CART決策樹
- 前言
- 一、CART決策樹演算法
- 二、Python代碼實作
- 1.計算結點GINI值
- 2.分離資料集
- 3.選擇最好的特征
- 4.生成決策樹
- 5.測驗決策樹
- 6.決策樹可視化
- 7.主程式部分
- CART決策分類樹所有代碼
- 三、運行結果
- 總結
前言
??CART演算法的全稱是Classification And Regression Tree,采用的是Gini指數(選Gini指數最小的特征s)作為分裂標準,是一種實用的分類演算法,
一、CART決策樹演算法
??主要思路是對一個資料集選擇幾個屬性作為特征,對于每個特征提出一個劃分條件,根據這個條件將結點分為兩個子節點,對于子節點同樣利用下一個特征進行劃分,直到某結點的Gini值符合要求,我們認為這個結點的不純性很小,該節點已成功分類,如此反復執行,最后可以得到由若干個結點組成的決策樹,其中的每個葉節點都是分類的結果,
??某結點的Gini值的計算公式如下:
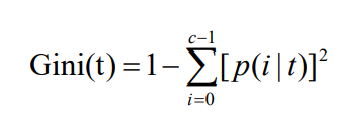
??如果要對某種劃分計算Gini值,可以利用加權平均,即:
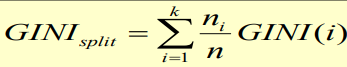
??明確了Gini值的計算以及決策樹的基本思路后,就可以繼續向下看具體的代碼實作了,本文沒有使用sklearn庫,如果讀者只是需要使用該演算法,而不想了解演算法實際的實作思路的話,可以無需向下看了,
二、Python代碼實作
主要分為6個步驟:
- 尋找到最佳屬性
- 創建決策樹
- 將上一結點分裂,分別計算左、右子節點的Gini值,
- 計算Gnin值有一種方法:將資料集對應這個屬性的值排序,從頭開始選擇相鄰兩個值的平均值作為劃分條件,計算該分發下的Gini值,如此遍歷一遍,選出最小的一個Gini值對應的劃分條件,作為該屬性的最佳分裂條件
- 對于子節點,Gini值小于閾值,認為其是葉節點,結束這一方向的分裂,若Gini值大于閾值,認為分類還不夠純,需繼續分裂,下一次分裂要使用不同的屬性值,
- 遞回呼叫創建決策樹,就可以得到完整的決策樹,
使用到的函式主要有5個:
- calcGini(dataSet) ??#計算結點GINI值
- splitDataSet(dataSet, n, value, type)??#根據條件分離資料集
- FindBestFeature(dataSet)??#選擇最好的特征劃分資料集,即回傳最佳特征下標及傳入資料集各列的Gini指數
- createTree(dataSet, features, decisionTree)??#生成決策樹,輸入:訓練資料集D,特征集A,輸出:決策樹T
- testTree(dataSet)??#獲得測驗結果,給出混淆矩陣
1.計算結點GINI值
def calcGini(dataSet):
numTotal = dataSet.shape[0] # 記錄本資料集總條數
length = len(dataSet[0]) # 計算特征列數
frequent_0 = 0.0 # 記錄三種樣本出現次數
frequent_1 = 0.0
frequent_2 = 0.0
for i in range(0,numTotal):
if dataSet[i][length-1] == '0.0':
frequent_0 += 1
elif dataSet[i][length-1] == '1.0':
frequent_1 += 1
elif dataSet[i][length-1] == '2.0':
frequent_2 += 1
gini = 1 - (frequent_0/numTotal)**2 - (frequent_1/numTotal)**2 - (frequent_2/numTotal)**2
return gini
2.分離資料集
def splitDataSet(dataSet, n, value, type):
subDataSet = []
numTotal = dataSet.shape[0] # 記錄本資料集總條數
if type == 1: # type==1對應小于等于value的情況
for i in range(0,numTotal):
if float(dataSet[i][n]) <= value:
subDataSet.append(dataSet[i])
elif type == 2: # type==2對應大于value的情況
for i in range(0,numTotal):
if float(dataSet[i][n]) > value:
subDataSet.append(dataSet[i])
subDataSet = np.array(subDataSet) # 強制轉換為array型別
return subDataSet,len(subDataSet)
3.選擇最好的特征
def FindBestFeature(dataSet):
numTotal = dataSet.shape[0] # 記錄本資料集總條數
numFeatures = len(dataSet[0]) - 2 # 計算特征列數
bestFeature = -1 # 初始化引數,記錄最優特征列i,下標從0開始
columnFeaGini={} # 初始化引數,記錄每一列x的每一種特征的基尼 Gini(D,A)
for i in range(1, numFeatures+1): # 遍歷所有x特征列,i為特征標號
featList = list(dataSet[:, i]) # 取這一列x中所有資料,轉換為list型別
featListSort = [float(x) for x in featList]
featListSort.sort() # 對該特征值排序
FeaGinis = []
FeaGiniv = []
for j in range(0,len(featListSort)-1): # j為第幾組資料
value = (featListSort[j]+featListSort[j+1])/2
feaGini = 0.0
subDataSet1,sublen1 = splitDataSet(dataSet, i, value, 1) # 獲取切分后的資料
subDataSet2,sublen2 = splitDataSet(dataSet, i, value, 2)
feaGini = (sublen1/numTotal) * calcGini(subDataSet1) + (sublen2/numTotal) * calcGini(subDataSet2) # 計算此分法對應Gini值
FeaGinis.append(feaGini) # 記錄該特征下各種分法遍歷出的Gini值
FeaGiniv.append(value) # 記錄該特征下的各種分法
