目錄
前言
MyBatis系列面試寶典
1.MyBatis是什么?
2.Mybatis優缺點:
3.MyBatis和Hibernate的適用場景?
4.MyBatis的功能架構是怎樣的
5.Mybatis如何執行批量操作
JVM系列面試寶典
1.詳解JVM記憶體模型
2.說說記憶體屏障
3.happen-before原則
4.怎么打破雙親委派模型?
5.強參考、軟參考、弱參考、虛參考的區別?
Zookeeper系列面試寶典
1.Zookeeper 的 java 客戶端都有哪些?
2.說幾個 zookeeper 常用的命令,
3.Zookeeper 的典型應用場景
4.負載均衡
5.集群支持動態添加機器嗎?
6.Zookeeper 下 Server 作業狀態
前言
來自螞蟻金服內部面試寶典意外流出!

面試寶典內容(JVM+Mybatis+Zookeeper),附答案+決議
MyBatis系列面試寶典

1.MyBatis是什么?
- Mybatis 是一個半 ORM(物件關系映射)框架,它內部封裝了 JDBC,開發時只需要關注 SQL 陳述句本身,不需要花費精力去處理加載驅動、創建連接、創建statement 等繁雜的程序,程式員直接撰寫原生態 sql,可以嚴格控制 sql 執行性能,靈活度高,
- MyBatis 可以使用 XML 或注解來配置和映射原生資訊,將 POJO 映射成資料庫中的記錄,避免了幾乎所有的 JDBC 代碼和手動設定引數以及獲取結果集,
2.Mybatis優缺點:
優點
- 與傳統的資料庫訪問技術相比,ORM有以下優點:基于SQL陳述句編程,相當靈活,不會對應用程式或者資料庫的現有設計造成任何影響,SQL寫在XML里,解除sql與程式代碼的耦合,便于統一管理;提供XML標簽,支持撰寫動態SQL陳述句,并可重用,
- 與JDBC相比,減少了50%以上的代碼量,消除了JDBC大量冗余的代碼,不需要手動開關連接,
- 很好的與各種資料庫兼容(因為MyBatis使用JDBC來連接資料庫,所以只要JDBC支持的資料庫MyBatis都支持),
- 提供映射標簽,支持物件與資料庫的ORM欄位關系映射;提供物件關系映射標簽,支持物件關系組件維護,
- 能夠與Spring很好的集成
缺點
SQL陳述句的撰寫作業量較大,尤其當欄位多、關聯表多時,對開發人員撰寫SQL陳述句的功底有一定要求,

3.MyBatis和Hibernate的適用場景?
- MyBatis專注于SQL本身,是一個足夠靈活的DAO層解決方案,
- 對性能的要求很高,或者需求變化較多的專案,如互聯網專案,MyBatis將是不錯的選擇,
開發難易程度和學習成本
- Hibernate 是重量級框架,學習使用門檻高,適合于需求相對穩定,中小型的專案,比如:辦公自動化系統
- MyBatis 是輕量級框架,學習使用門檻低,適合于需求變化頻繁,大型的專案,比如:互聯網電子商務系統
總結
- MyBatis 是一個小巧、方便、高效、簡單、直接、半自動化的持久層框架,
- Hibernate 是一個強大、方便、高效、復雜、間接、全自動化的持久層框架
4.MyBatis的功能架構是怎樣的
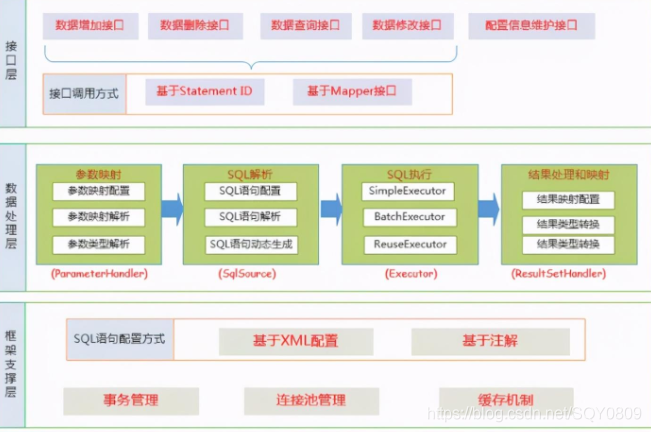
- 我們把Mybatis的功能架構分為三層:
- API介面層:提供給外部使用的介面API,開發人員通過這些本地API來操縱資料庫,介面層一接收到呼叫請求就會呼叫資料處理層來完成具體的資料處理,
- 資料處理層:負責具體的SQL查找、SQL決議、SQL執行和執行結果映射處理等,它主要的目的是根據呼叫的請求完成一次資料庫操作,
- 基礎支撐層:負責最基礎的功能支撐,包括連接管理、事務管理、配置加載和快取處理,這些都是共用的東西,將他們抽取出來作為最基礎的組件,為上層的資料處理層提供最基礎的支撐
5.Mybatis如何執行批量操作
- 使用foreach標簽
- foreach的主要用在構建in條件中,它可以在SQL陳述句中進行迭代一個集合,foreach標簽的屬性主要有item,index,collection,open,separator,close,
- item?? 表示集合中每一個元素進行迭代時的別名,隨便起的變數名;
- index?? 指定一個名字,用于表示在迭代程序中,每次迭代到的位置,不常用;
- open?? 表示該陳述句以什么開始,常用“(”;
- separator 表示在每次進行迭代之間以什么符號作為分隔符,常用“,”;
