寫在前面
理解多執行緒并發和鎖的關鍵在于正確的理清當前代碼正處在哪個執行緒的執行環境下,說白了,這個同步代碼/同步方法誰都可以來執行的,關鍵是有沒有其他人在用這個鎖,
1 Thread如何理解
1.1 Thread類與普通類的區別?
執行緒與執行緒類是不同的概念, 執行緒是系統CPU資源調度的基本單元,它是一個抽象的概念,Thread類和其他別的類沒有什么區別,它只是對執行緒有著“管理”作用,而真正執行的代碼都是在run()方法中,或者外部傳入的runnable中,
1.2 中介作用
在執行緒的start方法之前,所有代碼都在老執行緒上運行,呼叫start方法之后,內部會呼叫VMTthread.create,實際上真正在新執行緒上運行的只有run方法,這個角度理解,thread類只是一個中介,任務就是啟動一個新執行緒來運行用戶指定的runnable,而不關心是內部的還是外部傳入的,
2 執行緒的狀態
- New 執行緒創建
- Runnable 可執行狀態
- Running 執行狀態
- wait:當前執行緒呼叫某個物件object的wait方法,只有當子執行緒也同樣呼叫該物件object的 notify/notifyAll方法才會喚醒當前執行緒,系統可能會有多個執行緒在wait,所以有notifyAll方法,
- block:遇到同步時候(同步方法、同步代碼塊、class類物件作為鎖時,類中的靜態方法),如果鎖已經被其他的執行緒占用,那么就會進入阻塞狀態,直到獲取到鎖,
- timed_wait: sleep/join, 等的一定時間才執行,
- terminated:執行緒運行完畢
join()用來保證兩個執行緒的順序執行:
Thread t1=new Thread(xx);
Thread t2=new Thread(xx);
t1.start();
t1.join();
t2.start();
