文章目錄
- C++輸入流和輸出流(超級詳細)
- C++輸入流和輸出流
- C++ cout.put():輸出單個字符
- C++ cout.write():輸出字串
- C++ cout.tellp()和cout.seekp()方法詳解
- C++ tellp()成員方法
- C++ seekp()成員方法
- C++ cout格式化輸出(超級詳細)
- C++ cout成員方法格式化輸出
- 使用流操縱算子格式化輸出
- C++怎樣對輸入輸出重定向?(3種方法)
- C++ freopen()函式實作重定向
- C++ rdbuf()函式實作重定向
- C++通過控制臺實作重定向
- C++如何管理輸出緩沖區?
- 重繪輸出緩沖區
- unitbuf 運算子
- 警告:如果程式崩潰,輸出緩沖區不會被重繪
- 關聯輸入和輸出流
- cin.get():C++讀取單個字符
- cin.getline():C++讀入一行字串(整行資料)
- C++如何跳過(忽略)指定字符?
- C++怎樣查看輸入流中的下一個字符?
- C++ cin是如何判斷輸入結束(讀取結束)的?
- cin 判斷控制臺(鍵盤)讀取結束
- cin 判斷檔案讀取結束
- 答疑解惑
- C++處理輸入輸出錯誤
- 實體
http://c.biancheng.net/cplus/
C++輸入流和輸出流(超級詳細)
本教程一開始就提到,C++ 又可以稱為“帶類的 C”,即可以理解為 C++ 是 C 語言的基礎上增加了面向物件(類和物件),在此基礎上,學過 C 語言的讀者應該知道,它有一整套完成資料讀寫(I/O)的解決方案:
- 使用 scanf()、gets() 等函式從鍵盤讀取資料,使用 printf()、puts() 等函式向螢屏上輸出資料;
- 使用 fscanf()、fgets() 等函式讀取檔案中的資料,使用 fprintf()、fputs() 等函式向檔案中寫入資料,
要知道,C 語言的這套 I/O 解決方案也適用于 C++ 程式,但 C++ 并沒有“偷懶”,它自己獨立開發了一套全新的 I/O 解決方案,其中就包含大家一直使用的 cin 和 cout,前面章節中,我們一直在用 cin 接收從鍵盤輸入的資料,用 cout 向螢屏上輸出資料(這 2 個程序又統稱為“標準 I/O”),除此之外,C++ 也對從檔案中讀取資料和向檔案中寫入資料做了支持(統稱為“檔案 I/O”),
本質上來說,C++ 的這套 I/O 解決方案就是一個包含很多類的類別庫(作為 C++ 標準庫的組成部分),這些類常被稱為“流類”,
C++ 的開發者認為資料輸入和輸出的程序也是資料傳輸的程序,資料像水一樣從一個地方流動到另一個地方,所以 C++ 中將此程序稱為“流”,實作此程序的類稱為“流類”,
圖 1 展示了 C++ 中用于實作資料輸入和輸出的這些流類以及它們之間的關系:

圖 1 C++類別庫中的流類
其中,圖中的箭頭代表各個類之間的派生關系,比如,ios 是所有流類的基類,它派生出 istream 和 ostream,特別需要指出的是,為了避免多繼承的二義性,從 ios 派生出 istream 和 ostream 時,均使用了 virtual 關鍵字(虛繼承),
圖 1 中這些流類各自的功能分別為:
- istream:常用于接收從鍵盤輸入的資料;
- ostream:常用于將資料輸出到螢屏上;
- ifstream:用于讀取檔案中的資料;
- ofstream:用于向檔案中寫入資料;
- iostream:繼承自 istream 和 ostream 類,因為該類的功能兼兩者于一身,既能用于輸入,也能用于輸出;
- fstream:兼 ifstream 和 ofstream 類功能于一身,既能讀取檔案中的資料,又能向檔案中寫入資料,
本章僅講解實作標準 I/O 操作的 istream、ostream 和 iostream 類,有關實作檔案 I/O 操作的流類放到后續章節講解,
C++輸入流和輸出流
在前面章節的學習中,只要涉及輸入或者輸出資料,我們立馬想到的就是 cin 和 cout,其實,cin 就是 istream 類的物件,cout 是 ostream 類的物件,它們都宣告在 頭檔案中,這也解釋了“為什么在 C++ 程式中引入 就可以使用 cin 和 cout”(當然使用 cin 和 cout,還需要宣告 std 命名空間),
除此之外, 頭檔案中還宣告有 2 個 ostream 類物件,分別為 cerr 和 clog,它們的用法和 cout 完全一樣,但 cerr 常用來輸出警告和錯誤資訊給程式的使用者,clog 常用來輸出程式執行程序中的日志資訊(此部分資訊只有程式開發者看得到,不需要對普通用戶公開),
cout、cerr 和 clog 之間的區別如下:
- cout 除了可以將資料輸出到螢屏上,通過重定向(后續會講),還可以實作將資料輸出到指定檔案中;而 cerr 和 clog 都不支持重定向,它們只能將資料輸出到螢屏上;
- cout 和 clog 都設有緩沖區,即它們在輸出資料時,會先將要資料放到緩沖區,等緩沖區滿或者手動換行(使用換行符 ‘\n’ 或者 endl)時,才會將資料全部顯示到螢屏上;而 cerr 則不設緩沖區,它會直接將資料輸出到螢屏上,
除了以上 2 點特性上的不同之外,cerr、clog 和 cout 沒有任何不同,之所以我們常用 cout,是因為 cerr 和 clog 有各自不同的適用場景,以 cerr 為例,一旦程式某處使用 cerr 輸出資料,我們自然而然地會認為此處輸出的是警告或者錯誤資訊,
值得一提的是,類似 cin、cout、cerr 和 clog 這樣,它們都是 C++ 標準庫的開發者創建好的,可以直接拿來使用,這種在 C++ 中提前創建好的物件稱為內置物件,實際上, 頭檔案中還宣告有處理寬字符的 4 個內置物件,分別為 wcin、wcout、wcerr 以及 wclog,由于不是本節重點,這里不再對它們做詳細講解,
如下程式演示了 cin、cout、cerr 和 clog 的基本用法:
#include <iostream>
#include <string>
int main() {
std::string url;
std::cin >> url;
std::cout << "cout:" << url << std::endl;
std::cerr << "cerr:" << url << std::endl;
std::clog << "clog:" << url << std::endl;
return 0;
}
程式執行結果為:
http://c.biancheng.net
cout:http://c.biancheng.net
cerr:http://c.biancheng.net
clog:http://c.biancheng.net
注意,此程式中并沒有考慮 cerr 和 clog 各自特有的含義,這里僅是為了演示 cerr 和 clog 的基礎用法,不建議讀者這樣使用,另外,如果程式中 std 命名空間提前宣告,則所有的 std:: 可以省略,
它們的用法遠不止此,istream 和 ostream 類提供了很多實用的函式,cin、cout、cerr 和 clog 作為類物件,當然也能呼叫,
表 1 羅列了 cin 物件常用的一些成員方法以及它們的功能:
| 成員方法名 | 功能 |
|---|---|
| getline(str,n,ch) | 從輸入流中接收 n-1 個字符給 str 變數,當遇到指定 ch 字符時會停止讀取,默認情況下 ch 為 ‘\0’, |
| get() | 從輸入流中讀取一個字符,同時該字符會從輸入流中消失, |
| gcount() | 回傳上次從輸入流提取出的字符個數,該函式常和 get()、getline()、ignore()、peek()、read()、readsome()、putback() 和 unget() 聯用, |
| peek() | 回傳輸入流中的第一個字符,但并不是提取該字符, |
| putback? | 將字符 c 置入輸入流(緩沖區), |
| ignore(n,ch) | 從輸入流中逐個提取字符,但提取出的字符被忽略,不被使用,直至提取出 n 個字符,或者當前讀取的字符為 ch, |
| operator>> | 多載 >> 運算子,用于讀取指定型別的資料,并回傳輸入流物件本身, |
表 2 羅列了 cout、cerr 和 clog 物件常用的一些成員方法以及它們的功能:
