一、堆疊與暫存器
① 堆疊
- 堆疊:是一種具有特殊的訪問方式的存盤空間(即先進后出 Last In First Out, LIFO):
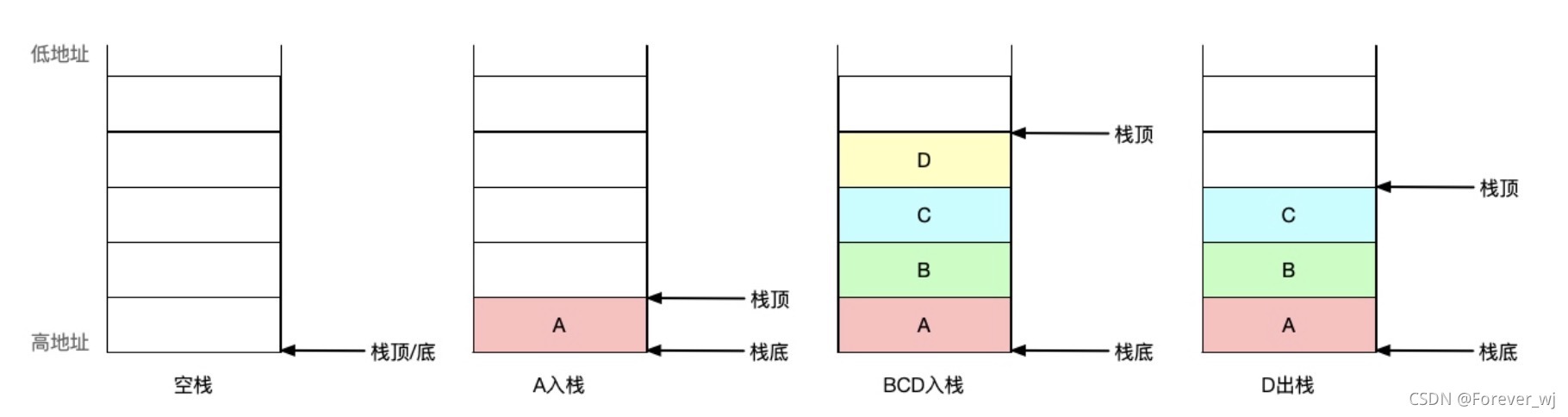
- 高地址往低地址存資料(存:高–>低);
- 堆疊空間開辟:往低地址開辟(開辟:高–>低),
② SP 和 FP 暫存器
- SP 暫存器:在任意時刻會保存堆疊頂的地址;
- FP 暫存器(也稱為 x29 暫存器):屬于通用暫存器,但是在某些時刻(例如函式嵌套呼叫時)可以利用它保存堆疊底的地址;
- arm64 開始,取消了 32 位的 LDM、STM、PUSH、POP 指令,取而代之的是 ldr/ldp、str/stp(r 和 p 的區別在于處理的暫存器個數,r 表示處理 1 個暫存器,p 表示處理兩個暫存器);
- arm64 中,對堆疊的操作是 16 位元組對齊,
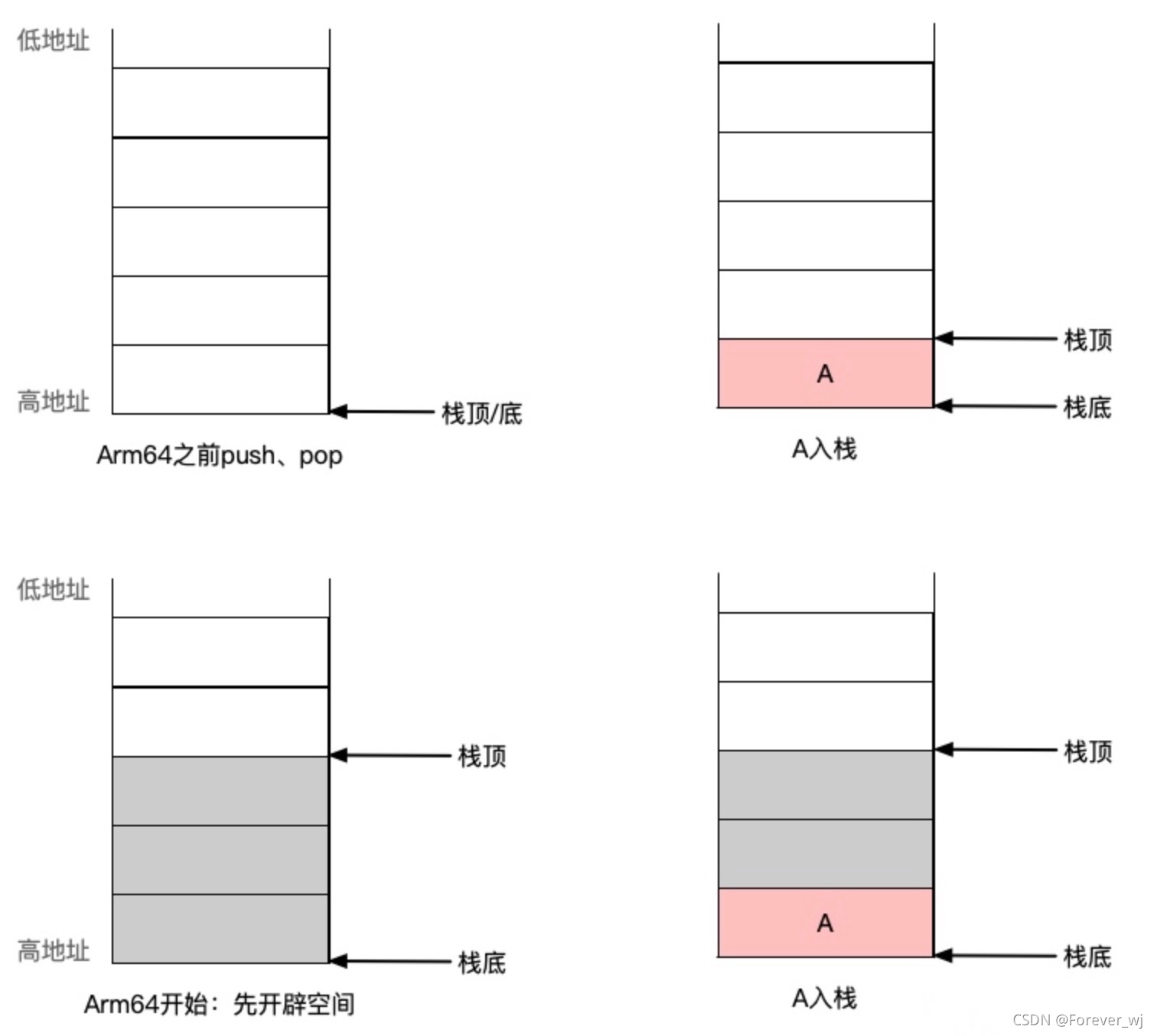
- arm64 之前和 arm64 之后堆疊的對比:
-
- 在 arm64 之前,堆疊頂指標是壓堆疊時一個資料移動一個單元;
-
- 在 arm64 開始,首先是從高地址往低地址開辟一段堆疊空間(由編譯器決定),然后再放入資料,所以不存在 push、pop 操作,這種情況可以通過記憶體讀寫指令(ldr/ldp、str/stp)對其進行操作,
③ x30 暫存器
- x30 暫存器存放的是函式的回傳地址,當 ret 指令執行時刻,會尋找 x30 暫存器保存的地址值;
- 在函式嵌套呼叫時,需要將 x30 入堆疊;
- lr 是 x30 的別名;
- sp 堆疊里面的操作必須是 16 位元組對齊,
二、函式呼叫堆疊