上面代碼表示,只有當t1執行完畢,t2才會執行,
2.1 wait和notify是如何系結的?
通過同一個object物件,當一個執行緒呼叫某個object物件的wait方法時候,系統會在object中記錄該請求,如果是多個執行緒呼叫則會有waitinglist,而當另外一個執行緒呼叫object的notify/notifyAll來喚醒一個/多個waitinglist中的執行緒,
2.2 執行緒呼叫wait()方法的條件?
- 執行這個object的synchronized方法
- 執行一段synchronized代碼,且是基于這個object做的同步
- 如果object是一個class類,可以實行synchronized static 方法
也就說: 一個執行緒獲得了物件object鎖lock,它才可以呼叫wait方法,而呼叫wait方法后該執行緒會釋放鎖,從而可以讓別的執行緒來獲取,
2.4 執行緒什么時候會釋放鎖?
- 當執行緒執行完畢
- 執行緒呼叫wait()方法
2.5 wait方法和sleep方法區別
- wait方法必須要在同步代碼中呼叫,sleep沒有限制
- wait方法會釋放CPU、釋放鎖,sleep釋放CPU,不釋放鎖(容易引起死鎖)
3 Java記憶體模型的本質(重點)
JMM java記憶體管理模型,提出了主存和執行緒本身的作業記憶體概念,如圖:
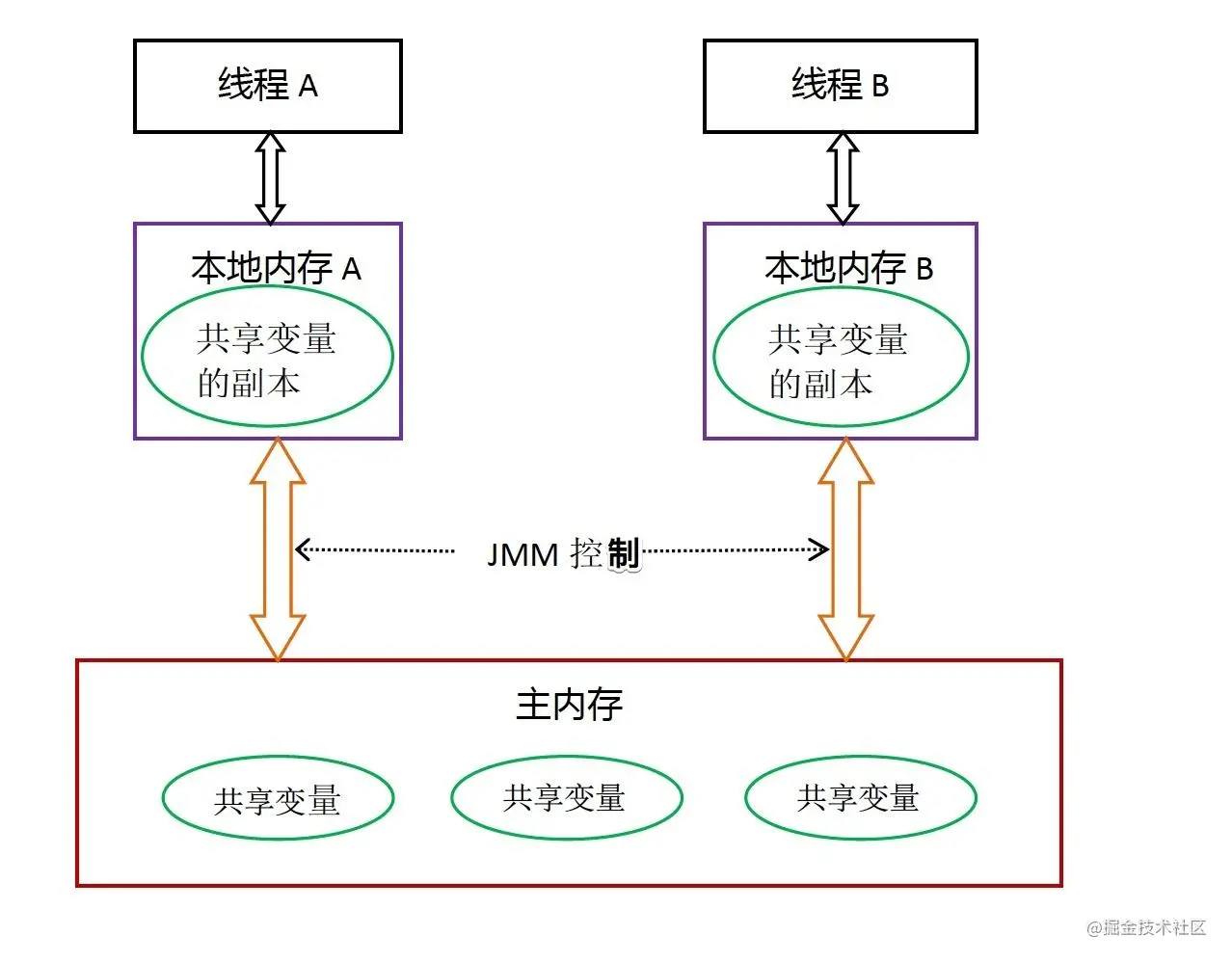
說明: 主存即記憶體,本地記憶體即CPU快取(包括三級快取、暫存器、WCbuffer等),
一個單核CPU在一個執行緒上執行指令,如果需要切換執行緒它會把當前執行緒的執行現場保存到記憶體中去,方便后續恢復,然后清空PC計數器,加載新執行緒的指令地址,因此,單核CPU不存在同步的問題,
