環境準備:
事先安裝好,pycharm
打開File——>Settings——>Projext——>Project Interpriter
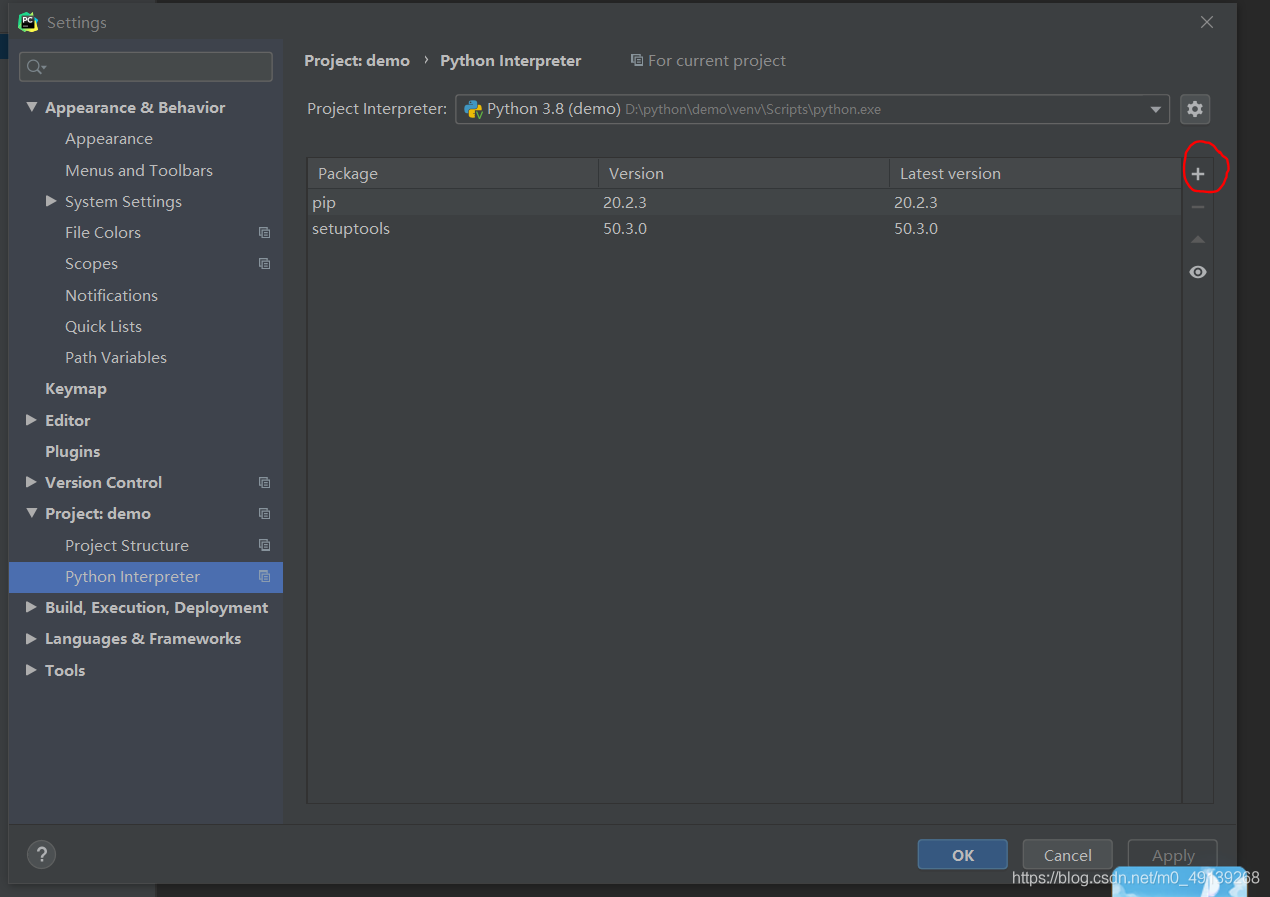
點擊加號(圖中紅圈的地方)
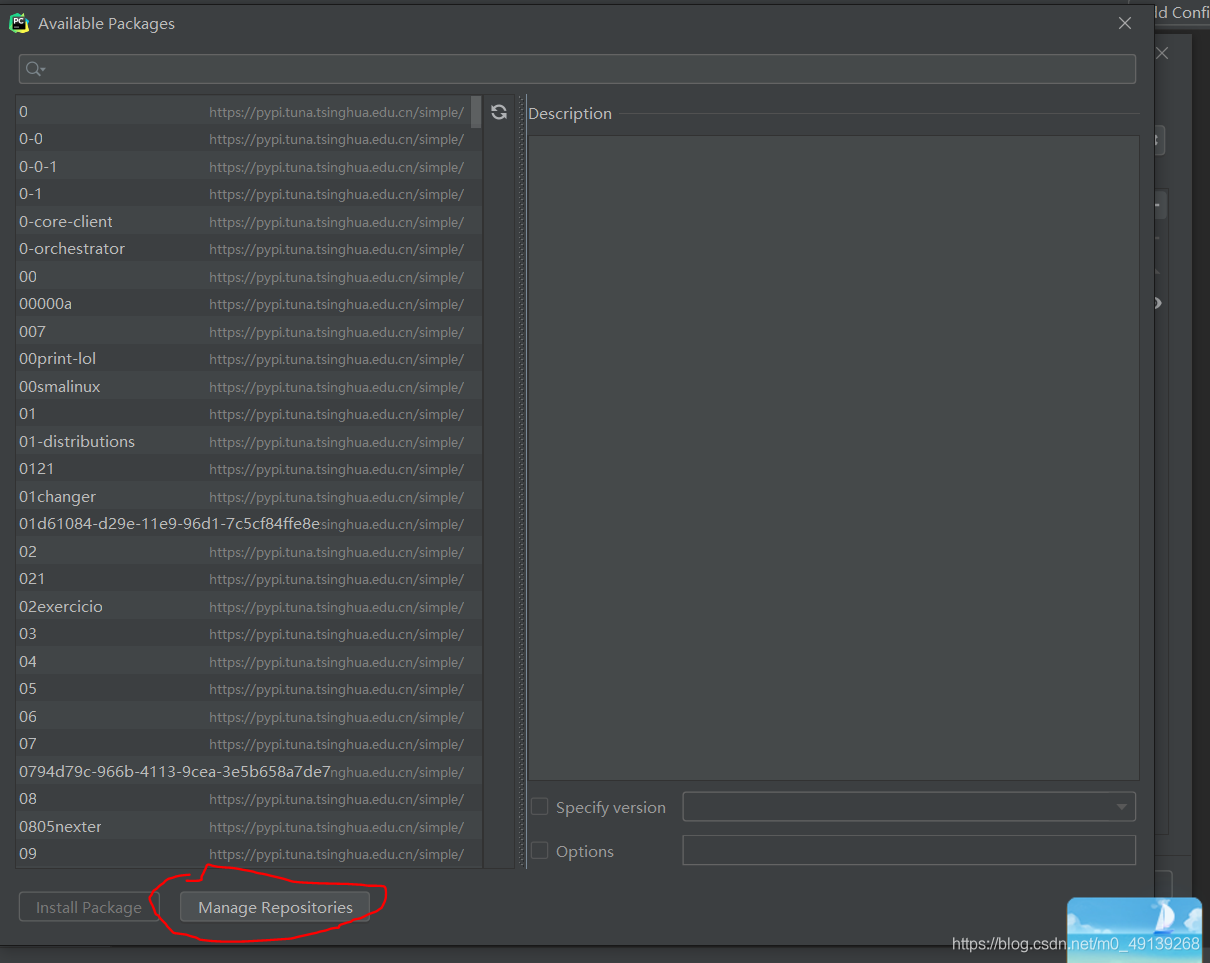
點擊紅圈中的按鈕
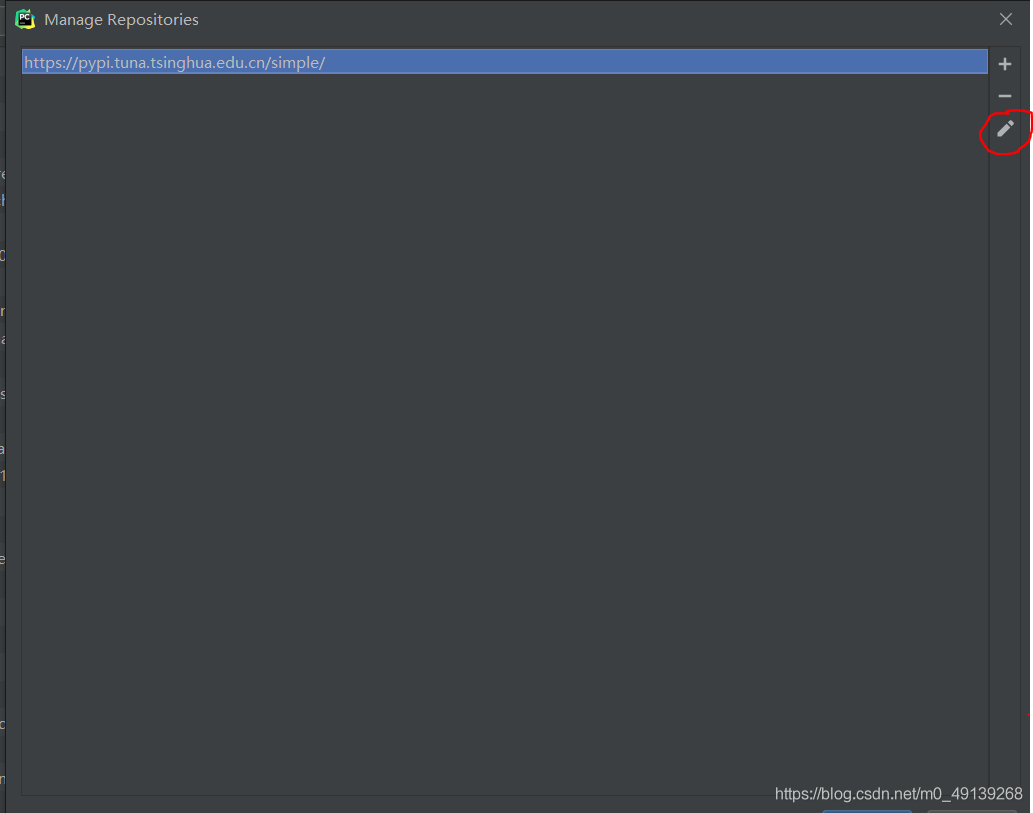
選中第一條,點擊鉛筆,將原來的鏈接替換為(這里已經替換過了):
https://pypi.tuna.tsinghua.edu.cn/simple/
點擊OK后,輸入requests-html然后回車
選中requests-html后點擊Install Package