- 常見的函式呼叫開辟(sub)以及恢復堆疊空間(add)的匯編代碼:
// 開辟堆疊空間
sub sp, sp, #0x40 ; 拉伸0x40(64位元組)空間
stp x29, x30, [sp, #0x30] ; x29\x30 暫存器入堆疊保護
add x29, sp, #0x30 ; x29指向堆疊幀的底部
...
ldp x29, x30, [sp, #0x30] ; 恢復x29/x30 暫存器的值
// 恢復堆疊空間
add sp, sp, #0x40 ; 堆疊平衡
ret
① 記憶體讀寫指令
- str(store register)指令(能和記憶體和暫存器互動的專門的指令):將資料從暫存器中讀出來,存到記憶體中 (即一個暫存器是 8 位元組 - 64 位);
- ldr(load register)指令:將資料從記憶體中讀出來,存到暫存器中;
- ldr 和 str 的變種 ldp 和 stp 還可以操作 2 個暫存器(即 128 位 - 16 位元組),
- 注意:
-
- 讀/寫資料都是往高地址讀/寫;
-
- 寫資料:先拉伸堆疊空間,再拿 sp 進行寫資料,即先申請空間再寫資料,
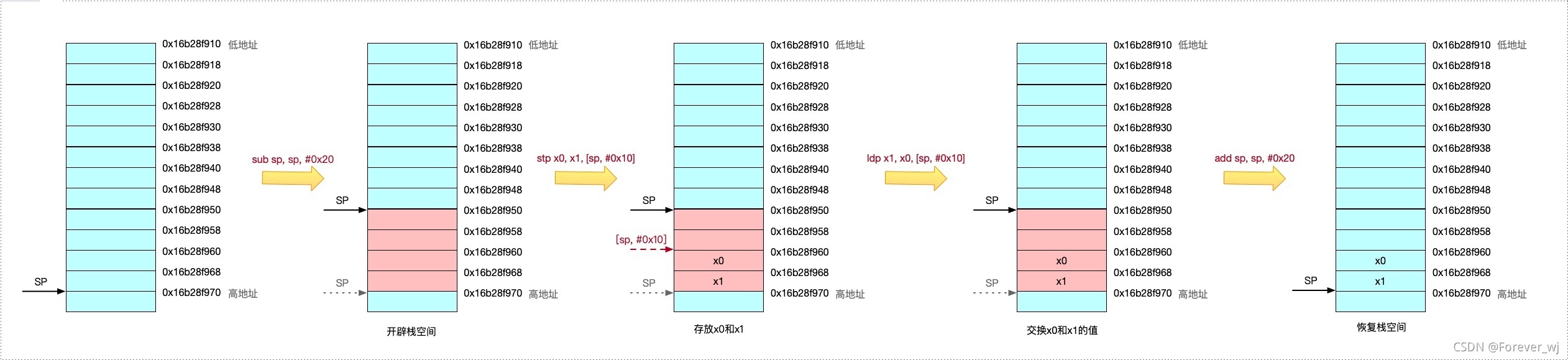
- 使用 32 個位元組空間作為如下程式的堆疊空間,然后利用堆疊將 x0 和 x1 的值進行交換:
sub sp, sp, #0x20 ;拉伸堆疊空間32個位元組
stp x0, x1, [sp, #0x10] ;sp往上加16個位元組,存放x0和x1
ldp x1, x0, [sp, #0x10] ;將sp偏移16個位元組的值取出來,放入x1和x0,記憶體是temp(暫存器里面的值進行交換)
add sp, sp, #0x20 ;堆疊平衡
ret ;回傳
