01 函式支持
OpenVINO 2020R04版本支持ONNX格式檔案的直接讀取了,使用的函式還是跟之前讀取IR檔案函式保持一致,只是第二個引數預設為空時候,就會嘗試讀取ONNX格式檔案。相關的函式與引數解釋如下:
CNNNetwork InferenceEngine::Core::ReadNetwork(
const std::string & modelPath,
const std::string & binPath = {}
) const
其中
modelPath 表示模型輸入路徑,(.xml 或者.onnx)
binPath 表示IR格式化資料路徑(*.bin),如果為空,嘗試讀取跟modelPath同名的bin檔案,如果失敗就會嘗試直接加載IR檔案。
02
ResNet模型轉換
這里我使用pytorch中torchvision自帶的ResNet18預訓練模型,首先把它從pth轉換為ONNX格式,轉換的腳本如下:
model = torchvision.models.resnet18(pretrained=True).eval()
dummy_input = torch.randn((1, 3, 224, 224))
torch.onnx.export(model, dummy_input, "resnet18.onnx")
轉換為IR中間檔案格式,參見下面的鏈接,這里不再贅述
從Pytorch 的ONNX到OpenVINO中IR中間層
這樣我們就得到了ONNX格式的模型了。該模型是在ImageNet資料集上訓練生成的,支持1000個類別的影像分類,對影像預處理的引數支持與輸入格式如下:
輸入影像: HxW=224x224,
通道:RGB三通道影像,
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]
對比測驗
這里我們分別使用ResNet18網路的ONNX格式與IR格式在OpenVINO 2020R04 版本上進行測驗,最終得到的時間比較如下:
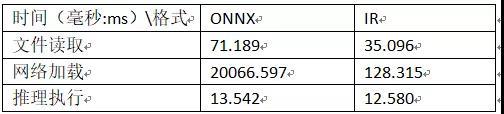
可以看出直接讀取ONNX方式執行的主要瓶頸居然在加載網路這步,對應的函式為:
ExecutableNetwork InferenceEngine::Core::LoadNetwork(
const CNNNetwork & network,
const std::string & deviceName,
const std::map< std::string, std::string > & config = {}
)
還好,當處理視頻或者多次回圈呼叫模型推理的時候,該函式屬于初始化步驟,只會執行一次,不太會影響FPS。但是這個慢的有點離譜!希望可以在下個版本中可以改進一波。在推理執行上,兩個格式基本速度相當,處理視頻時候FPS也基本都很穩定。OpenVINO支持ONNX模型加載與推理穩了,這個將會是很多pytorch開發者的福音,CPU加速模型不是夢了。下面可以看一下我執行的推理時間與FPS:
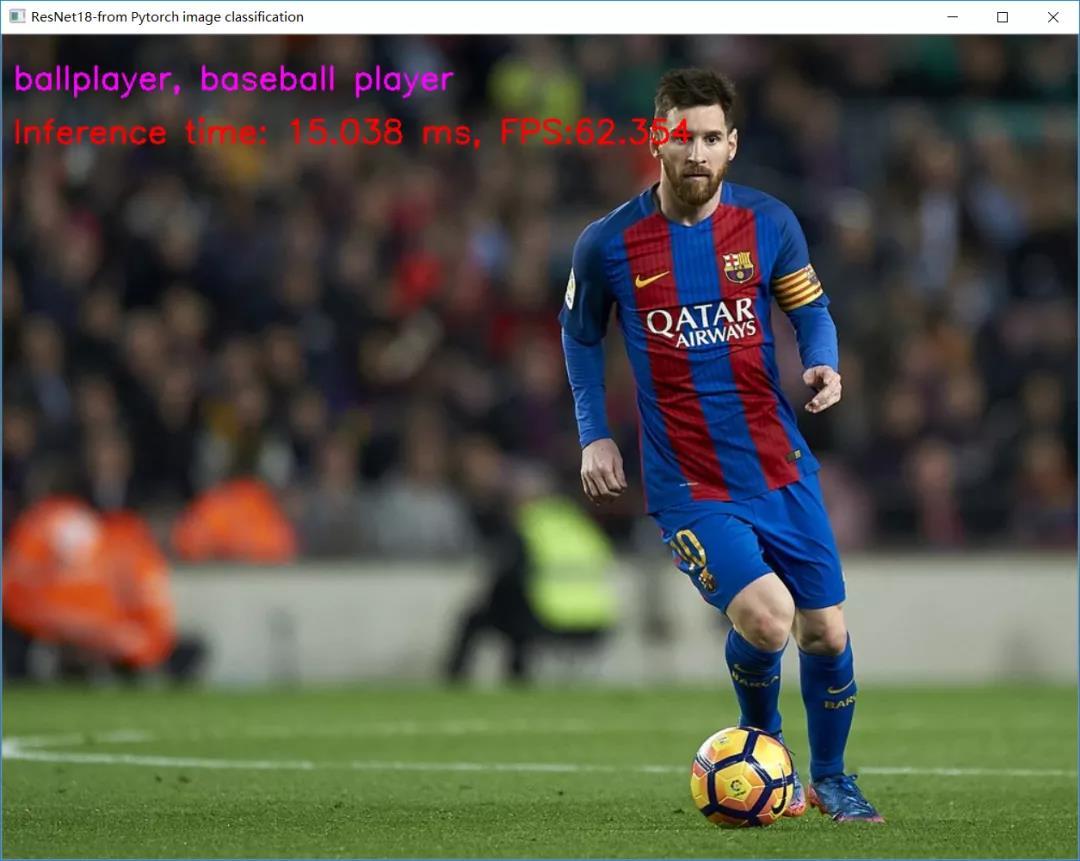
這速度,還用說嗎?靠譜!
