DQN演算法實戰-小車上山
- 案例分析
- 實驗環境
- 用線性近似求解最優策略
- 用深度Q學習求解最優策略
- 參考
代碼鏈接
案例分析
如圖1所示,一個小車在一段范圍內行駛,在任一時刻,在水平方向看,小車位置的范圍是[-1.2,0.6],速度的范圍是[-0.07,0.07],在每個時刻,智能體可以對小車施加3種動作中的一種:向左施力、不施力、向右施力,智能體施力和小車的水平位置會共同決定小車下一時刻的速度,當某時刻小車的水平位置大于0.5時,控制目標成功達成,回合結束,控制的目標是讓小車以盡可能少的步驟達到目標,一般認為,如果智能體在連續100個回合中的平均步數≤110,就認為問題解決了,
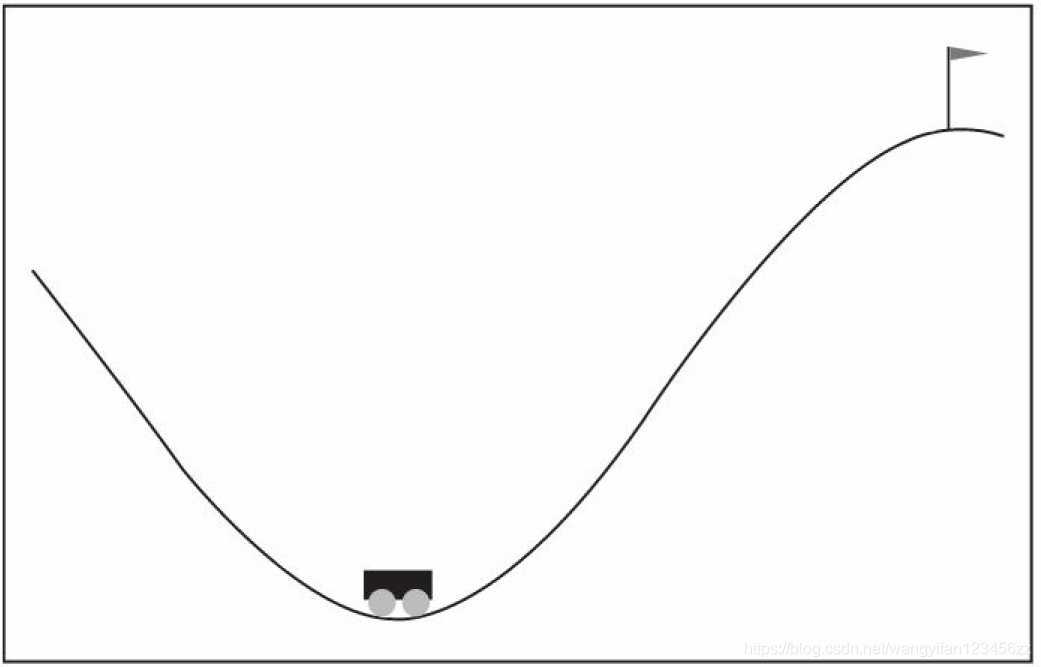
在絕大多數情況下,智能體簡單向右施力并不足以讓小車成功越過目標,假設智能體并不知道環境確定小車位置和速度的數學運算式,事實上,小車的位置和速度是有數學運算式的,記第t時刻(t=0,1,2,…)小車的位置為
X
t
(
X
t
∈
[
?
1.2
,
0.6
]
)
X_t(X_t∈[-1.2,0.6])
Xt?(Xt?∈[?1.2,0.6]),速度為
V
t
(
V
t
∈
[
?
0.07
,
0.07
]
)
V_t(V_t∈[-0.07,0.07])
Vt?(Vt?∈[?0.07,0.07]),智能體施力為
A
t
∈
0
,
1
,
2
A_t∈{0,1,2}
At?∈0,1,2,初始狀態
X
0
∈
[
?
0.6
,
?