- close?? 表示以什么結束,常用“)”,
- 在使用foreach的時候最關鍵的也是最容易出錯的就是collection屬性,該屬性是必須指定的,但是在不同情況下,該屬性的值是不一樣的,主要有一下3種情況:
1. 如果傳入的是單引數且引數型別是一個List的時候,collection屬性值為list
2. 如果傳入的是單引數且引數型別是一個array陣列的時候,collection的屬性值為array
3. 如果傳入的引數是多個的時候,我們就需要把它們封裝成一個Map了,當然單引數也可以封
裝成map,實際上如果你在傳入引數的時候,在MyBatis里面也是會把它封裝成一個Map的,map的key就是引數名,所以這個時候collection屬性值就是傳入的List或array物件在自己封裝的map里面的key.
具體用法如下:
</select><!-- 批量保存(foreach插入多條資料兩種方法)
int addEmpsBatch(@Param("emps") List<Employee> emps); -->
<!-- MySQL下批量保存,可以foreach遍歷 mysql支持values(),(),()語法 --> //推薦使用
<insert id="addEmpsBatch">
INSERT INTO emp(ename,gender,email,did)
VALUES
<foreach collection="emps" item="emp" separator=",">
(#{emp.eName},#{emp.gender},#{emp.email},#{emp.dept.id})
</foreach>
</insert><!-- 這種方式需要資料庫連接屬性allowMutiQueries=true的支持
如jdbc.url=jdbc:mysql://localhost:3306/mybatis?allowMultiQueries=true -->
<insert id="addEmpsBatch">
<foreach collection="emps" item="emp" separator=";">
INSERT INTO emp(ename,gender,email,did)
VALUES(#{emp.eName},#{emp.gender},#{emp.email},#{emp.dept.id})
</foreach>
</insert>使用ExecutorType.BATCH
- Mybatis內置的ExecutorType有3種,默認為simple,該模式下它為每個陳述句的執行創建一個新的預處理陳述句,單條提交sql;而batch模式重復使用已經預處理的陳述句,并且批量執行所有更新陳述句,顯然batch性能將更優; 但batch模式也有自己的問題,比如在Insert操作時,在事務沒有提交之前,是沒有辦法獲取到自增的id,這在某型情形下是不符合業務要求的
- 具體用法如下:
//批量保存方法測驗
//批量保存方法測驗
@Test
public void testBatch() throws IOException{
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
//可以執行批量操作的sqlSession
SqlSession openSession =
sqlSessionFactory.openSession(ExecutorType.BATCH);
//批量保存執行前時間
long start = System.currentTimeMillis();
try {
EmployeeMapper mapper =
openSession.getMapper(EmployeeMapper.class);
for (int i = 0; i < 1000; i++) {
mapper.addEmp(new
Employee(UUID.randomUUID().toString().substring(0, 5), "b", "1"));
}
openSession.commit();
long end = System.currentTimeMillis();
//批量保存執行后的時間
System.out.println("執行時長" + (end - start));