當多核CPU分別在執行自己執行緒指令時,如果存在共享同一個變數,那么就有可能存在競爭關系,因為每個CPU的核都有自己的本地快取,而二者通信是通過記憶體中共享變數的方式來實作的,這就存在這個變數同步不及時的情況,所以需要同步,
其實本質上本地記憶體是一個抽象的概念,實際上指的是CPU中的L1、L2和暫存器等相關的快取, 現在的設備都是多個CPU多核同時作業,如:CPU執行PC(程式計數器)中的某條指令需要一個變數,那么CPU不是直接去記憶體中操作該變數,而是先把變數讀取到L3->L2->L1(三級快取),最后到暫存器快取起來,然后CPU在去暫存器中讀取該變數,當然CPU不會一次只讀取一個變數,而是一次讀取一個快取行Cache Line,一個快取行的大小是64個Byte,如果在需要下一個變數則會先從暫存器和快取中查找,這樣就比去操作記憶體塊很多,最后,把計算結果重繪到暫存器,同步到主存(也就是記憶體)中,
4 同步相關問題(重點)
4.1 重排序和happens-before
4.1.1 重排序
不管什么用到語言,我們寫的代碼最終都會轉成匯編指令,而匯編指令與機器指令(如:01010)是一一對應的,因此當CPU在執行當前指令的時候處于讀等待,CPU不作業了?豈不是浪費?為了提高性能,它會嘗試下一條指令能不能先執行了?,如果可以,那么CPU就不會閑下來了,
但有個前提,這個指令跟前一個指令沒有依賴關系才會執行, 有了亂序執行這個機制,一連串的指令就看起來變得可以并行執行了(其實沒有,只是利用了CPU處于讀等待的空隙做事情),
因此,為了提高執行效率,編譯器和CPU都會進行指令的重排序,
4.1.2 happens-before
顧名思義,如果一個操作happens-before另一個操作,那么第一個操作的執行結果將對第二個操作可見,而且第一個操作的執行順序排在第二個操作之前,
不用太糾結這個概念,這只是一個規范而已,本質上就是說這個規范實作的代碼肯定是加了記憶體屏障的,