0.4
)
,
V
0
=
0
X_0∈[-0.6,-0.4),V_0=0
X0?∈[?0.6,?0.4),V0?=0,從t時刻到
t
+
1
t+1
t+1時刻的更新式為
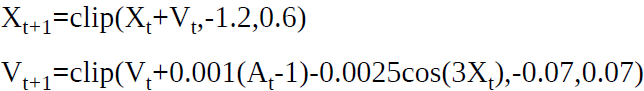
其中限制函式clip()限制了位置和速度的范圍:
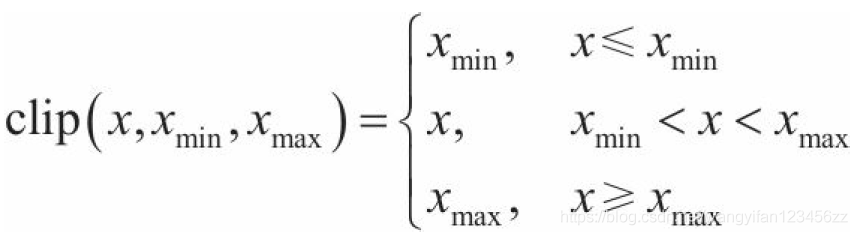
實驗環境
Gym庫內置的環境’MountainCar-v0’已經實作了小車上山環境,在這個環境中,每一步的獎勵都是-1,回合的回報的值就是總步數的負數,匯入這個環境,并查看其狀態空間和動作空間,以及位置和速度的引數,
import numpy as np
np.random.seed(0)
import pandas as pd
import matplotlib.pyplot as plt
import gym
import tensorflow.compat.v2 as tf
tf.random.set_seed(0)
from tensorflow import keras
env = gym.make('MountainCar-v0')
env.seed(0)
print('觀測空間 = {}'.format(env.observation_space))
print('動作空間 = {}'.format(env.action_space))
print('位置范圍 = {}'.format((env.unwrapped.min_position,
env.unwrapped.max_position)))
print('速度范圍 = {}'.format((-env.unwrapped.max_speed,
env.unwrapped.max_speed)))
print('目標位置 = {}'.format(env.unwrapped.goal_position))
使用這個環境,在代碼清單2中的策略總是試圖向右對小車施力,程式運行結果表明,僅僅簡單地向右施力,是不可能讓小車達到目標的,為了避免程式無窮盡地運行下去,這里限制了回合最大的步數為200,
positions, velocities = [], []
observation = env.reset()
while True:
positions.append(observation[0])
velocities.append(observation[1])
next_observation, reward, done, _ = env.step(2)
if done:
break
observation = next_observation
if next_observation[0] > 0.5:
print('成功到達')
else:
print('失敗退出')
# 繪制位置和速度影像
fig, ax = plt.subplots()
ax.plot(positions, label='position')
ax.plot(velocities, label='velocity')
ax.legend()
plt.show()
用線性近似求解最優策略
本節我們將用形如
q
(
s
,
a
)
=
[
x
(
s
,
a
)
]
T
w
q(s,a)=[x(s,a)]^Tw
q(s,a)=[x(s,a)]Tw的線性組合來近似動作價值函式,求解最優策略,
在這個問題中,位置和速度都是連續的變數,要從連續空間中匯出數目有限的特征,最簡單的方法是采用獨熱編碼(one-hot coding),如圖a所示:在二維的“位置–速度”空間中,我們可將其劃分為許多小格,位置軸范圍總長是
l
位
置
l_位置
l位?置,每個小格的寬度是
δ
位
置
δ_位置
δ位?置,那么位置軸有
b
位
置
=
[
l
位
置
÷
δ
速
度
]
b_{位置}=[l_{位置} ÷\delta_{速度}]
b位置?=[l位置?÷δ速度?]個小格;同理,速度范圍總長l速度,每個小格長度
δ
δ
δ速度,
b
速
度
=
[
l
速
度
÷
δ
速
度
]
b_{速度} = [l_{速度}÷\delta_{速度}]
b速度?=[l速度?÷δ速度?]個小格,這樣,整個空間有
b
位
置
b
速
度
b_{位置}b_{速度}
b位置?b速度?個小格,每個小格對應一個特征:當位置速度對位于某個小格時,那個小格對應的特征為1,其他小格對應的特征均為0,這樣,獨熱編碼就從連續的空間中提取出了
b
位
置
b
速
度
b_{位置}b_{速度}
b位置?b速度?個特征,采用獨熱編碼后得到的價值函式,對于同一網格內的所有位置速度對,其價值函式的估計都是相同的,所以這只是一種近似,如果要讓近似更準確,就要讓每個小格的長度
δ
位
置
和
δ
速
度
δ_{位置}和δ_{速度}
δ位置?和δ速度?更小,但是,這樣會增大特征的數目
b
位
置
b
速
度
b_{位置}b_{速度}
b位置?b速度?,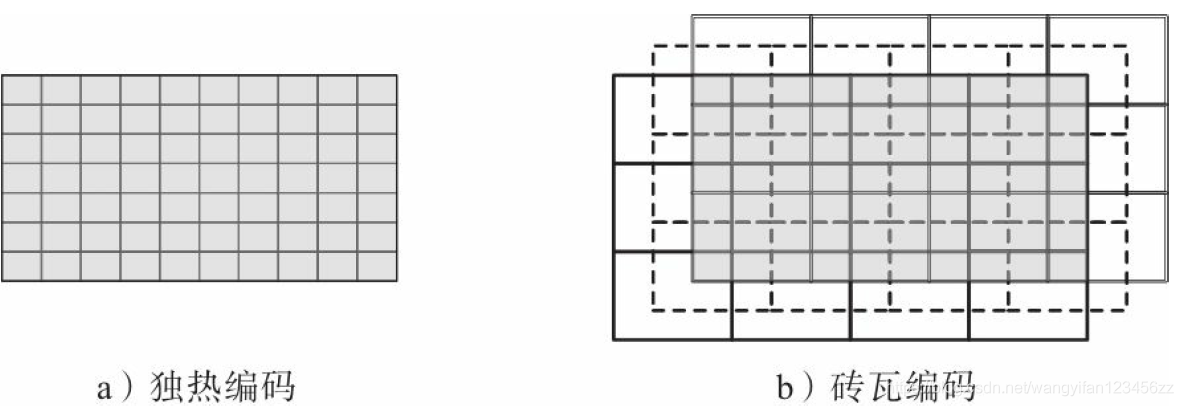
磚瓦編碼(tile coding)可以在精度相同的情況下減少特征數目,如圖b所示,磚瓦編碼引入了多層大網格,本節用的m層磚瓦編碼,每層的大網格都是原來獨熱編碼小格的m位寬、m位長,在相鄰兩層之間,在兩個維度上都偏移一個獨熱編碼的小格,對于任意的位置速度對,它在每一層都會落在某個大網格里,這樣,我們可以讓每層中大網格對應的特征為1,其他特征為0,綜合考慮所有層,總共大致有
b
位
置
b
速
度
/
m
b_{位置}b_{速度}/m
b位置?b速度?/m個特征,特征數大大減小,
