本文作者:友盟+技術專家 劉章軍
前言:App推送在日常運營場景中經常用到,如:資訊類的新聞及時下發、生活服務類優惠券精準推送、 電商類的貨品狀態或是促銷優惠等,通常開發者會根據運營的需求通過自建訊息推送通道或使用第三方訊息推送平臺實作,但自建訊息推送的開發成本和人力成本非常高, 很多App開發者選擇第三方訊息推送,今天就以友盟+訊息推送U-Push,詳細解讀在海量業務背景下如何保證服務的穩定性以及功能豐富的觸達服務,
1. 業務背景
友盟+訊息推送U-Push日均訊息下發量百億級,其中篩選任務日均數十萬,篩選設備每分鐘峰值可達7億+,本文將分享友盟+技術架構團隊在長期生產實踐中沉淀的篩選架構解決方案,
如何保證百億級的下發量?
友盟+U-Push篩選是Push產品的核心功能,其中實時篩選是面向推送要求較高的付費Pro用戶提供的核心能力之一,實作了用戶實時打標、篩選、分發、觸達的功能,友盟+U-Push的設備識別以device_token為基準,為保證盡可能的觸達我們留存了近期所有可能觸達客戶的device_token,以10億真實設備為例,每個設備安裝10個集成友盟+SDK的應用可以產生10個device_token,牽扯到硬體環境變動導致的device_token漂移問題,可能產生更多device_token,
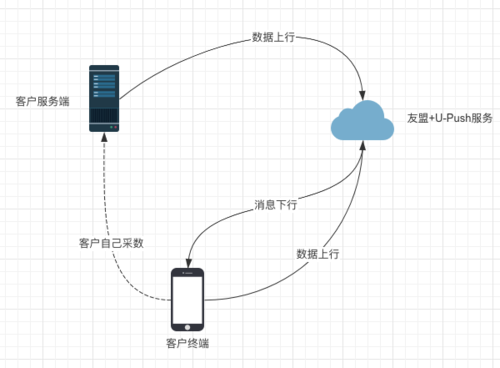
( 圖1.1.1 友盟+U-Push業務資料流簡圖)
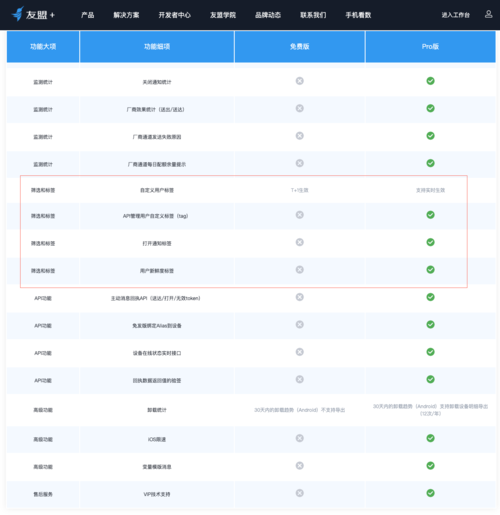
圖1.1.2 友盟+U-Push功能清單
2. U-Push篩選架構概覽
2.1 上下行兩個核心鏈路
U-Push服務由兩個關鍵鏈路組成,下行鏈路保證客戶訊息的觸達,上行鏈路承載終端采數和與客戶服務端的資料同步,其中下行鏈路主要分為任務調度、篩選中心,上行鏈路主要服務是多種收數通道(為兼容歷史問題)和設備中心,上行通過設備中心實作跟下行橋接,
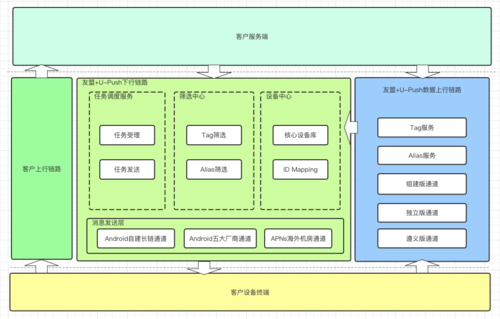
圖2.1.1 友盟+U-Push篩選業務場景
在U-Push服務中,依照業務場景不同定義了多種任務型別,其中除單播、列播直接下發外組播、廣播、自定義播、自定義檔案播均需要通過篩選服務處理后才可執行下發,下行鏈路中(如圖2.1.2)優先級最高是的任務受理和任務發送流程(紅色鏈路),即無論發生什么情況都要保證客戶訊息的正確下發,是U-Push服務穩定性的底線,出于融災考慮,篩選服務在架構上與主鏈路解耦,
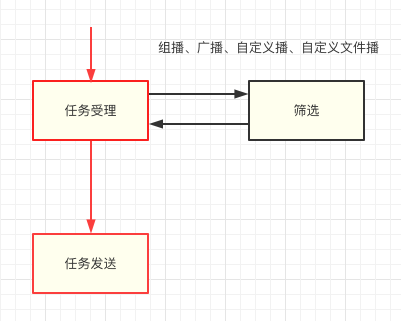
圖2.1.2 篩選和核心鏈路隔離
2.2 資料架構目標和設計
提到篩選,其本質是通過建立合理的標簽索引系統實作資料的快速定位,篩選的目標是U-Push核心設備庫,但是為避免篩選請求影響到核心庫穩定需要將待篩選集合分庫冗余存盤,與一般OLAP,OLTP場景不同,U-Push篩選的應用場景更加苛刻,