- 堆疊的操作如下圖所示:
② 除錯查看堆疊
- 重寫 x0、x1 的值:
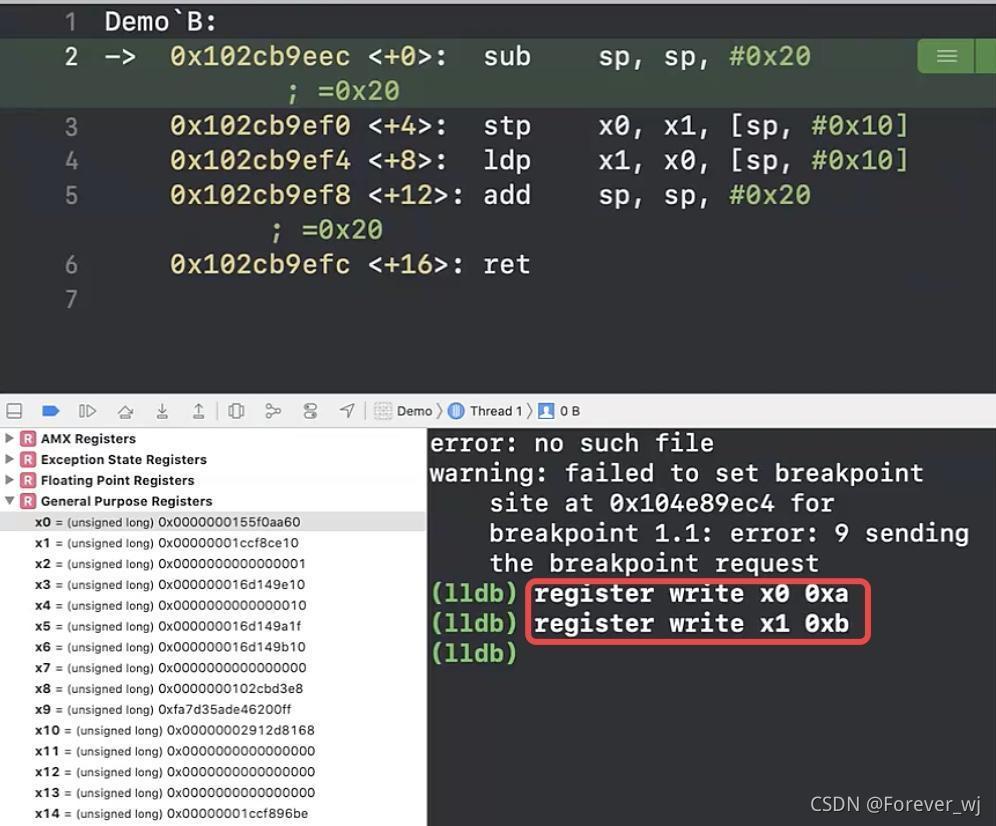
- register read sp:查看堆疊的存盤情況 debug - debug workflow - view Memory:
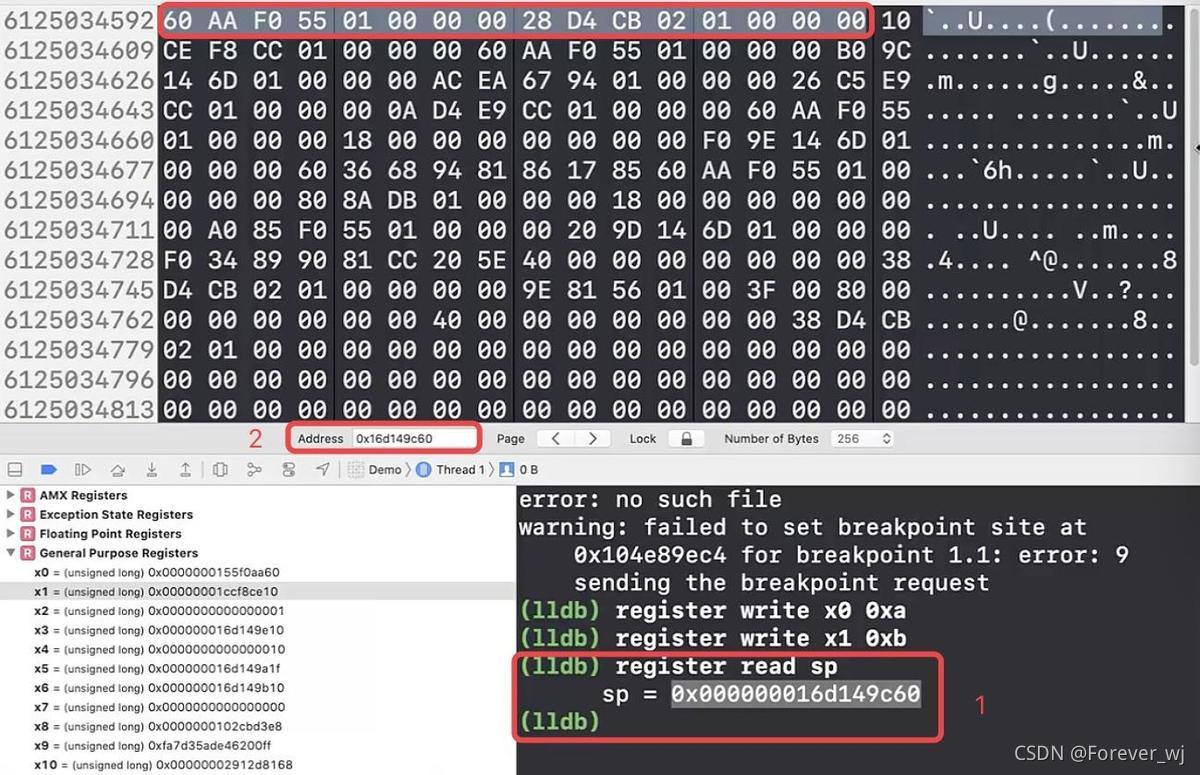
- 然后單步往下執行,發現 x0、x1 已經變成寫入的值:
int A();
int B();
int test() {
int cTemp = 0x1FFFFFFFF;
return cTemp;
}
- (void)viewDidLoad {
[super viewDidLoad];
printf("A");
A();
printf("B");
}
- 查看記憶體變化,發現 sp 拉伸了 32 位元組:
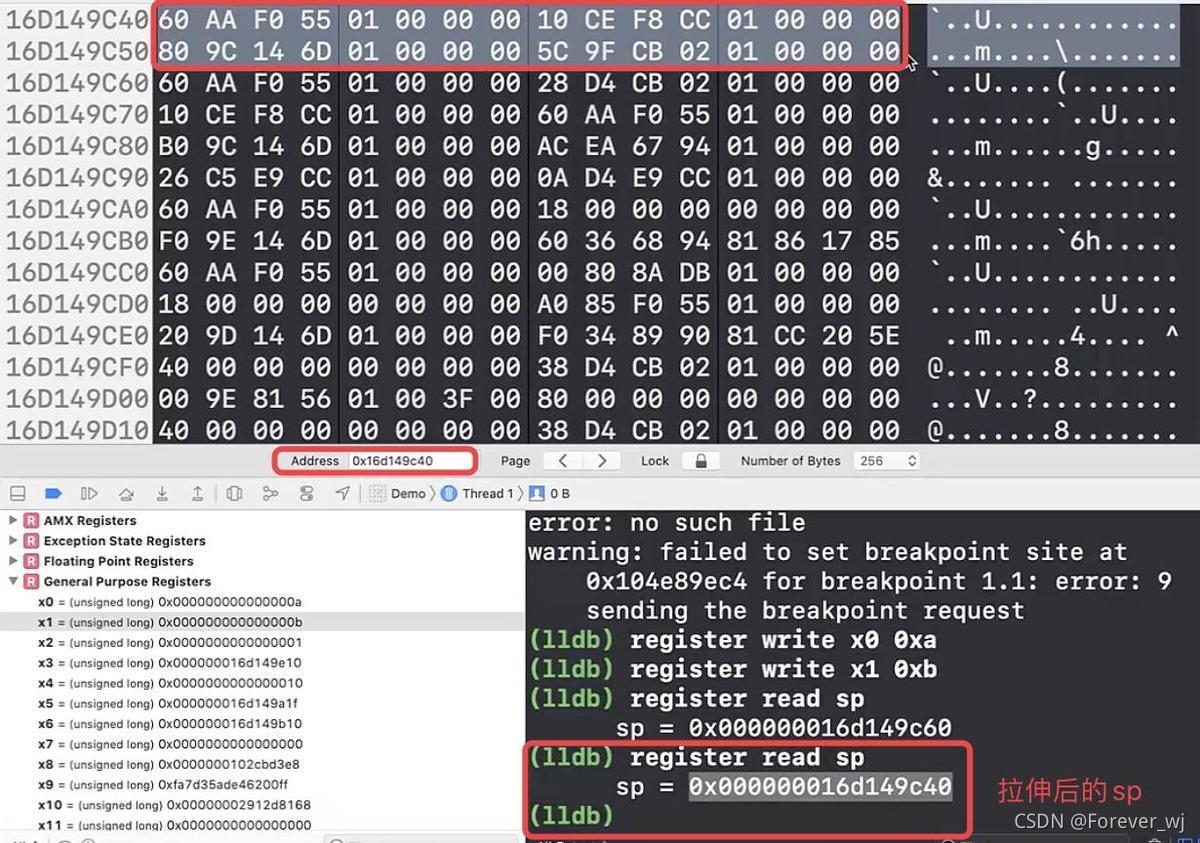
- stp x0, x1, [sp, #0x10]:將 x0、x1 寫入 fp 偏移 0x10 的位置,繼續往下執行一步:
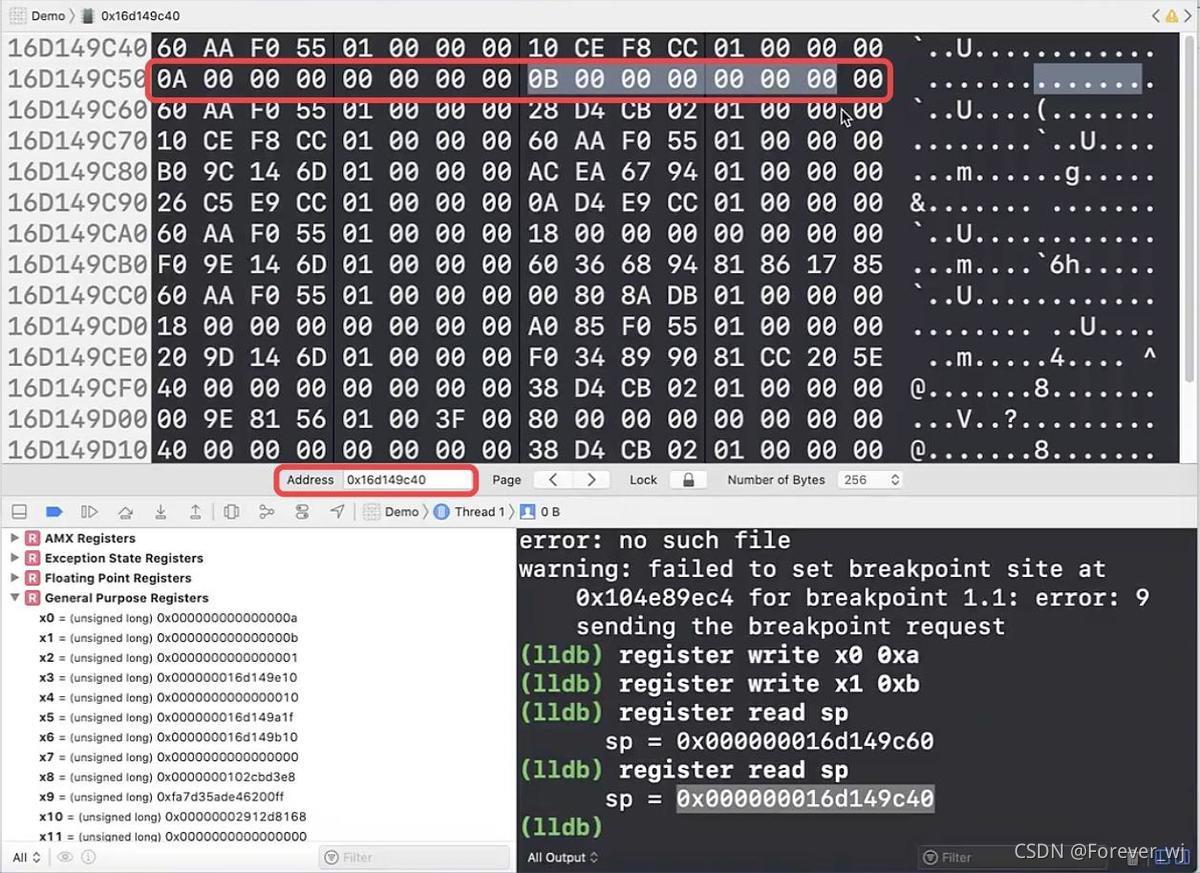
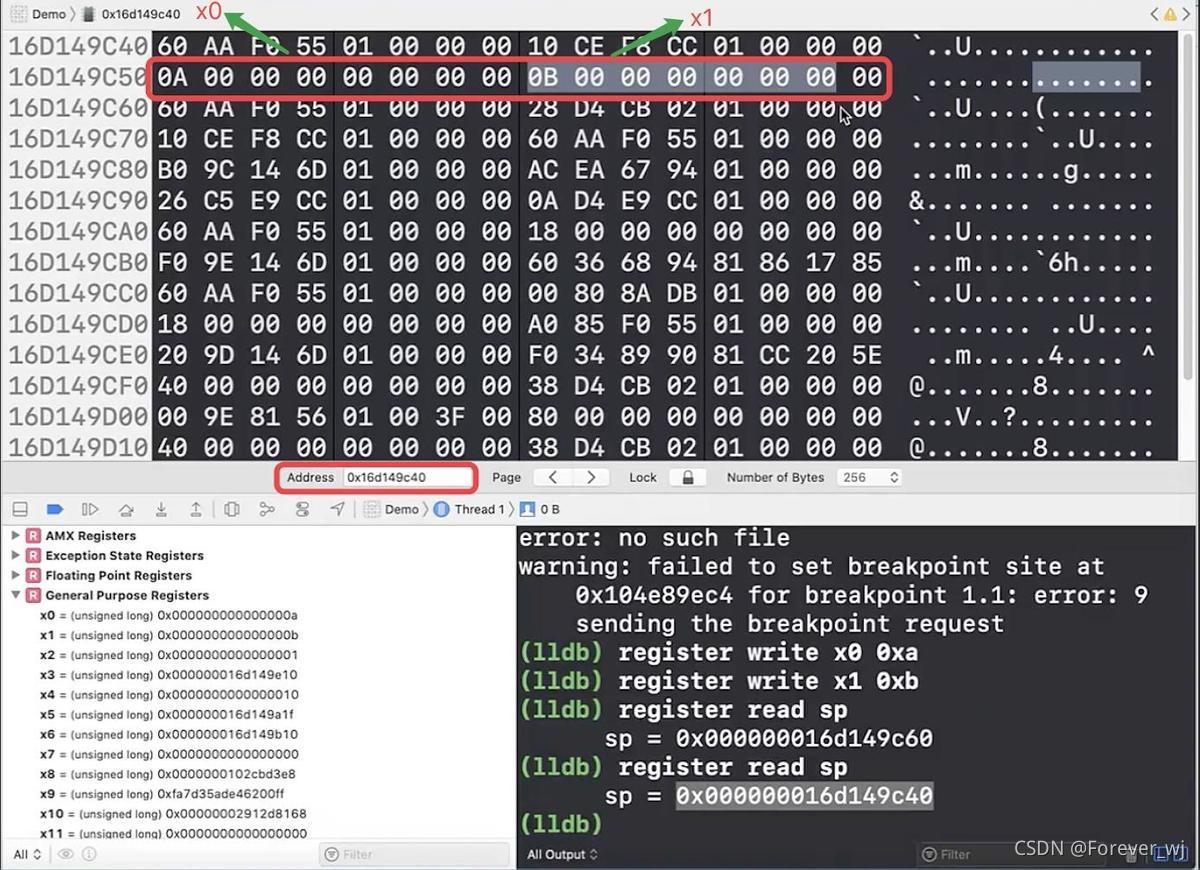
- 此時 sp 的值并沒有變化,還是指向 40:
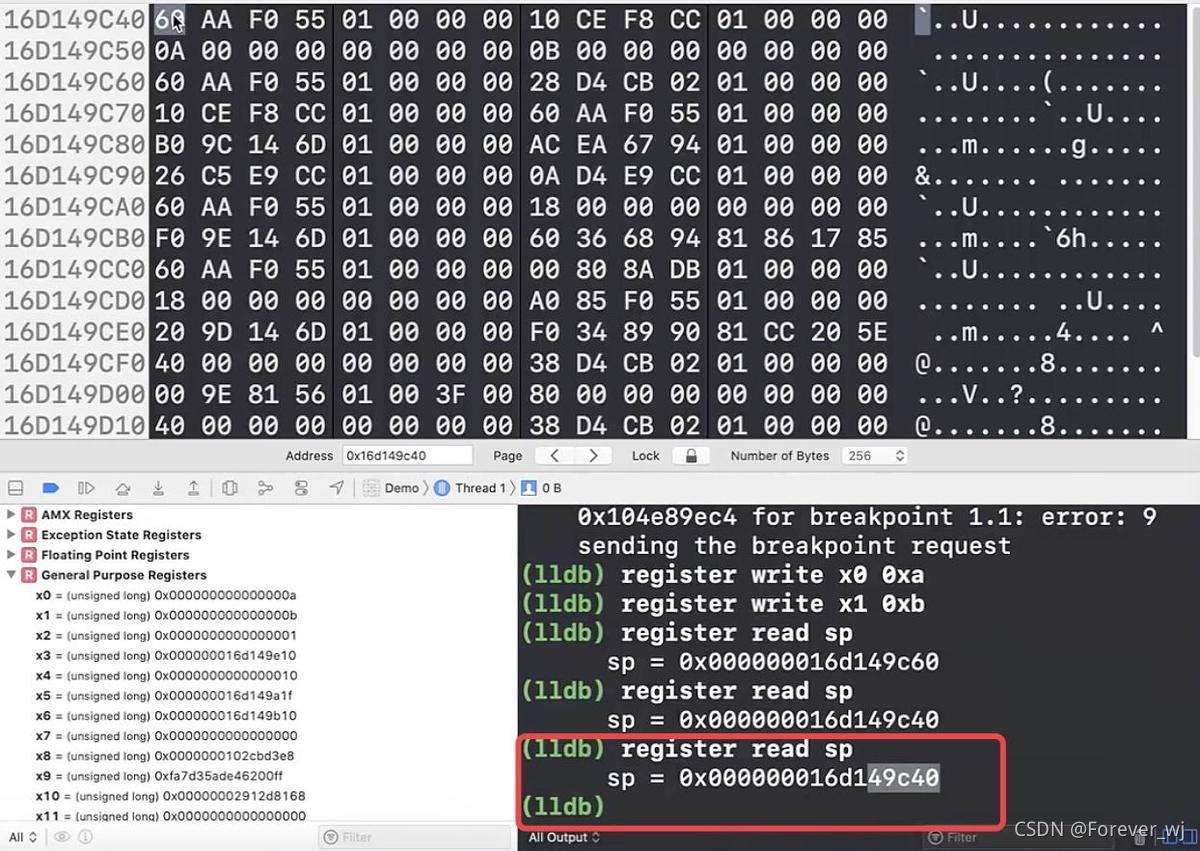
- ldp x1, x0, [sp, #0x10]:讀取 x0,x1 的資料并交換,繼續往下執行一步,此時記憶體并沒有變化:
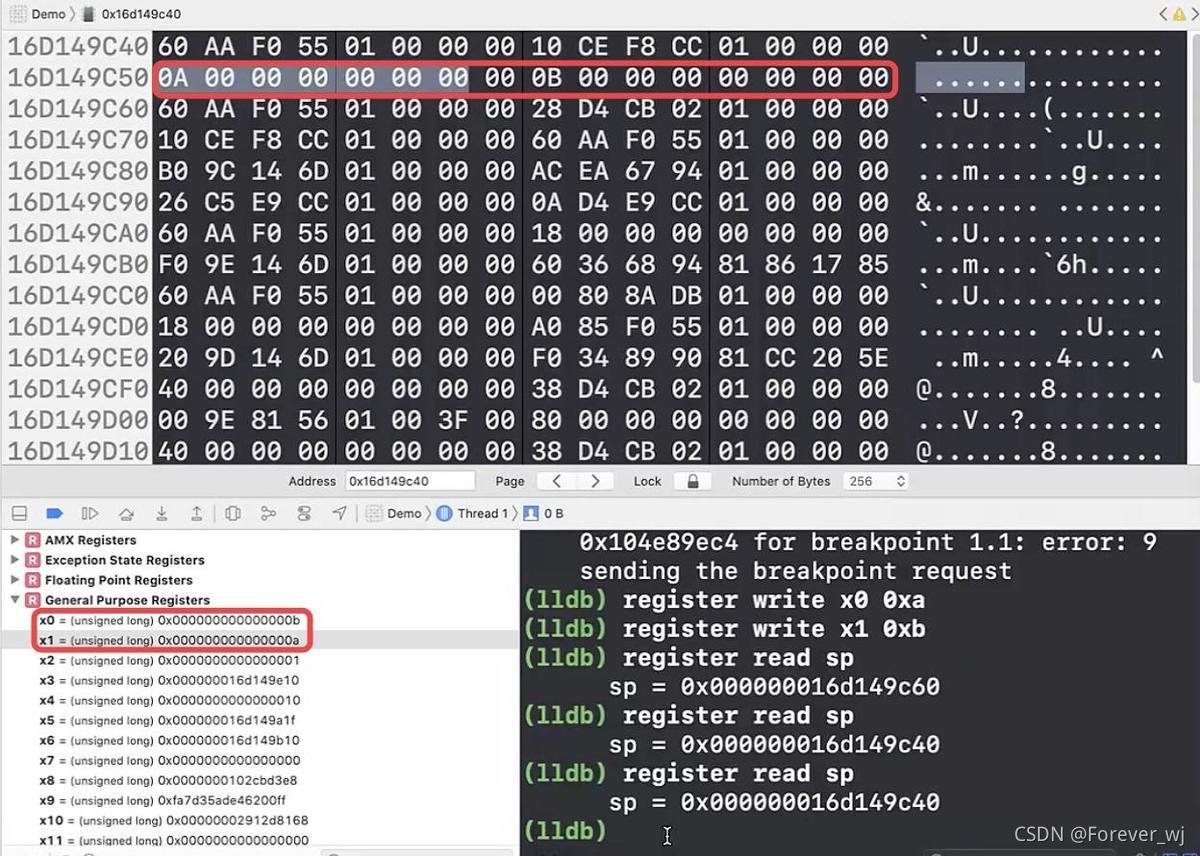
