開發環境
軟體版本資訊:
Windows10 64位
Tensorflow1.15
Tensorflow object detection API 1.x
Python3.6.5
VS2015 VC++
CUDA10.0
硬體:
CPUi7
GPU 1050ti
如何安裝tensorflow object detection API框架,看這里:
Tensorflow Object Detection API 終于支持tensorflow1.x與tensorflow2.x了
資料集處理與生成
首先需要下載資料集,下載地址為:
https://pan.baidu.com/s/1UbFkGm4EppdAU660Vu7SdQ
總計7581張影像,基于Pascal VOC2012完成標注。分為兩個類別,分別是安全帽與人(hat與person),json格式如下:
item {
id: 1
name: 'hat'
}
item {
id: 2
name: 'person'
}
資料集下載之后,并不能被tensorflow object detection API框架中的腳本轉換為tfrecord,主要是有幾個XML跟JPEG影像格式錯誤,本人經過一番磨難之后把它們全部修正了。修正之后的資料運行下面兩個腳本即可生成訓練集與驗證集的tfrecord資料,命令列如下:

這里需要注意的是create_pascal_tf_record.py 腳本的165行把
'aeroplane_' + FLAGS.set + '.txt')
修改為:
FLAGS.set + '.txt')
原因是這里的資料集沒有做分類train/val。所以需要修改一下,修改完成之后保存。運行上述的命令列,就可以正確生成tfrecord,否則會遇到錯誤。
模型訓練
基于faster_rcnn_inception_v2_coco物件檢測模型實作遷移學習,首先需要配置遷移學習的config檔案,對應的組態檔可以從:
research\object_detection\samples\configs
中發現,發現檔案:
faster_rcnn_inception_v2_coco.config
之后,修改組態檔的中相關部分,關于如何修改,修改什么,可以看這里:


修完完成之后,在D盤下新建好幾個目錄之后,執行下面的命令列引數:

就會開始訓練,總計訓練40000 step。訓練程序中可以通過tensorboard查看訓練結果:
模型匯出
完成了40000 step訓練之后,就可以看到對應的檢查點檔案,借助tensorflow object detection API框架提供的模型匯出腳本,可以把檢查點檔案匯出為凍結圖格式的PB檔案。相關的命令列引數如下:

得到pb檔案之后,使用OpenCV4.x中的tf_text_graph_faster_rcnn.py腳本,轉換生成graph.pbtxt組態檔。最終得到:
- frozen_inference_graph.pb
- frozen_inference_graph.pbtxt
轉為OpenVINO IR檔案
python mo_tf.py
--input_model D:\safehat_train\models\train\frozen_inference_graph.pb /
--transformations_config extensions\front\tf\faster_rcnn_support_api_v1.15.json /
--tensorflow_object_detection_api_pipeline_config D:\safehat_train\models\pipeline.config /
--input_shape [1,600,600,3] /
--reverse_input_channels
使用模型實作,安全帽檢測
from __future__ import print_function
import cv2
import time
import logging as log
from openvino.inference_engine import IECore
labels = ["hat", "person"]
def safehat_detection():
model_xml = "D:/projects/opencv_tutorial/data/models/safetyhat/frozen_inference_graph.xml"
model_bin = "D:/projects/opencv_tutorial/data/models/safetyhat/frozen_inference_graph.bin"
log.info("Creating Inference Engine")
ie = IECore()
# Read IR
net = ie.read_network(model=model_xml, weights=model_bin)
log.info("Preparing input blobs")
input_it = iter(net.input_info)
input1_blob = next(input_it)
input2_blob = next(input_it)
print(input2_blob)
out_blob = next(iter(net.outputs))
# Read and pre-process input images
print(net.input_info[input1_blob].input_data.shape)
print(net.input_info[input2_blob].input_data.shape)
image = cv2.imread("D:/safehat/test/1.jpg")
ih, iw, ic = image.shape
image_blob = cv2.dnn.blobFromImage(image, 1.0, (600, 600), (0, 0, 0), False)
# Loading model to the plugin
exec_net = ie.load_network(network=net, device_name="CPU")
# Start sync inference
log.info("Starting inference in synchronous mode")
inf_start1 = time.time()
res = exec_net.infer(inputs={input1_blob:[[600, 600, 1.0]], input2_blob: [image_blob]})
inf_end1 = time.time() - inf_start1
print("inference time(ms) : %.3f" % (inf_end1 * 1000))
# Processing output blob
res = res[out_blob]
for obj in res[0][0]:
if obj[2] > 0.5:
index = int(obj[1])
xmin = int(obj[3] * iw)
ymin = int(obj[4] * ih)
xmax = int(obj[5] * iw)
ymax = int(obj[6] * ih)
cv2.putText(image,labels[index-1], (xmin, ymin), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (255, 0, 0), 2)
cv2.rectangle(image, (xmin, ymin), (xmax, ymax), (0, 0, 255), 2, 8, 0)
cv2.imshow("safetyhat detection", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
if __name__ == '__main__':
safehat_detection()
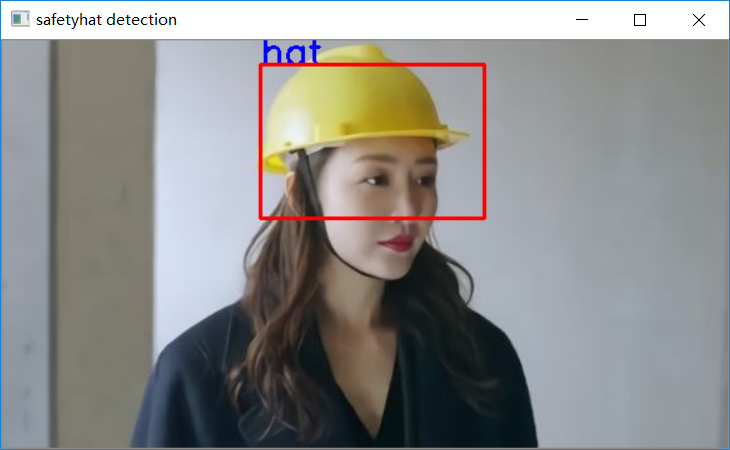
運行結果如下:
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/175287.html
標籤:英特爾技術