1. 不俗的在線任務并發能力
篩選本質還是在線場景,具有一定的并發能力,并發壓力主要在于壓榨系統IO上,通過合理的中間件使用、嚴謹的服務調度、針對性場景的差異化設計降低單次篩選的執行時間,提高并發,
2. 實時海量資料分析和傳輸能力
篩選提供了多種分析維度(圖2.2.2),支持靈活的語法組合,篩選服務不僅要滿足對海量資料的實時查詢分析,還要支持對單次可能破億的結果集做低成本傳輸,

圖2.2.2 篩選支持的欄位型別
3. 成本可控
一切問題都是成本問題,從行業看全民上云后服務架構的成本問題更是備受關注,尤其在友盟+龐大的業務量下成本問題更加重要,
4. 為下游任務并行發送創造條件
友盟+U-Push的發送層集群用于大量的發送節點,最理想的設計就是在任務篩選階段即完成資料切片、分發、調度,下游直接并行發送以達到最高效率,
U-Push篩選在持續的技術迭代中,和多領域專業團隊深度合作,充分利用不同組件的特性,通過整合Tair、AnalyticDB for MySQL(ADS)、OSS、MaxCompute(ODPS)、Lindorm、HBase、SchedulerX等產出了一套兼顧穩定、性能、和成本的均衡解決方案,
篩選分為離線和實時兩部分,離線通過ODPS生成設備主庫快照,匯入ADS,實時通過消費資料上行服務的設備資訊更新事件,實時更新ADS或者RDB庫,在執行篩選時候,對于較大結果集通過upload或者dump到OSS的方式輸出多個小檔案,傳輸給發送鏈路下游執行并行發送,
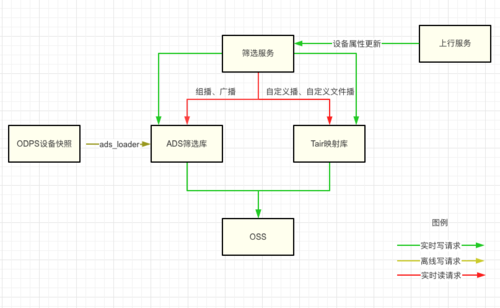
圖2.2.4 篩選服務資料流向
上述業務鏈路和資料結構介紹了篩選目前的整體設計,但是要應付復雜的客情和多變的業務場景還需要做更多細節設計,
3. 設計細節
3.1 篩選庫的場景設計
從上面的概覽可以看出,篩選架構中的主要矛盾就是訊息下行鏈路中海量資料的讀和上行鏈路中設備屬性更新的高頻寫的矛盾,解決這個矛盾需要大量的資源來保證資料一致性和性能,在常規的設計思路中在目前的成本資源下幾乎是不可行,大資料三大寶,冷熱分離分庫分表,通過業務分析調研,U-Push將業務分成若干場景,基于客戶的不同生命周期的業務訴求和服務能力將客戶指向不同場景,盡量優化客戶體驗,
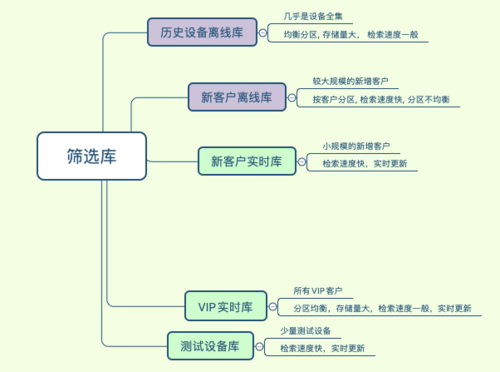
圖3.1.1 篩選庫的場景設計
組播和廣播篩選我們主要圍繞ADS來建設,ADS提供了實時和離線兩種更新方式,在產品形態上只對Pro客戶開放實時篩選能力,在架構設計上通過分庫的方式隔離不同層客戶的資料,提供差異化服務,提高穩定性,
離線部分:通過離線主庫保證了所有客戶的T+1篩選能力,在實際業務中離線主庫只有讀請求作為所有極端場景下的兜底,離線主庫以device_token磁區,可以實作完全打散但是聚合查詢的時候性能稍差,為了提高部分客戶尤其是新客戶的體驗我們設計了新客戶離線庫,修改為客戶磁區,提高了單客戶聚合查詢的效率,但是新客戶離線庫因客戶間的規模差異容易引發磁區傾斜,生產中這個表需要持續關注,及時清理和轉移,否則在跑ads_loader的時候可能破線,