| 成員方法名 | 功能 |
|---|---|
| put() | 輸出單個字符, |
| write() | 輸出指定的字串, |
| tellp() | 用于獲取當前輸出流指標的位置, |
| seekp() | 設定輸出流指標的位置, |
| flush() | 重繪輸出流緩沖區, |
| operator<< | 多載 << 運算子,使其用于輸出其后指定型別的資料, |
舉個例子:
#include <iostream>
using namespace std;
int main() {
char url[30] = {0};
//讀取一行字串
cin.getline(url, 30);
//輸出上一條陳述句讀取字串的個數
cout << "讀取了 "<<cin.gcount()<<" 個字符" << endl;
//輸出 url 陣列存盤的字串
cout.write(url, 30);
return 0;
}
程式執行結果為:
http://c.biancheng.net
讀取了 23 個字符
http://c.biancheng.net
注意,表 1 和表 2 中僅羅列了 istream 和 ostream 類中常用的一些成員方法,關于這些方法的具體用法,后續章節會做詳細介紹,
C++ cout.put():輸出單個字符
通過前面的學習我們知道,C++ 程式中一般用 ostream 類的 cout 輸出流物件和 << 輸出運算子實作輸出,并且 cout 輸出流在記憶體中有相應的緩沖區,但有時用戶還有特殊的輸出需求,例如只輸出一個字符,這種情況下可以借助該類提供的 put() 成員方法實作,
put() 方法專用于向輸出流緩沖區中添加單個字符,其語法格式如下:
ostream&put(char c);
其中,引數 c 為要輸出的字符,
可以看到,該函式會回傳一個 ostream 類的參考物件,可以理解回傳的是 cout 的參考,這意味著,我們可以像下面這樣使用 put() 函式:
cout.put(c1).put(c2).put(c3);
因為 cout.put(c1) 向輸出流緩沖區中添加 c1 字符的同時,回傳一個參考形式的 cout 物件,所以可以繼續用此物件呼叫 put(c2),依次類推,
【實體1】輸出單個字符 a,
cout.put(‘a’);
呼叫該方法的結果是在螢屏上顯示一個字符 a,
【實體2】put() 函式的引數可以是字符或字符的 ASCII 代碼(也可以是一個整型運算式),
cout.put(65 + 32);
cout.put(97);
上面兩行代碼都輸出字符 a,因為 97 是字符 a 的 ASCII 代碼,
【實體3】可以在一個陳述句中連續呼叫 put() 函式,例如:
cout.put(71).put(79).put(79). put(68).put(’\n’);
在螢屏上顯示GOOD,
【實體4】有一個字串 “ten.gnehcnaib.c//:ptth”,要求把它們按相反的順序輸出,
#include <iostream>
#include <string>
using namespace std;
int main(){
string str = "ten.gnehcnaib.c//:ptth";
for (int i = str.length() - 1; i >= 0; i--) {
cout.put(str[i]); //從最后一個字符開始輸出
}
cout.put('\n');
return 0;
}
運行結果:
http://c.biancheng.net
除了使用 cout.put() 函式輸出一個字符外,還可以用 putchar() 函式輸出一個字符,putchar() 函式是C語言中使用的,在 <stdio.h> 頭檔案中定義,C++保留了這個函式,在 頭檔案中定義,
C++ cout.write():輸出字串
《C++ cout.put()》一節中,講解了 ostream 類提供的 put() 成員方法的用法,其用于向輸出流緩沖區中添加要輸出的單個字符,而在某些場景中,我們還需要輸出指定的字串,這時可以使用 ostream 類提供的 write() 成員方法,
write() 成員方法專用于向輸出流緩沖區中添加指定的字串,初學者可以簡單的理解為輸出指定的字串,其語法格式如下:
ostream&write(const char * s,streamsize n);
其中,s 用于指定某個長度至少為 n 的字符陣列或字串;n 表示要輸出的前 n 個字符,
可以看到,該函式會回傳一個 ostream 類的參考物件,可以理解回傳的是 cout 的參考,這意味著,我們可以像下面這樣使用 write() 方法:
cout.write(c1, 1).write(c2, 2).write(c3, 3);
因為 cout.write(c1, 1) 向輸出流緩沖區中添加 c1 字串中第 1 字符的同時,會回傳一個參考形式的 cout 物件,所以可以繼續用此物件呼叫 write(c2, 2),向輸出流緩沖區添加 c2 字串中前 2 個字符,依次類推,
【例 1】輸出 “http://c.biancheng.net/cplus/” 字串中前 4 個字符,
#include <iostream>
using namespace std;
int main() {
const char * str = "http://c.biancheng.net/cplus/";
cout.write(str, 4);
return 0;
}
程式執行結果為:
http
【例 2】連續使用 write() 方法,
#include <iostream>
using namespace std;
int main() {
cout.write("http://", 7).write("c.biancheng.net", 15).write("/cplus/", 7);
return 0;
}
程式執行結果為:
http://c.biancheng.net/cplus/
C++ cout.tellp()和cout.seekp()方法詳解
通過前面章節的學習我們知道,無論是使用 cout 輸出普通資料,用 cout.put() 輸出指定字符,還是用 cout.write() 輸出指定字串,資料都會先放到輸出流緩沖區,待緩沖區重繪,資料才會輸出到指定位置(螢屏或者檔案中),
值得一提的是,當資料暫存于輸出流緩沖區中時,我們仍可以對其進行修改,ostream 類中提供有 tellp() 和 seekp() 成員方法,借助它們就可以修改位于輸出流緩沖區中的資料,
C++ tellp()成員方法
首先,tellp() 成員方法用于獲取當前輸出流緩沖區中最后一個字符所在的位置,其語法格式如下:
streampos tellp();
顯然,tellp() 不需要傳遞任何引數,會回傳一個 streampos 型別值,事實上,streampos 是 fpos 型別的別名,而 fpos 通過自動型別轉換,可以直接賦值給一個整形變數(即 short、int 和 long),也就是說,在使用此函式時,我們可以用一個整形變數來接收該函式的回傳值,
注意,當輸出流緩沖區中沒有任何資料時,該函式回傳的整形值為 0;當指定的輸出流緩沖區不支持此操作,或者操作失敗時,該函式回傳的整形值為 -1,
在下面的樣例中,實作了借助 cout.put() 方法向 test.txt 檔案中寫入指定字符,由于此程序中字符會先存入輸出流緩沖區,所以借助 tellp() 方法,我們可以實時監控新存入緩沖區中字符的位置,
舉個例子:
#include <iostream> //cin 和 cout
#include <fstream> //檔案輸入輸出流
int main() {
//定義一個檔案輸出流物件
std::ofstream outfile;
//打開 test.txt,等待接收資料
outfile.open("test.txt");
const char * str = "http://c.biancheng.net/cplus/";
//將 str 字串中的字符逐個輸出到 test.txt 檔案中,每個字符都會暫時存在輸出流緩沖區中
for (int i = 0; i < strlen(str); i++) {
outfile.put(str[i]);
//獲取當前輸出流
long pos = outfile.tellp();
std::cout << pos << std::endl;
