
CSDN個人主頁: 高智商白癡
原文地址: https://blog.csdn.net/qq_44700693/article/details/109124334?utm_source=app
日常跳轉:
- 匯入
- 單個短視頻
- 獲取視頻的資訊
- 通過m3u8檔案地址下載視頻
- 原始碼及效果
- 番劇劇集
- 獲取視頻的資訊
- 番劇劇集鏈接
- 原始碼及效果
匯入
前段時間我已經將B站的爬取方法做了一個總結:Python爬蟲:嗶哩嗶哩(bilibili)視頻下載,
這一次,我將繼續分享 AcFun 視頻網站的決議,其實相對于B站,A站的反爬機制更為簡單:
單個短視頻
獲取視頻的資訊
為了能夠方便的決議與說明,就肯定會拿一個例子來才好的哇:
【仙女UP特輯】AcFun Family Party ——成都站(今天又是
lsp的一天呢~~)
直接在瀏覽器端打開并抓包該鏈接發現,在 XHR 的資料下,第一條(又或者某一次)的請求就加載了視頻的真實請求鏈接: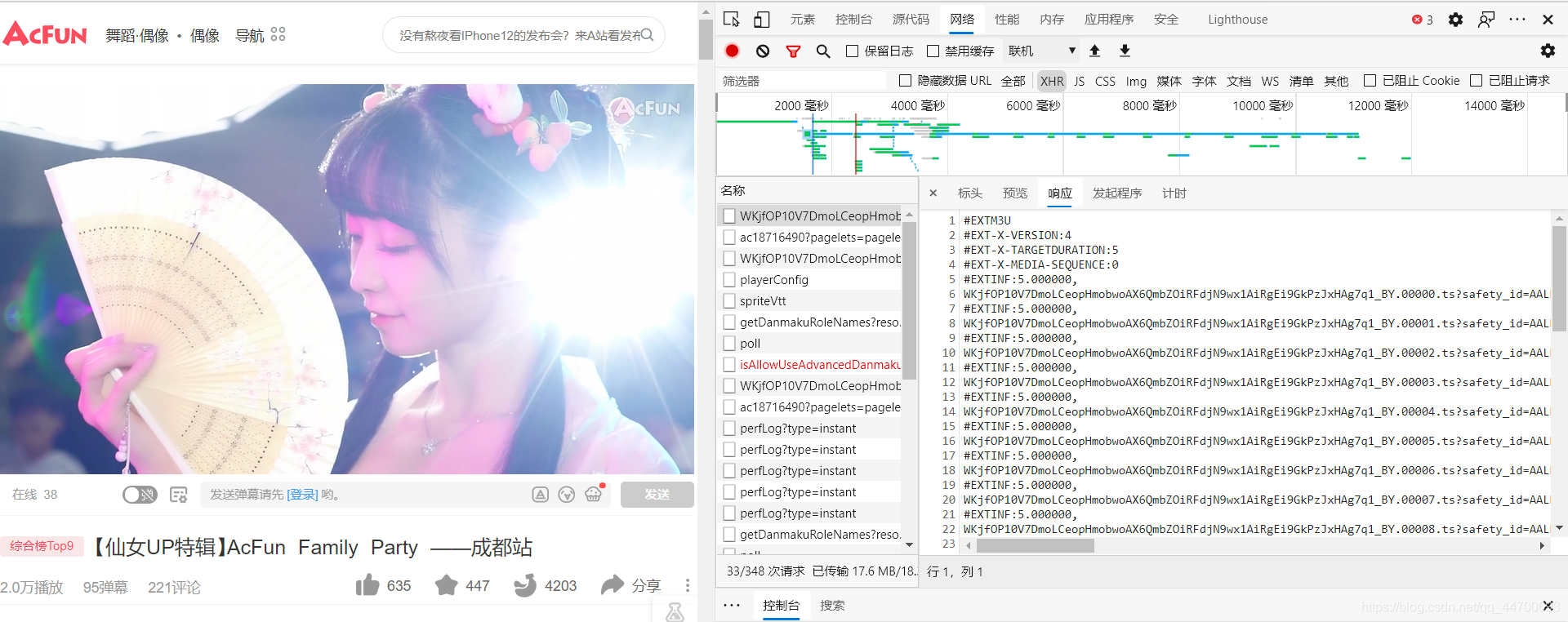
雖然本身僅僅是一個 m3u8 檔案,不過我們還是有辦法處理的,我們在此之前先必須要找到該檔案的親親貴是從哪里發出來的,又或者能夠在哪里找到這個鏈接,
在找遍了 XHR 資料無果后,我決定去看一看網頁原始碼:
當我用 m3u8 檔案的請求鏈接在網頁原始碼中搜索后發現,鏈接就出現在原始碼中:

因為在原始碼中是以 JSON 資料存放的:

所以我們需要將資料格式化,方便我們進行資料提取:
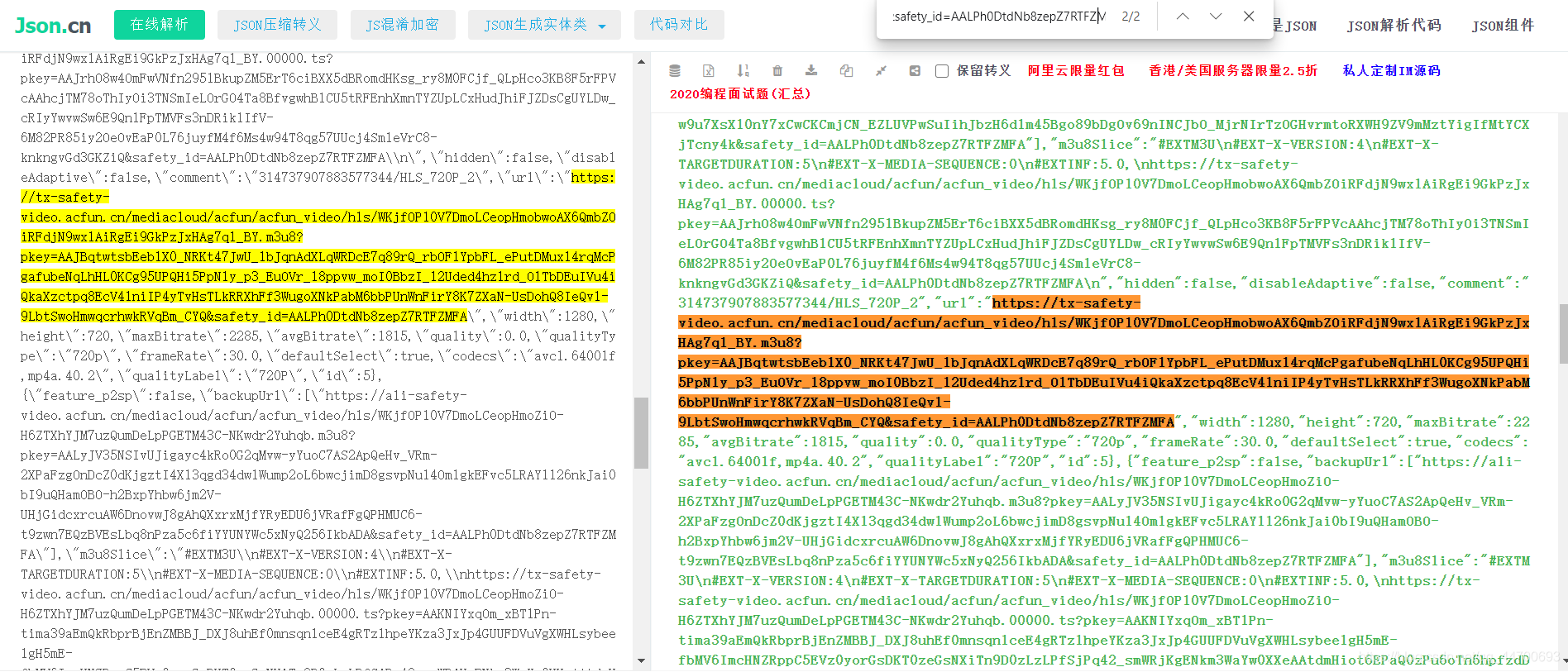
雖然我將該資料格式化以后發現,有一個欄位的值居然也是一個 JSON 資料的格式,所以我們再對第二層的 JSON 資料進行格式化后可以看到以下資訊:
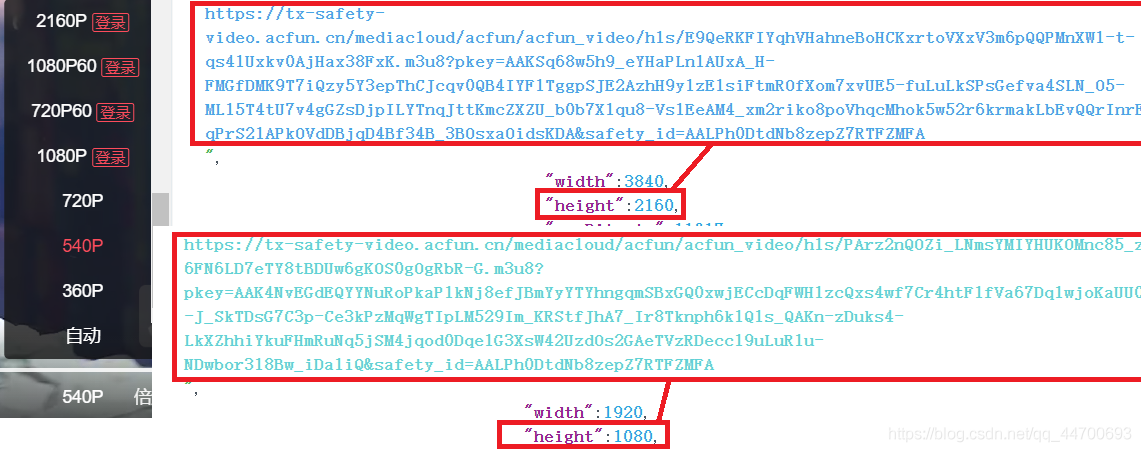
對于未登錄時的狀態,即使網頁端不能直接播放,但是 “ 后臺 ” 早已經給我們準備好了播放鏈接(B站則是加載當前賬戶或著未登錄時能觀看的最大清晰度),所以我們可以在未登陸的情況下 白嫖 超高清資源~~
class m3u8_url():
def __init__(self, f_url):
self.url = f_url
def get_m3u8(self):
global flag, qua, rel_path
html = requests.get(self.url, headers=headers).text
first_json = json.loads(re.findall('window.pageInfo = window.*? = (.*?)};', html)[0] + '}', strict=False)
name = first_json['title'].strip().replace("|",'')
video_info = json.loads(first_json['currentVideoInfo']['ksPlayJson'], strict=False)['adaptationSet'][0]['representation']