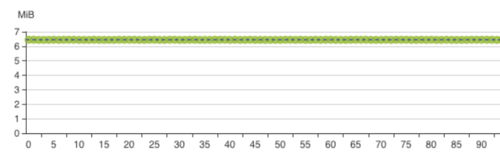
圖3.1.2 離線主庫的磁區狀態
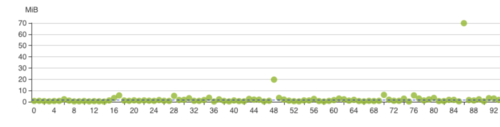
圖3.1.3 以客戶為磁區的磁區傾斜情況
實時部分:保證實時篩選服務體驗是整個系統的重點,將實時篩選再細分為VIP實時庫、測驗設備庫(方便客戶接入階段實時獲取測驗效果)、新客戶實時庫(新增客戶一般設備量很小,U-Push會免費提供一段時間的實時篩選服務),與離線磁區類似,在磁區設計上同樣對大規模場景資料和較少規模場景的資料分表,特別的測驗設備庫可能產生大量臟資料,整體隔離出來,
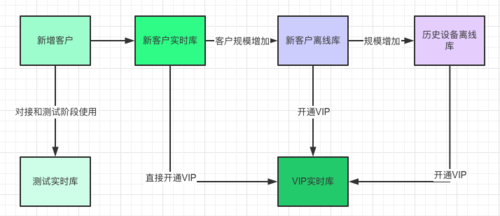
圖3.1.2 客戶場景遷移
新客戶接入伊始基于客戶規模區分,在不同的生命周期節點會被引入特定的場景,在保證大盤能力的前提下盡量輸出更優質的客戶體驗,
3.2 利用OSS傳輸和切分檔案
在上述設計中通過離線和實時的區分,降低了高頻寫可能對設備庫造成的影響,但是始終繞不過海量資料的傳輸問題,為規避這個問題U-Push采用差異化的設計思路,以結果集規模做區分,對大結果集直接通過ADS dump到OSS,基于不同客戶的并行度做遠程切分,在OSS完成upload和split操作后回傳檔案路徑集合,后續鏈路只保留檔案路徑集,直至進入發送層執行并行發送,對小結果集通過select拉取到記憶體整合訊息報文傳輸,后續鏈路直接發送設備ID,通過OSS做中間存盤,極大的降低冗余的IO損耗,
ADS3.0由于整體架構改動改為通過外部表的方式dump到OSS,與2.0可以dump出單個檔案不同3.0在dump后會產生一系列小檔案直接導致原有的方案不可行,在通過和ADS團隊溝通后ADS特地在3.0版本完善了dump單個檔案的功能,致謝ADS的同學,
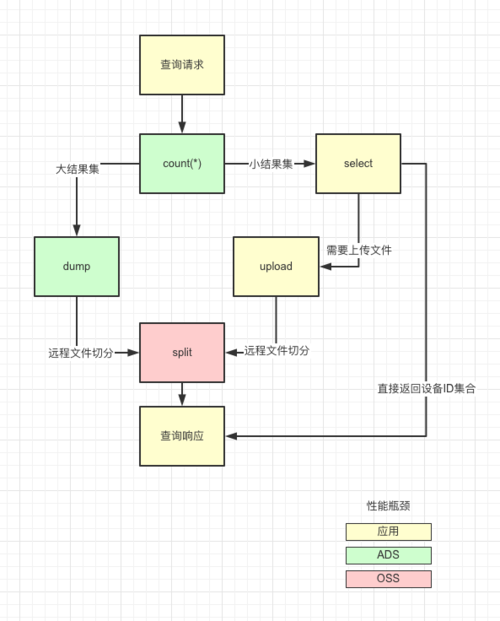
圖3.2.1 篩選查詢中的性能瓶頸風險
3.3 查詢快取和預篩選
談到查詢場景,必然會有快取的一席之地,與一般設計思路不同,U-Push直接放棄了針對實時篩選能力的查詢快取,因為在這樣的設備量級下隨時的設備更新是必然,U-Push的實時篩選庫是一個高頻寫低頻讀的場景,但是對單次讀的要求比較苛刻,首先對未開啟實時功能的離線客戶,因為設備庫是快照形式,一天內的多次讀拿到的結果必然相同這時候設定快取就很有意義,比如新聞、氣象、工具類客戶的習慣,一天內發送多次廣播,就不必每次再去重新生成篩選集檔案,
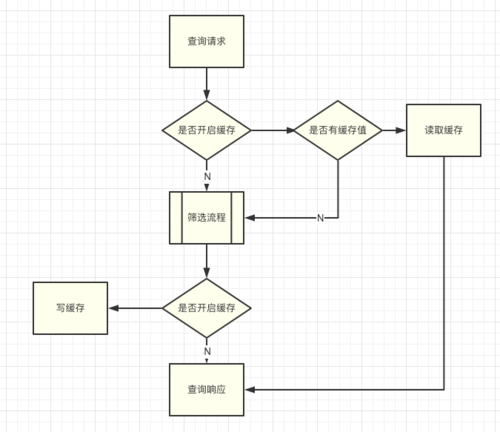
圖3.3.1 查詢快取邏輯流程圖