}
//關閉檔案之前,重繪 outfile 輸出流緩沖區,使所有字符由緩沖區流入test.txt檔案
outfile.close();
return 0;
}
注意,此例中涉及到了檔案操作的相關知識,初學者僅需借助注釋了解程式的執行脈絡即可,不需要研究具體實作細節,有關檔案操作,后續章節會做詳細講解,
讀者可自行運行此程式,其輸出結果為 1~29,這意味著,程式中每次向輸出流緩沖區中放入字符時,pos 都表示的是當前字符的位置,比如,當將 str 全部放入緩沖區中時,pos 值為 29,表示的是最后一個字符 ‘/’ 位于第 29 個位置處,
C++ seekp()成員方法
seekp() 方法用于指定下一個進入輸出緩沖區的字符所在的位置,
舉個例子,假設當前輸出緩沖區中存有如下資料:
http://c.biancheng.net/cplus/
借助 tellp() 方法得知,最后一個 ‘/’ 字符所在的位置是 29,此時如果繼續向緩沖區中存入資料,則下一個字符所在的位置應該是 30,但借助 seekp() 方法,我們可以手動指定下一個字符存放的位置,
比如通過 seekp() 指定下一個字符所在的位置為 23,即對應 “cplus/” 部分中字符 ‘c’ 所在的位置,此時若再向緩沖區中存入 “python/”,則緩沖區中存盤的資料就變成了:
http://c.biancheng.net/python/
顯然,新的 “python/” 覆寫了原來的 “cplus/”,
seekp() 方法有如下 2 種語法格式:
//指定下一個字符存盤的位置
ostream& seekp (streampos pos);
//通過偏移量間接指定下一個字符的存盤位置
ostream& seekp (streamoff off, ios_base::seekdir way);
其中,各個引數的含義如下:
- pos:用于接收一個正整數;、
- off:用于指定相對于 way 位置的偏移量,其本質也是接收一個整數,可以是正數(代表正偏移)或者負數(代表負偏移);
- way:用于指定偏移位置,即從哪里計算偏移量,它可以接收表 1 所示的 3 個值,
| 模式標志 | 描 述 |
|---|---|
| ios::beg | 從檔案頭開始計算偏移量 |
| ios::end | 從檔案末尾開始計算偏移量 |
| ios::cur | 從當前位置開始計算偏移量 |
同時,seekp() 方法會回傳一個參考形式的 ostream 類物件,這意味著 seekp() 方法可以這樣使用:
cout.seekp(23) << "當前位置為:" << cout.tellp();
舉個例子:
#include <iostream> //cin 和 cout
#include <fstream> //檔案輸入輸出流
using namespace std;
int main() {
//定義一個檔案輸出流物件
ofstream outfile;
//打開 test.txt,等待接收資料
outfile.open("test.txt");
const char * str = "http://c.biancheng.net/cplus/";
//將 str 字串中的字符逐個輸出到 test.txt 檔案中,每個字符都會暫時存在輸出流緩沖區中
for (int i = 0; i < strlen(str); i++) {
outfile.put(str[i]);
//獲取當前輸出流
}
cout << "當前位置為:" << outfile.tellp() << endl;
//調整新進入緩沖區字符的存盤位置
outfile.seekp(23); //等價于:
//outfile.seekp(23, ios::beg);
//outfile.seekp(-6, ios::cur);
//outfile.seekp(-6, ios::end);
cout << "新插入位置為:" << outfile.tellp() << endl;
const char* newstr = "python/";
outfile.write("python/", 7);
//關閉檔案之前,重繪 outfile 輸出流緩沖區,使所有字符由緩沖區流入test.txt檔案
outfile.close();
return 0;
}
讀者可自行執行此程式,會發現最終 test.txt 檔案中存盤的為 “http://c.biancheng.net/python/”,
C++ cout格式化輸出(超級詳細)
在某些實際場景中,我們經常需要按照一定的格式輸出資料,比如輸出浮點數時保留 2 位小數,再比如以十六進制的形式輸出整數,等等,
對于學過 C 語言的讀者應該知道,當使用 printf() 函式輸出資料時,可以通過設定一些合理的格式控制符,來達到以指定格式輸出資料的目的,例如 %.2f 表示輸出浮點數時保留 2 位小數,%#X 表示以十六進制、帶 0X 前綴的方式輸出整數,
關于 printf() 函式支持的格式控制符,更詳細的講解,可閱讀《C語言資料輸出大匯總》一節,這里不做詳細贅述,
C++ 通常使用 cout 輸出資料,和 printf() 函式相比,cout 實作格式化輸出資料的方式更加多樣化,一方面,cout 作為 ostream 類的物件,該類中提供有一些成員方法,可實作對輸出資料的格式化;另一方面,為了方面用戶格式化輸出資料,C++ 標準庫專門提供了一個 頭檔案,該頭檔案中包含有大量的格式控制符(嚴格意義上稱為“流操縱算子”),使用更加方便,
C++ cout成員方法格式化輸出
《C++輸入流和輸出流》一節中,已經針對 cout 講解了一些常用成員方法的用法,除此之外,ostream 類中還包含一些可實作格式化輸出的成員方法,這些成員方法都是從 ios 基類(以及 ios_base 類)中繼承來的,cout(以及 cerr、clog)也能呼叫,
表 1 羅列了 ostream 類中可實作格式化輸出的常用成員方法,以及它們各自的用法,
| 成員函式 | 說明 |
|---|---|
| flags(fmtfl) | 當前格式狀態全部替換為 fmtfl,注意,fmtfl 可以表示一種格式,也可以表示多種格式, |
| precision(n) | 設定輸出浮點數的精度為 n, |
| width(w) | 指定輸出寬度為 w 個字符, |
| fill? | 在指定輸出寬度的情況下,輸出的寬度不足時用字符 c 填充(默認情況是用空格填充), |
| setf(fmtfl, mask) | 在當前格式的基礎上,追加 fmtfl 格式,并洗掉 mask 格式,其中,mask 引數可以省略, |
| unsetf(mask) | 在當前格式的基礎上,洗掉 mask 格式, |
其中,對于表 1 中 flags() 函式的 fmtfl 引數、setf() 函式中的 fmtfl 引數和 mask 引數以及 unsetf() 函式 mask 引數,可以選擇表 2 中列出的這些值,
| 標 志 | 作 用 |
|---|---|
| ios::boolapha | 把 true 和 false 輸出為字串 |
| ios::left | 輸出資料在本域寬范圍內向左對齊 |
| ios::right | 輸出資料在本域寬范圍內向右對齊 |
| ios::internal | 數值的符號位在域寬內左對齊,數值右對齊,中間由填充字符填充 |
| ios::dec | 設定整數的基數為 10 |
| ios::oct | 設定整數的基數為 8 |
| ios::hex | 設定整數的基數為 16 |
| ios::showbase | 強制輸出整數的基數(八進制數以 0 開頭,十六進制數以 0x 打頭) |
| ios::showpoint | 強制輸出浮點數的小點和尾數 0 |
| ios::uppercase | 在以科學記數法格式 E 和以十六進制輸出字母時以大寫表示 |
| ios::showpos | 對正數顯示“+”號 |
| ios::scientific | 浮點數以科學記數法格式輸出 |
| ios::fixed | 浮點數以定點格式(小數形式)輸出 |
| ios::unitbuf | 每次輸出之后重繪所有的流 |
舉個例子:
#include <iostream>
using namespace std;
int main()
{
double a = 1.23;
//設定后續輸出的浮點數的精度為 4
