機器學習筆記
- 機器學習
- 學習方法
- 有監督學習
- 分類
- 決策樹
- 貝葉斯分類
- 支持向量機(SVM)
- 邏輯回歸
- 集成學習
- 回歸
- 線性回歸
- 嶺回歸
- Lasso回歸
- 無監督學習
- 聚類
- K-means
- 高斯混合聚類
- 密度聚類
- 層次聚類
- 半監督學習
- 增強學習
- 多任務學習
- 模型評估
- 分類
- 準確率
- 召回率
- 精確率
- F1-score
- AUC
- PR曲線
- 邏輯回歸損失
- 平均絕對誤差
- 平均平方誤差
- R Squared
- 聚類
- 外部指標
- 內部指標
- 模型選擇
- 問題
- 準備
- 資料預處理
- 資料清洗
- 資料采樣
- 資料不平衡
- 解決方法
- 資料集拆分
- 資料集型別
- 拆分方法
- 特征工程
- 特征選擇
- 過濾法
- 包裹法
- 嵌入法
- 特征降維
- 主成分分析(PCA)
- 線性判別分析(LDA)
- 特征編碼
- one-hot編碼
- 語意編碼
- 規范化
- 標準化
- 區間縮放
- 歸一化
機器學習
學習方法
有監督學習
分類
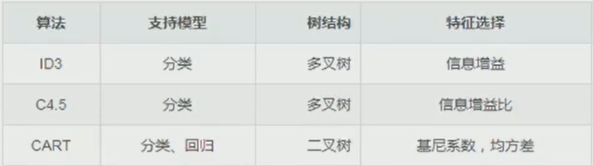
決策樹
- 定義:一個樹結構,每個非葉節點表示一個特征屬性,每個分支邊代表該特征屬性的輸出,每個葉節點放一個類別,
- 程序:從根節點開始判斷非葉節點屬性,直到葉子節點(決策結果),
- 構建:1. 選擇具有分類作用的特征;2.遞回構建決策樹;3.剪枝,
- 選擇

- 演算法
貝葉斯分類
- 貝葉斯公式
P ( 類 別 ∣ 特 征 ) = P ( 特 征 ∣ 類 別 ) P ( 類 別 ) P ( 特 征 ) P(類別|特征)=\frac{P(特征|類別)P(類別)}{P(特征)} P(類別∣特征)=P(特征)P(特征∣類別)P(類別)? - 樸素貝葉斯
ω m a p = a r g m a x P ( ω i ∣ a 1 , a 2 , . . . , a n ) = a r g m a x P ( a 1 , a 2 , . . . , a n ∣ ω i ) P ( ω i ) P ( a 1 , a 2 , . . . , a n ) = a r g m a x P ( a 1 , a 2 , . . . , a n ∣ ω i ) P ( ω i ) = a r g m a x P ( ω i ) ∏ j P ( a j ∣ ω i ) \omega_{map}=arg\ max\ P(\omega_{i}|a_{1},a_{2},...,a_{n})\\\qquad=arg\ max\frac{P(a_{1},a_{2},...,a_{n}|\omega_{i})P(\omega_{i})}{P(a_{1},a_{2},...,a_{n})}\\\qquad=arg\ max\ P(a_{1},a_{2},...,a_{n}|\omega_{i})P(\omega_{i})\\\qquad=arg\ maxP(\omega_{i})\prod_{j}P(a_{j}|\omega_{i}) ωmap?=arg max P(ωi?∣a1?,a2?,...,an?)=arg maxP(a1?,a2?,...,an?)P(a1?,a2?,...,an?∣ωi?)P(ωi?)?=arg max P(a1?,a2?,...,an?∣ωi?)P(ωi?)=arg maxP(ωi?)j∏?P(aj?∣ωi?) - 拉普拉斯修正
P ( c ) = D c D ? P ( c ) = D c + 1 D + N P ( x i ∣ c ) = D c , x i D c ? P ( x i ∣ c ) = D c , x i + 1 D c + N i P(c)=\frac{D_{c}}{D}\Rightarrow P(c)=\frac{D_{c}+1}{D+N}\\P(x_{i}|c)=\frac{D_{c,xi}}{D_{c}}\Rightarrow P(x_{i}|c)=\frac{D_{c,xi}+1}{D_{c}+N_{i}} P(c)=DDc???P(c)=D+NDc?+1?P(xi?∣c)=Dc?Dc,xi???P(xi?∣c)=Dc?+Ni?Dc,xi?+1?
