性能會受其他圖形程式使用GPU而引起性能下降,比如推理同時呼叫OpenCV的imshow()顯示會導致推理速度下降
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/160000.html
標籤:英特爾技術
上一篇:矩形面積交[藍橋杯]
下一篇:Java中List去重問題分析