預篩選功能的開發是個小插曲,前面講到U-Push放棄了對實時的查詢快取,導致客戶的每次訊息發送都要重新去生成檔案,在保證資料實時性的角度考慮無可非議,但是遇到“較真”的客戶就很有壓力,比如新聞類客戶極度關注訊息下發的時效性,通過開發者控制臺可以查看每個任務的篩選時間,有時候同類訊息2s的差異也會引發客戶在DING群的"客訴",客戶的訴求可以理解但是這也耗費了團隊大量的精力,通過和個別客戶溝通U-Push開發了預篩選功能,在客戶習慣性發送訊息的前一段時間預先調度執行篩選邏輯生成設備ID集合,通過損失少量的資料時效性來壓縮訊息下發時間,爭取訊息發送速度,
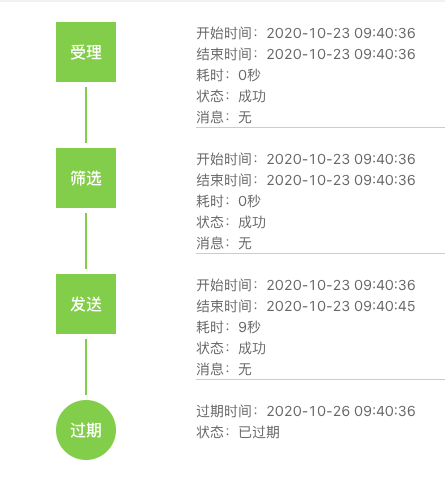
圖3.3.1 友盟+U-Push訊息軌跡
3.4 Alias篩選的優化
篩選請求可以歸類為兩種場景:
-
Alias功能依賴的ID Mapping場景,NvN的設備ID和Alias映射,
-
tag組播和iOS廣播功能的select場景,條件查詢,基于ADS實作,
Alias功能簡介:Alias允許開發者為設備系結別名,別名由alias_type,alias兩個屬性組成,譬如開發者可以標識設備A,為他增加alias_type=telephone_number, alias=13900000000以此來給設備A增加手機號的屬性,在發送訊息時候可以繞開device_token,直接通過服務端指定alias實作觸達,alias是一個典型的NVN ID Mapping場景,一個設備在同一個alias_type下面同時只能擁有一個alias,這也是符合一般業務場景的,比如上例一般一個設備只有一個手機號,設定新手機號后會覆寫原alias,如果需要滿足雙卡雙待的功能,需要設定兩個alias_type,即alias_type=telephone_number_main,alias_type=telephone_number_secondary,alias的一般使用場景是開發者通過自定義檔案播上傳一批檔案,檔案內容為某個alias_type下若干設備alias的集合(百萬千萬級),篩選服務掃描檔案后依次找出alias值mapping的device_token,
3.4.1 Alias的早期設計
說到Mapping,輪詢,高吞吐查詢,首當其沖選Redis,早期的U-Push也是如此,

圖3.5.1 alias早期資料結構設計
alias利用Redis的Set和Hash結構實作正查和反差的功能,為什么反差用hash,前面講到1個設備在1個alias_type下只保存最新的alias,這也是出于保護用戶的目的,如果1個設備同時存在多個alias下,在開發者執行圈選的時候可能會多次選出這個設備造成多次無效觸達,
這個設計平淡無奇,的確也可以滿足絕大部分客戶的篩選場景,但是隨著業務量的增加有幾個問題逐漸暴露
-
輪詢成為海量設備查詢的瓶頸,且不可突破,
-
Redis資料持久化難的問題凸顯,資料分析難上加難,
-
Alias無法很好的滿足資料返還鏈路的需求,
3.4.2 研究Alias的解法
分庫的確是很好的思路但是仍然無法滿足性能問題和持久化問題,而且隨著行業對大資料的關注,資料返還也成為更多開發者的訴求,打通資料返還鏈路做好客戶資料的存、取、管、用已經是一個重要的行業方向,為了解決這個問題U-Push通過離線和實時相結合制定措施
