smooth-ap
AP是資訊檢索任務的標準度量之一,它是一個單一值,定義為精確召回曲線下的面積,對于一個查詢Iq,檢索集中所有實體的預測相關性得分是通過一個選定的度量來度量的,它的思想就是在排序的時候,dataset中與query相似度高的排名要比與query相似度低的排名靠前,假設采用余弦相似度表示兩個樣本之間的相似度,
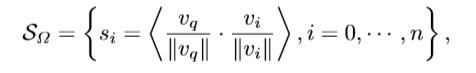
其中
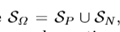
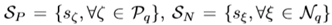
Sp和Sn分別表示正樣本和負樣本的相似度集合,
那么Iq的AP值既可以通過公式(2)計算得到:
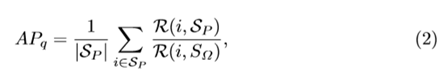
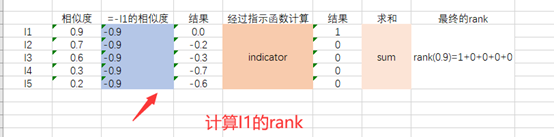
如何計算呢?下面給出一個例子,
 第一行指的是label,與I相同就為1,與I不同就為0,顯然,1/2和2/3的分子和分母分別表示,每一個正例在所有正例中的rank和在所有set里的rank(set包括正例和負例)(需要注意的是AP對排名靠前一定要是正例有很高要求,對排名靠后的正例并沒有那么高的要求,比如,如果I1的相似度為0.65,那么AP=1/2(1/2+2/3),影響就很大),
第一行指的是label,與I相同就為1,與I不同就為0,顯然,1/2和2/3的分子和分母分別表示,每一個正例在所有正例中的rank和在所有set里的rank(set包括正例和負例)(需要注意的是AP對排名靠前一定要是正例有很高要求,對排名靠后的正例并沒有那么高的要求,比如,如果I1的相似度為0.65,那么AP=1/2(1/2+2/3),影響就很大),
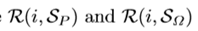
那么rank是如何得到的呢?論文中計算rank的公式(3):
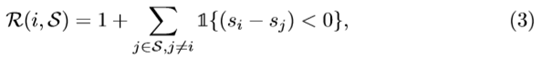
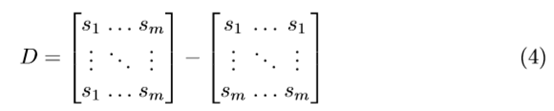
1{·} 是一個指示函式,先由公式(4)計算一個差分矩陣:
那最終的AP計算公式就應該是:
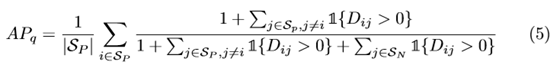
其中:1{·} 是一個Heaviside函式,Heaviside階躍函式定義如下:
H(x) = {(1, x>=0) | (0, x<0)
為了更好地理解AP計算的程序,下面看一個例子:
階躍函式是不可微的,因為smooth-ap將指示函式用sigmoid函式替代,
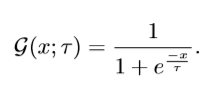
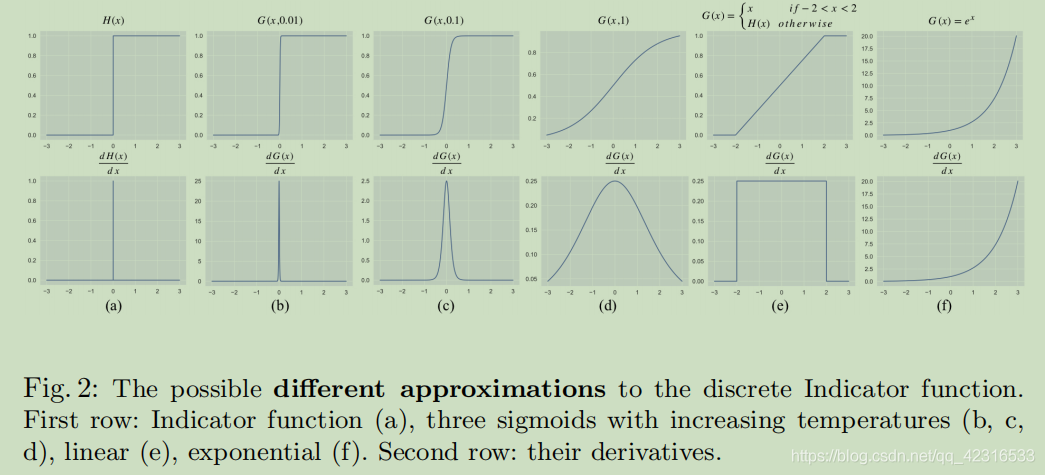
τ控制著sigmoid代替指示函式1{·}的的范圍,它定義了一個由Smooth-AP loss計算的差分矩陣的梯度的可操作區域(operation region),如果排列錯誤,Smooth-AP將嘗試將它們轉換到正確的順序,τ越小,operation region將越小,τ越大,operation region將越大,如下圖(b,c,d)
那么smooth-ap的最終公式為:
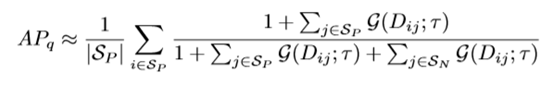
損失函式為:
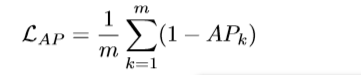
論文后面還解釋了triple loss是指一種度量損失而不是排序損失
,
例如:
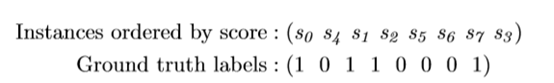 計算triplet loss:
計算triplet loss:
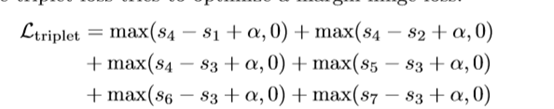
其一:
所有項都是線性組合的,并在一組中平等地處理,這種替代損失可能會迫使模型優化那些對AP影響很小的項,例如優化s4?s1與優化三態損失中的s7?s4是一樣的,但是,從AP的角度來看,重要的是要在高階上糾正錯誤的實體,也就是說triplet loss優化距離,而不是rank,
其二:
線性導數意味著優化程序純粹是基于距離(而不是排序順序),這使得AP在評估時處于次優狀態,例如,在triplet loss的情況下,將s4?s1的距離從0.8減小到0.5相當于從0.2減小到?0.1,因為距離沒有變,但在AP中,排序是變了的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/176928.html
標籤:其他