columnFeaGini['%d_%f'%(i,FeaGiniv[FeaGinis.index(min(FeaGinis))])] = min(FeaGinis) # 將該特征下最小的Gini值
bestFeature = min(columnFeaGini, key=columnFeaGini.get) # 找到最小的Gini指數對應的資料列
return bestFeature,columnFeaGini
4.生成決策樹
def createTree(dataSet, features, decisionTree):
if len(features) > 2: #特征未用完
bestFeature, columnFeaGini = FindBestFeature(dataSet)
bestFeatureLable = features[int(bestFeature.split('_')[0])] # 最佳特征
NodeName = bestFeatureLable + '\n' +'<=' + bestFeature.split('_')[1] #結點名稱
decisionTree = {NodeName: {}} # 構建樹,以Gini指數最小的特征bestFeature為子節點
else:
return decisionTree
LeftSet, LeftSet_len = splitDataSet(dataSet, int(bestFeature.split('_')[0]), float(bestFeature.split('_')[1]), 1)
RightSet, RightSet_len = splitDataSet(dataSet, int(bestFeature.split('_')[0]), float(bestFeature.split('_')[1]), 2)
del (features[int(bestFeature.split('_')[0])]) # 該特征已為子節點使用,則洗掉,以便接下來繼續構建子樹
if calcGini(LeftSet) <= 0.1 or len(features) == 2:
L_lables_grp = dict(Counter(LeftSet[:,-1]))
L_leaf = max(L_lables_grp, key=L_lables_grp.get) # 獲得劃分后出現概率最大的分類作為結點的分類
decisionTree[NodeName]['Y'] = L_leaf # 設定左枝葉子值
elif calcGini(LeftSet) > 0.1:
dataSetNew = np.delete(LeftSet, int(bestFeature.split('_')[0]), axis=1) # 洗掉此最優劃分x列,使用剩余的x列進行資料劃分
L_subFeatures = features[:]
decisionTree[NodeName]['Y'] = {'NONE'}
decisionTree[NodeName]['Y'] = createTree(dataSetNew, L_subFeatures, decisionTree[NodeName]['Y']) #遞回生成左邊的樹
if calcGini(RightSet) <= 0.1 or len(features) == 2:
R_lables_grp = dict(Counter(RightSet[:,-1]))
R_leaf = max(R_lables_grp, key=R_lables_grp.get) # 獲得劃分后出現概率最大的分類作為結點的分類
decisionTree[NodeName]['N'] = R_leaf # 設定右枝葉子值
elif calcGini(RightSet) > 0.1:
dataSetNew = np.delete(RightSet, int(bestFeature.split('_')[0]), axis=1) # 洗掉此最優劃分x列,使用剩余的x列進行資料劃分
R_subFeatures = features[:]
decisionTree[NodeName]['N'] = {'NONE'}
decisionTree[NodeName]['N'] = createTree(dataSetNew, R_subFeatures, decisionTree[NodeName]['N']) #遞回生成右邊的樹
return decisionTree
5.測驗決策樹
def testTree(dataSet):
numTotal = dataSet.shape[0] # 記錄本資料集總條數
testmemory = []
label = dataSet[:,-1]
TP = 0
FP = 0
TN = 0
FN = 0
for i in range(0,numTotal):
if float(dataSet[i][4]) <= 0.001444: #標準差
if float(dataSet[i][1]) <= 0.01022: #均值
if float(dataSet[i][6]) <= -0.589019: #峰度
testmemory.append('0.0')
else:
if float(dataSet[i][3]) <= -0.001811: #四分位差
if float(dataSet[i][2]) <= -0.000026: #中位數
testmemory.append('0.0')
else:
testmemory.append('2.0')
else:
if float(dataSet[i][2]) <= 0.007687: #中位數
if float(dataSet[i][5]) <= 0.452516: #偏度
testmemory.append('0.0')
else:
testmemory.append('0.0')
else:
testmemory.append('2.0')
else:
testmemory.append('2.0')
else:
if float(dataSet[i][3]) <= -0.013691: # 四分位差
testmemory.append('1.0')
else:
if float(dataSet[i][5]) <= 1.462280: #偏度
if float(dataSet[i][6]) <= -1.034223: # 峰度
if float(dataSet[i][1]) <= 0.009173: # 均值
if float(dataSet[i][2]) <= -0.004193: # 中位數
testmemory.append('2.0')
else:
testmemory.append('2.0')
else:
testmemory.append('0.0')
else:
testmemory.append('2.0')
