InnoDB的一棵B+樹可以存放多少行資料?
答案:約2千萬
為什么是這么多?
因為這是可以算出來的,要搞清楚這個問題,先從InnoDB索引資料結構、資料組織方式說起,
計算機在存盤資料的時候,有最小存盤單元,這就好比現金的流通最小單位是一毛,
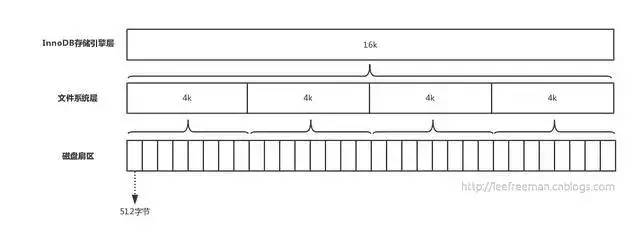
在計算機中,磁盤存盤資料最小單元是扇區,一個扇區的大小是512位元組,而檔案系統(例如XFS/EXT4)的最小單元是塊,一個塊的大小是4k,而對于InnoDB存盤引擎也有自己的最小儲存單元,頁(Page),一個頁的大小是16K,
下面幾張圖可以理解最小存盤單元:
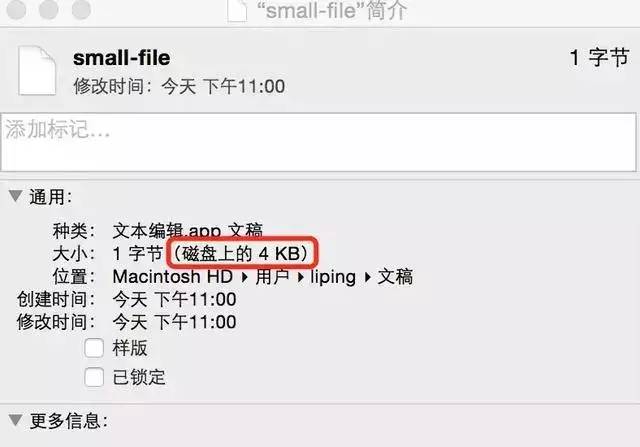
檔案系統中一個檔案大小只有1個位元組,但不得不占磁盤上4KB的空間,
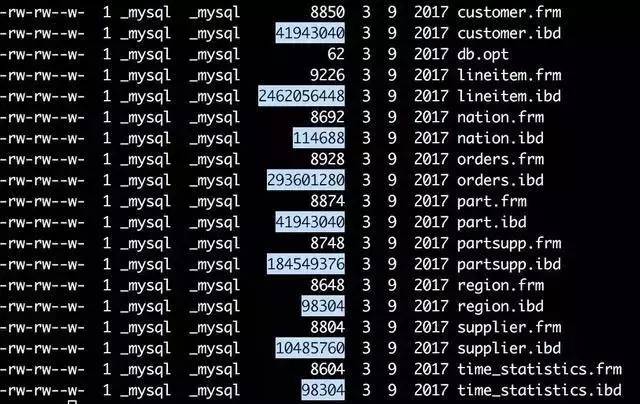
InnoDB的所有資料檔案(后綴為ibd的檔案),大小始終都是16384(16k)的整數倍,
磁盤扇區、檔案系統、InnoDB存盤引擎都有各自的最小存盤單元,
在MySQL中,InnoDB頁的大小默認是16k,當然也可以通過引數設定:

表中的資料都是存盤在頁中的,所以一個頁中能存盤多少行資料呢?