為了后續能夠選擇清晰度,所以我還進行了清晰度的爬取:
for quality in video_info: # 清晰度
num += 1
Label[num] = quality['qualityLabel']
print(Label)
choice = int(input("請選擇清晰度: "))
通過m3u8檔案地址下載視頻
到此,我們已經可以拿到視頻的 m3u8 檔案的地址,那么現在就來開始解決之前遺留的一個小問題:如何通過 m3u8 檔案下載視頻?
首先,我們拿到一個 m3u8 檔案來作為案例:
為了方便,在這里我手動的寫了一個 m3u8 檔案來作為例子,
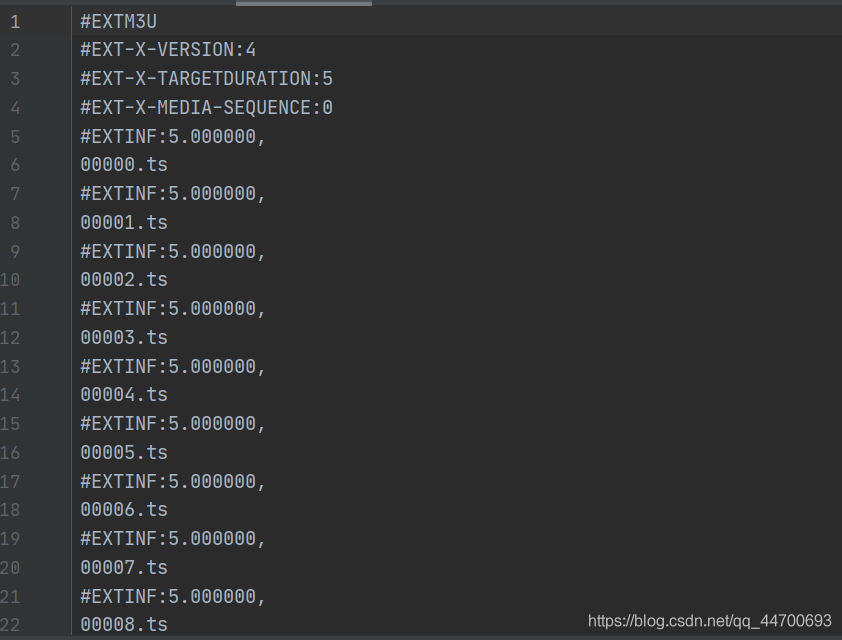
我們知道,在 m3u8 檔案中的視頻鏈接都是 .ts 的分段格式,所以我們必須要先想辦法將所有的 .ts 鏈接都拿出來,并且加上前綴,拼裝成視頻的真實完整的鏈接:(在這里假設視頻原前綴為 https://www.acfun.cn/)
urls=[] # 用于保存視頻的分段鏈接
def get_ts_urls():
with open('123.m3u8',"r") as file:
lines = file.readlines()
for line in lines:
if '.ts' in line:
print("https://www.acfun.cn/"+line)
通過以上方法,我們就可以通過 m3u8 檔案來獲取每一段的視頻鏈接了,接下來,我們再將下載的功能進行完善:
下載的基本思路還是和我以前的一篇文章的思路一樣:Python爬蟲:用最普通的方法爬取ts檔案并合成為mp4格式
class Download():
urls = [] # 用于保存視頻的分段鏈接
def __init__(self, name, m3u8_url, path):
'''
:param name: 視頻名
:param m3u8_url: 視頻的 m3u8檔案 地址
:param path: 下載地址
'''
self.video_name = name
self.path = path
self.f_url = str(m3u8_url).split('hls/')[0] + 'hls/'
with open(self.path + '/{}.m3u8'.format(self.video_name), 'wb')as f:
f.write(requests.get(m3u8_url, headers={'user-agent': 'Chrome/84.0.4147.135'}).content)
def get_ts_urls(self):
with open(self.path + '/{}.m3u8'.format(self.video_name), "r") as file:
lines = file.readlines()
for line in lines:
if '.ts' in line:
self.urls.append(self.f_url + line.replace('\n', ''))
def start_download(self):
self.get_ts_urls()
for url in tqdm(self.urls, desc="正在下載 {} ".format(self.video_name)):
movie = requests.get(url, headers={'user-agent': 'Chrome/84.0.4147.135'})
with open(self.path + '/{}.flv'.format(self.video_name), 'ab')as f:
f.write(movie.content)
os.remove(self.path + '/{}.m3u8'.format(self.video_name))
代碼注解:
- 1、為了最后得到的只有視頻,所以在視頻下載完后,自動的將當前視頻的 m3u8 檔案進行了洗掉操作,
- 2、
line.replace('\n', '')的原因:讀取到的 m3u8 檔案的每一行結尾都含有一個 " \n ",
原始碼及效果
終于,到現在我們已經可以整合代碼并運行看一看了:
import os
import re
import json
import requests
from tqdm import tqdm
path = './'
headers = {
'referer': 'https://www.acfun.cn/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83'
}
class m3u8_url():
def __init__(self, f_url):
self.url = f_url
def get_m3u8(self):
global flag, qua, rel_path
html = requests.get(self.url, headers=headers).text
first_json = json.loads(re.findall('window.pageInfo = window.videoInfo = (.*?)};', html)[0] + '}', strict=False)
name = first_json['title'].strip().replace("|",'')
video_info = json.loads(first_json['currentVideoInfo']['ksPlayJson'], strict=False)['adaptationSet'][0]['representation']
Label = {}
num = 0
for quality in video_info: # 清晰度
num += 1
Label[num] = quality['qualityLabel']
print(Label)
choice = int(input("請選擇清晰度: "))
Download(name + '[{}]'.format(Label[choice]), video_info[choice - 1]['url'], path).start_download()