支持向量機(SVM)
資料離超平面的距離越遠,分類的信任度越大
- 硬間隔

m i n 1 2 ∣ ∣ w ∣ ∣ 2 y ( i ) ( w T x ( i ) + b ) ≥ 1 min\frac{1}{2}||w||^{2}\\\quad y^{(i)}(w^{T}x^{(i)}+b)\ge1 min21?∣∣w∣∣2y(i)(wTx(i)+b)≥1 - 軟間隔向量機

- 非線性向量機
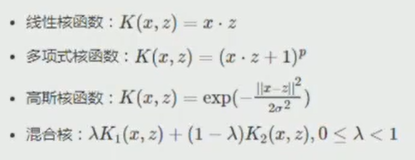
- 多分類SVM
一對多:每次選定一個類別,構造其對應向量機,
一對一:每次選定兩個類別,構造兩個類別之間的向量機,
層次:不斷二分所有類別,
邏輯回歸
- 廣義線性回歸
w = ( w 1 , w 2 , . . . , w n , b ) T x = ( x 1 , x 2 , . . . , x n , 1 ) w ? x = w 1 ? x 1 + w 2 ? x 2 + . . . + w n ? x n + b w=(w_{1},w_{2},...,w_{n},b)^T\\ x=(x_{1},x_{2},...,x_{n},1)\\ w·x=w_{1}·x_{1}+w_{2}·x_{2}+...+w_{n}·x_{n}+b w=(w1?,w2?,...,wn?,b)Tx=(x1?,x2?,...,xn?,1)w?x=w1??x1?+w2??x2?+...+wn??xn?+b - sigmoid函式
離散化
P ( Y = 1 ∣ x ) = e w ? x e w ? x + 1 P ( Y = 0 ∣ x ) = 1 e w ? x + 1 P(Y=1|x)=\frac{e^{w·x}}{e^{w·x}+1}\\ P(Y=0|x)=\frac{1}{e^{w·x}+1} P(Y=1∣x)=ew?x+1ew?x?P(Y=0∣x)=ew?x+11? - 多分類
在單分類的基礎上,訓練多個w系數集
P ( Y = k ∣ x ) = e w k ? x ∑ k = 1 K ? 1 e w k ? x + 1 P ( Y = 0 ∣ x ) = 1 ∑ k = 1 K ? 1 e w k ? x + 1 P(Y=k|x)=\frac{e^{w_{k}·x}}{\sum_{k=1}^{K-1}e^{w_{k}·x}+1}\\ P(Y=0|x)=\frac{1}{\sum_{k=1}^{K-1}e^{w_{k}·x}+1} P(Y=k∣x)=∑k=1K?1?ewk??x+1ewk??x?P(Y=0∣x)=∑k=1K?1?ewk??x+11?
集成學習
弱分類器集成強分類器
- Bagging
隨機重抽樣:弱分類器分完之后的結果共同決定分類結果 - Boosting
關注被分類器分類錯誤的樣本,調整權重集中關注判斷錯誤樣本, - 代表演算法
隨機森林、Adboost
回歸
預測輸入和輸出之間的關系
線性回歸
- 擬合函式形式
h θ ( x ) = ∑ i = 0 n θ i x i = θ T x h_\theta(x)=\sum_{i=0}^{n}\theta_{i}x_{i}=\theta^{T}x hθ?(x)=i=0∑n?θi?xi?=θTx - 確定損失函式形式
min ? θ J ( θ ) = 1 2 ∑ i = 1 m ( h θ ( x ) ( i ) ? y i ) 2 \min\limits_{\theta}\qquad J(\theta)=\frac{1}{2}\sum_{i=1}^{m}(h_\theta(x)^{(i)}-y_{i})^2 θmin?J(θ)=21?i=1∑m?(hθ?(x)(i)?yi?)2 - 訓練演算法,尋找系數
最小二乘法、梯度下降等 - 資料預測
y = w ? x + b y=w·x+b y=w?x+b - 擴展
用簡單的基函式替換變數x
y ( x , w ) = w 0 + ∑ j = 1 M ? 1 w j ? j ( x ) ? ? j ( x ) = x j ? y ( x , w ) = ∑ j = 0 M w j x j E ( w ) = 1 2 ∑ n = 1 N { y ( x n , w ) ? t n } 2 y(x,w)=w_{0}+\sum_{j=1}^{M-1}w_{j}\phi_{j}(x)\\ \Downarrow\phi_{j}(x)=x^{j}\Downarrow\\y(x,w)=\sum_{j=0}^{M}w_{j}x^{j}\\ E(w)=\frac{1}{2}\sum_{n=1}^{N}\{y(x_n,w)-t_{n}\}^2 y(x,w)=w0?+j=1∑M?1?wj??j?(x)??j?(x)=xj?y(x,w)=j=0∑M?wj?xjE(w)=21?n=1∑N?{y(xn?,w)?tn?}2
嶺回歸
風險最小化的基礎上加入正則化因子
β
0
∈
R
,
β
∈
R
p
m
i
n
m
i
z
e
1
n
∑
i
=
1
n
(
y
i
?