//批量 預編譯sql一次==》設定引數==》10000次==》執行1次 677//非批量 (預編譯=設定引數=執行 )==》10000次 1121
} finally {
openSession.close();
}
}- mapper和mapper.xml如下
public interface EmployeeMapper {
//批量保存員工
Long addEmp(Employee employee);
}```
<mapper namespace="com.jourwon.mapper.EmployeeMapper"
<!--批量保存員工 -->
<insert id="addEmp">
insert into employee(lastName,email,gender)
values(#{lastName},#{email},#{gender})
</insert>
</mapper>
```上述面試題已經整理成檔案,有需要的可以?點擊進入 查看領取資料,
JVM系列面試寶典

1.詳解JVM記憶體模型
思路: 給面試官畫一下JVM記憶體模型圖,并描述每個模塊的定義,作用,以及可能會存在的問題,如堆疊溢位等,
我的答案:
JVM記憶體結構
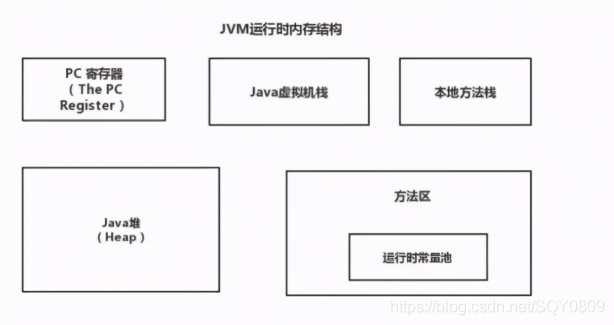
- 程式計數器:當前執行緒所執行的位元組碼的行號指示器,用于記錄正在執行的虛擬機位元組指令地址,執行緒私有,
- Java虛擬堆疊:存放基本資料型別、物件的參考、方法出口等,執行緒私有,
- Native方法堆疊:和虛擬堆疊相似,只不過它服務于Native方法,執行緒私有,
- Java堆:java記憶體最大的一塊,所有物件實體、陣列都存放在java堆,GC回收的地方,執行緒共享,
- 方法區:存放已被加載的類資訊、常量、靜態變數、即時編譯器編譯后的代碼資料等,(即永久帶),回收目標主要是常量池的回收和型別的卸載,各執行緒共享
2.說說記憶體屏障
記憶體屏障,也叫記憶體柵欄,是一種CPU指令,用于控制特定條件下的重排序和記憶體可見性問題,
LoadLoad屏障:對于這樣的陳述句Load1; LoadLoad; Load2,在Load2及后續讀取操作要讀取的資料被訪問前,保證Load1要讀取的資料被讀取完畢,
StoreStore屏障:對于這樣的陳述句Store1; StoreStore; Store2,在Store2及后續寫入操作執行前,保證Store1的寫入操作對其它處理器可見,
LoadStore屏障:對于這樣的陳述句Load1; LoadStore; Store2,在Store2及后續寫入操作被刷出前,保證Load1要讀取的資料被讀取完畢,
StoreLoad屏障:對于這樣的陳述句Store1; StoreLoad; Load2,在Load2及后續所有讀取操作執行前,保證Store1的寫入對所有處理器可見,它的開銷是四種屏障中最大的, 在大多數處理器的實作中,這個屏障是個萬能屏障,兼具其它三種記憶體屏障的功能,
3.happen-before原則
- 單執行緒happen-before原則:在同一個執行緒中,書寫在前面的操作happen-before后面的操作,鎖的happen-before原則:同一個鎖的unlock操作happen-before此鎖的lock操作,
- volatile的happen-before原則:對一個volatile變數的寫操作happen-before對此變數的任意操作(當然也包括寫操作了),
- happen-before的傳遞性原則:如果A操作 happen-before B操作,B操作happen-before C操作,那么A操作happen-before C操作,
- 執行緒啟動的happen-before原則:同一個執行緒的start方法happen-before此執行緒的其它方法,
- 執行緒中斷的happen-before原則 :對執行緒interrupt方法的呼叫happen-before被中斷執行緒的檢測到中斷發送的代碼,
- 執行緒終結的happen-before原則: 執行緒中的所有操作都happen-before執行緒的終止檢測,
- 物件創建的happen-before原則: 一個物件的初始化完成先于他的fifinalize方法呼叫,
4.怎么打破雙親委派模型?
打破雙親委派機制則不僅要繼承ClassLoader類,還要重寫loadClass和fifindClass方法,
5.強參考、軟參考、弱參考、虛參考的區別?