class Download():
urls = []
def __init__(self, name, m3u8_url, path):
'''
:param name: 視頻名
:param m3u8_url: 視頻的 m3u8檔案 地址
:param path: 下載地址
'''
self.video_name = name
self.path = path
self.f_url = str(m3u8_url).split('hls/')[0] + 'hls/'
with open(self.path + '/{}.m3u8'.format(self.video_name), 'wb')as f:
f.write(requests.get(m3u8_url, headers={'user-agent': 'Chrome/84.0.4147.135'}).content)
def get_ts_urls(self):
with open(self.path + '/{}.m3u8'.format(self.video_name), "r") as file:
lines = file.readlines()
for line in lines:
if '.ts' in line:
self.urls.append(self.f_url + line.replace('\n', ''))
def start_download(self):
self.get_ts_urls()
for url in tqdm(self.urls, desc="正在下載 {} ".format(self.video_name)):
movie = requests.get(url, headers={'user-agent': 'Chrome/84.0.4147.135'})
with open(self.path + '/{}.flv'.format(self.video_name), 'ab')as f:
f.write(movie.content)
os.remove(self.path + '/{}.m3u8'.format(self.video_name))
url1 = input("輸入地址: ")
m3u8_url(url1).get_m3u8()
效果:


哦豁~ 起飛~~
番劇劇集
獲取視頻的資訊
既然要從番劇入手,那肯定就還是拿一個例子來說明吧:
租借女友 (又是
lsp的呢~~)
針對這部番劇,我們直接從單個視頻決議方式來獲取經驗 -----> 直接從網頁原始碼開始:

果然也在原始碼中找到了與單個視頻類似的 JSON 資料,我們繼續將這些資料進行格式化:
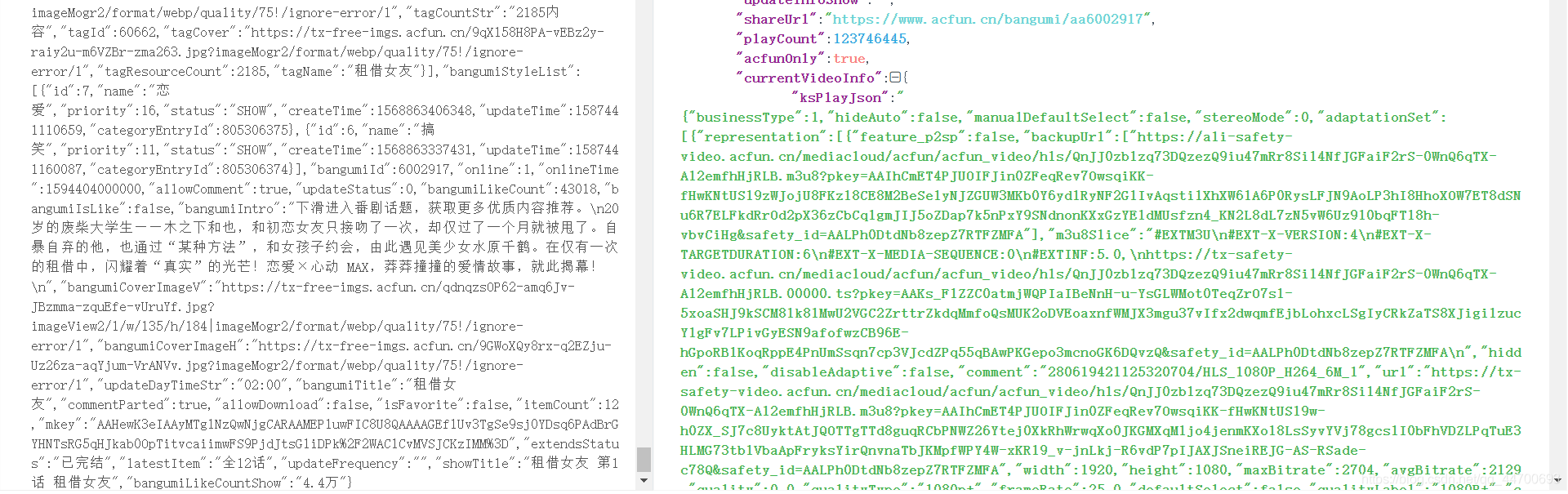
結果視頻的 存放方式 和 存放的欄位 和單個視頻 一摸一樣,為了減少最后的代碼量,我們可以將兩種方式都適配到一個類中:
class m3u8_url():
def __init__(self, f_url, name=""):