else:
if float(dataSet[i][1]) <= -0.023631: # 均值
testmemory.append('2.0')
else:
testmemory.append('1.0')
for i in range(0, numTotal):
if (testmemory[i] == '1.0') and (label[i] == '1.0'):
TP += 1
elif (testmemory[i] == '1.0') and (label[i] != '1.0'):
FP += 1
elif (testmemory[i] != '1.0') and (label[i] != '1.0'):
TN += 1
elif (testmemory[i] != '1.0') and (label[i] == '1.0'):
FN += 1
print('TP:%d' % TP) #真陽性
print('FP:%d' % FP) #假陽性
print('TN:%d' % TN) #真陰性
print('FN:%d' % FN) #假陰性
cm = confusion_matrix(label, testmemory, labels=["0.0", "1.0", "2.0"])
plt.rc('figure', figsize=(5, 5))
plt.matshow(cm, cmap=plt.cm.cool) # 背景顏色
plt.colorbar() # 顏色標簽
# 內部添加圖例標簽
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(y, x), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True Label')
plt.xlabel('Predicted Label')
plt.title('decision_tree')
plt.savefig(r'confusion_matrix')
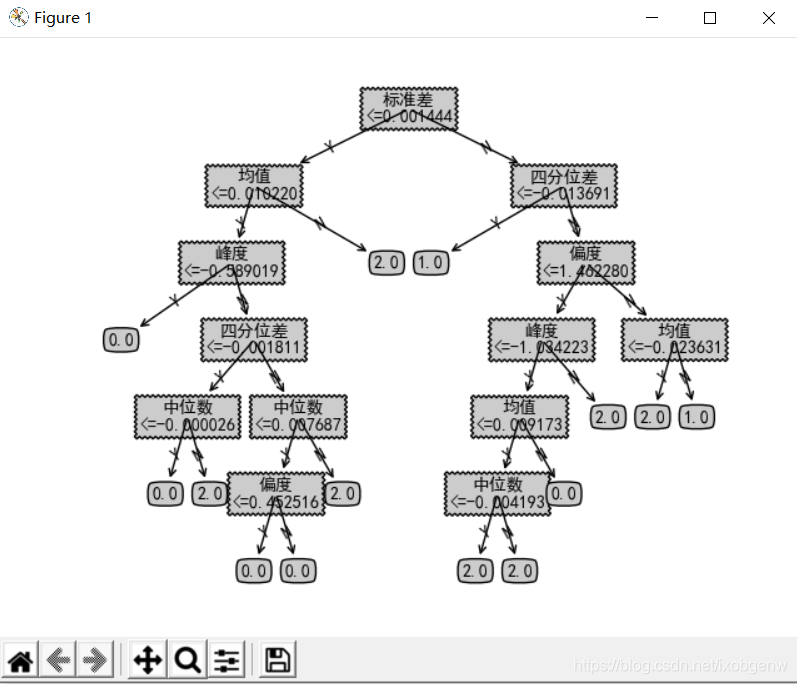
6.決策樹可視化
可視化部分基本摘自《機器學習實戰》第三章,
matplotlib.rcParams['font.family']='SimHei' # 用來正常顯示中文
plt.rcParams['axes.unicode_minus']=False # 用來正常顯示負號
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[
key]).__name__ == 'dict': # test to see if the nodes are dictonaires, if not they are leaf nodes
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree.keys())[0] # myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[
key]).__name__ == 'dict': # test to see if the nodes are dictonaires, if not they are leaf nodes
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt): # if the first key tells you what feat was split on
numLeafs = getNumLeafs(myTree) # this determines the x width of this tree
# depth = getTreeDepth(myTree)
firstStr = list(myTree.keys())[0] # myTree.keys()[0] #the text label for this node should be this
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict.keys():
if type(secondDict[
key]).__name__ == 'dict': # test to see if the nodes are dictonaires, if not they are leaf nodes
plotTree(secondDict[key], cntrPt, str(key)) # recursion
else: # it's a leaf node print the leaf node
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
def createPlot(myTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) # no ticks
# createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
plotTree.totalW = float(getNumLeafs(myTree))
plotTree.totalD = float(getTreeDepth(myTree))
plotTree.xOff = -0.5 / plotTree.totalW;
plotTree.yOff = 1.0;
plotTree(myTree, (0.5, 1.0), '')
plt.show()
7.主程式部分
trainingData, testingData= read_xslx(r'e:/Table/機器學習/1109/attribute_113.xlsx')
features = list(trainingData[0]) # x的表頭,即特征
trainingDataSet = trainingData[1:] # 訓練集
bestFeature, columnFeaGini=FindBestFeature(trainingDataSet)
decisionTree = {}
decisiontree = createTree(trainingDataSet, features, decisionTree) # 建立決策樹,CART分類樹
print('CART分類樹:\n', decisiontree)
testTree(testingData)
createPlot(decisiontree)
CART決策分類樹所有代碼
# -*- coding: utf-8 -*- 支持檔案中出現中文字符
#########################################################################