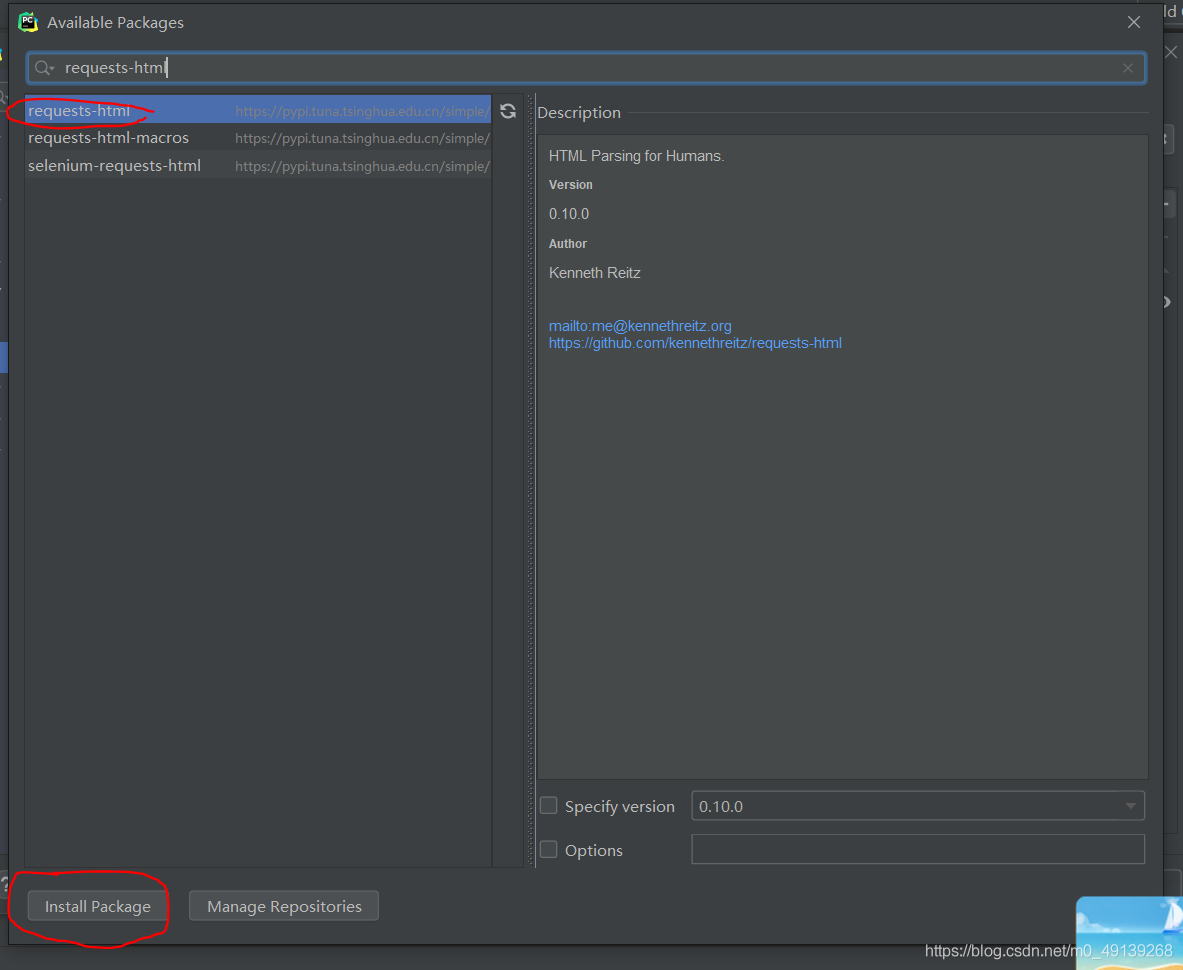
等待安裝成功,關閉
通過決議網頁源代碼
實體內容:
從某博主的所有文章爬取想要的內容,
實體背景:
從(https://me.csdn.net/weixin_44286745)博主的所有文章獲取各文章的標題,時間,閱讀量,
- 匯入requests_html中HTMLSession方法,并創建其物件
from requests_html import HTMLSession
session = HTMLSession()
- 使用get請求獲取要爬的網站,得到該網頁的源代碼,
html = session.get("https://me.csdn.net/weixin_44286745").html