β
0
?
x
i
T
β
)
2
+
λ
∣
∣
β
∣
∣
2
∣
∣
β
∣
∣
2
≤
t
\stackrel{minmize}{\beta_{0}\in R,\beta\in R^p}\frac{1}{n}\sum_{i=1}^{n}(y_i-\beta_0-x_i^T\beta)^2+\lambda||\beta||^2\\ ||\beta||^2\le t
β0?∈R,β∈Rpminmize?n1?i=1∑n?(yi??β0??xiT?β)2+λ∣∣β∣∣2∣∣β∣∣2≤t
Lasso回歸
- 通過懲罰函式壓縮引數,得到精煉的模型
- 適合樣本量小,指標多的資料
β 0 ∈ R , β ∈ R p m i n m i z e 1 n ∑ i = 1 n ( y i ? β 0 ? x i T β ) 2 + λ ∣ ∣ β ∣ ∣ ∣ ∣ β ∣ ∣ 1 ≤ t \stackrel{minmize}{\beta_{0}\in R,\beta\in R^p}\frac{1}{n}\sum_{i=1}^{n}(y_i-\beta_0-x_i^T\beta)^2+\lambda||\beta||\\ ||\beta||_1\le t β0?∈R,β∈Rpminmize?n1?i=1∑n?(yi??β0??xiT?β)2+λ∣∣β∣∣∣∣β∣∣1?≤t
無監督學習
聚類
感知樣本之間的相似度,對輸入進行輸出預測
K-means
隨機選擇k個中心點作為聚類中心,把每個資料點分配給最近的中心點

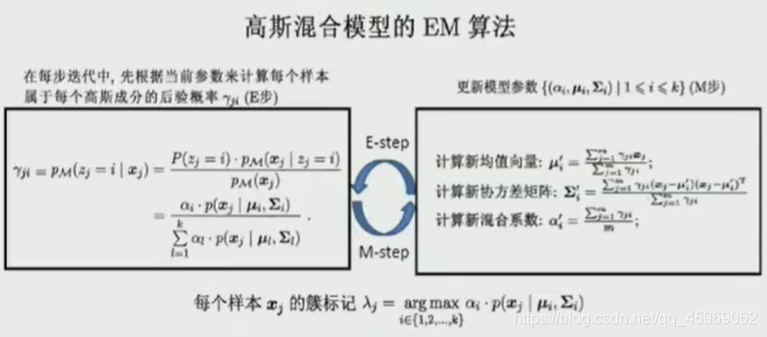
高斯混合聚類
多個高斯分布函式的線性組合
- 單高斯模型
f ( x ∣ μ , σ 2 ) = 1 2 σ 2 π e ? ( x ? μ ) 2 2 σ 2 f(x|\mu,\sigma^2)=\frac{1}{\sqrt{2\sigma^2\pi}}e^{-\frac{(x-\mu)^2}{2\sigma^2}} f(x∣μ,σ2)=2σ2π ?1?e?2σ2(x?μ)2? - 高斯混合模型
p ( x ) = ∑ i = 1 K ? i 1 2 σ i 2 π e ? ( x ? μ i ) 2 2 σ i 2 p(x)=\sum_{i=1}^K\phi_i\frac{1}{\sqrt{2\sigma_i^2\pi}}e^{-\frac{(x-\mu_i)^2}{2\sigma_i^2}} p(x)=i=1∑K??i?2σi2?π ?1?e?2σi2?(x?μi?)2? - EM演算法
密度聚類
通過樣本分布的緊密程度判斷樣本之間的可連接性,并基于連接樣本擴展
- DBSCAN演算法
1.檢查每個點的Eps鄰域,若點p鄰域內點的個數多于MinPts個,則創建一個以p為核心的簇
2.演算法迭代地聚集核心物件,合并密度可達簇的合并
3.沒有新點加入簇時結束
層次聚類
根據每個資料點之間的距離,分層次劃分樹形聚類結構
- AGNES演算法
1.將每個資料點作為一個簇,使用簡單連接方法合并
2.簇之間的相似度由點對之間的距離確定,簇之間的最近距離超過設定的閾值時結束