測驗代碼
image_classification方法默認執行IR格式加載,修改引數為True執行ONNX格式推理,代碼如下:
from __future__ import print_function
import cv2
import numpy as np
import time
import logging as log
from openvino.inference_engine import IECore
with open('imagenet_classes.txt') as f:
labels = [line.strip() for line in f.readlines()]
def image_classification(use_onnx=False):
model_xml = "resnet18.xml"
model_bin = "resnet18.bin"
onnx_model = "resnet18.onnx"
# Plugin initialization for specified device and load extensions library if specified
log.info("Creating Inference Engine")
ie = IECore()
# Read IR
log.info("Loading network files:\n\t{}\n\t{}".format(model_xml, model_bin))
inf_start = time.time()
if use_onnx:
# 直接使用ONNX格式加載
net = ie.read_network(model=onnx_model)
else:
# IR 格式加載
net = ie.read_network(model=model_xml, weights=model_bin)
load_time = time.time() - inf_start
print("read network time(ms) : %.3f"%(load_time*1000))
log.info("Preparing input blobs")
input_blob = next(iter(net.input_info))
out_blob = next(iter(net.outputs))
# Read and pre-process input images
n, c, h, w = net.input_info[input_blob].input_data.shape
src = cv2.imread("D:/images/messi.jpg")
# image = cv2.dnn.blobFromImage(src, 0.00375, (w, h), (123.675, 116.28, 103.53), True)
image = cv2.resize(src, (w, h))
image = np.float32(image) / 255.0
image[:, :, ] -= (np.float32(0.485), np.float32(0.456), np.float32(0.406))
image[:, :, ] /= (np.float32(0.229), np.float32(0.224), np.float32(0.225))
image = image.transpose((2, 0, 1))
# Loading model to the plugin
log.info("Loading model to the plugin")
start_load = time.time()
exec_net = ie.load_network(network=net, device_name="CPU")
end_load = time.time() - start_load
print("load time(ms) : %.3f" % (end_load * 1000))
# Start sync inference
log.info("Starting inference in synchronous mode")
inf_start1 = time.time()
res = exec_net.infer(inputs={input_blob: [image]})
inf_end1 = time.time() - inf_start1
print("infer onnx as network time(ms) : %.3f" % (inf_end1 * 1000))
# Processing output blob
log.info("Processing output blob")
res = res[out_blob]
label_index = np.argmax(res, 1)
label_txt = labels[label_index[0]]
inf_end = time.time()
det_time = inf_end - inf_start1
inf_time_message = "Inference time: {:.3f} ms, FPS:{:.3f}".format(det_time * 1000, 1000 / (det_time * 1000 + 1))
cv2.putText(src, label_txt, (10, 50), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 255), 2, 8)
cv2.putText(src, inf_time_message, (10, 100), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 255), 2, 8)
cv2.imshow("ResNet18-from Pytorch image classification", src)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == '__main__':
image_classification(True)
還有一個發現,OpenVINO2020 R04的Python版本在SDK方面,對網路的輸入與輸出不再使用inputs與outputs了。用什么替代了,可以自己看上面的代碼即可。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/170092.html
標籤:英特爾技術