思路: 先說一下四種參考的定義,可以結合代碼講一下,也可以擴展談到ThreadLocalMap里弱參考用處,
我的答案:
1)強參考
我們平時new了一個物件就是強參考,例如 Object obj = new Object();即使在記憶體不足的情況下,JVM
寧愿拋出OutOfMemory錯誤也不會回收這種物件,
2)軟參考
如果一個物件只具有軟參考,則記憶體空間足夠,垃圾回收器就不會回收它;如果記憶體空間不足了,就會回收這些物件的記憶體,
SoftReference<String> softRef=new SoftReference<String>(str); // 軟參考用處: 軟參考在實際中有重要的應用,例如瀏覽器的后退按鈕,按后退時,這個后退時顯示的網頁內容是重新進行請求還是從快取中取出呢?這就要看具體的實作策略了,
(1)如果一個網頁在瀏覽結束時就進行內容的回收,則按后退查看前面瀏覽過的頁面時,需要重新構建
(2)如果將瀏覽過的網頁存盤到記憶體中會造成記憶體的大量浪費,甚至會造成記憶體溢位
如下代碼:
Browser prev = new Browser(); // 獲取頁面進行瀏覽
SoftReference sr = new SoftReference(prev); // 瀏覽完畢后置為軟參考
if(sr.get()!=null){
rev = (Browser) sr.get(); // 還沒有被回收器回收,直接獲取
}else{
prev = new Browser(); // 由于記憶體吃緊,所以對軟參考的物件回收了
sr = new SoftReference(prev); // 重新構建
}3)弱參考
具有弱參考的物件擁有更短暫的生命周期,在垃圾回收器執行緒掃描它所管轄的記憶體區域的程序中,一旦發現了只具有弱參考的物件,不管當前記憶體空間足夠與否,都會回收它的記憶體,
String str=new String("abc");
WeakReference<String> abcWeakRef = new WeakReference<String>(str);
str=null;
等價于
str = null;
System.gc();4)虛參考
如果一個物件僅持有虛參考,那么它就和沒有任何參考一樣,在任何時候都可能被垃圾回收器回收,虛參考主要用來跟蹤物件被垃圾回收器回收的活動,
Zookeeper系列面試寶典

1.Zookeeper 的 java 客戶端都有哪些?
java 客戶端:zk 自帶的 zkclient 及 Apache 開源的 Curator,
2.說幾個 zookeeper 常用的命令,
常用命令:ls get set create delete 等,
3.Zookeeper 的典型應用場景
Zookeeper 是一個典型的發布/訂閱模式的分布式資料管理與協調框架,開發人員可以使用它來進行分布式資料的發布和訂閱,
通過對 Zookeeper 中豐富的資料節點進行交叉使用,配合 Watcher 事件通知機制,可以非常方便的構建一系列分布式應用中年都會涉及的核心功能,如:
(1)資料發布/訂閱
(2)負載均衡
(3)命名服務
(4)分布式協調/通知
(5)集群管理(6)Master 選舉
(7)分布式鎖
(8)分布式佇列
4.負載均衡
zk 的命名服務
命名服務是指通過指定的名字來獲取資源或者服務的地址,利用 zk 創建一個全域的路徑,這個路徑就可以作為一個名字,指向集群中的集群,提供的服務的地址,或者一個遠程的物件等等,
5.集群支持動態添加機器嗎?
其實就是水平擴容了,Zookeeper 在這方面不太好,兩種方式:
全部重啟:關閉所有 Zookeeper 服務,修改配置之后啟動,不影響之前客戶端的會話,
逐個重啟:在過半存活即可用的原則下,一臺機器重啟不影響整個集群對外提供服務,這是比較常用的方式,
3.5 版本開始支持動態擴容
6.Zookeeper 下 Server 作業狀態
服務器具有四種狀態,分別是 LOOKING、FOLLOWING、LEADING、OBSERVING,
(1)LOOKING:尋 找 Leader 狀態,當服務器處于該狀態時,它會認為當前集群中沒有 Leader,因此需要進入 Leader 選舉狀態,
(2)FOLLOWING:跟隨者狀態,表明當前服務器角色是 Follower,
(3)LEADING:領導者狀態,表明當前服務器角色是 Leader,
(4)OBSERVING:觀察者狀態,表明當前服務器角色是 Observer,
7.Chroot 特性
3.2.0 版本后,添加了 Chroot 特性,該特性允許每個客戶端為自己設定一個命名空間,如果一個客戶端設定了 Chroot,那么該客戶端對服務器的任何操作,都將會被限制在其自己的命名空間下,
通過設定 Chroot,能夠將一個客戶端應用于 Zookeeper 服務端的一顆子樹相對應,在那些多個應用公用一個 Zookeeper 進群的場景下,對實作不同應用間的相互隔離非常有幫助,
最后來自小編的福利

以下的面試題及答案是小編整理許久整理成的合集,需要領取的小伙伴可以 點我 免費領取 ,在這里小編祝福想去大廠面試的同學,旗開得勝,offer拿到手抽筋,
部分資料圖片:
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/208463.html
標籤:其他
上一篇:用例子理解遞回
下一篇:c++控制臺密碼管理系統