如下這些代碼實作方式,就是符合happens-before規則的:
- 程式順序規則:一個執行緒中的每一個操作,happens-before于該執行緒中的任意后續操作,
- 監視器鎖規則:對一個鎖的解鎖,happens-before于隨后對這個鎖的加鎖,
- volatile變數規則:對一個volatile域的寫,happens-before于任意后續對這個volatile域的讀,
- 傳遞性:如果A happens-before B,且B happens-before C,那么A happens-before C,
- start規則:如果執行緒A執行操作ThreadB.start()啟動執行緒B,那么A執行緒的ThreadB.start()操作happens-before于執行緒B中的任意操作、
- join規則:如果執行緒A執行操作ThreadB.join()并成功回傳,那么執行緒B中的任意操作happens-before于執行緒A從ThreadB.join()操作成功回傳,
4.2 synchronize
synchronize不管是修飾方法還是代碼塊,都需要用到鎖物件,而鎖物件的鎖是有狀態的,它會升級也會降級,鎖的是物件,而不是把代碼塊鎖住了!
鎖的狀態(jdk1.6后):
- 無鎖態
- 偏向鎖
- 輕量級鎖(也叫自旋鎖)
- 重量級鎖 用戶態向內核態申請鎖,消耗鎖資源,mutex
4.2.1 物件頭
在jvm中,每個Object物件在記憶體中的布局有三部分組成:
- 物件頭 : 包含markword(32位系統是4個位元組,64位是8個位元組)、class物件指標占4個位元組
- 實體物件 :
- padding對齊: 為了讓物件能夠被8整除,需要補齊的位元組數
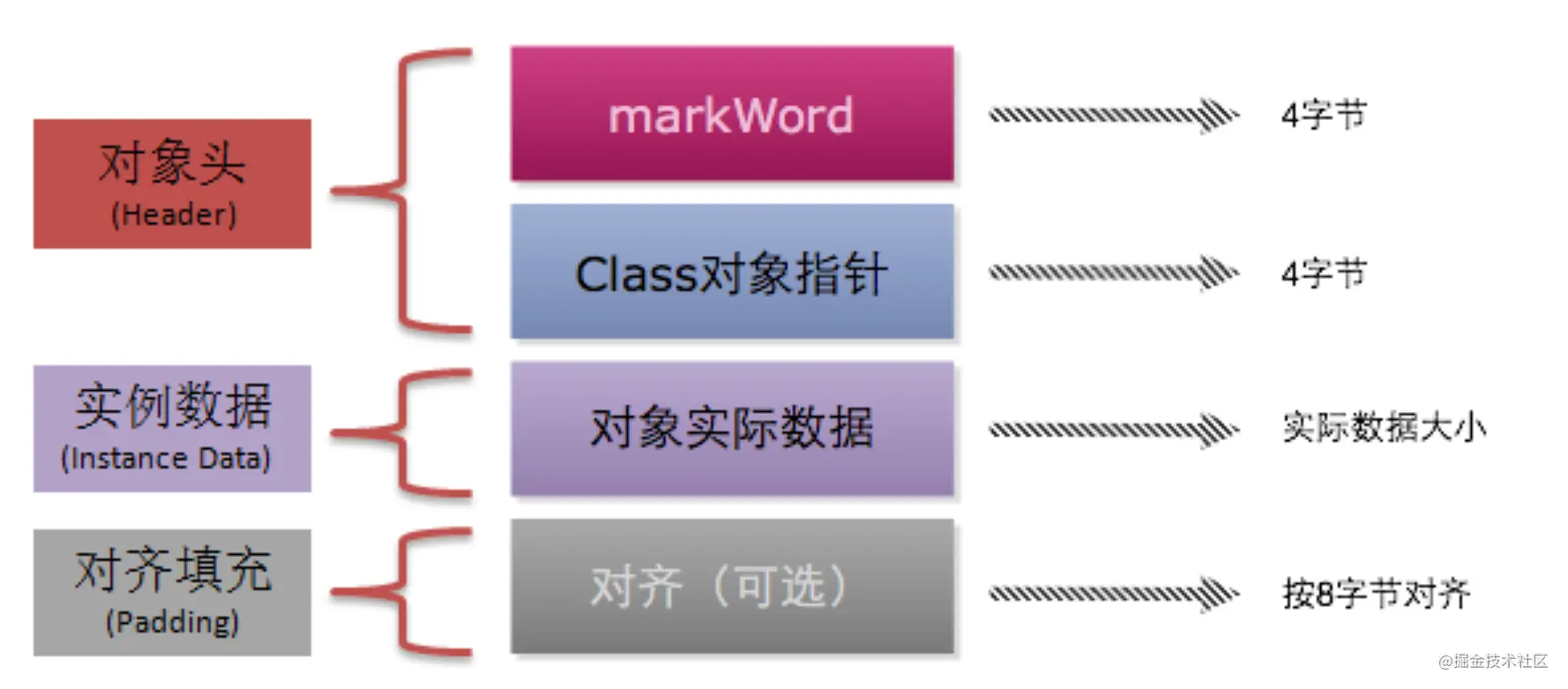
舉個例子: Object0=new Object(); o物件占多少記憶體?