'''
:param f_url: 當前視頻的鏈接
:param name: 番劇名,默認為空
'''
self.url = f_url
self.name = name
def get_m3u8(self):
global flag, qua, rel_path
html = requests.get(self.url, headers=headers).text
first_json = json.loads(re.findall('window.pageInfo = window.*? = (.*?)};', html)[0] + '}', strict=False)
if self.name == '':
name = first_json['title'].strip().replace("|",'')
else:
name = self.name
rel_path = path + first_json['bangumiTitle'].strip()
if os.path.exists(rel_path):
pass
else:
os.makedirs(rel_path)
video_info = json.loads(first_json['currentVideoInfo']['ksPlayJson'], strict=False)['adaptationSet'][0]['representation']
Label = {}
num = 0
for quality in video_info: # 清晰度
num += 1
Label[num] = quality['qualityLabel']
if flag:
print(Label)
choice = int(input("請選擇清晰度: "))
flag = False
qua = choice
Download(name + '[{}]'.format(Label[choice]), video_info[choice - 1]['url'], path).start_download()
else:
Download(name + '[{}]'.format(Label[qua]), video_info[qua - 1]['url'], rel_path).start_download()
代碼注解:
- flag :用于判斷是否已經選擇了下載時的清晰度,
- qua : 保存選擇的清晰度,
- rel_path :更改番劇下載的位置(番劇名的檔案夾下),
- first_json = json.loads(re.findall(‘window.pageInfo = window.? = (.?)};’, html)[0] + ‘}’, strict=False) :更改視頻資訊的匹配正則運算式,可以同時用來匹配單個視頻和番劇視頻,
知道了某一集怎么下載,總不可能要每一集都要去手動輸入鏈接吧!!!遇到只有幾集的番劇還好,要是遇到這樣的:
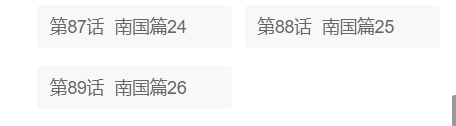
你來???