TileCoder類實作了磚瓦編碼,構造TileCoder類需要兩個引數:引數layers表示要用幾層磚瓦編碼;引數features表示磚瓦編碼應該得到多少特征,即x(s,a)的維度,它也是w的維度,構造TileCoder類物件后,就可以呼叫這個物件找到每個資料激活了哪些特征,呼叫的引數floats輸入[0,1]間的浮點數的tuple,引數ints輸入int元素的tuple(不參與磚瓦編碼);回傳int型串列,表示激活的引數指標,
class TileCoder:
def __init__(self, layers, features):
self.layers = layers
self.features = features
self.codebook = {}
def get_feature(self, codeword):
if codeword in self.codebook:
return self.codebook[codeword]
count = len(self.codebook)
if count >= self.features: # 沖突處理
return hash(codeword) % self.features
self.codebook[codeword] = count
return count
def __call__(self, floats=(), ints=()):
dim = len(floats)
scaled_floats = tuple(f * self.layers * self.layers for f in floats)
features = []
for layer in range(self.layers):
codeword = (layer,) + tuple(int((f + (1 + dim * i) * layer) /
self.layers) for i, f in enumerate(scaled_floats)) + ints
feature = self.get_feature(codeword)
features.append(feature)
return features
在小車上山任務中,如果我們對觀測空間選取8層的磚瓦編碼,那么觀測空間第0層有8×8=64個磚瓦,剩下8-1=7層有(8+1)×(8+1)=81個磚瓦,一共有64+7×81=631個磚瓦,再考慮到動作有3種可能的取值,那么總共有631×3=1893個特征,接下來,我們運用磚瓦編碼來實作函式近似的智能體,以下是函式近似SARSA演算法的智能體類SARSAAgent和函式近似SARSA(λ)的智能體類SARSALambdaAgent,
class SARSAAgent:
def __init__(self, env, layers=8, features=1893, gamma=1.,
learning_rate=0.03, epsilon=0.001):
self.action_n = env.action_space.n # 動作數
self.obs_low = env.observation_space.low
self.obs_scale = env.observation_space.high - \
env.observation_space.low # 觀測空間范圍
self.encoder = TileCoder(layers, features) # 磚瓦編碼器
self.w = np.zeros(features) # 權重
self.gamma = gamma # 折扣
self.learning_rate = learning_rate # 學習率
self.epsilon = epsilon # 探索
def encode(self, observation, action): # 編碼
states = tuple((observation - self.obs_low) / self.obs_scale)
actions = (action,)
return self.encoder(states, actions)
def get_q(self, observation, action): # 動作價值
features = self.encode(observation, action)
return self.w[features].sum()
def decide(self, observation): # 判決
if np.random.rand() < self.epsilon:
return np.random.randint(self.action_n)
else:
qs = [self.get_q(observation, action) for action in
range(self.action_n)]
return np.argmax(qs)
def learn(self, observation, action, reward,
next_observation, done, next_action): # 學習
u = reward + (1. - done) * self.gamma * \
self.get_q(next_observation, next_action)
td_error = u - self.get_q(observation, action)
features = self.encode(observation, action)
self.w[features] += (self.learning_rate * td_error)
class SARSALambdaAgent(SARSAAgent):
def __init__(self, env, layers=8, features=1893, gamma=1.,
learning_rate=0.03, epsilon=0.001, lambd=0.9):
super().__init__(env=env, layers=layers, features=features,