假如是64位系統:
物件頭+實體物件,也就是 8+4+0=12,不能被8整除,所以還需要加上padding 4. 因此,最終的o物件占用了16個位元組,
請注意!!! markword就是用來存盤鎖資訊的地方, 一共32/64位,多少位沒有太大關系,我們只需要知道里面有什么即可,
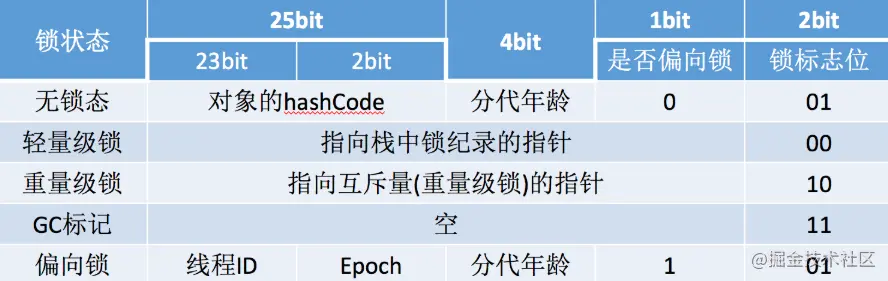
4.2.2 鎖的升級程序
- 一開始new 出鎖物件時,還沒有執行緒進入臨界區,此時是無鎖態,
- 有執行緒進入,則改成偏向鎖,同時markword存入執行緒的id,
- 如果是同一執行緒則還是偏向鎖,
- 當另外執行緒也進入臨界區,請求鎖物件,發現物件頭已經有偏向鎖了,產生了競爭!!那不好意思,先撤銷偏向鎖,然后兩個執行緒通過CAS自旋的方式開始爭搶鎖物件,都往鎖物件頭里面寫入自己執行緒堆疊的lock record,一旦有執行緒爭搶成功,那么其他執行緒就會失敗,此時鎖物件變成了輕量級鎖,
- 失敗的執行緒會一直CAS回圈下去,此間也可能還會有其他執行緒參與進來自旋,
- 當自旋次數超過一定值如10次,或者參與自旋的執行緒數太多,系統會進行干預,
- 這樣干耗著會浪費CPU資源,所以干脆升級為重量級鎖,其他執行緒全部進入mutex中的佇列中去排隊,執行緒進入wait或者block狀態,不消耗CPU,
- 但synchronize修飾的是非公平的佇列,
講了這么多,synchronize的底層到底是怎么實作的?
其實還是 lock cmpxchg 指令,
4.3 volatile
volatile修飾變數后有兩個作用: 1,記憶體可見性 執行緒間作業記憶體和主存實作了及時同步 2,防止指令重排 這對這個變數的操作被JMM加入記憶體屏障來保證指令不會亂序執行,
volatile到底是怎么解決指令重排的??
JVM層通過加入記憶體屏障,是一個邏輯實作,是jvm的要求規范而已,具體要看匯編語言,
- loadload 屏障 讀
- storestore 屏障 寫
- loadstore 屏障
- storeload 屏障