番劇劇集鏈接
同樣的,我們還是從網頁原始碼出發:
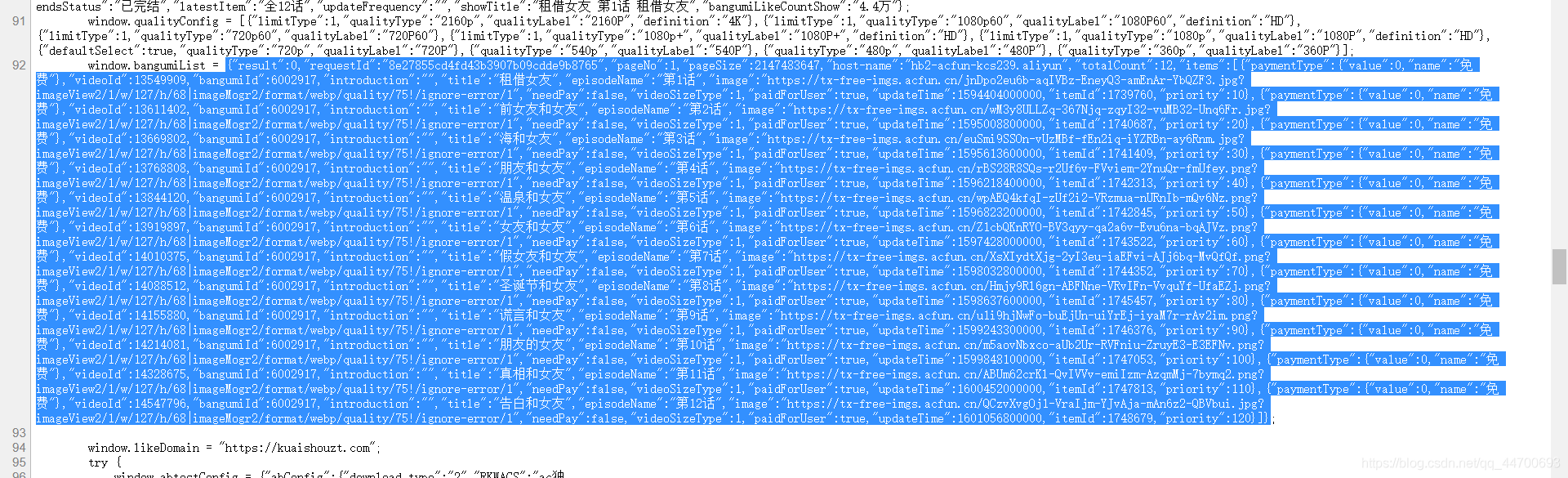
雖然我們能在原始碼中找到番劇的所有資訊,但是,并不是所有的都是我們需要的,我們還要先去看看哪些資訊是我們必須要拿到的:
當我點擊第二集時,瀏覽器地址欄的地址發生了變化:
https://www.acfun.cn/bangumi/aa6002917_36188_1740687
我們很容易的就可以發現:
- https://www.acfun.cn/bangumi/aa6002917 :番劇的主頁鏈接,
- 36188 :一串不知道有什么用的數字,不過我發現它并沒有什么用,都是固定的:
舉幾個例子:
租借女友 :第2話 前女友和女友:https://www.acfun.cn/bangumi/aa6002917_36188_1740687
租借女友 :第3話 海和女友:https://www.acfun.cn/bangumi/aa6002917_36188_1741409
鎮魂街 :第2話:https://www.acfun.cn/bangumi/aa5020166_36188_232386
…
同樣的點回第一集時也可以看到第一集的鏈接也可以寫成:
鎮魂街 :第1話:https://www.acfun.cn/bangumi/aa5020166_36188_232383
租借女友 :第1話 租借女友:https://www.acfun.cn/bangumi/aa6002917_36188_1739760
…
- 1740687 :每一集的 ID ,在原始碼中以 itemId 欄位保存,
于是,我們就可以寫出獲取每一集視頻鏈接的代碼:
class Pan_drama():
def __init__(self, f_url):
'''
:param f_url: 視頻主頁的鏈接
'''
self.aa = len(str(f_url).split('/')[-1])
if self.aa == 7:
self.url = f_url
elif self.aa > 7:
self.url = str(f_url).split('_')[0]
def get_info(self):
video_info = {}
html = requests.get(self.url, headers=headers).text
all_item = json.loads(re.findall('window.bangumiList = (.*?);', html)[0])['items']
for item in tqdm(all_item, desc="正在準備番劇"):
video_info[item['episodeName'] + '-' + item['title']] = self.url + '_36188_' + str(item['itemId'])
for name in video_info.keys():
m3u8_url(video_info[name],name).get_m3u8()
代碼注解:
- self.aa :為了更好的適應性,簡單的解決一下,傳入某一集的鏈接,但是可以下載全番劇的情況,
原始碼及效果
全部原始碼:
import os
import re
import json
import requests
from tqdm import tqdm
path = './'
headers = {