- 再來看 sp 是否有變化?從結果來看,也沒有變化,因此這里只是讀出來進行的交換,并不會導致記憶體變化:
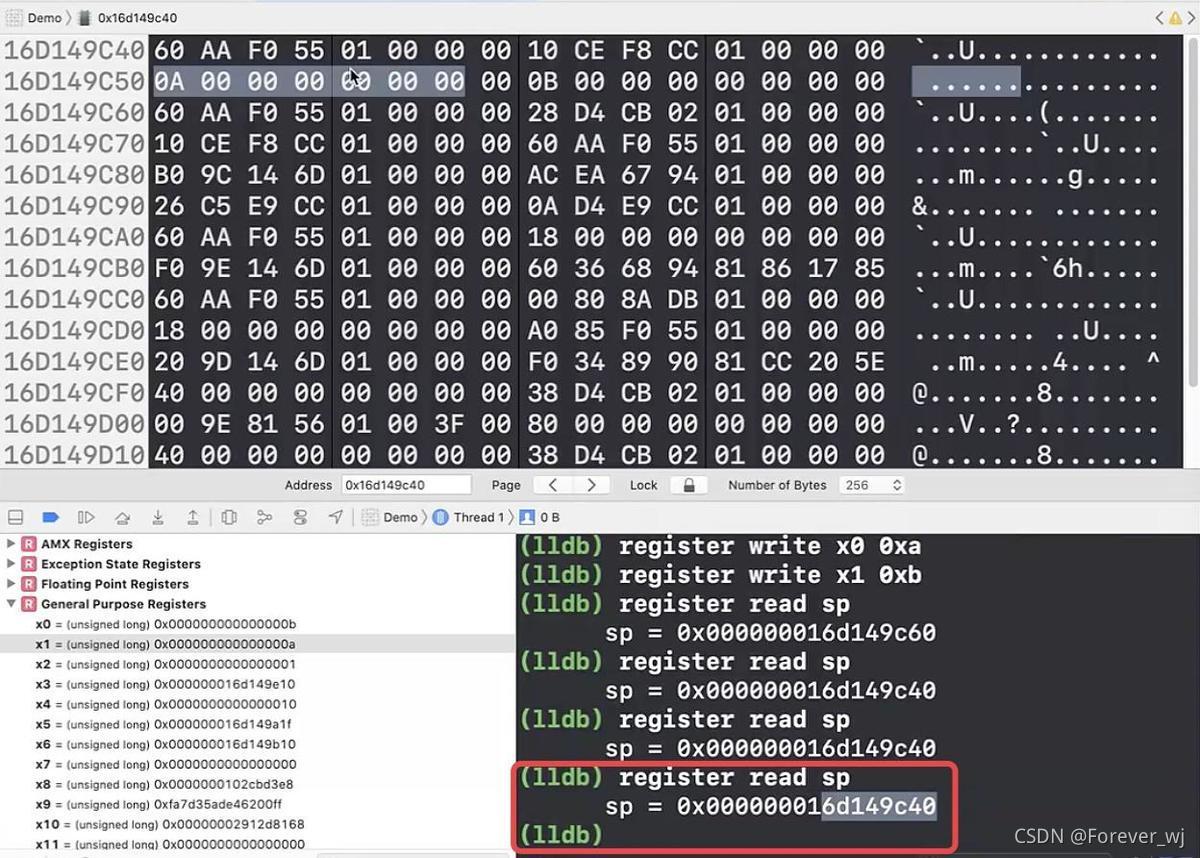
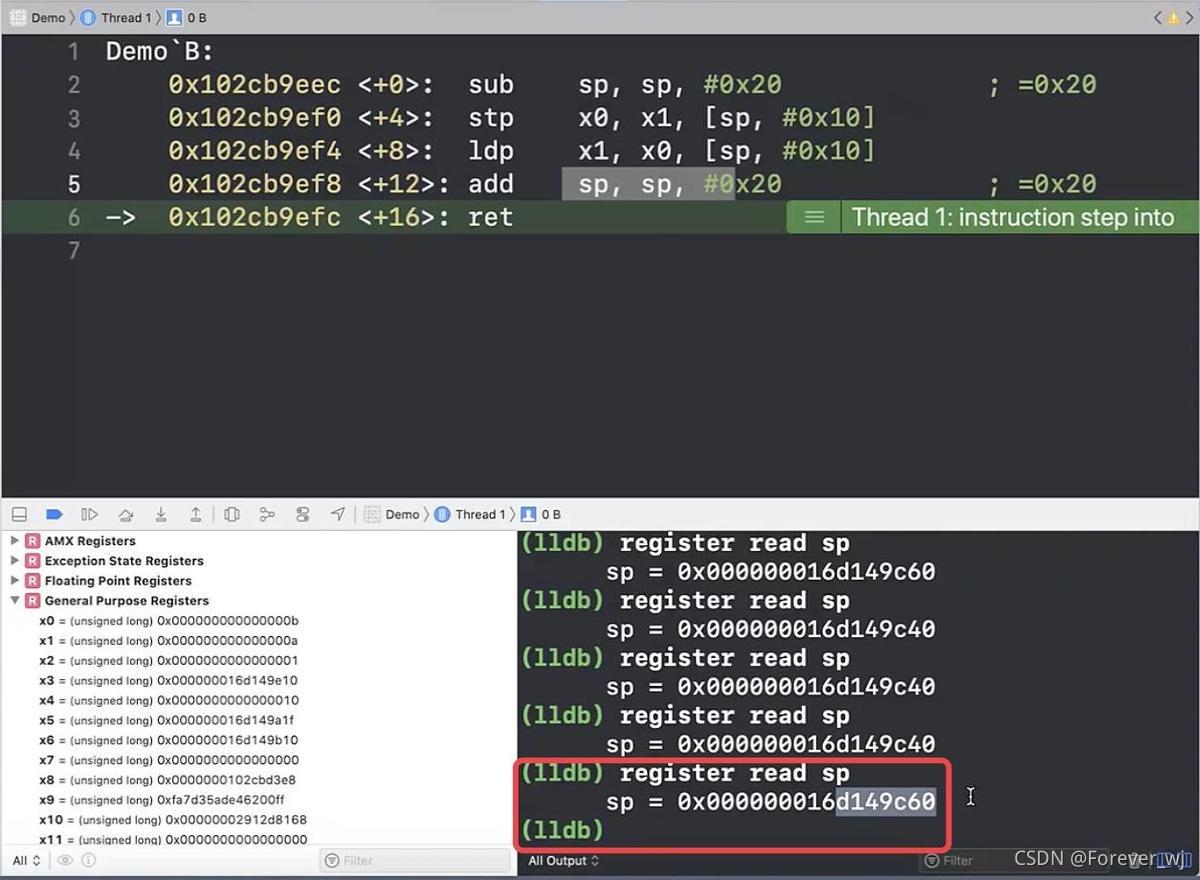
- add sp, sp, #0x20:繼續執行一步,走到堆疊平衡,即 sp 恢復,此時的 a 和 b 仍然在記憶體中,等待著下一輪堆疊拉伸后資料的寫入覆寫,如果此時讀取,讀取到的是垃圾資料:
- 堆疊空間不斷開辟,死回圈,會不會崩潰?通過一個匯編代碼來演示:
// asm.s
.text
.global _B
_B:
sub sp,sp,#0x20
stp x0,x1,[sp,#0x10]
ldp x1,x0,[sp,#0x10];暫存器里面的值進行交換
bl _B
add sp,sp,#0x20
ret
// 呼叫
int B();
int main(int argc, char * argv[]) {
B();
}
- 運行可以發現:死回圈會崩潰,會導致堆疊溢位:

- 堆疊溢位是說堆區和堆疊區的溢位,二者同屬于緩沖區溢位,一旦程式確定,堆疊記憶體空間的大小就是固定的,當資料已經把堆疊的空間占滿時,再往里面存放資料就會超出容量,發生上溢;當堆疊中的已經沒有資料時,再取資料就無法取到了,發生下溢,需要注意的是,堆疊分為順序堆疊和鏈堆疊,鏈堆疊不會發生溢位,順序堆疊會發生溢位,

- 這樣,就解決了iOS逆向之初識匯編的基礎理論最后遺留問題的原因分析,
三、bl 與 ret 指令
① 概念
- bl 標號:
-
- 將下一條指令的地址放入 lr(x30)暫存器(lr 保存的是回家的路)(即l);
-
- 轉到標號處執行指令(即 b),
- ret:
-