cout.precision(4);
cout <<"precision: "<< a << endl;
//設定后續以科學計數法的方式輸出浮點數
cout.setf(ios::scientific);
cout <<"scientific:"<< a << endl;
return 0;
}
程式執行結果為:
precision: 1.23
scientific:1.2300e+00
注意,當 cout 采用此方式進行格式化輸出時,其后不能立即輸出資料,而只能像示例程式中那樣,再用一個 cout 輸出資料,
值得一提的是,當呼叫 unsetf() 或者 2 個引數的 setf() 函式時,為了提高撰寫代碼的效率,可以給 mask 引數傳遞如下 3 個組合格式:
- ios::adjustfield:等價于 ios::left | ios::right | ios::internal;
- ios::basefield:等價于 ios::dec | ios::oct | ios::hex;
- ios::floatfield:等價于 ios::scientific | ios::fixed,
舉個例子:
#include <iostream>
using namespace std;
int main()
{
double f = 123;
//設定后續以科學計數法表示浮點數
cout.setf(ios::scientific);
cout << f << '\n';
//洗掉之前有關浮點表示的設定
cout.unsetf(ios::floatfield);
cout << f;
return 0;
}
程式執行結果為:
1.230000e+02
123
使用流操縱算子格式化輸出
表 3 羅列了 頭檔案中定義的一些常用的格式控制符,它們都可用于格式化輸出,
| 流操縱算子 | 作 用 | |
|---|---|---|
| *dec | 以十進制形式輸出整數 | 常用 |
| hex | 以十六進制形式輸出整數 | |
| oct | 以八進制形式輸出整數 | |
| fixed | 以普通小數形式輸出浮點數 | |
| scientific | 以科學計數法形式輸出浮點數 | |
| left | 左對齊,即在寬度不足時將填充字符添加到右邊 | |
| *right | 右對齊,即在寬度不足時將填充字符添加到左邊 | |
| setbase(b) | 設定輸出整數時的進制,b=8、10 或 16 | |
| setw(w) | 指定輸出寬度為 w 個字符,或輸入字串時讀入 w 個字符,注意,該函式所起的作用是一次性的,即只影響下一次 cout 輸出, | |
| setfill? | 在指定輸出寬度的情況下,輸出的寬度不足時用字符 c 填充(默認情況是用空格填充) | |
| setprecision(n) | 設定輸出浮點數的精度為 n, 在使用非 fixed 且非 scientific 方式輸出的情況下,n 即為有效數字最多的位數,如果有效數字位數超過 n,則小數部分四舍五人,或自動變為科學計 數法輸出并保留一共 n 位有效數字, 在使用 fixed 方式和 scientific 方式輸出的情況下,n 是小數點后面應保留的位數, | |
| setiosflags(mask) | 在當前格式狀態下,追加 mask 格式,mask 引數可選擇表 2 中的所有值, | |
| resetiosflags(mask) | 在當前格式狀態下,洗掉 mask 格式,mask 引數可選擇表 2 中的所有值, | |
| boolapha | 把 true 和 false 輸出為字串 | 不常用 |
| *noboolalpha | 把 true 和 false 輸出為 0、1 | |
| showbase | 輸出表示數值的進制的前綴 | |
| *noshowbase | 不輸出表示數值的進制.的前綴 | |
| showpoint | 總是輸出小數點 | |
| *noshowpoint | 只有當小數部分存在時才顯示小數點 | |
| showpos | 在非負數值中顯示 + | |
| *noshowpos | 在非負數值中不顯示 + | |
| uppercase | 十六進制數中使用 A~E,若輸出前綴,則前綴輸出 0X,科學計數法中輸出 E | |
| *nouppercase | 十六進制數中使用 a~e,若輸出前綴,則前綴輸出 0x,科學計數法中輸出 e, | |
| internal | 數值的符號(正負號)在指定寬度內左對齊,數值右對 齊,中間由填充字符填充, |
注意:“流操縱算子”一欄帶有星號 * 的格式控制符,默認情況下就會使用,例如在默認情況下,整數是用十進制形式輸出的,等效于使用了 dec 格式控制符,
和 cout 成員方法的用法不同,下面程式演示了表 3 中這些格式控制符的用法:
#include <iostream>
#include <iomanip>
using namespace std;
int main()
{
//以十六進制輸出整數
cout << hex << 16 << endl;
//洗掉之前設定的進制格式,以默認的 10 進制輸出整數
cout << resetiosflags(ios::basefield)<< 16 << endl;
double a = 123;
//以科學計數法的方式輸出浮點數
cout << scientific << a << endl;
//洗掉之前設定的科學計數法的方法
cout << resetiosflags(ios::scientific) << a << endl;
return 0;
}
程式執行結果為:
10
16
1.230000e+02
123
注意,如果兩個相互矛盾的標志同時被設定,如先設定 setiosflags(ios::fixed),然后又設定 setiosflags(ios::scientific),那么結果可能就是兩個標志都不起作用,因此,在設定了某標志,又要設定其他與之矛盾的標志時,就應該用 resetiosflags 清除原先的標志,
C++怎樣對輸入輸出重定向?(3種方法)
《C++輸入流和輸出流》一節提到,cout 和 cerr、clog 的一個區別是,cout 允許被重定向,而 cerr 和 clog 都不支持,值得一提的是,cin 也允許被重定向,
那么,什么是重定向呢?在默認情況下,cin 只能接收從鍵盤輸入的資料,cout 也只能將資料輸出到螢屏上,但通過重定向,cin 可以將指定檔案作為輸入源,即接收檔案中早已準備好的資料,同樣 cout 可以將原本要輸出到螢屏上的資料轉而寫到指定檔案中,
C++ 中,實作重定向的常用方式有 3 種,本節將一一做詳細講解,
C++ freopen()函式實作重定向
freopen() 定義在<stdio.h>頭檔案中,是 C 語言標準庫中的函式,專門用于重定向輸入流(包括 scanf()、gets() 等)和輸出流(包括 printf()、puts() 等),值得一提的是,該函式也可以對 C++ 中的 cin 和 cout 進行重定向,
舉個例子:
#include <iostream> //cin、cout
#include <string> //string
#include <stdio.h> //freopen
using namespace std;
int main()
{
string name, url;
//將標準輸入流重定向到 in.txt 檔案
freopen("in.txt", "r", stdin);
cin >> name >> url;
//將標準輸出重定向到 out.txt檔案
freopen("out.txt", "w", stdout);
cout << name << "\n" << url;
return 0;
}
執行此程式之前,我們需要找到當前程式檔案所在的目錄,并手動創建一個 in.txt 檔案,其包含的內容如下:
C++
http://c.biancheng.net/cplus/
創建好 in.txt 檔案之后,可以執行此程式,其執行結果為:
<–控制臺中,既不需要手動輸入,也沒有任何輸出
與此同時,in.txt 檔案所在目錄下會自動生成一個 out.txt 檔案,其包含的內容和 in.txt 檔案相同:
C++
http://c.biancheng.net/cplus/
