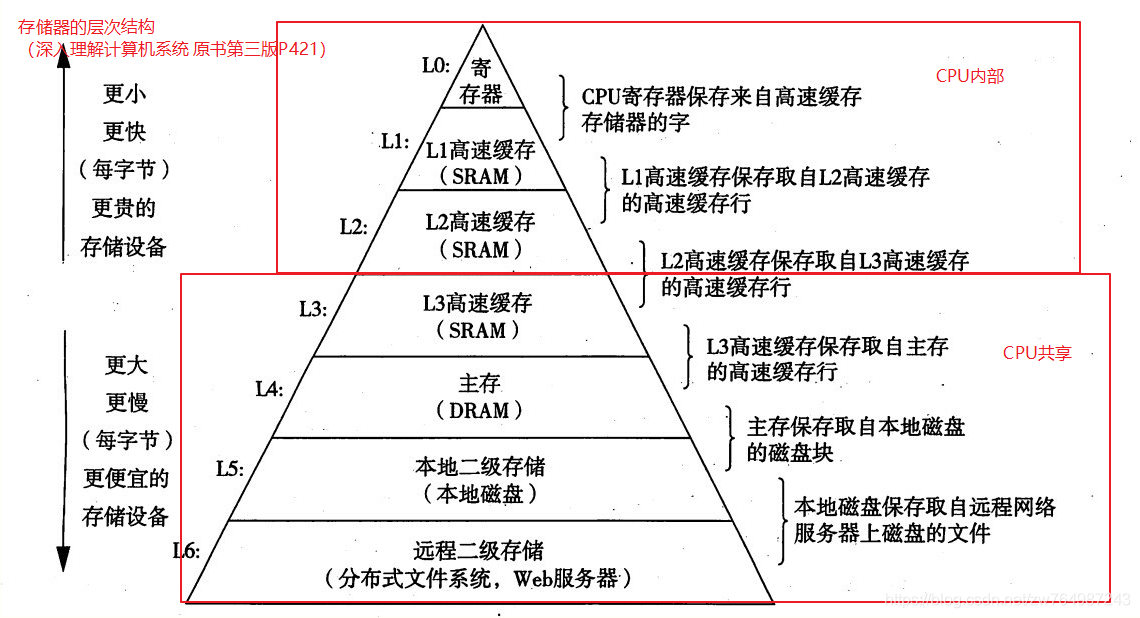
1、存盤器的層次結構
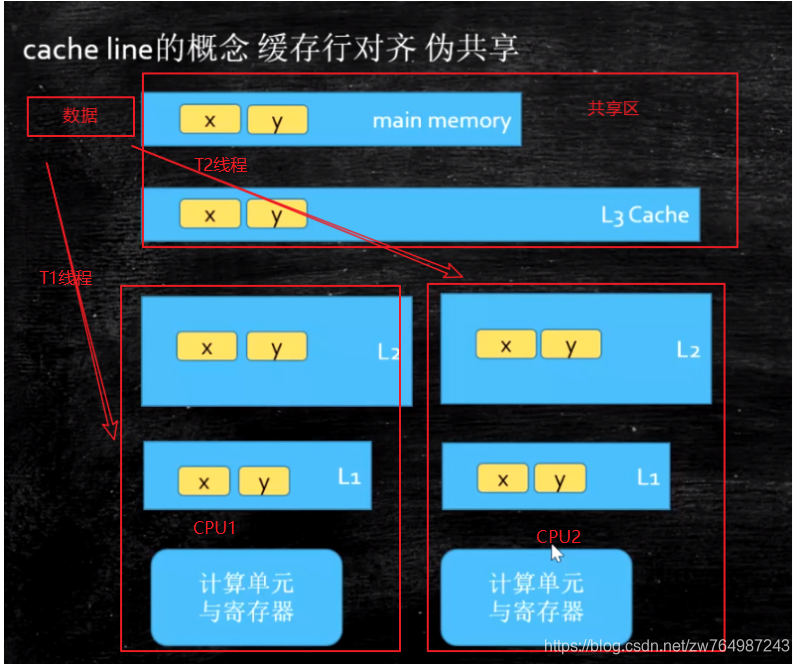
2、cache line 快取行
由于共享變數在CPU快取中的存盤是以快取行為基本單位,一個快取行可以存盤多個變數(存滿當前快取行的位元組數);而CPU對快取的修改又是以快取行為最小單位的,那么就會出現上訴的偽共享問題,
Cache Line可以簡單的理解為CPU Cache中的最小快取單位,今天的CPU不再是按位元組訪問記憶體,而是以64位元組為單位的塊(chunk)拿取,稱為一個快取行(cache line),當你讀一個特定的記憶體地址,整個快取行將從主存換入快取,并且訪問同一個快取行內的其它值的開銷是很小的,
3、為什么會出現偽共享的問題呢?