3.反復合并直到所有資料點滿足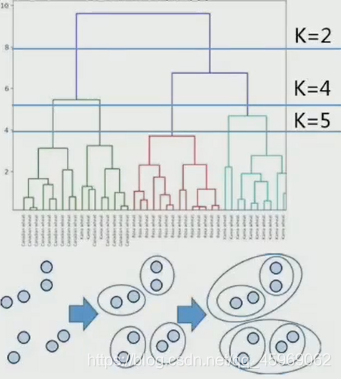
半監督學習
- 標注訓練資料(少量)
- 未標注資料(大量)
增強學習
- 外部對輸出進行評價
多任務學習
- 相關任務一起學習
模型評估
分類
準確率
正確個數站總記錄的比值
a
c
c
u
r
a
c
y
=
T
P
+
T
N
T
P
+
T
N
+
F
P
+
F
N
accuracy=\frac{TP+TN}{TP+TN+FP+FN}
accuracy=TP+TN+FP+FNTP+TN?
召回率
樣本的正例中預測正確的比值
r
e
c
a
l
l
=
T
P
T
P
+
T
N
recall=\frac{TP}{TP+TN}
recall=TP+TNTP?
精確率
判斷正例中正確的比值
p
r
e
c
i
s
i
o
n
=
T
P
T
P
+
F
P
precision=\frac{TP}{TP+FP}
precision=TP+FPTP?
F1-score
精確率與召回率的調和平均值
常用
F
1
=
2
?
p
r
e
c
i
s
i
o
n
?
r
e
c
a
l
l
p
r
e
c
i
s
i
o
n
+
r
e
c
a
l
l
F1=\frac{2·precision·recall}{precision+recall}
F1=precision+recall2?precision?recall?
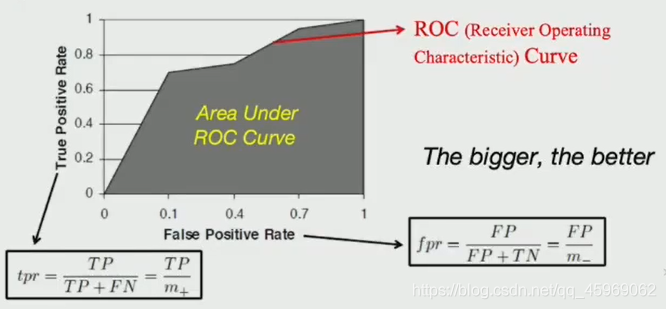
AUC
- ROC曲線:
縱軸:真正例率TPR
橫軸:假正例率FPR - AUC
ROC和橫軸圍成的面積
面積越大,模型越好
PR曲線
根據不同學習器的正例可能性大小對樣例排序
- 橫軸:查全率
- 縱軸:查準率
- 外層的模型性能更好
- 有交叉考慮平衡點
BEP
邏輯回歸損失
- 二分類問題
y ∈ { 0 , 1 } ∩ p = P r ( y = 1 ) L l o g ( y , p ) = ? l o g P r ( y ∣ p ) = ? ( y l o g ( p ) + ( 1 ? y ) l o g ( 1 ? p ) ) y\in \{0,1\}\cap p=Pr(y=1)\\ L_{log}(y,p)=-logPr(y|p)=-(ylog(p)+(1-y)log(1-p)) y∈{0,1}∩p=Pr(y=1)Llog?(y,p)=?logPr(y∣p)=?(ylog(p)+(1?y)log(1?p)) - 多分類問題
p i , k = P r ( t i , k = 1 ) ? L l o g ( Y i ∣ P i ) = ? l o g P r ( Y i ∣ P i ) = ∑ k = 1 K y i , k l o g p i , k p_{i,k}=Pr(t_{i,k}=1)\\ \Downarrow \\ L_{log}(Y_i|P_i)=-logPr(Y_i|P_i)=\sum_{k=1}^Ky_{i,k}logp_{i,k} pi,k?=Pr(ti,k?=1)?Llog?(Yi?∣Pi?)=?logPr(Yi?∣Pi?)=k=1∑K?yi,k?logpi,k?