顯然,通過 2 次呼叫 freopen() 函式,分別對輸入流和輸出流重定向,使得 cin 不再接收由鍵盤輸入的資料,而是直接從 in.txt 檔案中獲取資料;同樣,cout 也不再將資料輸出到螢屏上,而是寫入到 out.txt 檔案中,
C++ rdbuf()函式實作重定向
rdbuf() 函式定義在<ios>頭檔案中,專門用于實作 C++ 輸入輸出流的重定向,
值得一提的是,ios 作為 istream 和 ostream 類的基類,rdbuf() 函式也被繼承,因此 cin 和 cout 可以直接呼叫該函式實作重定向,
rdbuf() 函式的語法格式有 2 種,分別為:
streambuf * rdbuf() const;
streambuf * rdbuf(streambuf * sb);
streambuf 是 C++ 標準庫中用于表示緩沖區的類,該類的指標物件用于代指某個具體的流緩沖區,
其中,第一種語法格式僅是回傳一個指向當前流緩沖區的指標;第二種語法格式用于將 sb 指向的緩沖區設定為當前流的新緩沖區,并回傳一個指向舊緩沖區的物件,
舉個例子:
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
//打開 in.txt 檔案,等待讀取
ifstream fin("in.txt");
//打開 out.txt 檔案,等待寫入
ofstream fout("out.txt");
streambuf *oldcin;
streambuf *oldcout;
char a[100];
//用 rdbuf() 重新定向,回傳舊輸入流緩沖區指標
oldcin = cin.rdbuf(fin.rdbuf());
//從input.txt檔案讀入
cin >> a;
//用 rdbuf() 重新定向,回傳舊輸出流緩沖區指標
oldcout = cout.rdbuf(fout.rdbuf());
//寫入 out.txt
cout << a << endl;
//還原標準輸入輸出流
cin.rdbuf(oldcin); // 恢復鍵盤輸入
cout.rdbuf(oldcout); //恢復螢屏輸出
//打開的檔案,最終需要手動關閉
fin.close();
fout.close();
return 0;
}
程式中涉及到的檔案操作,后續章節會做詳細講解,讀者只需領悟 rdbuf() 函式的用法即可,
仍以前面創建好的 in.txt 檔案為例,執行此程式后,控制臺不會輸出任何資料,而是會在該專案的目錄下生成一個 out.txt 檔案,其中就存有該程式的執行結果:
C++
http://c.biancheng.net/cplus/
C++通過控制臺實作重定向
以上 2 種方法,都是從代碼層面實作輸入輸出流的重定向,除此之外,我們還可以通過控制臺實作輸入輸出的重定向,
舉個例子,假設有如下代碼(檔案名為 demo.cpp):
#include <iostream>
#include <string>
using namespace std;
int main()
{
string name, url;
cin >> name >> url;
cout << name << '\n' << url;
return 0;
}
通過編譯、鏈接后,會生成一個 demo.exe 可執行檔案,該執行檔案可以雙擊執行,也可以在控制臺上執行,例如,打開控制臺(Windows 系統下指的是 CMD命令列視窗,Linux 系統下指的是 Shell 終端),并輸入如下指令:
C:\Users\mengma>D:\demo.exe
C++ http://c.biancheng.net/cplus/
C++
http://c.biancheng.net/cplus/
可以看到,demo.ext 成功被執行,但程式中的 cin 和 cout 并沒有被重定向,因此這里仍需要我們手動輸入測驗資料,
在此基礎上,繼續在控制臺執行如下指令:
C:\Users\mengma>D:\demo.exe <in.txt >out.txt
需要注意的是,執行此命令前,需保證 C:\Users\mengma 目錄下有 in.txt 檔案,
執行后會發現,控制臺沒有任何輸出,這是因為,我們使用了"<in.txt"對程式中的 cin 輸入流做了重定向,同時還用 ">out.txt"對程式中的 cout 輸出流做了重定向,
如果此時讀者進入 C:\Users\mengma 目錄就會發現,當前目錄生成了一個 out.txt 檔案,其中就存盤了 demo.ext 的執行結果,
在控制臺中使用 > 或者 < 實作重定向的方式,DOS、windows、Linux 以及 UNIX 都能自動識別,
C++如何管理輸出緩沖區?
每個輸出流都管理一個緩沖區,用來保存程式讀寫的資料,例如,如果執行下而的代碼:
cout << “http://c.biancheng.net/cplus/”;
文本串可能立即列印出來,但也有可能被作業系統保存在緩沖區中,隨后再列印,
有了緩沖機制,作業系統就可以將程式的多個輸出操作組合成單一的系統級寫操作,由于設備的寫操作可能很耗時,允許作業系統將多個輸出操作組合為單一的設備寫操作可以帶來很大的性能提升,
導致緩沖重繪(資料真正寫到輸出設備或檔案)的原因有很多:
- 程式正常結束,作為 main() 函式的 return 操作的一部分,緩沖重繪被執行,
- 緩沖區滿時,需要重繪緩沖,而后新的資料才能繼續寫入緩沖區,
- 我們可以使用操縱符如 endl 來顯式重繪緩沖區,
- 在每個輸出操作之后,我們可以用運算子 unitbuf 設定流的內部狀態,來清慷訓沖區,默認情況下,對 cerr 是設定 unitbuf 的,因此寫到 cerr 的內容都是立即重繪的,
- 一個輸出流可能被關聯到另一個流,在這種情況下,當讀寫被關聯的流時,關聯到的流的緩沖區會被重繪,例如,默認情況下,cin 和 cerr 都關聯到 cout,因此,讀 cin 或寫 cerr 都會導致 cout 的緩沖區被重繪,
重繪輸出緩沖區
我們已經使用過運算子 endl,它完成換行并重繪緩沖區的作業,IO 庫中還有兩個類似的操縱符:
- flush 和 ends,flush 重繪緩沖區,但不輸出任何額外的字符;
- ends向緩沖區插入一個空字符,然后重繪緩沖區,
值得一提得是,cout 所屬 ostream 類中還提供有 flush() 成員方法,它和 flush 操縱符的功能完全一樣,僅在使用方法上( cout.flush() )有區別,
請看下面的例子:
cout << "hi!" << endl; //輸出hi和一個換行,然后重繪緩沖區
cout << "hi!" << flush; //輸出hi,然后重繪緩沖區,不附加任何額外字符
cout << "hi!" << ends; //輸出hi和一個空字符,然后重繪緩沖區
unitbuf 運算子
如果想在每次輸出操作后都重繪緩沖區,我們可以使用 unitbuf 運算子,它告訴流在接下來的每次寫操作之后都進行一次 flush 操作,而 nounitbuf 運算子則重置流, 使其恢復使用正常的系統管理的緩沖區重繪機制:
cout << unitbuf; //所有輸出操作后都會立即重繪緩沖區
//任何輸出都立即重繪,無緩沖
cout << nounitbuf; //回到正常的緩沖方式
警告:如果程式崩潰,輸出緩沖區不會被重繪
如果程式例外終止,輸出緩沖區是不會被重繪的,當一個程式崩潰后,它所輸出的資料很可能停留在輸出緩沖區中等待列印,
當除錯一個已經崩潰的程式時,需要確認那些你認為已經輸出的資料確實已經重繪了,否則,可能將大量時間浪費在追蹤代碼為什么沒有執行上,而實際上代碼已經執行了,只是程式崩潰后緩沖區沒有被重繪,輸出資料被掛起沒有列印而已,
關聯輸入和輸出流
當一個輸入流被關聯到一個輸出流時,任何試圖從輸入流讀取資料的操作都會先重繪關聯的輸出流,標準庫將 cout 和 cin 關聯在一起,因此下面陳述句:
cin >> ival;
導致 cout 的緩沖區被重繪,
互動式系統通常應該關聯輸入流和輸出流,這意味著所有輸出,包括用戶提示資訊,都會在讀操作之前被列印出來,
tie() 函式可以用來系結輸出流,它有兩個多載的版本:
ostream* tie ( ) const; //回傳指向系結的輸出流的指標,
ostream* tie ( ostream* os ); //將 os 指向的輸出流系結的該物件上,并回傳上一個系結的輸出流指標,