四個邏輯, 具體 就是在volatile讀/寫的前后加入記憶體屏障,保證順序執行,記憶體屏障前后的指令不能重排序!
匯編層面: 最終就是呼叫了 lock: andl 指令,表示在暫存器中加0操作,
為什么這條指令能實作記憶體可見和禁止指令重排序??
記憶體可見性: 該指令能夠將當前處理器對應快取內容重繪到記憶體,并且是其他處理器的快取失效, 重排序: 該指令本身就是記憶體屏障,它前面的指令和后面的指令都不能重排序,
4.4 CAS和原子操作
4.4.1 樂觀鎖和悲觀鎖
- 悲觀鎖: 在訪問共享資源的時候總是認為別人會來搶,所以只要訪問臨界區就直接上鎖,通俗講就是因為怕被搶,所以無腦上鎖,比如用synchronize來對臨界區上鎖,
- 樂觀鎖: 在訪問共享資源時候,認為別的執行緒不會來搶資源,所以是“無鎖”狀態,但是可以通過CAS來保證資料的安全,ReentrantLock互斥鎖(互斥別人,不互斥自己)
4.4.2 CAS
CAS(compare and swap): 比較并且交換, 目的: 在沒有鎖的狀態下,可以保證多個執行緒對一個值的更新,
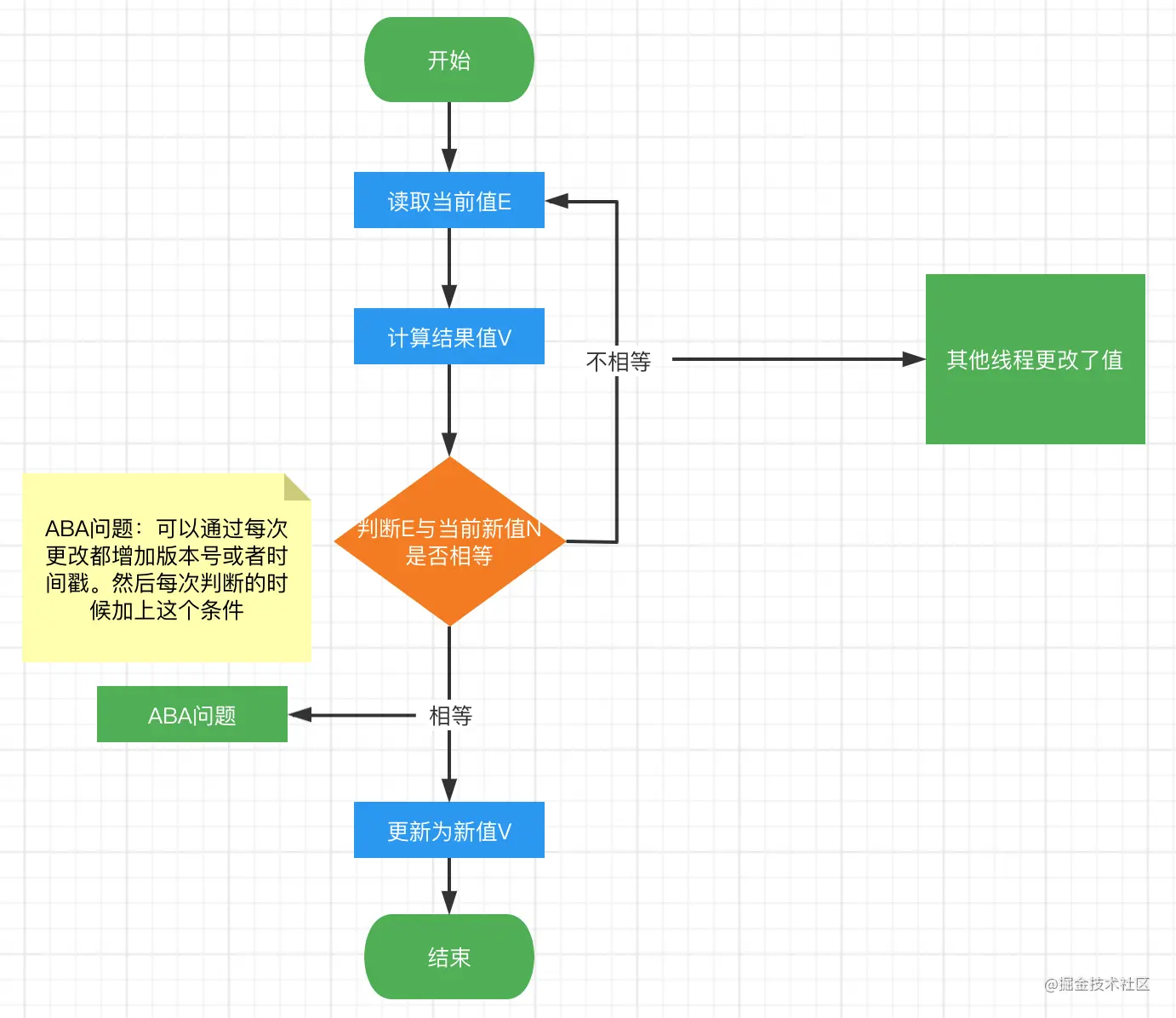
CAS實作思想:
- E:拿到變數當前原始值(期望值)
- V:計算的結果值
- N:再次獲取變數的值(當前值)
舉個例子: 假設i=0,對i做++操作, CAS的程序是這樣的:
- 拿當i的前值 E=0;
- 計算結果值V=1;
- 再次拿i的當前,有可能如下情況: N=0;N=3(因為某個執行緒更改了)
- 如果E=N,表示沒有被修改,我們可以更新,直接修改i=1,
- 如果E!=N,表示被修改過,我們這次修改就不能執行,然后我們在重頭開始,再次比較,最終實作交換,
流程圖:
- 實作的本質:
AtomicInteger內部就是通過CAS的方式來保證執行緒安全的,
內部會呼叫UnSafe類的方法,
private static final sun.misc.Unsafe U = sun.misc.Unsafe.getUnsafe();
/**
* Atomically decrements by one the current value.