如下圖:在T1,T2等多執行緒的情況下,假如想,X,Y兩個共享變數在同一個快取行中,CPU1修改變數X,會導致CPU2中的X和Y變數同事失效,此時對于在CPU1上運行的執行緒,僅僅只是修改了變數X,卻導致同一個快取行中的所有變數都無效,需要重新重繪快取(并不一定代表每次都要從記憶體中重新載入,也有可能是從其他Cache中匯入資料,具體的實作要看各個芯片廠商的實作了),假設此時在CPU2上運行的執行緒,正好想要修改變數Y,那么就會出現相互競爭,相互失效的情況,這就是偽共享,
4、怎么解決偽共享?
- 使用快取行的對齊能夠提高效率
- 現在cpu的資料一致性實作是通過快取所(MESI)+總線鎖(資料量非常大無法被快取的資料或者跨越多個快取行的資料就得使用快取鎖)結合設計的,
代碼驗證:
T01_CacheLinePadding 演示在同一快取行里需要的時間,回應時間:280左右
public class T01_CacheLinePadding {
private static class T {
public volatile long x = 0L;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(()->{
for (long i = 0; i < 1000_0000L; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(()->{
for (long i = 0; i < 1000_0000L; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start)/100_0000);
}
}我們把兩個物件分開在不同的快取行,默認初始化為56個位元組大小的資料,回應時間:120左右
public class T02_CacheLinePadding {
private static class Padding {
public volatile long p1, p2, p3, p4, p5, p6, p7;
}
private static class T extends Padding {
public volatile long x = 0L;
}
public static T[] arr = new T[2];
static {
arr[0] = new T();
arr[1] = new T();
}
public static void main(String[] args) throws Exception {
Thread t1 = new Thread(()->{
for (long i = 0; i < 1000_0000L; i++) {
arr[0].x = i;
}
});
Thread t2 = new Thread(()->{
for (long i = 0; i < 1000_0000L; i++) {
arr[1].x = i;
}
});
final long start = System.nanoTime();
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println((System.nanoTime() - start)/100_0000);
}
}測驗結果很明顯T02_CacheLinePadding 的運行時間比T01_CacheLinePadding少很多,雖然多占了記憶體但是它的效率提升了,
5、硬體層資料一致性 MESI(快取鎖)
MESI(Modified Exclusive Shared Or Invalid)(也稱為伊利諾斯協議,是因為該協議由伊利諾斯州立大學提出)是一種廣泛使用的支持寫回策略的快取一致性協議,
1、MESI協議中的狀態
CPU中每個快取行(caceh line)使用4種狀態進行標記(使用額外的兩位(bit)表示):
Modified: 被修改
該快取行只被快取在該CPU的快取中,并且是被修改過的(dirty),即與主存中的資料不一致,該快取行中的記憶體需要在未來的某個時間點(允許其它CPU讀取請主存中相應記憶體之前)寫回(write back)主存,
當被寫回主存之后,該快取行的狀態會變成獨享(exclusive)狀態,
Exclusive: 獨享的
該快取行只被快取在該CPU的快取中,它是未被修改過的(clean),與主存中資料一致,該狀態可以在任何時刻當有其它CPU讀取該記憶體時變成共享狀態(shared),
同樣地,當CPU修改該快取行中內容時,該狀態可以變成Modified狀態,
Shared: 共享的
該狀態意味著該快取行可能被多個CPU快取,并且各個快取中的資料與主存資料一致(clean),當有一個CPU修改該快取行中,其它CPU中該快取行可以被作廢(變成無效狀態(Invalid)),
Invalid: 無效的
該快取是無效的(可能有其它CPU修改了該快取行),再去記憶體里面讀一遍
6、CPU亂序問題
如果一個cpu在執行的時候需要訪問的記憶體都不在cache中,cpu必須要通過記憶體總線到主存中取,那么在資料回傳到cpu這段時間內(這段時間大致為cpu執行成百上千條指令的時間,至少兩個資料量級)干什么呢?