第一個版本不帶引數,返冋指向出流的指標,如果本物件當前關聯到一個輸出流,則回傳的就是指向這個流的指標,如果物件未關聯到流,則回傳空指標,
tie() 的第二個版本接受一個指向 ostream 的指標,將自己關聯到此 ostream,即,x.tie(&o) 將流 x 關聯到輸出流 o,
我們既可以將一個 istream 物件關聯到另一個 ostream,也可以將一個 ostream 關聯到另一個 ostream:
cin.tie(&cout); //僅僅是用來展示,標準庫已經將 cin 和 cout 關聯在一起
//old_tie 指向當前關聯到 cin 的流(如果有的話)
ostream *old_tie = cin.tie(nullptr); // cin 不再與其他流關聯
//將 cin 與 cerr 關聯,這不是一個好主意,因為 cin 應該關聯到 cout
cin.tie(&cerr); //讀取 cin 會重繪 cerr 而不是 cout
cin.tie(old_tie); //重建 cin 和 cout 間的正常關聯
在這段代碼中,為了將一個給定的流關聯到一個新的輸出流,我們將新流的指標傳遞給了 tie(),為了徹底解開流的關聯,我們傳遞了一個空指標,每個流同時最多關聯到一個流, 但多個流可以同時關聯到同一個ostream,
cin.get():C++讀取單個字符
get() 是 istream 類的成員函式,它有多種多載形式(請猛擊這里了解詳情),不過本文只介紹最簡單最常用的一種:
int get();
此函式從輸入流中讀入一個字符,回傳值就是該字符的 ASCII 碼,如果碰到輸入的末尾,則回傳值為 EOF,
EOF 是 End of File 的縮寫,istream 類中從輸入流(包括檔案)中讀取資料的成員函式,在把輸入資料都讀取完后再進行讀取,就會回傳 EOF,EOF 是在 iostream 類中定義的一個整型常量,值為 -1,
get() 函式不會跳過空格、制表符、回車等特殊字符,所有的字符都能被讀入,例如下面的程式:
#include <iostream>
using namespace std;
int main()
{
int c;
while ((c = cin.get()) != EOF)
cout.put(c);
return 0;
}
程式運行情況如下:
http://c.biancheng.net/cplus/↙
http://c.biancheng.net/cplus/
C++ Tutorial↙
C++ Tutorial
^Z↙
↙表示回車鍵,^Z表示 Ctrl+Z 組合鍵,
程式中的變數 c 應為 int 型別,而不能是 char 型別,在輸入流中碰到 ASCII 碼等于 0xFF 的字符時,cin.get() 回傳 0xFF,0xFF 賦值給 c,此時如果 c 是 char 型別的,那么其值就是 -1(因為符號位為 1 代表負數),即等于 EOF,于是程式就錯誤地認為輸入已經結束,
而在 c 為 int 型別的情況下,將 0xFF 賦值給 c,c 的值是 255(因為符號位為 0,是正數),而非 -1,即除非讀到輸入末尾,c 的值都不可能是 -1,
要將文本檔案 test.txt 中的全部內容原樣顯示出來,程式可以如下撰寫:
#include <iostream>
using namespace std;
int main()
{
int c;
freopen("test.txt", "r", stdin); //將標準輸入重定向為 test.txt
while ((c = cin.get()) != EOF)
cout.put(c);
return 0;
}
cin.getline():C++讀入一行字串(整行資料)
getline() 是 istream 類的成員函式,它有如下兩個多載版本:
istream & getline(char* buf, int bufSize);
istream & getline(char* buf, int bufSize, char delim);
第一個版本從輸入流中讀取 bufSize-1 個字符到緩沖區 buf,或遇到\n為止(哪個條件先滿足就按哪個執行),函式會自動在 buf 中讀入資料的結尾添加\0,
第二個版本和第一個版本的區別在于,第一個版本是讀到\n為止,第二個版本是讀到 delim 字符為止,\n或 delim 都不會被讀入 buf,但會被從輸入流中取走,
這兩個函式的回傳值就是函式所作用的物件的參考,如果輸入流中\n或 delim 之前的字符個數達到或超過 bufSize,就會導致讀入出錯,其結果是:雖然本次讀入已經完成,但是之后的讀入都會失敗,
從輸入流中讀入一行,可以用第一個版本,用cin >> str這種寫法是不行的,因為此種讀法在碰到行中的空格或制表符時就會停止,因此就不能保證 str 中讀入的是整行,
第一個版本的 getline 函式的用法示例如下:
#include <iostream>
using namespace std;
int main()
{
char szBuf[20];
int n = 120;
if(!cin.getline(szBuf,6)) //如果輸入流中一行字符超過5個,就會出錯
cout << "error" << endl;
cout << szBuf << endl;
cin >> n;
cout << n << endl;
cin.clear(); //clear能夠清除cin內部的錯誤標記,使之恢復正常
cin >> n;
cout << n << endl;
return 0;
}
程式的運行程序如下:
ab cd↙
ab cd
33↙
33
44↙
44
在上面的輸入情況下,程式是正常的,程式運行程序中還可能出現如下情況:
ab cd123456k↙
error
ab cd
120
123456
第 7 行,讀入時因字串超長導致出錯,于是第 11 行并沒有從輸入流讀入 n,n 維持了原來的值 120,
第 12 行,呼叫 istream 的成員函式 clear() 清除 cin 內部的錯誤標記,此后 cin 又能正常讀入了,因此,123456 在第 13 行被讀入 n,
可以用 getline() 函式的回傳值(為 false 則輸入結束)來判斷輸入是否結束,例如,要將檔案 test.txt 中的全部內容(假設檔案中一行最長有 10 000個字符)原樣顯示,程式可以如下撰寫:
#include <iostream>
using namespace std;
const int MAX_LINE_LEN = 10000; //假設檔案中一行最長 10000 個字符
int main()
{
char szBuf[MAX_LINE_LEN + 10];
freopen("test.txt", "r", stdin); //將標準輸入重定向為 test.txt
while (cin.getline(szBuf, MAX_LINE_LEN + 5))
cout << szBuf << endl;
return 0;
}
程式每次讀入檔案中的一行到 szBuf 并輸出,szBuf 中不會讀入回車符,因此輸出 szBuf 后要再輸出 endl 以換行,
C++如何跳過(忽略)指定字符?
ignore() 是 istream 類的成員函式,它的原型是:
istream & ignore(int n =1, int delim = EOF);
此函式的作用是跳過輸入流中的 n 個字符,或跳過 delim 及其之前的所有字符,哪個條件先滿足就按哪個執行,兩個引數都有默認值,因此 cin.ignore() 就等效于 cin.ignore(1, EOF), 即跳過一個字符,
該函式常用于跳過輸入中的無用部分,以便提取有用的部分,例如,輸入的電話號碼形式是Tel:63652823,Tel:就是無用的內容,例如下面的程式:
#include <iostream>
using namespace std;
int main()
{
int n;
cin.ignore(5, 'A');
cin >> n;
cout << n;
return 0;
}
程式的運行程序可能如下:
abcde34↙
34
cin.ignore() 跳過了輸入中的前 5 個字符,其余內容被當作整數輸入 n 中,
該程式的運行程序也可能如下:
abA34↙
34
cin.ignore() 跳過了輸入中的 ‘A’ 及其前面的字符,其余內容被當作整數輸入 n 中,
C++怎樣查看輸入流中的下一個字符?
