文章目錄
- 寫在前面
- 一、爬取原界面
- 1.網站連接
- 2.爬取內容
- 二、編程思路
- 1.功能描述
- 2.程式的結構設計
- 三、撰寫函式
- 1.函式getHTMLText()
- 2.函式fillUnivList()
- 3.函式printUnivList()
- 四、完整代碼
- 參考源自
寫在前面
??這個例子是筆者今天在中國大學MOOC(嵩天 北京理工大學)上學習的時候寫下來的,但是很快寫完之后我就發現不對勁,首先課程給的例子是中國好大學網站的排名,但是現在這個網站已經重構了,原來的鏈接進去是軟科的大學排名,所以之前的代碼就需要做一些修改,在我不懈的努力下(各種瞎折騰,走了很多彎路),現在基本成功了,寫這篇博客記錄一下,
一、爬取原界面
1.網站連接
鏈接:https://www.shanghairanking.cn/rankings/bcur/2020.
2.爬取內容
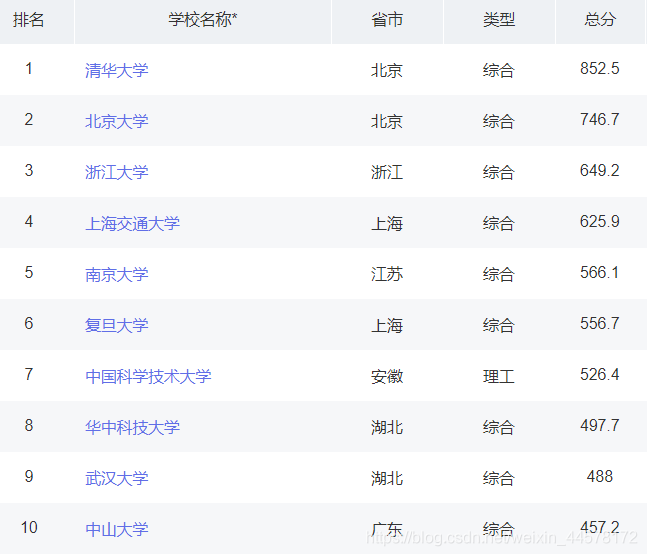
??本例爬取的是下圖的排名、大學名稱、總分三個內容,
二、編程思路
??這一部分嵩天老師在課中給出了講解,這里我整理分享給大家,
1.功能描述
輸入:大學排名URL鏈接
輸出:大學排名資訊的螢屏輸出(排名,大學名稱,總分)
技術路線:requests-–bs4
定向爬蟲:僅對輸入URL進行爬取,不擴展爬取
注:requestts和bs4庫的使用只能獲取靜態頁面的資訊,如何獲取動態頁面資訊,我會在后邊專門寫篇文章詳細說明
2.程式的結構設計
步驟一:從網路上獲取大學排名網頁內容:定義函式getHTMLText()
步驟二:提取網頁內容中資訊到合適的資料結構:定義函式fillUnivList()
步驟三:利用資料結構展示并輸出結果:定義函式printUnivList()
三、撰寫函式
??在撰寫函式前,首先我們要先看一下網頁的源代碼

??通過對網頁源代碼的觀察,我們可以看到,所有大學資訊被封裝在一個表格中,這個表格的標簽叫tbody,在tbody中,每個大學的資訊被封裝在一個標簽中,這個標簽叫tr,每個tr標簽里又有一個td標簽,每個大學的具體資訊就被這個標簽包圍,但是大學的名字是被包在a標簽中的,這里要做處理,
??所以我們首先遍歷tbody標簽,獲得所有大學資訊,然后在tbody標簽中找到tr標簽,獲得每個大學資訊,最后在tr標簽里找到td標簽,把我們需要的相關資料寫在我們的ulist串列中,
注:
??1.由于大學名稱被a標簽包含,所以我們可以定義一個串列存放a標簽內容(與td標簽區別開),
??2.為了視覺方面更加美觀,可采用中文字符的空格填充 chr(12288),其實就是為了對齊,
1.函式getHTMLText()
??從網路上獲取大學排名網頁內容,
def getHTMLText(url):#獲取URL資訊,輸出內容
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return""
2.函式fillUnivList()
??提取網頁內容中資訊到合適的資料結構.
def fillUnivList(ulist,html):#將html頁面放到ulist串列中(核心)
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):#如果tr標簽的型別不是bs4庫中定義的tag型別,則過濾掉
a = tr('a')#將所有的a標簽存為一個串列型別
tds = tr('td')#將所有的td標簽存為一個串列型別
ulist.append([tds[0].string.strip(),a[0].string.strip(),tds[4].string.strip()])
注:這里要注意的是,要注意使用strip()函式,它的作用是用于移除字串頭尾指定的字符(默認為空格或換行符)或字符序列,但該方法只能洗掉開頭或是結尾的字符,不能洗掉中間部分的字符,用在此處可以使爬取的內容,在格式化輸出時達到對齊的效果,
3.函式printUnivList()
??利用資料結構展示并輸出結果:定義函式,
def printUnivList(ulist1,num):#列印出ulist串列的資訊,num表示希望將串列中的多少個元素列印出來
#格式化輸出
tplt = "{0:^10}\t{1:{3}^12}\t{2:^10}"
# 0、1、2為槽,{3}表示若寬度不夠,使用format的3號位置處的chr(12288)(中文空格)進行填充
print(tplt.format("排名","學校名稱","總分",chr(12288)))
for i in range(num):
u = ulist1[i]
print(tplt.format(u[0], u[1], u[2],chr(12288)))
print()
print("共有記錄"+str(num)+"條")
四、完整代碼
'''
功能描述:
輸入:大學排名URL
輸出:大學排名資訊的螢屏輸出(排名,大學名稱,總分)
技術路線:requests—bs4(只能獲取靜態頁面資訊)
定向爬蟲:僅對輸入URL進行爬取,不擴展爬取
程式的結構設計:
1.從網路上獲取大學排名網頁內容:定義函式getHTMLText()
2.提取網頁內容中資訊到合適的資料結構:定義函式fillUnivList()
3.利用資料結構展示并輸出結果:定義函式printUnivList()
'''
import requests
from bs4 import BeautifulSoup
import bs4
ulist1=[]
def getHTMLText(url):#獲取URL資訊,輸出內容
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return""
def fillUnivList(ulist,html):#將html頁面放到ulist串列中(核心)
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):#如果tr標簽的型別不是bs4庫中定義的tag型別,則過濾掉
a = tr('a')
tds = tr('td')#將所有的td標簽存為一個串列型別
ulist.append([tds[0].string.strip(),a[0].string.strip(),tds[4].string.strip()])
def printUnivList(ulist1,num):#列印出ulist串列的資訊,num表示希望將串列中的多少個元素列印出來
#格式化輸出
tplt = "{0:^10}\t{1:{3}^12}\t{2:^10}"
# 0、1、2為槽,{3}表示若寬度不夠,使用format的3號位置處的chr(12288)(中文空格)進行填充
print(tplt.format("排名","學校名稱","總分",chr(12288)))
for i in range(num):
u = ulist1[i]
print(tplt.format(u[0], u[1], u[2],chr(12288)))
print()
print("共有記錄"+str(num)+"條")
def main():
uinfo = [] #將大學資訊放到串列中
url = "https://www.shanghairanking.cn/rankings/bcur/2020"
html = getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,10)
main()
輸出效果如下圖:

??本篇完,如有錯誤歡迎指出~
參考源自
中國大學MOOC Python網路爬蟲與資訊提取
https://www.icourse163.org/course/BIT-1001870001
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/195773.html
標籤:其他