- 找到所有文章
allBlog=html.xpath("//dl[@class='tab_page_list']")
-
進入網站主頁(本例: https://me.csdn.net/weixin_44286745)
-
文章空白處右鍵檢查可以定位到這文章的標簽
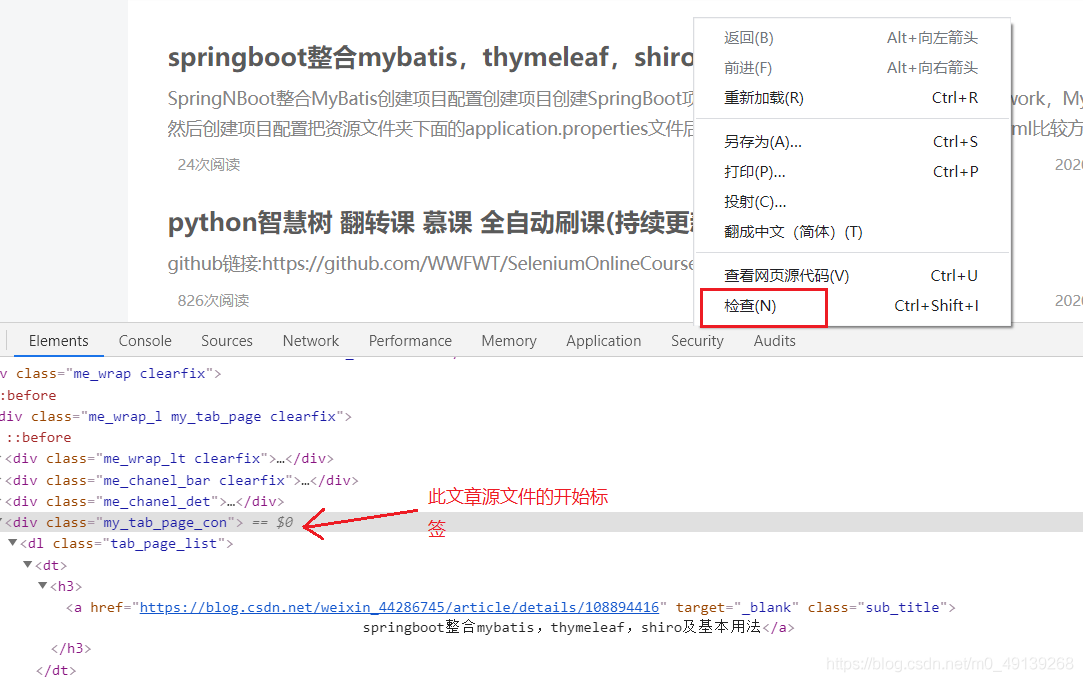
-
其他文章一樣操作,然后找到所有文章共同的標記(這里所有文章的class都是‘my_tab_page_con’)
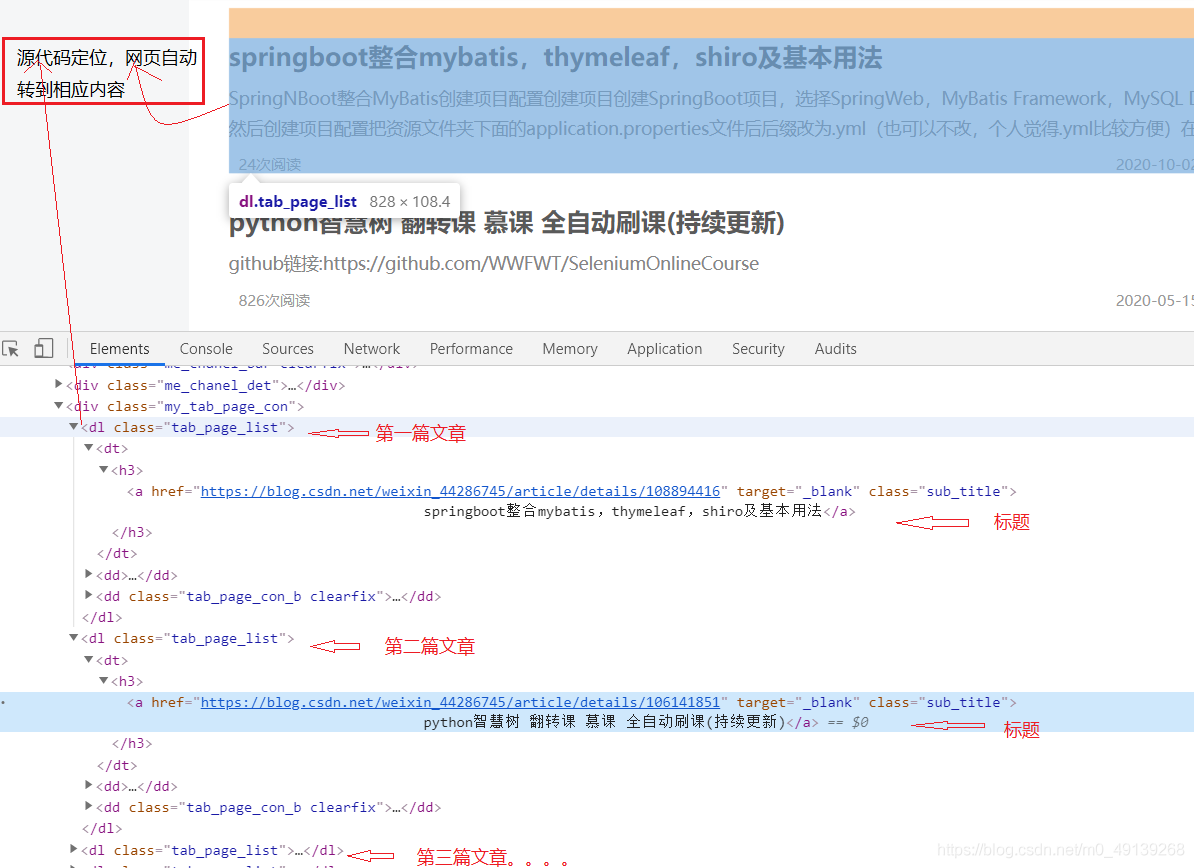
-
xpath 可以遍歷html的各個標簽和屬性,來定位到我們需要的資訊的位置,并提取,
-
網頁分析獲取標題,閱讀量,日期,
for i in allBlog:
title = i.xpath("dl/dt/h3/a")[0].text
views = i.xpath("//div[@class='tab_page_b_l fl']")[0].text
date = i.xpath("//div[@class='tab_page_b_r fr']")[0].text
print(title +' ' +views +' ' + date )
網頁分析:
-
因為有多篇文章,分別獲取使用for回圈,上述代碼已得到所有文章所以i表示一篇文章
-
第二行代碼獲取文章標題,于獲取文章類似,滑鼠放到標題上右鍵檢查,因為文章只有一個標題所以用絕對路徑也可以按標簽一層層進到標題位置,
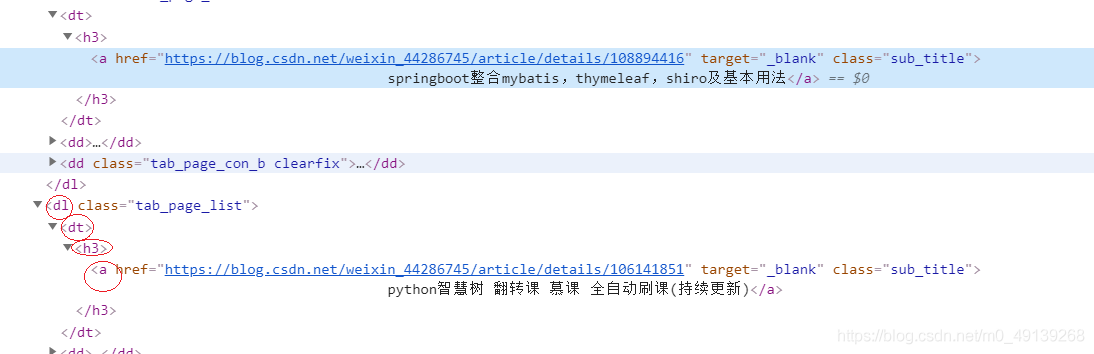