peek() 是 istream 類的成員函式,它的原型是:
int peek();
此函式回傳輸入流中的下一個字符,但是并不將該字符從輸入流中取走——相當于只是看了一眼下一個字符,因此叫 peek,
cin.peek() 不會跳過輸入流中的空格、回車符,在輸入流已經結束的情況下,cin.peek() 回傳 EOF,
在輸入資料的格式不同,需要預先判斷格式再決定如何輸入時,peek() 就能起到作用,
例題:撰寫一個日期格式轉換程式,輸入若干個日期,每行一個,要求全部轉換為“mm-dd-yyyy”格式輸出,輸入的日期格式可以是“2011.12.24”(中式格式),也可以是“Dec 24 2011”(西式格式),要求該程式對于以下輸入資料:
Dec 3 1990
2011.2.3
458.12.1
Nov 4 1998
Feb 12 2011
輸出結果應為:
12-03-1990
02-03-2011
12-01-0458
11-04-1998
02-12-2011
輸入資料中的 Ctrl+Z 略去不寫,因為輸入資料也可能來自于檔案,
撰寫這個程式時,如果輸入的是中式格式,就用 cin>>year(假設 year 是 int 型別變數)讀取年份,然后再讀取后面的內容;如果輸入是西式格式,就用 cin>>sMonth(假設 sMonth 是 string 型別物件)讀取月份,然后讀取后面的內容,
可是,如果沒有將資料從輸入流中讀取出來,就無法判斷輸入到底是哪種格式,即便用 cin.get() 讀取一個字符后再作判斷,也很不方便,例如,在輸入為2011.12.24的情況下,讀取第一個字符2后就知道是格式一,問題是輸入流中的已經被讀取了,剩下的表示年份的部分只有011,如何將這個011和前面讀取的2奏成一個整數 2011,也是頗費周折的事情,使用 peek() 函式很容易解決這個問題,
示例程式如下:
#include <iostream>
#include <iomanip>
#include <string>
using namespace std;
string Months[12] = { "Jan","Feb","Mar","Apr","May","Jun","Jul","Aug", "Sep","Oct","Nov","Dec" };
int main()
{
int c;
while((c = cin.peek()) != EOF) { //取輸入流中的第一個字符進行查看
int year,month,day;
if(c >= 'A' && c <= 'Z') { //美國日期格式
string sMonth;
cin >> sMonth >> day >> year;
for(int i = 0;i < 12; ++i) //查找月份
if(sMonth == Months[i]) {
month = i + 1;
break;
}
}
else { //中國日期格式
cin >> year ;
cin.ignore() >> month ; //用ignore跳過 "2011.12.3"中的'.'
cin.ignore() >> day;
}
cin.ignore(); //跳過行末 '\n'
cout<< setfill('0') << setw(2) << month ;//設定填充字符'\0',輸出寬度2
cout << "-" << setw(2) << day << "-" << setw(4) << year << endl;
}
return 0;
}
istream 還有一個成員函式 istream & putback(char c),可以將一個字符插入輸入流的最前面,對于上面的例題,也可以在用 get() 函式讀取一個字符并判斷是中式格式還是西式格式時,將剛剛讀取的字符再用 putback() 成員函式放回流中,然后再根據判斷結果進行不同方式的讀入,
C++ cin是如何判斷輸入結束(讀取結束)的?
cin 可以用來從鍵盤輸入資料;將標準輸入重定向為檔案后,cin 也可以用來從檔案中讀入資料,在輸入資料的多少不確定,且沒有結束標志的情況下,該如何判斷輸入資料已經讀完了呢?
從檔案中讀取資料很好辦,到達檔案末尾就讀取結束了,從控制臺讀取資料怎么辦呢?總不能把控制臺關閉吧?這樣程式也運行結束了!
其實,在控制臺中輸入特殊的控制字符就表示輸入結束了:
- 在 Windows 系統中,通過鍵盤輸入時,按 Ctrl+Z 組合鍵后再按回車鍵,就代表輸入結束,
- 在 UNIX/Linux/Mac OS 系統中,Ctrl+D 代表輸入結束,
不管是檔案末尾,還是 Ctrl+Z 或者 Ctrl+D,它們都是結束標志;cin 在正常讀取時回傳 true,遇到結束標志時回傳 false,我們可以根據 cin 的回傳值來判斷是否讀取結束,
cin 判斷控制臺(鍵盤)讀取結束
輸入若干個正整數,輸出其中的最大值,程式該如何撰寫?
#include <iostream>
using namespace std;
int main()
{
int n;
int maxN = 0;
while (cin >> n){ //輸入沒有結束,cin 就回傳 true,條件就為真
if (maxN < n)
maxN = n;
}
cout << maxN <<endl;
return 0;
}
在 Windows 下運行該程式,先輸入以下整數:
10
30
93
206
8
然后在按下 Ctrl+Z 組合鍵(可以在當前行,也可以在新的一行),接著按下回車鍵,輸入就結束了,此時 cin 回傳 false,回圈結束,得到了最大值,
完整的輸入輸出結果如下所示:
10↙
30↙
93↙
206↙
8↙
^Z↙
206
↙表示回車鍵,^Z表示 Ctrl+Z 組合鍵,
cin 判斷檔案讀取結束
如果將標準輸入重定向為某個檔案,如在程式開始添加freopen("test.txt", "r", stdin);陳述句,或者不添加上述陳述句,但是在 Windows 的“命令提示符”視窗中輸入:
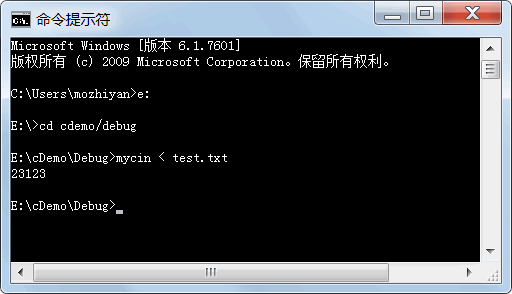
mycin < test.txt //假設編譯生成的可執行檔案的名字為 mycin.exe
則都能使得本程式不再從鍵盤輸入資料,而是從 test.txt 檔案輸入資料(前提是 test.txt 檔案和 mycin.exe 在同一個檔案夾中),在這種情況下,test.txt 檔案中并不需要包含 Ctrl+Z,只要有用空格或回車隔開的若干個正整數即可,
cin 讀到檔案末尾時,cin>>n就會回傳 false,從而導致程式結束,例如,假定 test.txt 檔案中的內容如下所示:
112
23123
34 444 55
44
對于前面的代碼,在“命令提示符”視窗中先 cd 到 mycin.exe 所在目錄,然后輸入mycin < test.txt,則程式的輸出是:
23123
下面是筆者實操演示圖:
答疑解惑
在《C++多載<<和>>》一節中我們提到過 istream 類將>>多載為成員函式,而且這些成員函式的回傳值是 cin 的參考,準確地說,cin>>n的回傳值的確是 istream & 型別的,而 while 陳述句中的條件運算式的回傳值應該是 bool 型別、整數型別或其他和整數型別兼容的型別,istream & 顯然和整數型別不兼容,為什么while(cin>>n)還能成立呢?