"""
Created on Mon Nov 16 21:26:00 2020
@author: ixobgenw
代碼功能描述: (1)計算結點GINI值
(2)分離資料集
(3)選擇最好的特征
(4)生成決策樹
(5)測驗決策樹
"""
#####################################################################
import xlrd
import numpy as np
from collections import Counter
import matplotlib.pyplot as plt
import matplotlib
#可視化部分
####################################################################################################################
matplotlib.rcParams['font.family']='SimHei' # 用來正常顯示中文
plt.rcParams['axes.unicode_minus']=False # 用來正常顯示負號
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
def getNumLeafs(myTree):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[
key]).__name__ == 'dict': # test to see if the nodes are dictonaires, if not they are leaf nodes
numLeafs += getNumLeafs(secondDict[key])
else:
numLeafs += 1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstStr = list(myTree.keys())[0] # myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[
key]).__name__ == 'dict': # test to see if the nodes are dictonaires, if not they are leaf nodes
thisDepth = 1 + getTreeDepth(secondDict[key])
else:
thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0] - cntrPt[0]) / 2.0 + cntrPt[0]
yMid = (parentPt[1] - cntrPt[1]) / 2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
def plotTree(myTree, parentPt, nodeTxt): # if the first key tells you what feat was split on
numLeafs = getNumLeafs(myTree) # this determines the x width of this tree
# depth = getTreeDepth(myTree)
firstStr = list(myTree.keys())[0] # myTree.keys()[0] #the text label for this node should be this
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs)) / 2.0 / plotTree.totalW, plotTree.yOff)
plotMidText(cntrPt, parentPt, nodeTxt)
plotNode(firstStr, cntrPt, parentPt, decisionNode)
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0 / plotTree.totalD
for key in secondDict.keys():
if type(secondDict[
key]).__name__ == 'dict': # test to see if the nodes are dictonaires, if not they are leaf nodes
plotTree(secondDict[key], cntrPt, str(key)) # recursion
else: # it's a leaf node print the leaf node
plotTree.xOff = plotTree.xOff + 1.0 / plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0 / plotTree.totalD
def createPlot(myTree):
fig = plt.figure(1, facecolor='white')
fig.clf()
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) # no ticks
# createPlot.ax1 = plt.subplot(111, frameon=False) #ticks for demo puropses
plotTree.totalW = float(getNumLeafs(myTree))
plotTree.totalD = float(getTreeDepth(myTree))
plotTree.xOff = -0.5 / plotTree.totalW;
plotTree.yOff = 1.0;
plotTree(myTree, (0.5, 1.0), '')
plt.show()
####################################################################################################################
#讀取excel檔案,70%為訓練集,30%為測驗集
####################################################################################################################
def read_xslx(xslx_path):
trainingdata = [] # 先宣告一個空list
testingdata = []