gamma=gamma, learning_rate=learning_rate, epsilon=epsilon)
self.lambd = lambd
self.z = np.zeros(features) # 初始化資格跡
def learn(self, observation, action, reward, next_observation, done,
next_action):
u = reward
if not done:
u += (self.gamma * self.get_q(next_observation, next_action))
self.z *= (self.gamma * self.lambd)
features = self.encode(observation, action)
self.z[features] = 1. # 替換跡
td_error = u - self.get_q(observation, action)
self.w += (self.learning_rate * td_error * self.z)
if done:
self.z = np.zeros_like(self.z) # 為下一回合初始化資格跡
運用環境物件env和構造好的智能體物件agent,我們就可以用函式play_sarsa()訓練智能體,對于訓練了300個回合的SARSAAgent,平均回合獎勵可以達到-121左右;對于訓練了150個回合的SARSALambdaAgent,平均回合獎勵可以達到-107左右,在這個實作中,SARSA(λ)演算法比SARSA演算法更為高效,事實上,SARSA(λ)演算法是針對小車上山這個任務最有效的方法之一,
用深度Q學習求解最優策略
首先我們來看經驗回放,代碼清單中的類DQNReplayer實作了經驗回放,構造這個類的引數中有個int型的引數capacity,表示存盤空間最多可以存盤幾條經驗,當要存盤的經驗數超過capacity時,會用最新的經驗覆寫最早存入的經驗,
class DQNReplayer:
def __init__(self, capacity):
self.memory = pd.DataFrame(index=range(capacity),
columns=['observation', 'action', 'reward',
'next_observation', 'done'])
self.i = 0
self.count = 0
self.capacity = capacity
def store(self, *args):
self.memory.loc[self.i] = args
self.i = (self.i + 1) % self.capacity
self.count = min(self.count + 1, self.capacity)
def sample(self, size):
indices = np.random.choice(self.count, size=size)
return (np.stack(self.memory.loc[indices, field]) for field in
self.memory.columns)
接下來我們來看函式近似部分,函式近似采用了矢量形式的近似函式 q ( s ; w ) , s ∈ ( S ) q(s;w),s∈(\mathcal{S}) q(s;w),s∈(S),近似函式的形式為全連接神經網路,以下分別實作了帶目標網路的深度Q學習智能體和雙重Q學習智能體,它們和play_qlearning()函式結合,就實作了帶目標網路的深度Q學習演算法和雙重Q學習演算法,
class DQNAgent:
def __init__(self, env, net_kwargs={}, gamma=0.99, epsilon=0.001,
replayer_capacity=10000, batch_size=64):
observation_dim = env.observation_space.shape[0]
self.action_n = env.action_space.n
self.gamma = gamma
self.epsilon = epsilon
self.batch_size = batch_size
self.replayer = DQNReplayer(replayer_capacity) # 經驗回放
self.evaluate_net = self.build_network(input_size=observation_dim,
output_size=self.action_n, **net_kwargs) # 評估網路
self.target_net = self.build_network(input_size=observation_dim,
output_size=self.action_n, **net_kwargs) # 目標網路
self.target_net.set_weights(self.evaluate_net.get_weights())
def build_network(self, input_size, hidden_sizes, output_size,
activation=tf.nn.relu, output_activation=None,
learning_rate=0.01): # 構建網路
model = keras.Sequential()
for layer, hidden_size in enumerate(hidden_sizes):
kwargs = dict(input_shape=(input_size,)) if not layer else {}