答案是:cpu會繼續執行其他的符合條件的指令,比如cpu有一個指令序列 指令1 指令2 指令3 …, 在指令1時需要訪問主存,在資料回傳前cpu會繼續后續的和指令1在邏輯關系上沒有依賴的”獨立指令”,cpu一般是依賴指令間的記憶體參考關系來判斷的指令間的”獨立關系”,具體細節可參見各cpu的檔案,這也是導致cpu亂序執行指令的根源之一,
CPU為了提高指令執行效率,會在一條指令執行程序中(比如去記憶體讀資料(慢100倍)),去同時執行另一條指令,前提是,兩條指令沒有依賴關系
對于寫資料則會顯得更加復雜一點:
當cpu執行存盤指令時,它會首先試圖將資料寫到離cpu最近的L1_cache, 如果此時cpu出現L1未命中,則會訪問下一級快取,速度上L1_cache基本能和cpu持平,其他的均明顯低于cpu,L2_cache的速度大約比cpu慢20-30倍,而且還存在L2_cache不命中的情況,又需要更多的周期去主存讀取,其實在L1_cache未命中以后,cpu就會使用一個另外的緩沖區,叫做合并寫存盤緩沖區(WCBuffer,速度比L1_cache更快,所以應該看起來是很貴的,一般只有4個位置),這一技術稱為合并寫入技術,在請求L2_cache快取行的所有權尚未完成時,cpu會把待寫入的資料寫入到合并寫存盤緩沖區,該緩沖區大小和一個cache line大小,一般都是64位元組,這個緩沖區允許cpu在寫入或者讀取該緩沖區資料的同時繼續執行其他指令,這就緩解了cpu寫資料時cache miss時的性能影響,
當后續的寫操作需要修改相同的快取行時,這些緩沖區變得非常有趣,在將后續的寫操作提交到L2快取之前,可以進行緩沖區寫合并, 這些64位元組的緩沖區維護了一個64位的欄位,每更新一個位元組就會設定對應的位,來表示將緩沖區交換到外部快取時哪些資料是有效的,當然,如果程式讀取已被寫入到該緩沖區的某些資料,那么在讀取快取資料之前會先去讀取本緩沖區的,
經過上述步驟后,緩沖區的資料還是會在某個延時的時刻更新到外部的快取(L2_cache).如果我們能在緩沖區傳輸到快取之前將其盡可能填滿,這樣的效果就會提高各級傳輸總線的效率,以提高程式性能,
合并寫代碼驗證:
/**
* WCBuffer只有4個位置
*/
public final class WriteCombining {
private static final int ITERATIONS = Integer.MAX_VALUE;
private static final int ITEMS = 1 << 24;
private static final int MASK = ITEMS - 1;
private static final byte[] arrayA = new byte[ITEMS];
private static final byte[] arrayB = new byte[ITEMS];
private static final byte[] arrayC = new byte[ITEMS];
private static final byte[] arrayD = new byte[ITEMS];
private static final byte[] arrayE = new byte[ITEMS];
private static final byte[] arrayF = new byte[ITEMS];
public static void main(final String[] args) {
for (int i = 1; i <= 3; i++) {
System.out.println(i + " SingleLoop duration (ns) = " + runCaseOne());
System.out.println(i + " SplitLoop duration (ns) = " + runCaseTwo());
}
}
public static long runCaseOne() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
byte b = (byte) i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
public static long runCaseTwo() {
long start = System.nanoTime();
int i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
// 這里的b占了一個位置
byte b = (byte) i;
arrayA[slot] = b;
arrayB[slot] = b;
arrayC[slot] = b;
}
i = ITERATIONS;
while (--i != 0) {
int slot = i & MASK;
// 這里的b占了一個位置
byte b = (byte) i;
arrayD[slot] = b;
arrayE[slot] = b;
arrayF[slot] = b;
}
return System.nanoTime() - start;
}
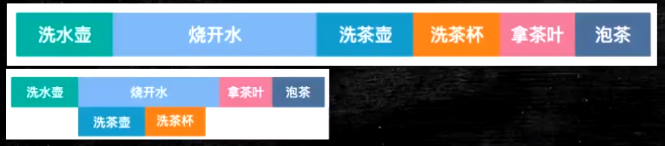
}結果顯示:分開的情況效率更快,(因為充分了利用了合并寫的技術)
6個的為什么會慢呢?