平均絕對誤差
M A E ( y , y ^ ) = 1 n s a m p l e s ∑ i = 1 n s a m p l e s ∣ y i ? y i ^ ∣ MAE(y,\hat{y})=\frac{1}{n_{samples}}\sum_{i=1}^{n_{samples}}|y_i-\hat{y_i}| MAE(y,y^?)=nsamples?1?i=1∑nsamples??∣yi??yi?^?∣
平均平方誤差
M S E ( y , y ^ ) = 1 n s a m p l e s ∑ i = 1 n s a m p l e s ( y i ? y i ^ ) 2 MSE(y,\hat{y})=\frac{1}{n_{samples}}\sum_{i=1}^{n_{samples}}(y_i-\hat{y_i})^2 MSE(y,y^?)=nsamples?1?i=1∑nsamples??(yi??yi?^?)2
R Squared
R 2 = 1 ? ( ∑ i ( y i ^ ? y i ) 2 ) / m ( ∑ i ( y i ˉ ? y i ) 2 ) / m R^2=1-\frac{(\sum_i(\hat{y_i}-y_i)^2)/m}{(\sum_i(\bar{y_i}-y_i)^2)/m} R2=1?(∑i?(yi?ˉ??yi?)2)/m(∑i?(yi?^??yi?)2)/m?
聚類
外部指標
Jaccard系數FM指數Rand指數purity純度entropy熵- 互資訊
ARIF-measurePRI
內部指標
DBIDI
模型選擇
- 泛化誤差
未來樣本的誤差 - 經驗誤差
訓練集上的誤差
問題
- scalability
- 速度
- online learning
準備
資料預處理
資料清洗
獲得連續的資料
- 完整性:資訊補全
- 唯一性:去重
- 合法性:設定合法規則
- 權威性:設定權威級別
- 唯一性:建立資料體系
資料采樣
資料不平衡
資料集類別分布不均
解決方法
- 過采樣:隨機復制少數類的樣本
- 欠采樣:隨機消除占多數的類的樣本
資料集拆分
資料集型別
- 訓練資料集:構建機器學習模型
- 驗證資料集:調整模型引數
- 測驗資料集:評估模型
拆分方法
- 留出法:將資料集分成兩個互斥的集合
- K-折交叉驗證法:分成K個互斥子集,進行K次訓練和測驗
特征工程
特征選擇
過濾法
按照發散性設定閾值
- 互資訊:兩個隨機變數之間的關聯程度
I ( X ; Y ) = ∑ x ∈ X ∑ y ∈ Y p ( x , y ) l o g p ( x , y ) p ( x ) p ( y ) I(X;Y)=\sum_{x\in X}\sum_{y\in Y}p(x,y)log\frac{p(x,y)}{p(x)p(y)} I(X;Y)=x∈X∑?y∈Y∑?p(x,y)logp(x)p(y)p(x,y)?
包裹法
選定演算法,不斷用啟發式方法來搜索特征
嵌入法
正則化的思想,將某些特征權重設定為0,相當于該特征被拋棄
特征降維
防止特征矩陣過大
主成分分析(PCA)
- 決議到彼此正交的特征向量空間
- 非滿秩時使用
SVD分解來構建特征向量
線性判別分析(LDA)
- 將資料集投影到一條直線
特征編碼
one-hot編碼
- 將資料按照01編碼
- 無法體現資料之間的語意關系
語意編碼
- 特征之間存在語意關系
規范化
標準化
將資料縮放到一個特定區間
x
=
(
x
?
μ
)
/
σ
x=(x-\mu)/\sigma
x=(x?μ)/σ
區間縮放
將資料縮放到指定最大/小值之間
x
=
x
?
m
i
n
m
a
x
?
m
i
n
x=\frac{x-min}{max-min}
x=max?minx?min?
歸一化
將特征的模長轉化為1
x
′
=
x
∑
j
m
x
[
j
]
2
x'=\frac{x}{\sqrt{\sum_{j}^{m}x[j]^{2}}}
x′=∑jm?x[j]2
?x?
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/224043.html
標籤:其他