*
* @return the previous value
*/
public final int getAndDecrement() {
//U表示 UnSafe類
return U.getAndAddInt(this, VALUE, -1);
}
UnSafe類直接呼叫的是C++層的native方法compareAndSwapInt():
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
// while中 native 方法
} while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;
}
// native 方法
public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5);
通過原始碼發現compareAndSwapInt()最侄訓呼叫c++層的 Atomic::cmpxchg方法,有如下指令:
//_asm_ 表示匯編指令
//LOCK_IF_MP: 如果是multi-processs 多處理器, 現在處理器都是多CPU的,
_asm_ volatile (LOCK_IF_MP(%4) "cmpxchg1 %1, (%3)")...//后面省略
如果是多個處理器則 進行lock,為什么? 多個CPU就會出現多執行緒同時執行,出現并發問題,
而CAS方法會直接通過匯編指令:lock cmpxchg 指令 來完成CAS真正的操作, cmpxchg 這個指令也就體現了比較和交換的本質了,
所以, 現在的問題變成 lock cmpxhg 指令 是如何實作執行緒安全的? 寫入的程序是沒有原子性保證的, 由 lock 指令來保證原子性, 最終由硬體來支持,硬體怎么實作的啊? 好啦,到這里就可以啦, 硬體通過鎖定北橋信號?(我也不清楚了啊),
4.5 AQS(AbstractQueuedSynchronizer) 抽象佇列同步器
高并發編程的核心: AQS,
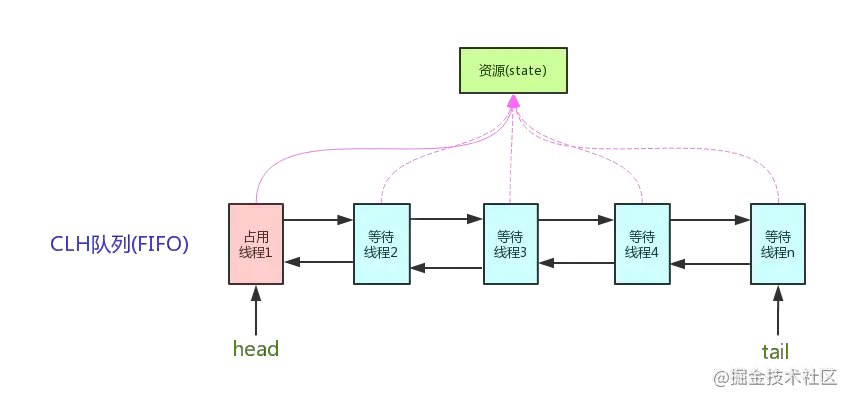
里面通過維護一個volatile int state變數和一個存盤執行緒的佇列(雙向鏈表)來實作同步的, 它本身是一個抽象的類,定義了同步模板方法,具體邏輯需要子類去繼承實作, 可通過構造方法傳入是否是公平鎖,
執行緒通過CAS去獲取state值,state初始值為0,那么拿到鎖state=1, 后續如果再有執行緒進來,那么就封裝成Node節點看,然后放到佇列中去阻塞,知道之前的執行緒釋放鎖, 支持公平鎖和非公平鎖兩種方式,
4.5.1 ReentrantLock和synchronize的區別?
synchronize: 最終要通過用戶態到內核態的切換,但是有鎖的升級優化,悲觀鎖
ReentrantLock(jdk1.5后新增的鎖): 基于AQS同步機制,其實內部還是通過CAS來獲取鎖,不用到內核態,輕量級,更加靈活,屬于 樂觀鎖, 需要自己手動try catch,在finally中釋放鎖,
分享
小編學習提升時,順帶從網上收集整理了一些 Android 開發相關的學習檔案、面試題、Android 核心筆記等等檔案,希望能幫助到大家學習提升,如有需要參考的可以直接去我 CodeChina地址:https://codechina.csdn.net/u012165769/Android-T3 訪問查閱,

轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/295211.html
標籤:其他