data = xlrd.open_workbook(xslx_path) # 讀取檔案
table = data.sheet_by_index(0) # 按索引獲取作業表,0就是作業表1
for i in range(int(0.7*table.nrows)): # table.nrows表示總行數
line = table.row_values(i) # 讀取每行資料,保存在line里面,line是list
trainingdata.append(line) # 將line加入到trainingdata中,trainingdata是二維list
trainingdata = np.array(trainingdata) # 將trainingdata從二維list變成陣列
for i in range(int(0.7*table.nrows),int(table.nrows)): # table.nrows表示總行數
line = table.row_values(i) # 讀取每行資料,保存在line里面,line是list
testingdata.append(line) # 將line加入到testingdata中,testingdata是二維list
testingdata = np.array(testingdata) # 將testingdata從二維list變成陣列
return trainingdata,testingdata
####################################################################################################################
#計算結點GINI值
####################################################################################################################
def calcGini(dataSet):
numTotal = dataSet.shape[0] # 記錄本資料集總條數
length = len(dataSet[0]) # 計算特征列數
frequent_0 = 0.0 # 記錄三種樣本出現次數
frequent_1 = 0.0
frequent_2 = 0.0
for i in range(0,numTotal):
if dataSet[i][length-1] == '0.0':
frequent_0 += 1
elif dataSet[i][length-1] == '1.0':
frequent_1 += 1
elif dataSet[i][length-1] == '2.0':
frequent_2 += 1
gini = 1 - (frequent_0/numTotal)**2 - (frequent_1/numTotal)**2 - (frequent_2/numTotal)**2
return gini
####################################################################################################################
#根據條件分離資料集
####################################################################################################################
def splitDataSet(dataSet, n, value, type):
subDataSet = []
numTotal = dataSet.shape[0] # 記錄本資料集總條數
if type == 1: # type==1對應小于等于value的情況
for i in range(0,numTotal):
if float(dataSet[i][n]) <= value:
subDataSet.append(dataSet[i])
elif type == 2: # type==2對應大于value的情況
for i in range(0,numTotal):
if float(dataSet[i][n]) > value:
subDataSet.append(dataSet[i])
subDataSet = np.array(subDataSet) # 強制轉換為array型別
return subDataSet,len(subDataSet)
####################################################################################################################
#選擇最好的特征劃分資料集,即回傳最佳特征下標及傳入資料集各列的Gini指數
####################################################################################################################
def FindBestFeature(dataSet):
numTotal = dataSet.shape[0] # 記錄本資料集總條數
numFeatures = len(dataSet[0]) - 2 # 計算特征列數
bestFeature = -1 # 初始化引數,記錄最優特征列i,下標從0開始
columnFeaGini={} # 初始化引數,記錄每一列x的每一種特征的基尼 Gini(D,A)
for i in range(1, numFeatures+1): # 遍歷所有x特征列,i為特征標號
featList = list(dataSet[:, i]) # 取這一列x中所有資料,轉換為list型別
featListSort = [float(x) for x in featList]
featListSort.sort() # 對該特征值排序
FeaGinis = []
FeaGiniv = []
for j in range(0,len(featListSort)-1): # j為第幾組資料
value = (featListSort[j]+featListSort[j+1])/2
feaGini = 0.0
subDataSet1,sublen1 = splitDataSet(dataSet, i, value, 1) # 獲取切分后的資料
subDataSet2,sublen2 = splitDataSet(dataSet, i, value, 2)