- 默認使用 lr(x30)暫存器的值,通過底層指令提示 CPU 此處作為下條指令地址;
-
- arm64 平臺的特色指令,它面向硬體做了優化處理,
② 實戰演練
- 現有如下的 bl、ret 相關的匯編指令:
.text
.global _A, _B
_A:
mov x0. #0xaaaa
bl _B
mov x0, #0xaaaa
ret
_B:
mov x0, #0xbbbb
ret
- 斷點執行:
int A();
int B();
int test() {
int cTemp = 0x1FFFFFFFF;
return cTemp;
}
- (void)viewDidLoad {
[super viewDidLoad];
printf("A");
A();
printf("B");
}
- 可以看到,A() 和 print 之間還有幾個匯編操作,這是什么意思呢?
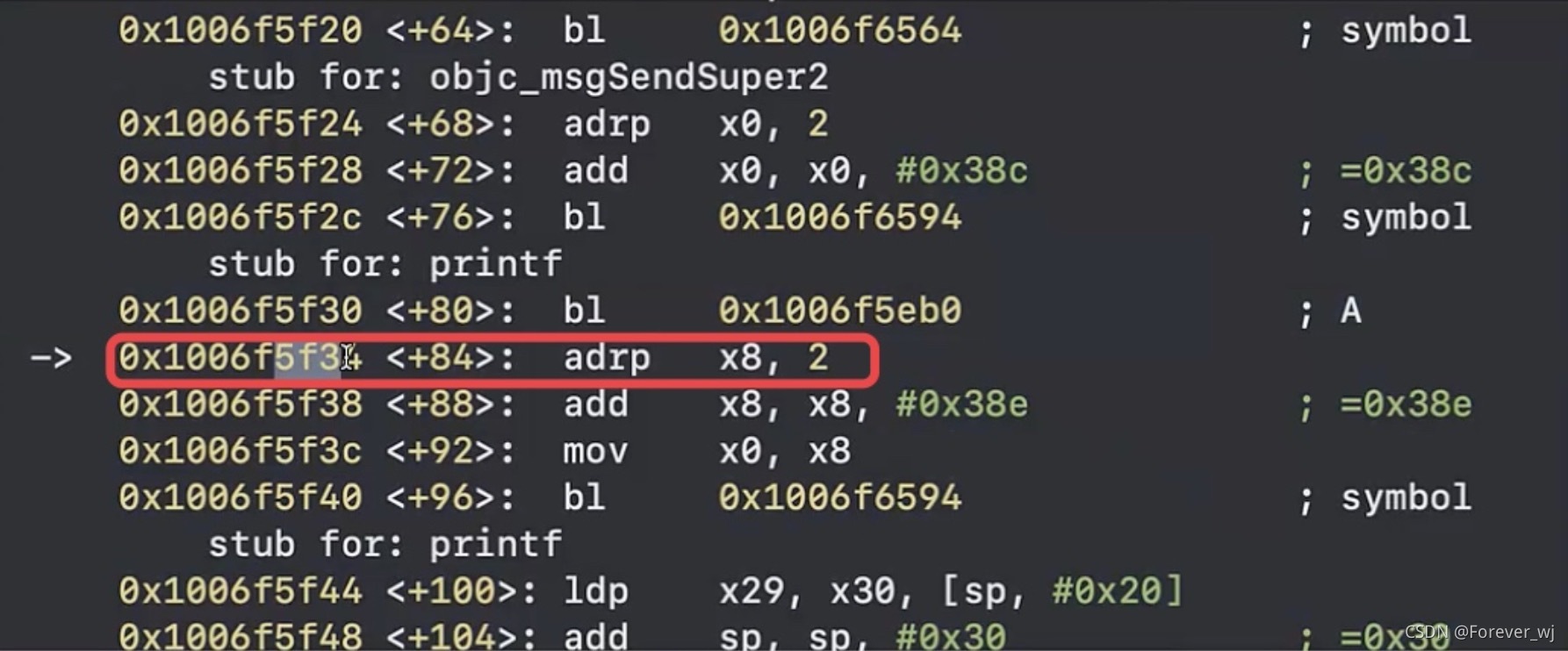
- 執行 mov x0. #0xaaaa:x0 變成 aaaa,此時此刻 lr 暫存器保存的是 5f34:
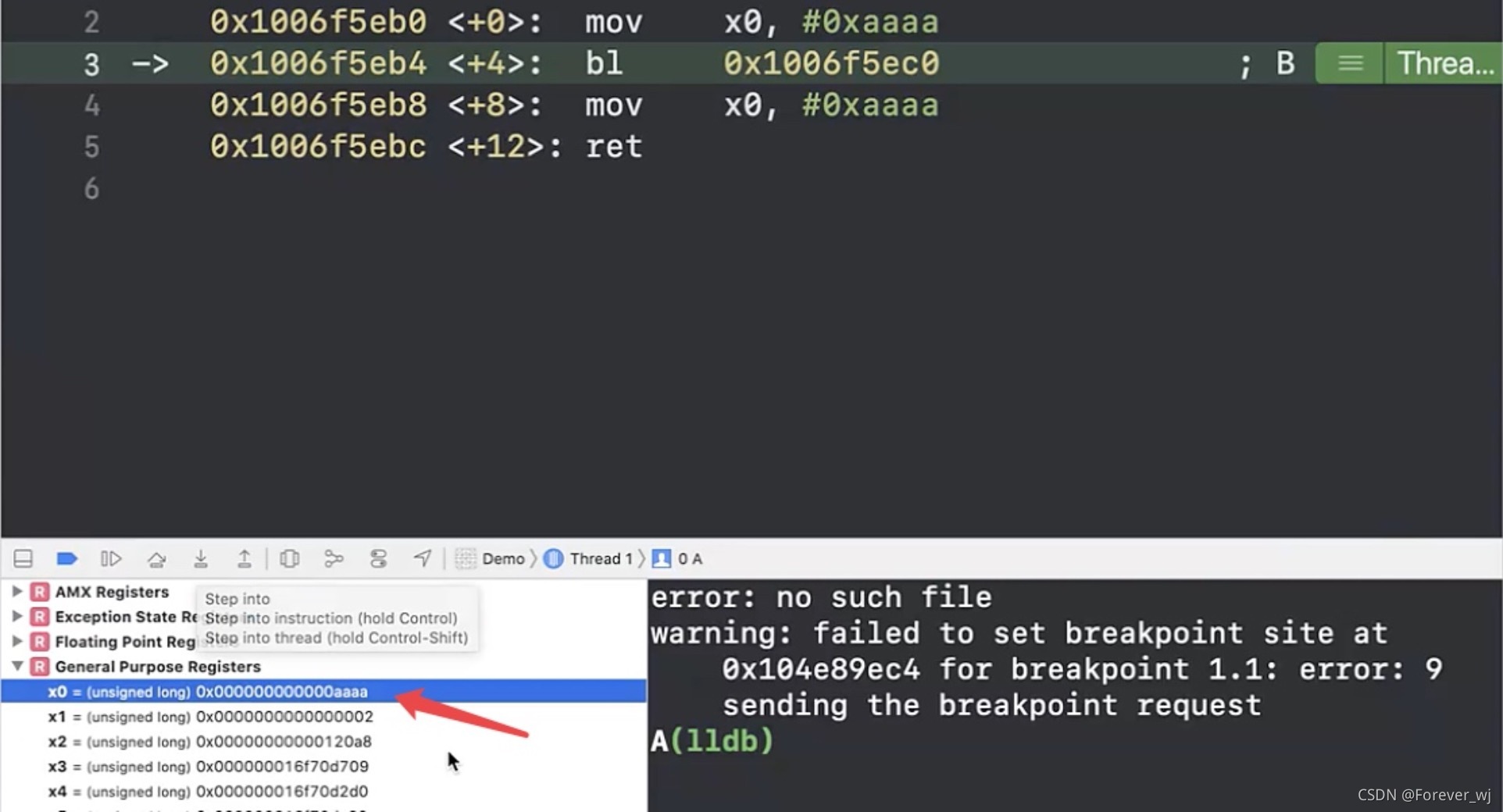
- 驗證 lr 是否保存的是 5f34,通過查看暫存器,可以發現結果與預期是一致的:
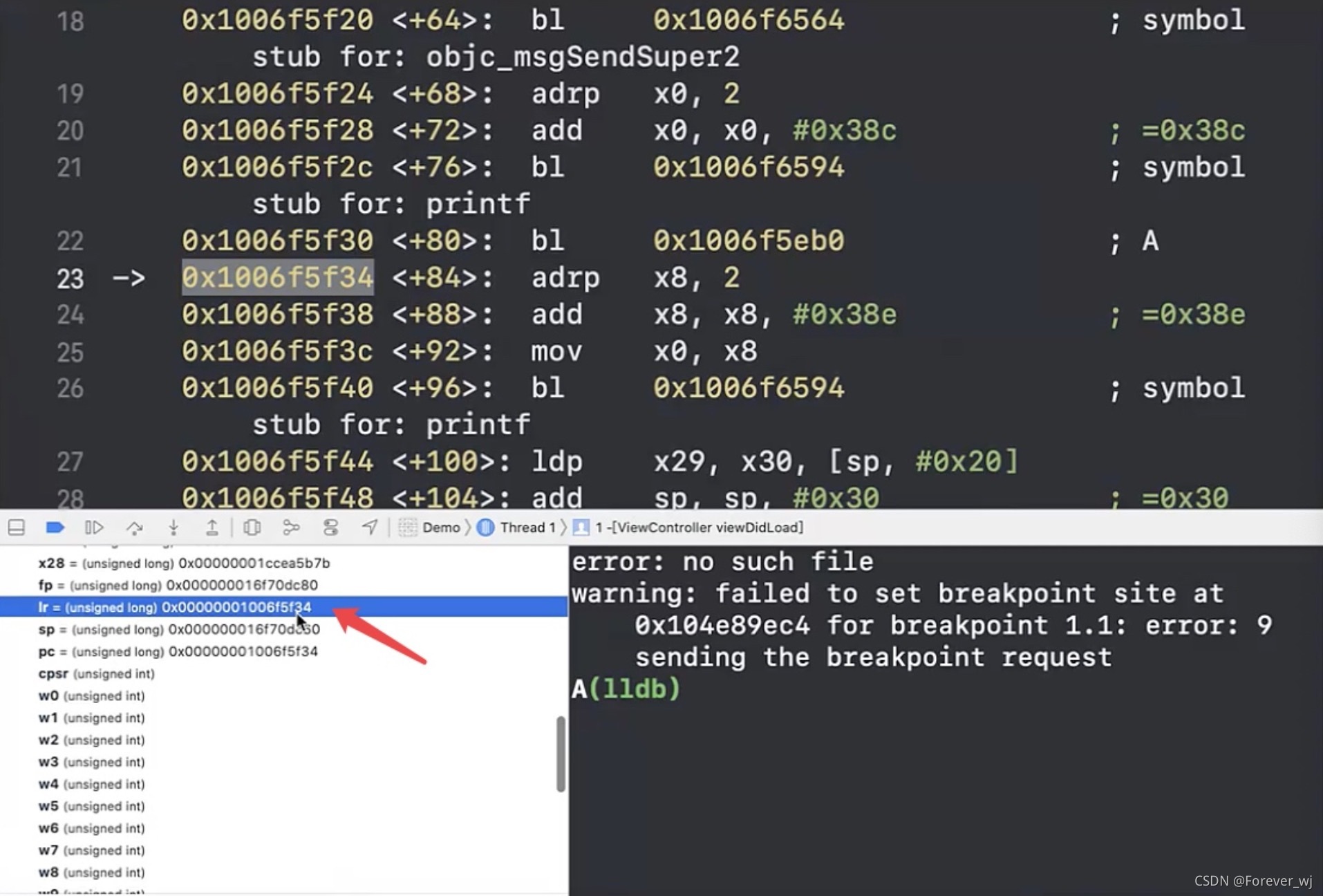
- 繼續執行 bl _B,跳轉到 B,此時的 lr 會變成 A 中 bl 的下一條指令的地址 5eb8:
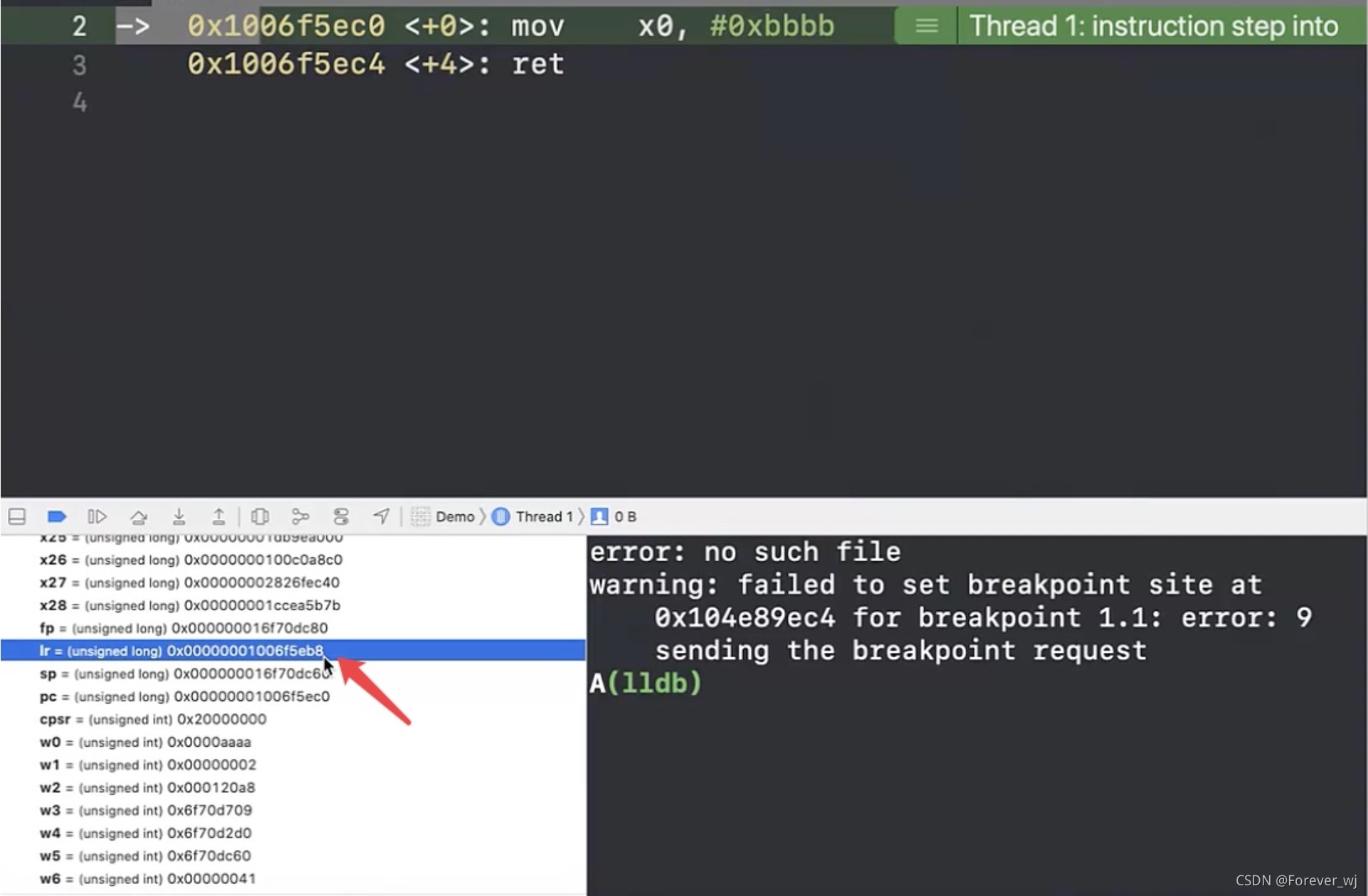
- 執行完 B 中的 mov x0, #0xbbbb,x0 變成 bbbb:
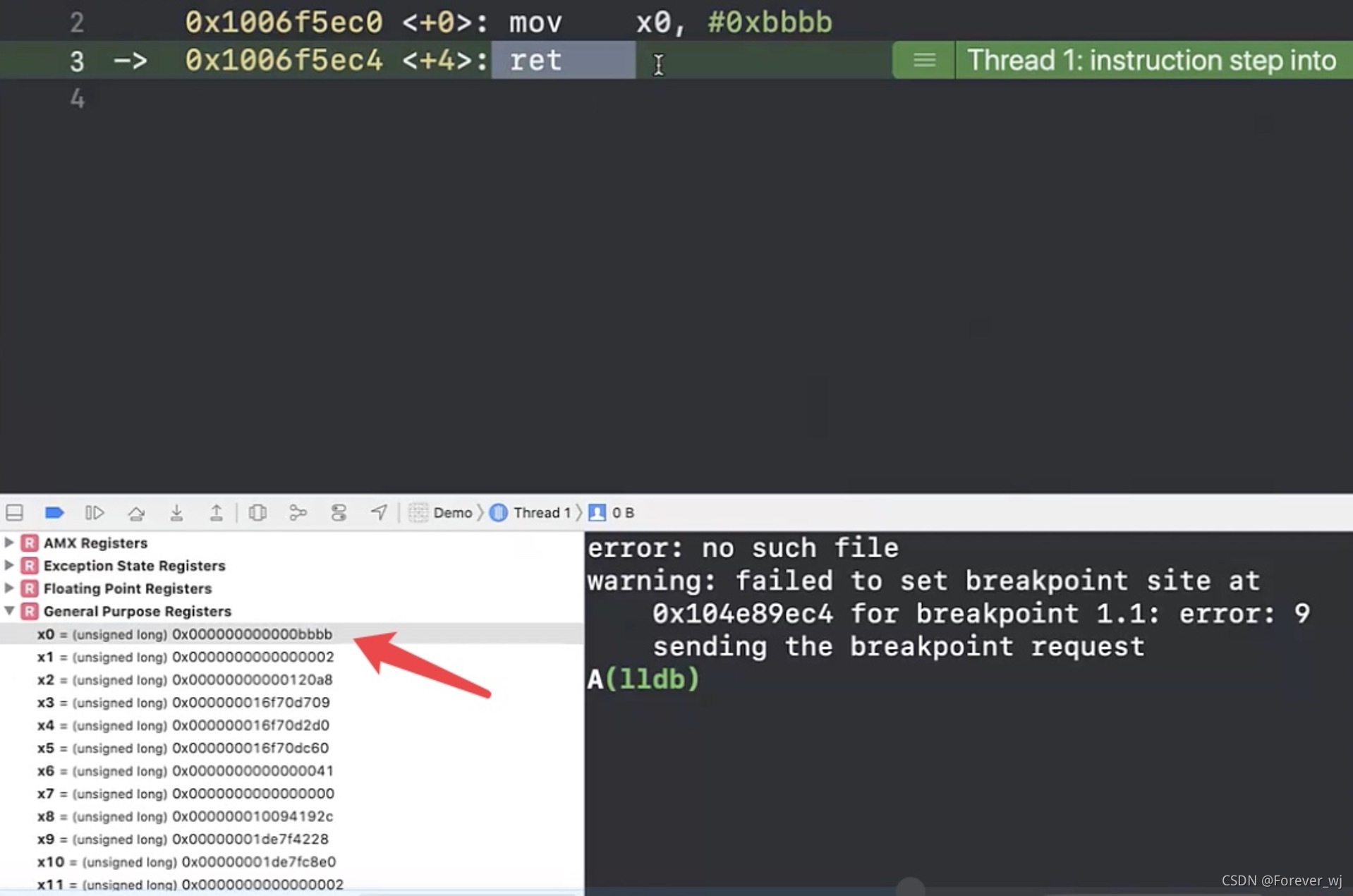