因為WCBuffer是4個位置,6=4+2,4個可以通過WCBuffer讀取一次,但是還有2個必須要等后面來2個補充才能讀取一次,這里也會浪費效率,
亂序執行的證明:
要執行蠻久才可能出現結果:
public class T04_Disorder {
private static int x = 0, y = 0;
private static int a = 0, b =0;
public static void main(String[] args) throws InterruptedException {
int i = 0;
for(;;) {
i++;
x = 0; y = 0;
a = 0; b = 0;
Thread one = new Thread(new Runnable() {
public void run() {
//由于執行緒one先啟動,下面這句話讓它等一等執行緒two. 讀著可根據自己電腦的實際性能適當調整等待時間.
//shortWait(100000);
a = 1;
x = b;
}
});
Thread other = new Thread(new Runnable() {
public void run() {
b = 1;
y = a;
}
});
one.start();other.start();
one.join();other.join();
String result = "第" + i + "次 (" + x + "," + y + ")";
if(x == 0 && y == 0) {
System.err.println(result);
break;
} else {
//System.out.println(result);
}
}
}
public static void shortWait(long interval){
long start = System.nanoTime();
long end;
do{
end = System.nanoTime();
}while(start + interval >= end);
}
}如何保證特定情況下不亂序?
1、硬體記憶體屏障(X86上)
- sfence: store| 在sfence指令前的寫操作當必須在sfence指令后的寫操作前完成,
- lfence:load | 在lfence指令前的讀操作當必須在lfence指令后的讀操作前完成,
- mfence:modify/mix | 在mfence指令前的讀寫操作當必須在mfence指令后的讀寫操作前完成,
- 原子指令,如x86上的”lock …” 指令是一個Full Barrier,執行時會鎖住記憶體子系統來確保執行順序,甚至跨多個CPU,Software Locks通常使用了記憶體屏障或原子指令來實作變、量可見性和保持程式順序
2、JVM級別如何規范(JSR133)
(這是虛的東西,硬體記憶體屏障才是實在的,JVM只是定了規范,實作看虛擬機或者CPU具體的實作)
- LoadLoad屏障:
- 對于這樣的陳述句Load1; LoadLoad; Load2,
- 在Load2及后續讀取操作要讀取的資料被訪問前,保證Load1要讀取的資料被讀取完畢,