model.add(keras.layers.Dense(units=hidden_size,
activation=activation, **kwargs))
model.add(keras.layers.Dense(units=output_size,
activation=output_activation)) # 輸出層
optimizer = tf.optimizers.Adam(lr=learning_rate)
model.compile(loss='mse', optimizer=optimizer)
return model
def learn(self, observation, action, reward, next_observation, done):
self.replayer.store(observation, action, reward, next_observation,
done) # 存盤經驗
observations, actions, rewards, next_observations, dones = \
self.replayer.sample(self.batch_size) # 經驗回放
next_qs = self.target_net.predict(next_observations)
next_max_qs = next_qs.max(axis=-1)
us = rewards + self.gamma * (1. - dones) * next_max_qs
targets = self.evaluate_net.predict(observations)
targets[np.arange(us.shape[0]), actions] = us
self.evaluate_net.fit(observations, targets, verbose=0)
if done: # 更新目標網路
self.target_net.set_weights(self.evaluate_net.get_weights())
def decide(self, observation): # epsilon貪心策略
if np.random.rand() < self.epsilon:
return np.random.randint(self.action_n)
qs = self.evaluate_net.predict(observation[np.newaxis])
return np.argmax(qs)
def play_qlearning(env, agent, train=False, render=False):
episode_reward = 0
observation = env.reset()
while True:
if render:
env.render()
action = agent.decide(observation)
next_observation, reward, done, _ = env.step(action)
episode_reward += reward
if train:
agent.learn(observation, action, reward, next_observation,
done)
if done:
break
observation = next_observation
return episode_reward
class DoubleDQNAgent(DQNAgent):
def learn(self, observation, action, reward, next_observation, done):
self.replayer.store(observation, action, reward, next_observation,
done) # 存盤經驗
observations, actions, rewards, next_observations, dones = \
self.replayer.sample(self.batch_size) # 經驗回放
next_eval_qs = self.evaluate_net.predict(next_observations)
next_actions = next_eval_qs.argmax(axis=-1)
next_qs = self.target_net.predict(next_observations)
next_max_qs = next_qs[np.arange(next_qs.shape[0]), next_actions]
us = rewards + self.gamma * next_max_qs * (1. - dones)
targets = self.evaluate_net.predict(observations)
targets[np.arange(us.shape[0]), actions] = us
self.evaluate_net.fit(observations, targets, verbose=0)
if done:
self.target_net.set_weights(self.evaluate_net.get_weights())
代碼使用TensorFlow來實作,并同時兼容TensorFlow 1.X的最新穩定版本和TensorFlow 2.X的最新穩定版本,對于基于TensorFlow的程式,即使已經設定了亂數的種子,也不能保證完全復現,所以,運行結果有差異是正常現象,
參考
原理的介紹可以參考我之前的文章
函式近似方法與原理
線性近似與函式近似的收斂性
DQN演算法原理
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/192977.html
標籤:其他