假設一行資料的大小是1k,那么一個頁可以存放16行這樣的資料,
如果資料庫只按這樣的方式存盤,**如何查找資料就成為一個問題,**因為不知道要查找的資料存在哪個頁中,也不可能把所有的頁遍歷一遍,那樣太慢了,
不過,可以使用B+樹的方式組織這些資料,如圖所示:
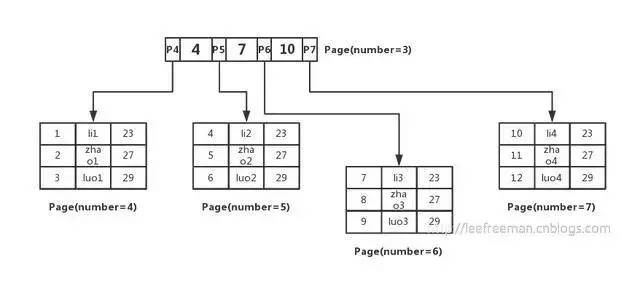
先將資料記錄按主鍵進行排序,分別存放在不同的頁中(為了便于理解這里一個頁中只存放3條記錄,實際情況可以存放很多)
除了存放資料的頁以外,還有存放鍵值+指標的頁,如圖中page number=3的頁,該頁存放鍵值和指向資料頁的指標,這樣的頁由N個鍵值+指標組成,
當然它也是排好序的,這樣的資料組織形式,我們稱為索引組織表,
現在來看下,要查找一條資料,怎么查?
如:select * from user where id=5;
這里id是主鍵,通過這棵B+樹來查找,首先找到根頁,你怎么知道user表的根頁在哪呢?
其實每張表的根頁位置在表空間檔案中是固定的,即page number=3的頁,
找到根頁后通過二分查找法,定位到id=5的資料應該在指標P5指向的頁中,那么進一步去page number=5的頁中查找,同樣通過二分查詢法即可找到id=5的記錄:
| 5 | zhao2 | 27 |
現在清楚了InnoDB中主鍵索引B+樹是如何組織資料、查詢資料的,
總結一下:
-
InnoDB存盤引擎的最小存盤單元是頁,頁可以用于存放資料也可以用于存放鍵值+指標,在B+樹中葉子節點存放資料,非葉子節點存放鍵值+指標,
-
索引組織表通過非葉子節點的二分查找法以及指標確定資料在哪個頁中,進而在去資料頁中查找到需要的資料;
那么回到我們開始的問題,通常一棵B+樹可以存放多少行資料?
這里我們先假設B+樹高為2,即存在一個根節點和若干個葉子節點,那么這棵B+樹的存放總記錄數為:根節點指標數*單個葉子節點記錄行數,
上文已經說明單個葉子節點(頁)中的記錄數=16K/1K=16,(這里假設一行記錄的資料大小為1k,實際上現在很多互聯網業務資料記錄大小通常就是1K左右),
那么現在需要計算出非葉子節點能存放多少指標?
其實這也很好算,假設主鍵ID為bigint型別,長度為8位元組,而指標大小在InnoDB原始碼中設定為6位元組,這樣一共14位元組
我們一個頁中能存放多少這樣的單元,其實就代表有多少指標,即16384/14=1170,
那么可以算出一棵高度為2的B+樹,能存放1170*16=18720條這樣的資料記錄,
根據同樣的原理可以算出一個高度為3的B+樹可以存放:1170117016=21902400條這樣的記錄,
所以在InnoDB中B+樹高度一般為1-3層,它就能滿足千萬級的資料存盤,
在查找資料時,一次頁的查找代表一次IO,所以通過主鍵索引查詢通常只需要1-3次IO操作即可查找到資料,
怎么得到InnoDB主鍵索引B+樹的高度?