- StoreStore屏障:
- 對于這樣的陳述句Store1; StoreStore; Store2,
- 在Store2及后續寫入操作執行前,保證Store1的寫入操作對其它處理器可見,
- LoadStore屏障:
- 對于這樣的陳述句Load1; LoadStore; Store2,
- 在Store2及后續寫入操作被刷出前,保證Load1要讀取的資料被讀取完畢,
- StoreLoad屏障:
- 對于這樣的陳述句Store1; StoreLoad; Load2,
- 在Load2及后續所有讀取操作執行前,保證Store1的寫入對所有處理器可見,
volatile的實作細節
很多文章講解volatile都比較凌亂,我這里從位元組碼、JVM、硬體層面上去分析一下,
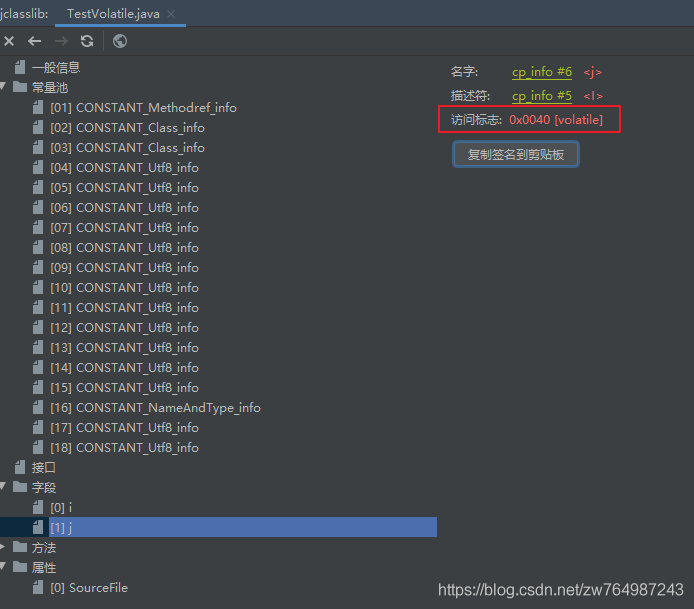
1、位元組碼層面
(去看編譯過后的位元組碼檔案)只是加了個 ACC_VOLATILE
public class TestVolatile {
int i;
volatile int j;
}
位元組碼:
2、JVM層面
volatile記憶體區的讀寫 都加屏障
指令見上面 “JVM級別如何規范”
StoreStoreBarrier
volatile 寫操作
StoreLoadBarrier
LoadLoadBarrier
volatile 讀操作
LoadStoreBarrier
3、OS和硬體層面
這個要工具
想詳細了解可以看一下這篇文章:https://blog.csdn.net/qq_26222859/article/details/52235930
使用hsdis觀察匯編碼
lock指令 執行指令的時候保證對記憶體區域的枷鎖
hsdis - HotSpot Dis Assembler
在windows上 就是使用 lock 指令實作 | MESI實作
synchrnized實作細節
1、位元組碼層面
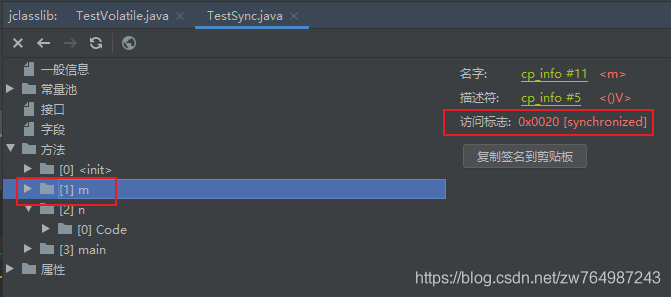
方法:ACC_SYSCHRONIZED
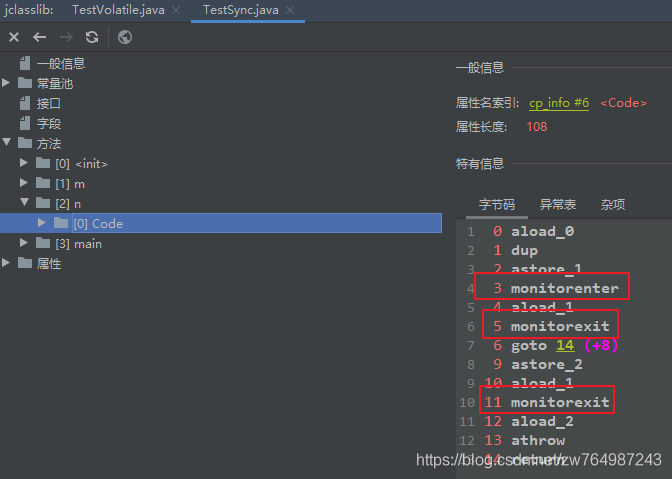
同步陳述句塊:monitorenter/monitorexit,
public class TestSync {
synchronized void m() {
}
void n() {
synchronized (this) {
}
}
public static void main(String[] args) {
}
}monitorenter:進入
第一個monitorexit:退出
第二個monitorexit:發現例外會自動退出
2、JVM層面
C/C++呼叫了作業系統提供的同步機制,
3、OS和硬體層面
X86:lock一個指令 各種各樣的指令cmpxchg / xxx(lock是鎖定,后面的是修改的意思)
詳情:https://blog.csdn.net/21aspnet/article/details/88571740
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/204620.html
標籤:其他