-
分庫,增加KA級別客戶獨享庫,壓縮橫向擴容空間,
-
分層,基于Lindorm做持久化分層存盤,
-
離線留存,通過日志系統留存下行篩選結果,一方面完善統計需求,一方面通過回執返還客戶,
3.4.3 基于Lindorm寬表的分層設計
用寬表代替Redis的Set設計做正查,用普通表基于設備ID的聯合主鍵做反查,在查詢時候通過將單次輪詢改為多次mget盡量壓縮IO損耗尋找回應性能和服務穩定的中間值,Lindorm的磁盤存盤可以滿足業務需求的同時通過exporter的配置實作lindorm資料T+1同步至ODPS,
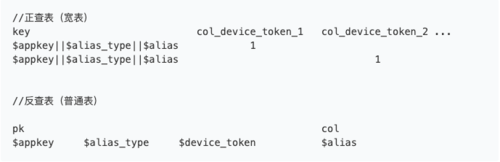
圖3.5.2 基于Lindorm款表的分層設計
3.4.4 資料遷移的嘗試和思考
資料遷移是在很多業務架構中都是痛中之痛,如何保證穩定、平滑、安全的遷移需要付出大量的成本,U-Push在Alias的資料遷移中做了多種方案的研究和思考,
-
Tair整體dump遷移,dump方案理論上可行但是有較大的業務風險,出于穩定性的考慮放棄,
-
寫請求增量更新,通過客戶的寫請求逐key遷移,會有漫長的灰度時間,且無法執行徹底清理,勝在穩定性強,
-
掃描設備主庫,分客戶批次灰度遷移,在U-Push的功能中,提供了appkey下alias_type的功能,客戶可以在開發者控制臺查詢appkey下的alias_type串列,為實作這個功能對appkey和alias_type做了集合索引,這個索引成為資料遷移的關鍵,通過掃描設備庫獲取appkey和device_token,結合alias_type去反查庫查找alias,再拿appkey+alias_type+alias去正查庫查詢device_token串列完成遷移,
第三種方法可以實作存量資料的完美遷移,對線上服務幾乎沒影響,但是在百億級設備下,以1wTPS計算仍然需要10天的時間,好在該方案可以實作單個客戶的灰度與回滾,
5. 結語
U-Push篩選服務只是U-Push眾多服務中的一環,在友盟+巨大的業務量下,為滿足形形色色的各行業需求輸出了大量精致的設計,本文列出的只是冰山一角,日均訊息下發量百億級做到游刃有余離不開其他技術架構團隊在篩選服務迭代中的共同協作,
目前U-Push已經以Push通道為基礎,整合了微信、短信、隱私短信升級為多通道觸達服務,為眾多知名的App如:今日頭條、澎湃新聞、作業幫、易車等提供了觸達能力,后續持續接入支付寶小程式、頭條號等更多運營場景通道,持續為客戶提供穩定、高性能、低成本的觸達能力保證,
友盟+,國內領先的第三方全域資料智能服務商,截至2020年6月已累計為200萬移動應用和890萬家網站提供十年的專業資料服務,
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/246064.html
標籤:其他