上面通過推斷得出B+樹的高度通常是1-3,下面從另外一個側面證明這個結論,
在InnoDB的表空間檔案中,約定page number為3的代表主鍵索引的根頁,而在根頁偏移量為64的地方存放了該B+樹的page level,
如果page level為1,樹高為2,page level為2,則樹高為3,即B+樹的高度=page level+1;下面將從實際環境中嘗試找到這個page level,
在實際操作之前,可以通過InnoDB元資料表確認主鍵索引根頁的page number為3,也可以從《InnoDB存盤引擎》這本書中得到確認,


可以看出資料庫dbt3下的customer表、lineitem表主鍵索引根頁的page number均為3,而其他的二級索引page number為4,
關于二級索引與主鍵索引的區別請參考MySQL相關書籍,本文不在此介紹,
下面對資料庫表空間檔案做想相關的決議:
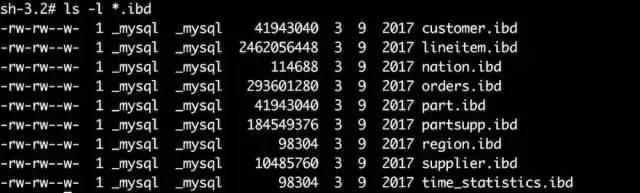
因為主鍵索引B+樹的根頁在整個表空間檔案中的第3個頁開始,所以可以算出它在檔案中的偏移量:16384*3=49152(16384為頁大小),
另外根據《InnoDB存盤引擎》中描述在根頁的64偏移量位置前2個位元組,保存了page level的值
因此我想要的page level的值在整個檔案中的偏移量為:16384*3+64=49152+64=49216,前2個位元組中,
接下來用hexdump工具,查看表空間檔案指定偏移量上的資料:
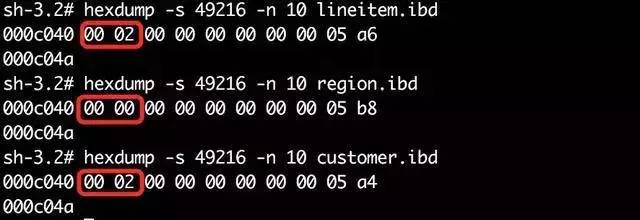
linetem表的page level為2,B+樹高度為page level+1=3;
region表的page level為0,B+樹高度為page level+1=1;
customer表的page level為2,B+樹高度為page level+1=3;
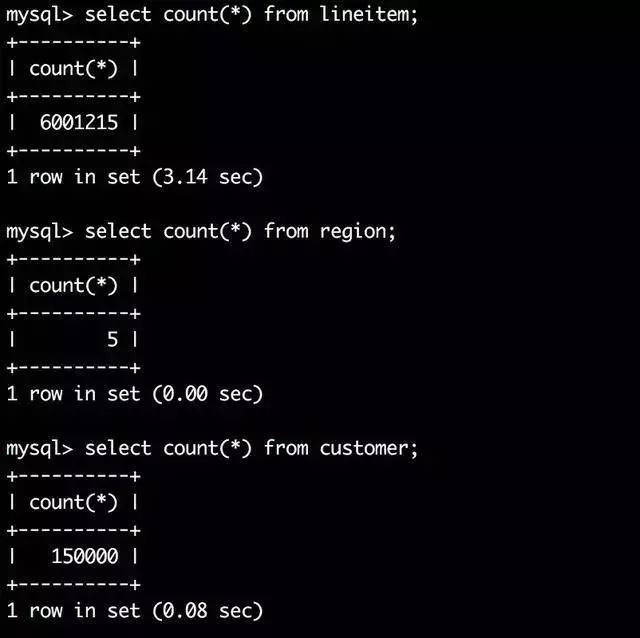
這三張表的資料量如下:
總結:
lineitem表的資料行數為600多萬,B+樹高度為3,customer表資料行數只有15萬,B+樹高度也為3,可以看出盡管資料量差異較大,這兩個表樹的高度都是3
換句話說這兩個表通過索引查詢效率并沒有太大差異,因為都只需要做3次IO,那么如果有一張表行數是一千萬,那么他的B+樹高度依舊是3,查詢效率仍然不會相差太大,
region表只有5行資料,當然他的B+樹高度為1,
面試題
有一道MySQL的面試題,為什么MySQL的索引要使用B+樹而不是其它樹形結構?比如B樹?
這個問題的復雜版本可以參考本文;
簡單回答是:
因為B樹不管葉子節點還是非葉子節點,都會保存資料,這樣導致在非葉子節點中能保存的指標數量變少(有些資料也稱為扇出)
指標少的情況下要保存大量資料,只能增加樹的高度,導致IO操作變多,查詢性能變低;
小結
本文從一個問題出發,逐步介紹了InnoDB索引組織表的原理、查詢方式,并結合已有知識,回答該問題,結合實踐來證明,
當然為了表述簡單易懂,文中忽略了一些細枝末節,比如一個頁中不可能所有空間都用于存放資料,它還會存放一些少量的其他欄位比如page level,index number等等,另外還有頁的填充因子也導致一個頁不可能全部用于保存資料,
寫在最后
歡迎大家關注我的公眾號【風平浪靜如碼】,海量Java相關文章,學習資料都會在里面更新,整理的資料也會放在里面,
覺得寫的還不錯的就點個贊,加個關注唄!點關注,不迷路,持續更新!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/173818.html
標籤:其他