feaGini = (sublen1/numTotal) * calcGini(subDataSet1) + (sublen2/numTotal) * calcGini(subDataSet2) # 計算此分法對應Gini值
FeaGinis.append(feaGini) # 記錄該特征下各種分法遍歷出的Gini值
FeaGiniv.append(value) # 記錄該特征下的各種分法
columnFeaGini['%d_%f'%(i,FeaGiniv[FeaGinis.index(min(FeaGinis))])] = min(FeaGinis) # 將該特征下最小的Gini值
bestFeature = min(columnFeaGini, key=columnFeaGini.get) # 找到最小的Gini指數對應的資料列
return bestFeature,columnFeaGini
####################################################################################################################
#生成決策樹,輸入:訓練資料集D,特征集A,輸出:決策樹T
####################################################################################################################
def createTree(dataSet, features, decisionTree):
if len(features) > 2: #特征未用完
bestFeature, columnFeaGini = FindBestFeature(dataSet)
bestFeatureLable = features[int(bestFeature.split('_')[0])] # 最佳特征
NodeName = bestFeatureLable + '\n' +'<=' + bestFeature.split('_')[1] #結點名稱
decisionTree = {NodeName: {}} # 構建樹,以Gini指數最小的特征bestFeature為子節點
else:
return decisionTree
LeftSet, LeftSet_len = splitDataSet(dataSet, int(bestFeature.split('_')[0]), float(bestFeature.split('_')[1]), 1)
RightSet, RightSet_len = splitDataSet(dataSet, int(bestFeature.split('_')[0]), float(bestFeature.split('_')[1]), 2)
del (features[int(bestFeature.split('_')[0])]) # 該特征已為子節點使用,則洗掉,以便接下來繼續構建子樹
if calcGini(LeftSet) <= 0.1 or len(features) == 2:
L_lables_grp = dict(Counter(LeftSet[:,-1]))
L_leaf = max(L_lables_grp, key=L_lables_grp.get) # 獲得劃分后出現概率最大的分類作為結點的分類
decisionTree[NodeName]['Y'] = L_leaf # 設定左枝葉子值
elif calcGini(LeftSet) > 0.1:
dataSetNew = np.delete(LeftSet, int(bestFeature.split('_')[0]), axis=1) # 洗掉此最優劃分x列,使用剩余的x列進行資料劃分
L_subFeatures = features[:]
decisionTree[NodeName]['Y'] = {'NONE'}
decisionTree[NodeName]['Y'] = createTree(dataSetNew, L_subFeatures, decisionTree[NodeName]['Y']) #遞回生成左邊的樹
if calcGini(RightSet) <= 0.1 or len(features) == 2:
R_lables_grp = dict(Counter(RightSet[:,-1]))
R_leaf = max(R_lables_grp, key=R_lables_grp.get) # 獲得劃分后出現概率最大的分類作為結點的分類
decisionTree[NodeName]['N'] = R_leaf # 設定右枝葉子值
elif calcGini(RightSet) > 0.1:
dataSetNew = np.delete(RightSet, int(bestFeature.split('_')[0]), axis=1) # 洗掉此最優劃分x列,使用剩余的x列進行資料劃分
R_subFeatures = features[:]
decisionTree[NodeName]['N'] = {'NONE'}
decisionTree[NodeName]['N'] = createTree(dataSetNew, R_subFeatures, decisionTree[NodeName]['N']) #遞回生成右邊的樹
return decisionTree
####################################################################################################################
#獲得測驗結果
####################################################################################################################
def testTree(dataSet):
numTotal = dataSet.shape[0] # 記錄本資料集總條數
testmemory = []
label = dataSet[:,-1]
TP = 0
FP = 0
TN = 0
FN = 0
for i in range(0,numTotal):
if float(dataSet[i][4]) <= 0.001444: #標準差
if float(dataSet[i][1]) <= 0.01022: #均值
if float(dataSet[i][6]) <= -0.589019: #峰度
testmemory.append('0.0')
else:
if float(dataSet[i][3]) <= -0.001811: #四分位差
if float(dataSet[i][2]) <= -0.000026: #中位數