- 執行 B 中的 ret,會回到 A 中 5eb8:
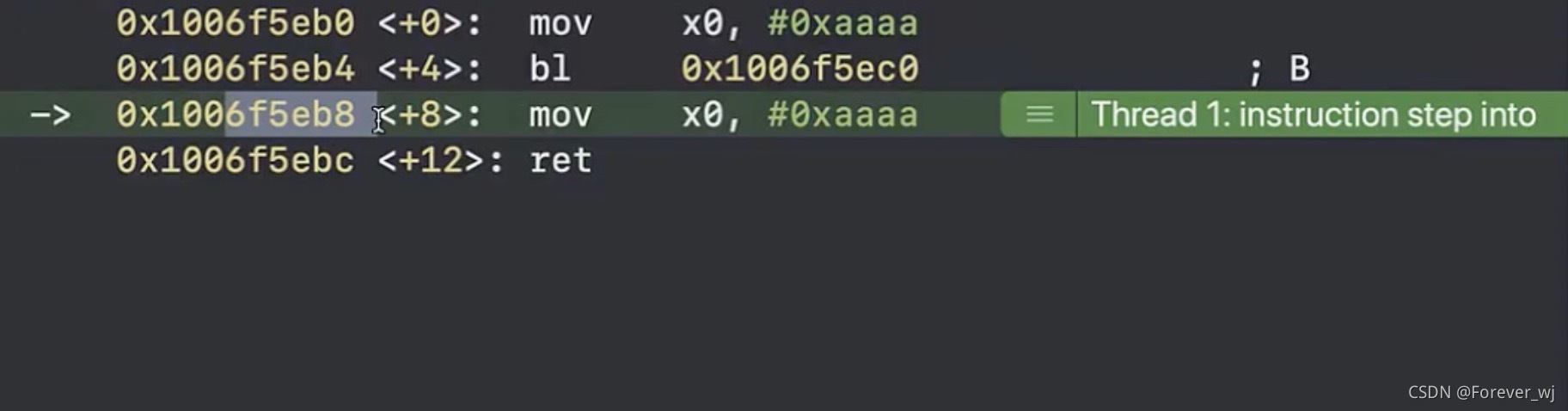
- 繼續執行 A 中的 ret,會再次回到 5eb8:

- 執行到這里,發現死回圈了,主要是因為 lr 一直是 5eb8,ret 只會看 lr,其中 pc 是指接下來要執行的記憶體地址,ret 是指讓 CPU 將 lr 作為接下來執行的地址(相當于將 lr 賦值給 pc):
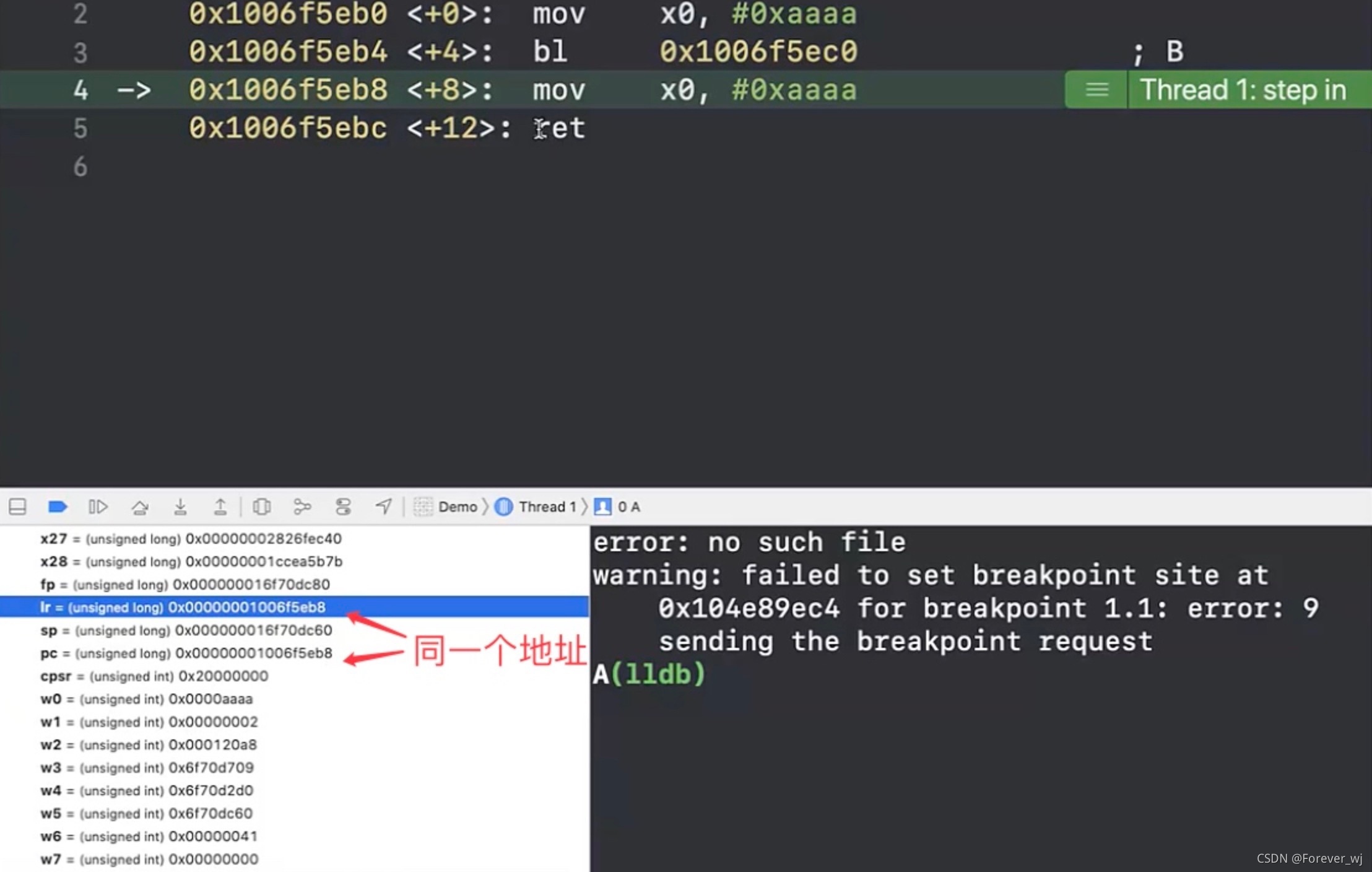
- 此時 B 回到 A 沒問題,那么 A 回到 viewDidload 該怎么處理呢?這就需要在 A 的 bl 之前保存 lr 暫存器,但是不可以保存到其他暫存器上,這是因為不安全,不確定這個暫存器會在什么時候被別人使用,正常應該保存到堆疊區域,
- 系統中函式嵌套是如何回傳?來看下系統是如何操作的,例如:d -> c -> viewDidLoad:
void d() {
}
void c() {
d();
return;
}
- (void)viewDidLoad {
[super viewDidLoad];
printf("A");
c();
printf("B");
}
- 查看匯編,斷點斷在 c 函式:
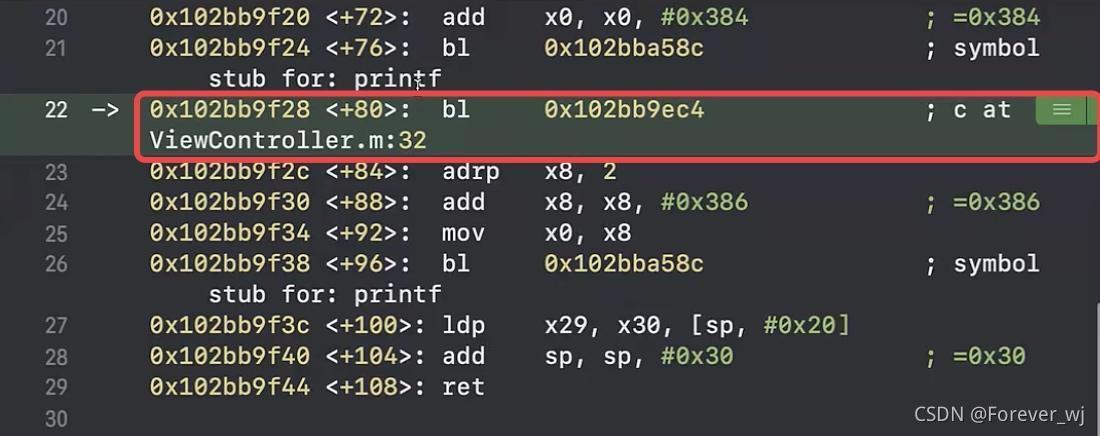
- 進入 c 函式的匯編:
-
- stp x29,x30,[sp,#-0x10]!:邊開辟堆疊,邊寫入,其中 x29 就是 fp,x30 是 lr,! 表示將這里算出來的結果,賦值給 sp;
-
- lsp x29,x30,[sp],#0x10:讀取 sp 指向地址的資料,放入 x29、x30,然后 #0x10 表示將 sp+0x10,賦值給 sp,