'referer': 'https://www.acfun.cn/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83'
}
flag = True
qua = 0
class m3u8_url():
def __init__(self, f_url, name=""):
'''
:param f_url: 當前視頻的鏈接
:param name: 番劇名,默認為空
'''
self.url = f_url
self.name = name
def get_m3u8(self):
global flag, qua, rel_path
html = requests.get(self.url, headers=headers).text
first_json = json.loads(re.findall('window.pageInfo = window.*? = (.*?)};', html)[0] + '}', strict=False)
if self.name == '':
name = first_json['title'].strip().replace("|", '')
rel_path=path
else:
name = self.name
rel_path = path + first_json['bangumiTitle'].strip()
if os.path.exists(rel_path):
pass
else:
os.makedirs(rel_path)
video_info = json.loads(first_json['currentVideoInfo']['ksPlayJson'], strict=False)['adaptationSet'][0][
'representation']
Label = {}
num = 0
for quality in video_info: # 清晰度
num += 1
Label[num] = quality['qualityLabel']
if flag:
print(Label)
choice = int(input("請選擇清晰度: "))
flag = False
qua = choice
Download(name + '[{}]'.format(Label[choice]), video_info[choice - 1]['url'], rel_path).start_download()
else:
Download(name + '[{}]'.format(Label[qua]), video_info[qua - 1]['url'], rel_path).start_download()
class Pan_drama():
def __init__(self, f_url):
'''
:param f_url: 視頻主頁的鏈接
'''
self.aa = len(str(f_url).split('/')[-1])
if self.aa == 7:
self.url = f_url
elif self.aa > 7:
self.url = str(f_url).split('_')[0]
def get_info(self):
video_info = {}
html = requests.get(self.url, headers=headers).text
all_item = json.loads(re.findall('window.bangumiList = (.*?);', html)[0])['items']