-
xpath回傳的是串列,我們要第一個所以要加下標(串列里也只有一個元素),要輸出的是文本,所以,text獲取文本,
-
閱讀量和時間也是重復的操作
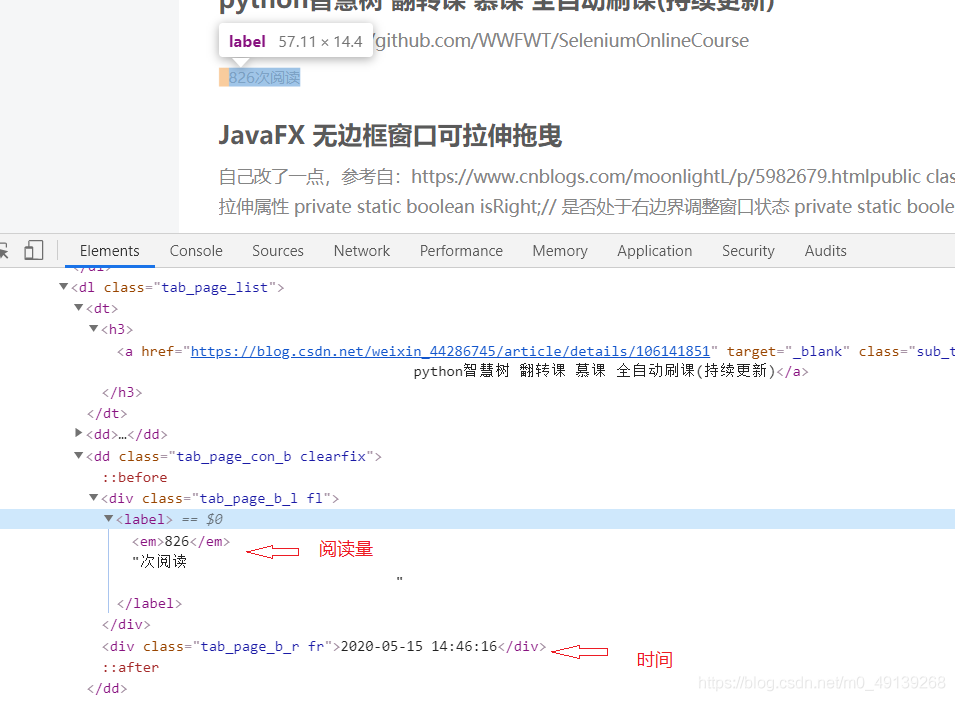
-
可以用相對路徑也可以用絕對路徑,一般都是用相對路徑,格式仿照代碼,
-
第五行代碼,每得到一篇文章的資訊就輸出,遍歷完就可以獲得全部的資訊,
完整代碼:
from requests_html import HTMLSession
session = HTMLSession()
html = session.get("https://me.csdn.net/weixin_44286745").html
allBlog=html.xpath("//dl[@class='tab_page_list']")
for i in allBlog:
title = i.xpath("dl/dt/h3/a")[0].text
views = i.xpath("//div[@class='tab_page_b_l fl']")[0].text
date = i.xpath("//div[@class='tab_page_b_r fr']")[0].text
print(title +' ' +views +' ' + date )
可以自己爬其他東西,如文章圖片,動手試試吧!!!
未完待續
通過html請求
自動化
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/175269.html
標籤:其他