- 當有函式嵌套呼叫時,將上一個函式的地址通過 x30(即 lr)放在堆疊中保存,保證可以找到回家的路,如下圖所示:
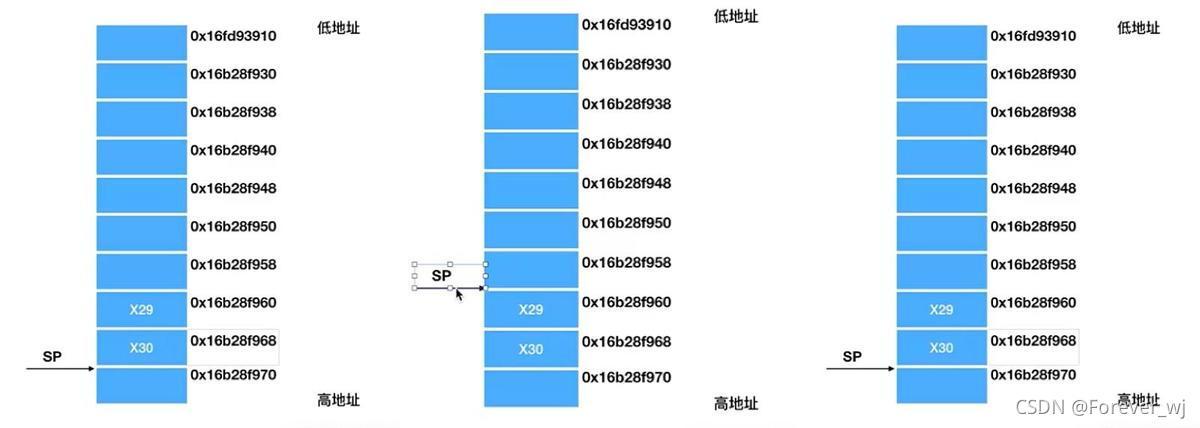
- 自定義匯編代碼完善:_A中保存“回家的路”,根據系統的函式嵌套操作,最終在 _A 中增加了如下匯編代碼,用于保存“回家的路”:
// 導致死回圈的匯編代碼
_A:
mov x0. #0xaaaa
bl _B
mov x0, #0xaaaa
ret
// 增加lr保存:可以找到回家的路
_A:
sub sp, sp, #0x10 // 拉伸
str x30, [sp] // 存
mov x0, #0xaaaa
// 保護lr暫存器,存盤到堆疊區域
bl _B
mov x0, #0xaaa
ldr x30, [sp] // 修改lr,用于A找到回家的路
add sp, sp, #0x10 // 堆疊平衡
ret
- 修改 _A、_B:改成簡寫形式,其中 lr 是 x30 的一個別名:
_A:
sub sp, sp, #0x10 // 拉伸
str x30, [sp] // 存
mov x0, #0xaaaa
// 保護lr暫存器,存盤到堆疊區域
bl _B
mov x0, #0xaaa
ldr x30, [sp] // 修改lr,用于A找到回家的路
add sp, sp, #0x10 // 堆疊平衡
ret
_B:
mov x0, #0xbbbb
ret
// 改成簡寫形式
_A:
//sub sp, sp, #0x10 // 拉伸
//str x30, [sp] // 存
str x30, [sp, #-0x10]
mov x0, #0xaaaa