testmemory.append('0.0')
else:
testmemory.append('2.0')
else:
if float(dataSet[i][2]) <= 0.007687: #中位數
if float(dataSet[i][5]) <= 0.452516: #偏度
testmemory.append('0.0')
else:
testmemory.append('0.0')
else:
testmemory.append('2.0')
else:
testmemory.append('2.0')
else:
if float(dataSet[i][3]) <= -0.013691: # 四分位差
testmemory.append('1.0')
else:
if float(dataSet[i][5]) <= 1.462280: #偏度
if float(dataSet[i][6]) <= -1.034223: # 峰度
if float(dataSet[i][1]) <= 0.009173: # 均值
if float(dataSet[i][2]) <= -0.004193: # 中位數
testmemory.append('2.0')
else:
testmemory.append('2.0')
else:
testmemory.append('0.0')
else:
testmemory.append('2.0')
else:
if float(dataSet[i][1]) <= -0.023631: # 均值
testmemory.append('2.0')
else:
testmemory.append('1.0')
for i in range(0, numTotal):
if (testmemory[i] == '1.0') and (label[i] == '1.0'):
TP += 1
elif (testmemory[i] == '1.0') and (label[i] != '1.0'):
FP += 1
elif (testmemory[i] != '1.0') and (label[i] != '1.0'):
TN += 1
elif (testmemory[i] != '1.0') and (label[i] == '1.0'):
FN += 1
print('TP:%d' % TP) #真陽性
print('FP:%d' % FP) #假陽性
print('TN:%d' % TN) #真陰性
print('FN:%d' % FN) #假陰性
cm = confusion_matrix(label, testmemory, labels=["0.0", "1.0", "2.0"])
plt.rc('figure', figsize=(5, 5))
plt.matshow(cm, cmap=plt.cm.cool) # 背景顏色
plt.colorbar() # 顏色標簽
# 內部添加圖例標簽
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x, y], xy=(y, x), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True Label')
plt.xlabel('Predicted Label')
plt.title('decision_tree')
plt.savefig(r'confusion_matrix')
####################################################################################################################
trainingData, testingData= read_xslx(r'e:/Table/機器學習/1109/attribute_113.xlsx')
features = list(trainingData[0]) # x的表頭,即特征
trainingDataSet = trainingData[1:] # 訓練集
bestFeature, columnFeaGini=FindBestFeature(trainingDataSet)
decisionTree = {}
decisiontree = createTree(trainingDataSet, features, decisionTree) # 建立決策樹,CART分類樹
print('CART分類樹:\n', decisiontree)
testTree(testingData)
createPlot(decisiontree)
三、運行結果
CART分類樹:
{‘標準差\n<=0.001444’: {‘Y’: {‘均值\n<=0.010220’: {‘Y’: {‘峰度\n<=-0.589019’: {‘Y’: ‘0.0’, ‘N’: {‘四分位差\n<=-0.001811’: {‘Y’: {‘中位數\n<=-0.000026’: {‘Y’: ‘0.0’, ‘N’: ‘2.0’}}, ‘N’: {‘中位數\n<=0.007687’: {‘Y’: {‘偏度\n<=0.452516’: {‘Y’: ‘0.0’, ‘N’: ‘0.0’}}, ‘N’: ‘2.0’}}}}}}, ‘N’: ‘2.0’}}, ‘N’: {‘四分位差\n<=-0.013691’: {‘Y’: ‘1.0’, ‘N’: {‘偏度\n<=1.462280’: {‘Y’: {‘峰度\n<=-1.034223’: {‘Y’: {‘均值\n<=0.009173’: {‘Y’: {‘中位數\n<=-0.004193’: {‘Y’: ‘2.0’, ‘N’: ‘2.0’}}, ‘N’: ‘0.0’}}, ‘N’: ‘2.0’}}, ‘N’: {‘均值\n<=-0.023631’: {‘Y’: ‘2.0’, ‘N’: ‘1.0’}}}}}}}}
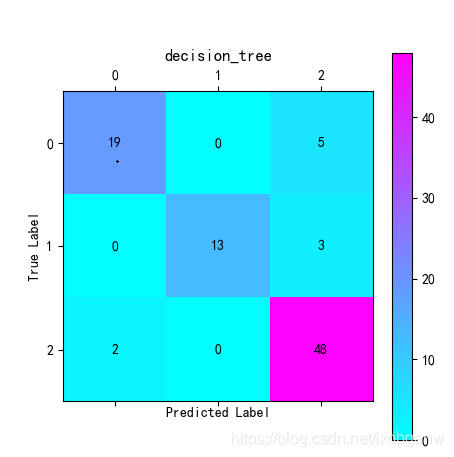
 混淆矩陣:
混淆矩陣:
如果將“1”看做一類,“0”和“2”看做一類,結果為:
TP:13
FP:0
TN:74
FN:3
如果每種標簽都看做一類,則混淆矩陣為:
總結
??用輪子前最好還是先造個輪子感受一下,以上就是CART決策分類樹的全部內容,內容基本上為筆者在BIT的機器學習課程所學,部分思路來自博客https://blog.csdn.net/weixin_43383558/article/details/84303339,本文內容為筆者初學之作,如有錯誤,歡迎評論指點,如有可改進之處,也歡迎討論,轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/224045.html
標籤:其他