for item in tqdm(all_item, desc="正在準備番劇"):
video_info[item['episodeName'] + '-' + item['title']] = self.url + '_36188_' + str(item['itemId'])
for name in video_info.keys():
m3u8_url(video_info[name],name).get_m3u8()
class Download():
urls = []
def __init__(self, name, m3u8_url, path):
'''
:param name: 視頻名
:param m3u8_url: 視頻的 m3u8檔案 地址
:param path: 下載地址
'''
self.video_name = name
self.path = path
self.f_url = str(m3u8_url).split('hls/')[0] + 'hls/'
with open(self.path + '/{}.m3u8'.format(self.video_name), 'wb')as f:
f.write(requests.get(m3u8_url, headers={'user-agent': 'Chrome/84.0.4147.135'}).content)
def get_ts_urls(self):
with open(self.path + '/{}.m3u8'.format(self.video_name), "r") as file:
lines = file.readlines()
for line in lines:
if '.ts' in line:
self.urls.append(self.f_url + line.replace('\n', ''))
def start_download(self):
self.get_ts_urls()
for url in tqdm(self.urls, desc="正在下載 {} ".format(self.video_name)):
movie = requests.get(url, headers={'user-agent': 'Chrome/84.0.4147.135'})
with open(self.path + '/{}.flv'.format(self.video_name), 'ab')as f:
f.write(movie.content)
os.remove(self.path + '/{}.m3u8'.format(self.video_name))
url1 = input("輸入地址: ")
if url1.split('/')[3] == 'v':
m3u8_url(url1).get_m3u8()
elif url1.split('/')[3] == 'bangumi':
Pan_drama(url1).get_info()
效果示例:
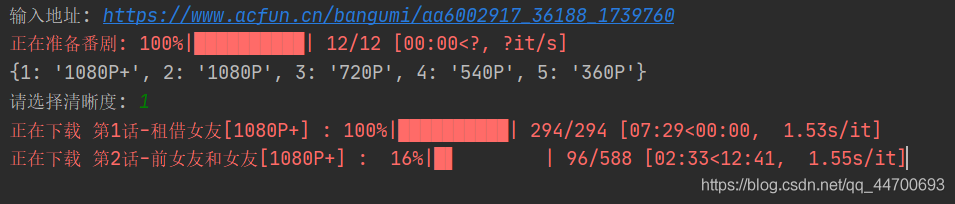
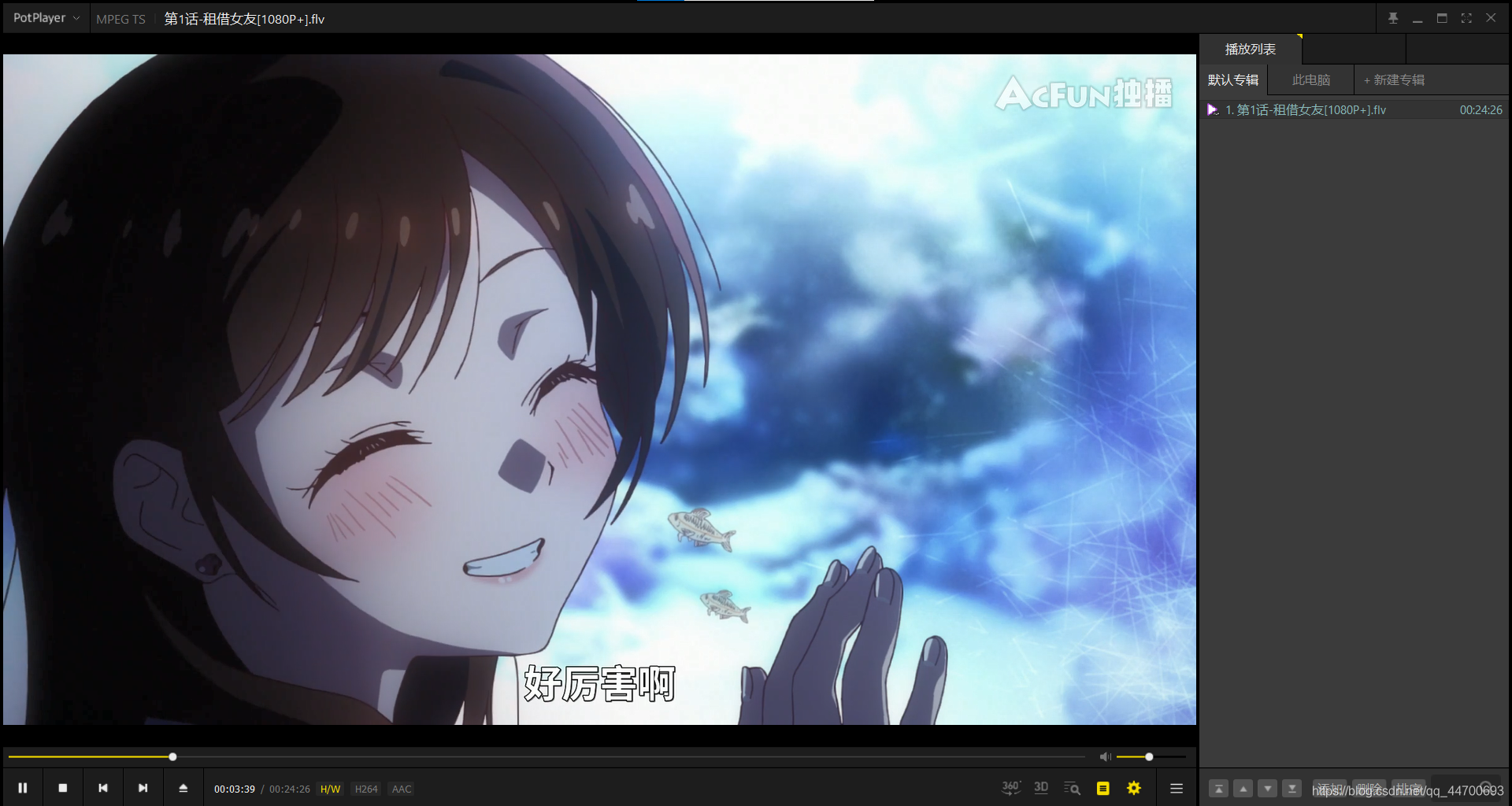
(因為考慮到萬一要被拉黑的問題,那不就 gg 了,所以我沒加入多執行緒,有需要可以直行嘗試嘗試~~~)
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/183278.html
標籤:其他
上一篇:自制爬蟲框架