這是因為,istream 類對強制型別轉換運算子 bool 進行了多載,這使得 cin 物件可以被自動轉換成 bool 型別,所謂自動轉換的程序,就是呼叫 cin 的 operator bool() 這個成員函式,而該成員函式可以回傳某個標志值,該標志值在 cin 沒有讀到輸入結尾時為 true,讀到輸入結尾后變為 false,對該標志值的設定,在 operator <<() 成員函式中進行,
如果 cin 在讀取程序中發生了錯誤,cin>>n這樣的運算式也會回傳 false,例如下面的程式:
#include <iostream>
using namespace std;
int main()
{
int n;
while (cin >> n)
cout << n << endl;
return 0;
}
程式本該輸入整數,如果輸入了一個字母,則程式就會結束,因為,應該讀入整數時卻讀入了字母也算讀入出錯,
C++處理輸入輸出錯誤
當處理輸入輸出時,我們必須預計到其中可能發生的錯誤并給出相應的處理措施,
- 當我們輸入時,可能會由于人的失誤(錯誤理解了指令、打字錯誤、允許自家的小貓在鍵盤上散步等)、檔案格式不符、錯誤估計了情況等原因造成讀取失敗,
- 當我們輸出時,如果輸出設備不可用、佇列滿或者發生了故障等,都會導致寫入失敗,
發生輸入輸出錯誤的可能情況是無限的!但 C++ 將所有可能的情況歸結為四類,稱為流狀態(stream state),每種流狀態都用一個 iostate 型別的標志位來表示,
| 標志位 | 意義 |
|---|---|
| badbit | 發生了(或許是物理上的)致命性錯誤,流將不能繼續使用, |
| eofbit | 輸入結束(檔案流的物理結束或用戶結束了控制臺流輸入,例如用戶按下了 Ctrl+Z 或 Ctrl+D 組合鍵, |
| failbit | I/O 操作失敗,主要原因是非法資料(例如,試圖讀取數字時遇到字母),流可以繼續使用,但會設定 failbit 標志, |
| goodbit | 一切止常,沒有錯誤發生,也沒有輸入結束, |
ios_base 類定義了以上四個標志位以及 iostate 型別,但是 ios 類又派生自 ios_base 類,所以可以使用 ios::failbit 代替 ios_base::failbit 以節省輸入,
一旦流發生錯誤,對應的標志位就會被設定,我們可以通過下表列出的函式檢測流狀態,
| 檢測函式 | 對應的標志位 | 說明 |
|---|---|---|
| good() | goodbit | 操作成功,沒有發生任何錯誤, |
| eof() | eofbit | 到達輸入末尾或檔案尾, |
| fail() | failbit | 發生某些意外情況(例如,我們要讀入一個數字,卻讀入了字符 ‘x’), |
| bad() | badbit | 發生嚴重的意外(如磁盤讀故障), |
不幸的是,fail() 和 bad() 之間的區別并未被準確定義,程式員對此的觀點各種各樣,但是,基本的思想很簡單:
- 如果輸入操作遇到一個簡單的格式錯誤,則使流進入 fail() 狀態,也就是假定我們(輸入操作的用戶)可以從錯誤中恢復,
- 如果錯誤真的非常嚴重,例如發生了磁盤故障,輸入操作會使得流進入 bad() 狀態,也就是假定面對這種情況你所能做的很有限,只能退出輸入,
以上觀點導致如下邏輯:
int i = 0;
cin >> i;
if(!cin){ //只有輸入操作失敗,才會跳轉到這里
if(cin.bad()){ //流發生嚴重故障,只能退出函式
error("cin is bad!"); //error是自定義函式,它拋出例外,并給出提示資訊
}
if(cin.eof()){ //檢測是否讀取結束
//TODO:
}
if(cin.fail()){ //流遇到了一些意外情況
cin.clear(); //清除/恢復流狀態
//TODO:
}
}
!cin 可以理解為“cin 不成功”或者“cin 發生了某些錯誤”或者“ cin 的狀態不是 good()”, 這與“操作成功”正好相反,《C++ cin判斷輸入結束》一節中對此有詳解,
請注意我們在處理 fail() 時所使用的 cin.clear(),當流發生錯誤時,我們可以進行錯誤恢復,為了恢復錯誤,我們顯式地將流從 fail() 狀態轉移到其他狀態,從而可以繼續從中讀取字符,clear() 就起到這樣的作用——執行 cin.clear() 后,cin 的狀態就變為 good(),
實體
下面是一個如何使用流狀態的例子,假定我們要讀取一個整數序列并存入 vector 中,字符*或“檔案尾”表示序列結束,Windows 平臺按下 Ctrl+Z 組合鍵,再按下回車鍵表示到達檔案末尾;類Unix系統按下 Ctrl+D 組合鍵表示到達檔案末尾,
上述功能可通過如下函式來實作:
//從 ist 中讀入整數到 v 中,直到遇到 eof() 或終結符
void fill_vector(istream& ist, vector<int>& v, char terminator){
for( int i; ist>>i; ) v.push_back(i);
//正常情況
if(ist.eof()) return; //發現到了檔案尾,正確,回傳
//發生嚴重錯誤,只能退出函式
if (ist.bad()){
error("cin is bad!"); //error是自定義函式,它拋出例外,并給出提示資訊
}
//發生意外情況
if (ist.fail()) { //最好清除混亂,然后匯報問題
ist.clear(); //清除流狀態
//檢測下一個字符是否是終結符
char c;
ist>>c; //讀入一個符號,希望是終結符
if(c != terminator) { // 非終結符
ist.unget(); //放回該符號
ist.clear(ios_base::failbit); //將流狀態設定為 fail()
}
}
}
如果發生了 fail(),我們嘗試檢測下一個字符是否是結束符:如果是,那么就完整得讀取了資料,使用 clear() 恢復狀態就可以;如果不是,我們就沒有辦法處理了,所以將狀態重新設定為 fail(),以期望 fill_vector() 的呼叫者(上層函式)有能力處理,
我們通過呼叫 ist.clear(ios_base::failbit) 來將流狀態設定為 fail(),對照簡單的cleal(),帶引數的用法有些令人迷惑:當 clear() 帶引數時,引數中所指出的 iostream 狀態位會被置位(進入相應狀態),而未指出的狀態位會被復位,通過將流狀態設定為 fail(),我們表明遇到了一個格式錯誤,而不是一個更為嚴重的問題,
可以用 unget() 將字符放回 ist,以便 fill_vector() 的呼叫者可能使用該字符,unget() 函式是 putback() 的簡化版本,它依賴于流物件記住最后一個字符是什么,所以在這里可以不用考慮它的用法,
如果 fill_vector() 的呼叫者想知道是什么原因終止了輸入,那么可以檢測流是處于 fail() 還是 eof() 狀態,當然也可以捕獲 error() 拋出的 runtime_error 例外,但當 istream 處于 bad() 狀態時,繼續獲取資料是不可能的,大多數的呼叫者無須為此煩惱,因為這意味著,幾乎在所有情況下,對于 bad() 狀態,我們所能做的只是拋出一個例外,
簡單起見,可以讓 istream 幫我們拋出這個例外,
//當 ist 出現問題時拋出例外
ist.exceptions(ist.exceptions() | ios_base:: badbit);
這樣的寫法也許看起來有些奇怪,但結果卻很簡單,當此陳述句執行時,如果 ist 處于 bad() 狀態,它會拋出一個標準庫例外 ios_base::failure,在一個程式中,我們只需要呼叫 exceptions() 一次,這允許我們簡化關聯于 ist 的所有輸入程序,同時忽略對 bad() 的處理:
//從ist中讀入整數到v中,直到遇到eof()或終結符
void fill_vector(istream& ist, vector<int>& v, char terminator){
ist.exceptions(ist.exceptions() | ios_base:: badbit);
for (int i; ist>>i; ) v.push_back(i);
if (ist.eof()) return; //發現到了檔案尾
//不是good(),不是bad(),不是eof(),ist的狀態一定是fail()
ist.clear(); //清除流狀態
char c;
ist>>c; //讀入一個符號,希望是終結符
if (c != terminator) { //不是終結符號,一定是失敗了
ist.unget(); //也許程式呼叫者可以使用這個符號
ist.clear(ios_base::failbit); //將流狀態設定為 fail()
}
}
這里使用了 ios_base,它是 iostream 的一部分,包含了對常量如 badbit 的定義、例外如 failure 的定義,以及其他一些有用的定義,可以通過::運算子來使用它們,例如 ios_ base::badbit,
我們無須如此深入地討論 iostream 庫的細節,若要學習 iostream的所有內容,可能需要一門完整的課程,例如,iostream 可以處理不同的字符集,實作不同的緩沖策略,還包含一些工具,能按不同語言的習慣格式化貨幣金額的輸入輸出,我們曾經收到過一份關于烏克蘭貨幣輸入輸出格式的錯誤報告,如果需要了解更多 iostream 庫的內容,可以參考 Stroustrup 的《The C++ Programming Language》和 Langer 的《Standard C++ IOStreams and Locales》,
與 istream—樣,ostream 也有四個狀態:good()、fail()、eof() 和 bad(),不過,對于本教程的讀者來說,輸出錯誤要比輸入錯誤少得多,因此通常不對 ostream 進行狀態檢測,如果程式運行環境中輸出設備不可用、佇列滿或者發生故障的概率很高,我們就可以像處理輸入操作那樣,在每次輸出操作之后都檢測其狀態,
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/292073.html
標籤:其他
下一篇:獲取和檢測android的父行程