// 保護lr暫存器,存盤到堆疊區域
bl _B
mov x0, #0xaaa
// ldr x30, [sp] // 修改lr,用于A找到回家的路
// add sp, sp, #0x10 // 堆疊平衡
ldr x30, [sp], #0x10 // 將sp的值讀取出來,給到x30,然后sp += 0x10
ret
_B:
mov x0, #0xbbbb
ret
- 查看此時 sp 暫存器的地址:
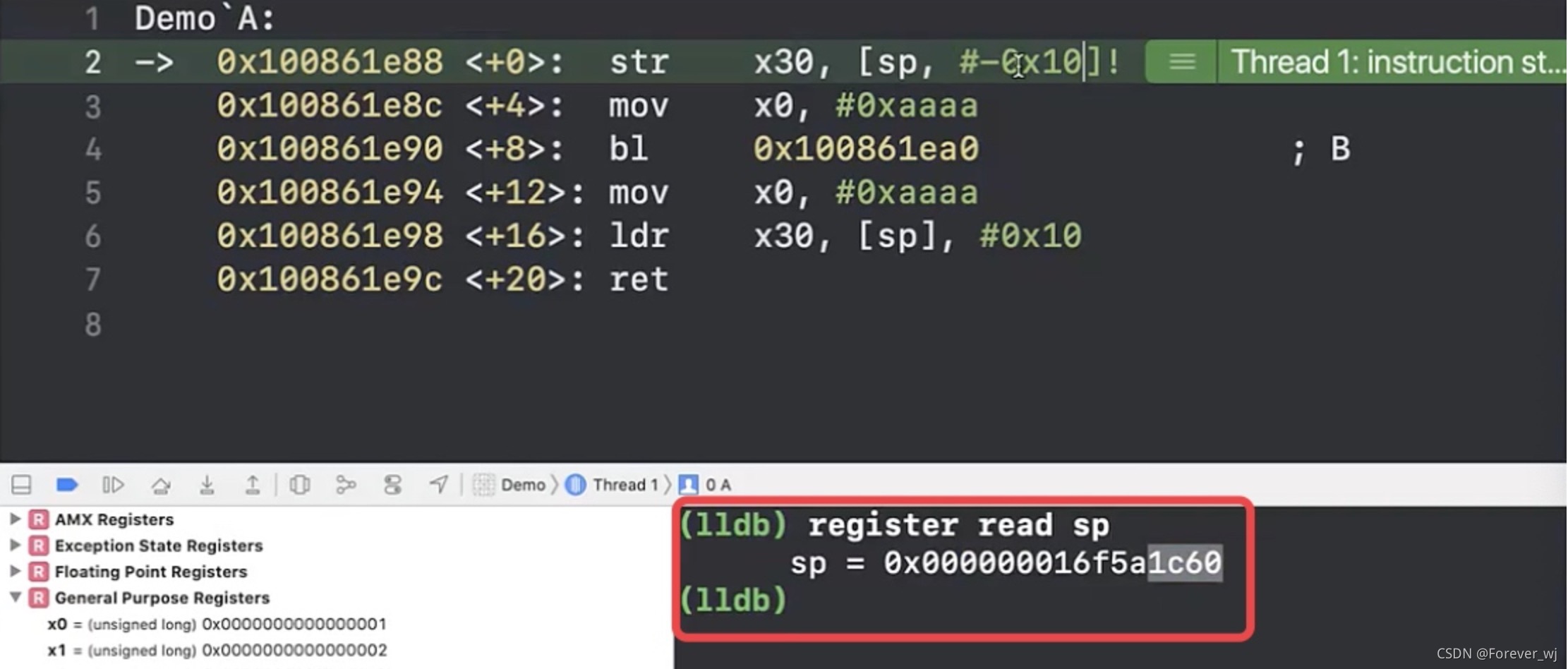
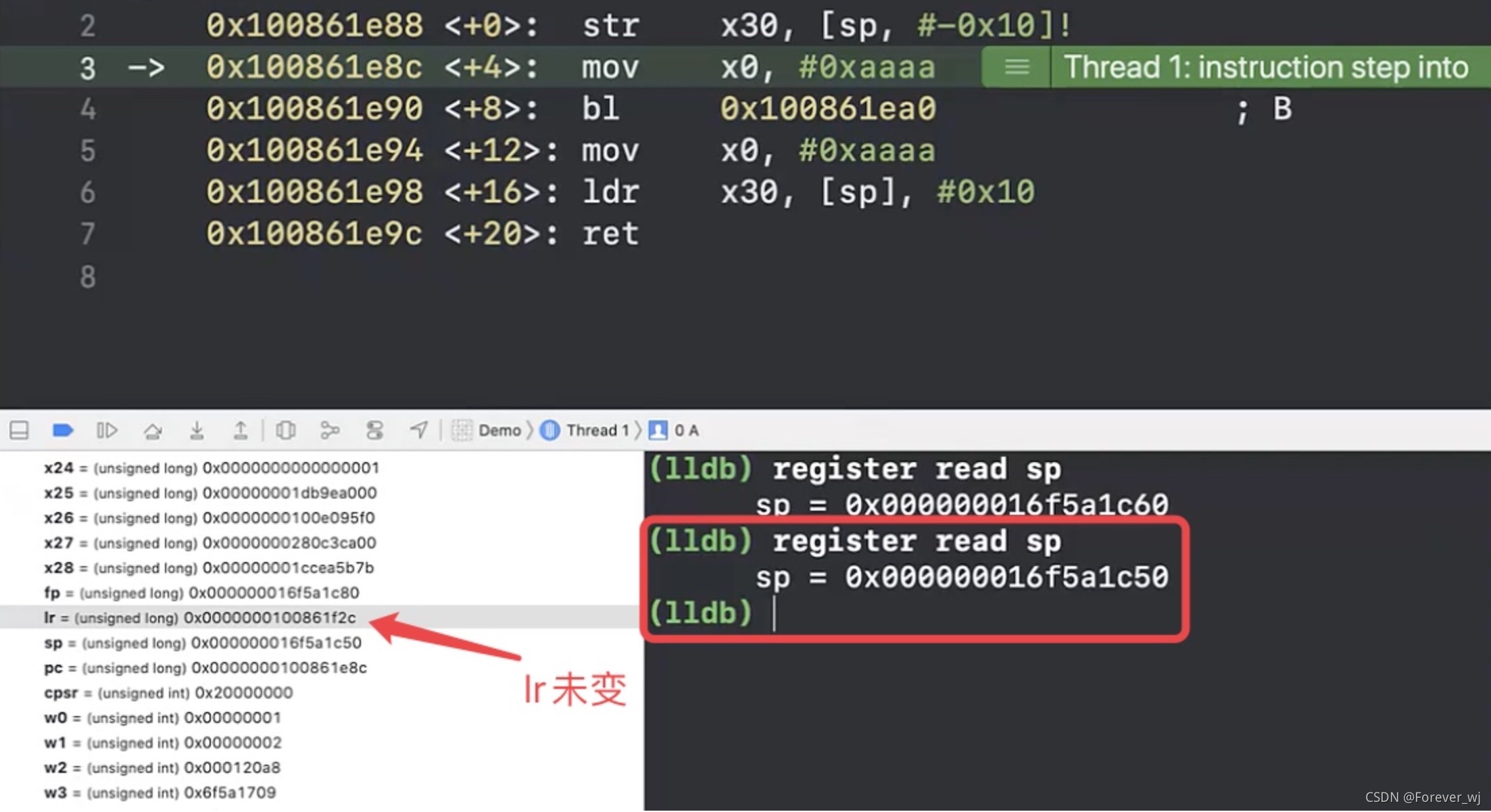
- 執行 str x30, [sp, #-0x10],繼續查看 sp,發現 sp 發生了變化,但是此時 lr 沒變:
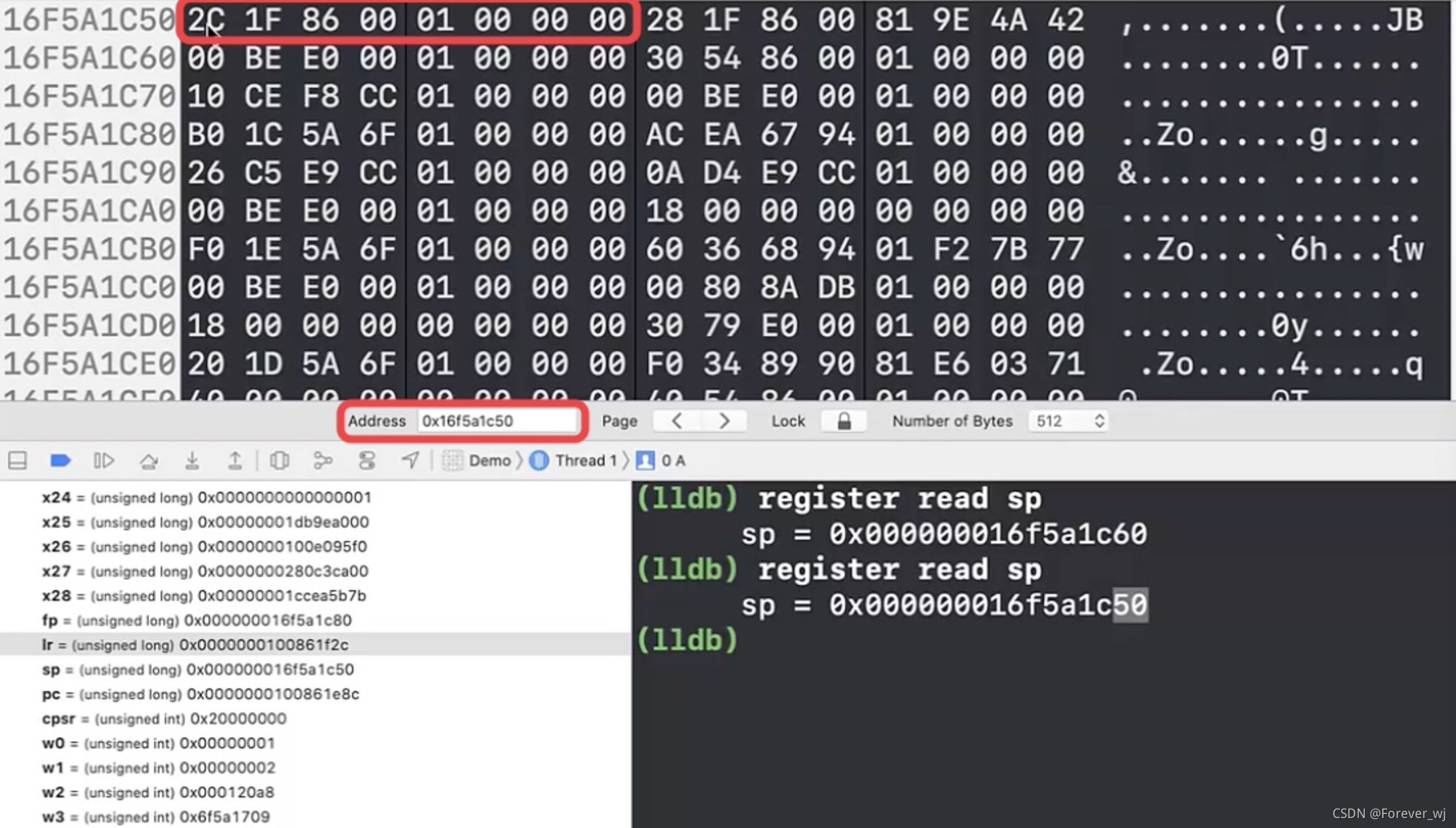
- 查看 0x16f5a1c50 的 memory,此時放入的是 lr 的值 861f2c,即 ViewDidLoad 中的 bl 下一條指令的地址,目前只存放 8 個位元組(1 個暫存器):
- 執行 A 中的 mov x0, #0xaaaa:x0 變成 aaaa:
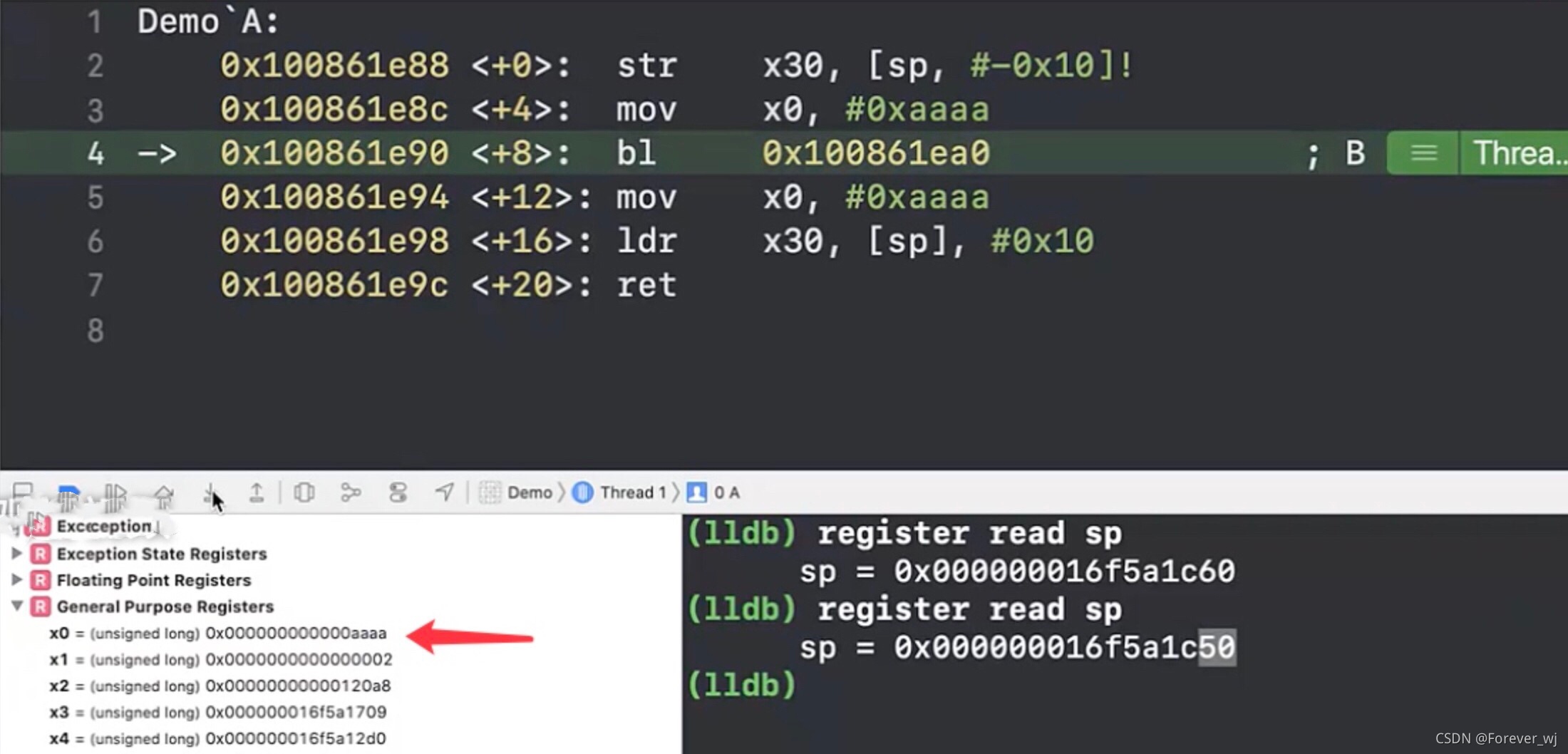
- 執行 B 的 ret:從 B 回到 A,此時 lr 還是 1e94:
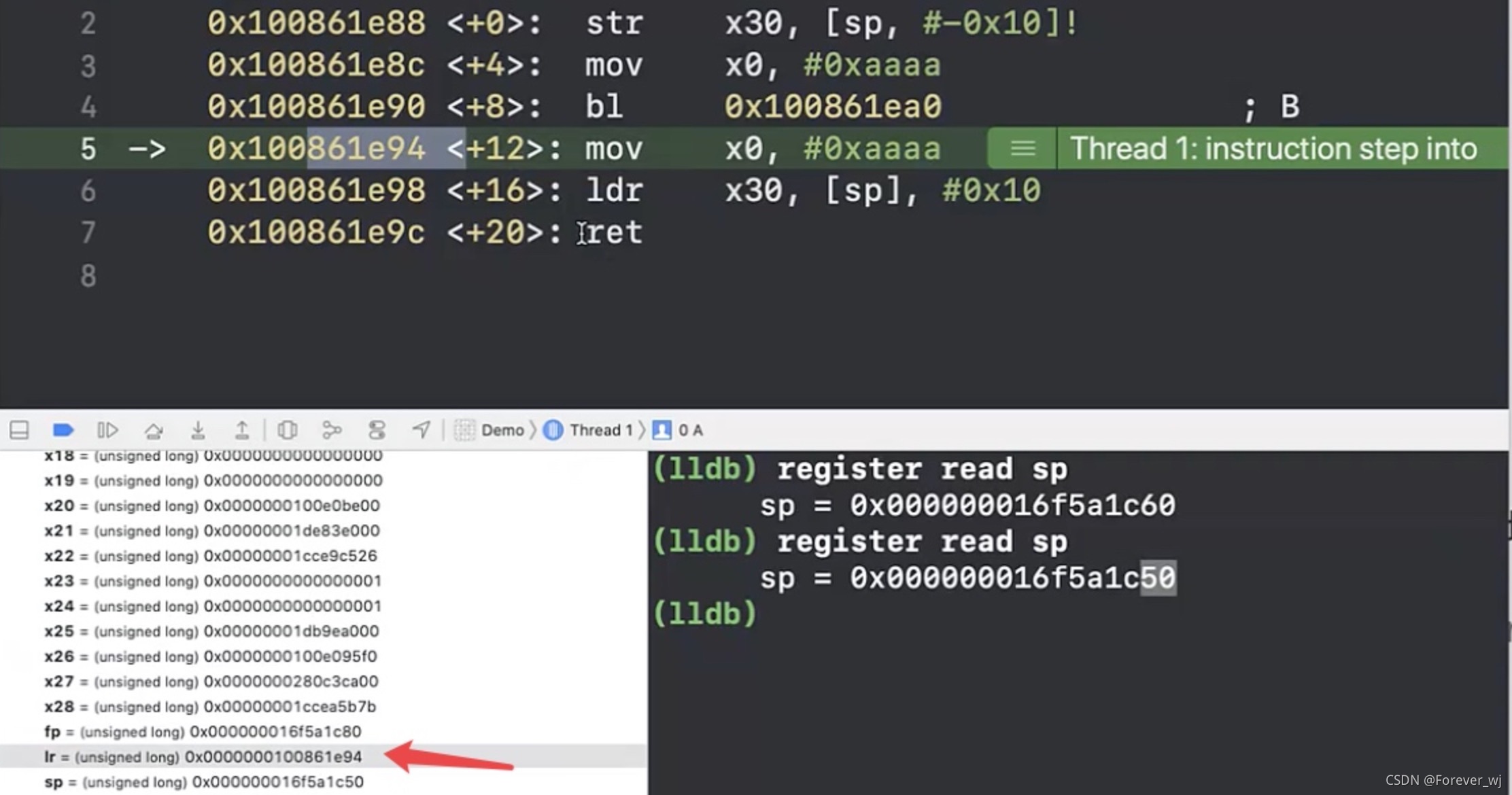
- 執行 A 中的 ldr x30, [sp], #0x10:
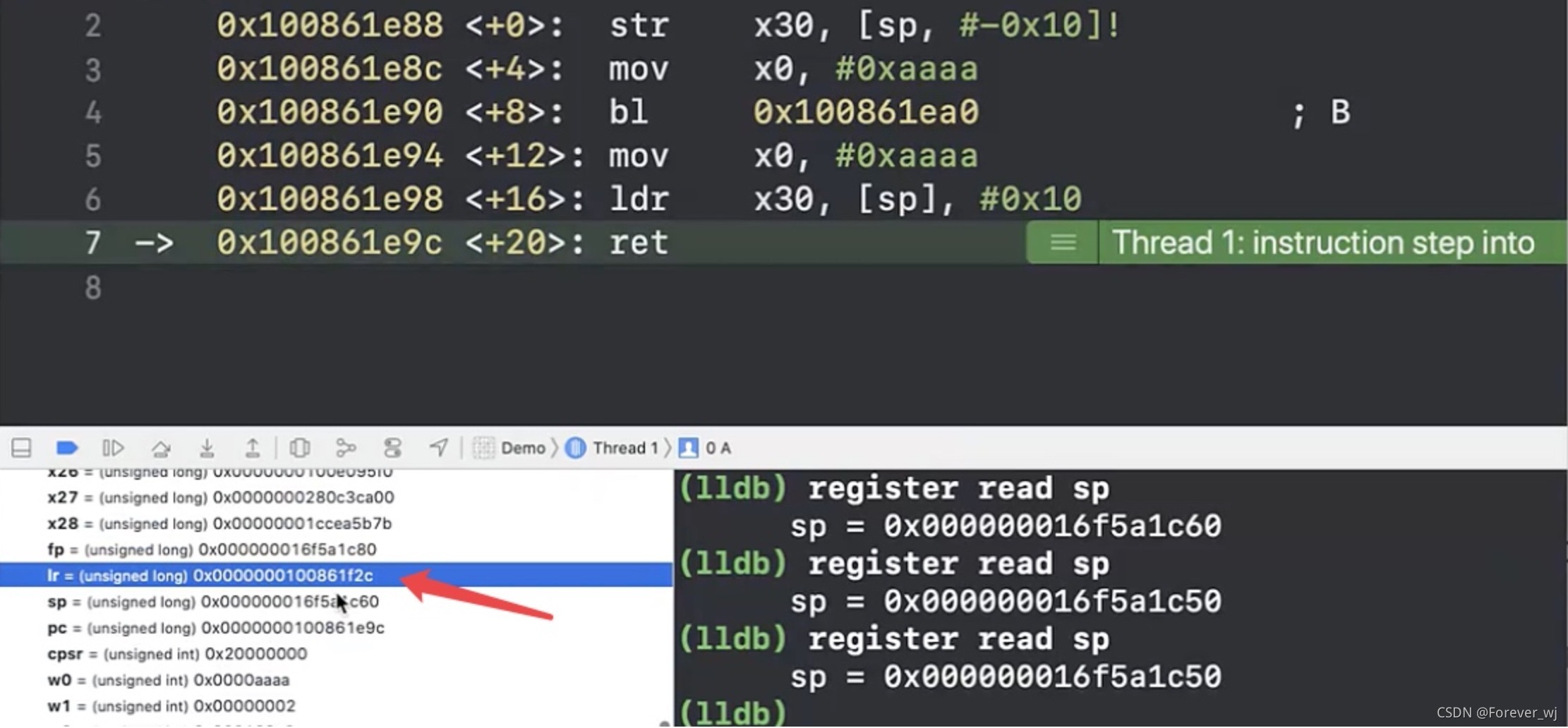
- 發現此時 sp 也變了,從 0x16f5a1c50->0x16f5a1c60,從這里可以看出,A 找到了“回家的路”:

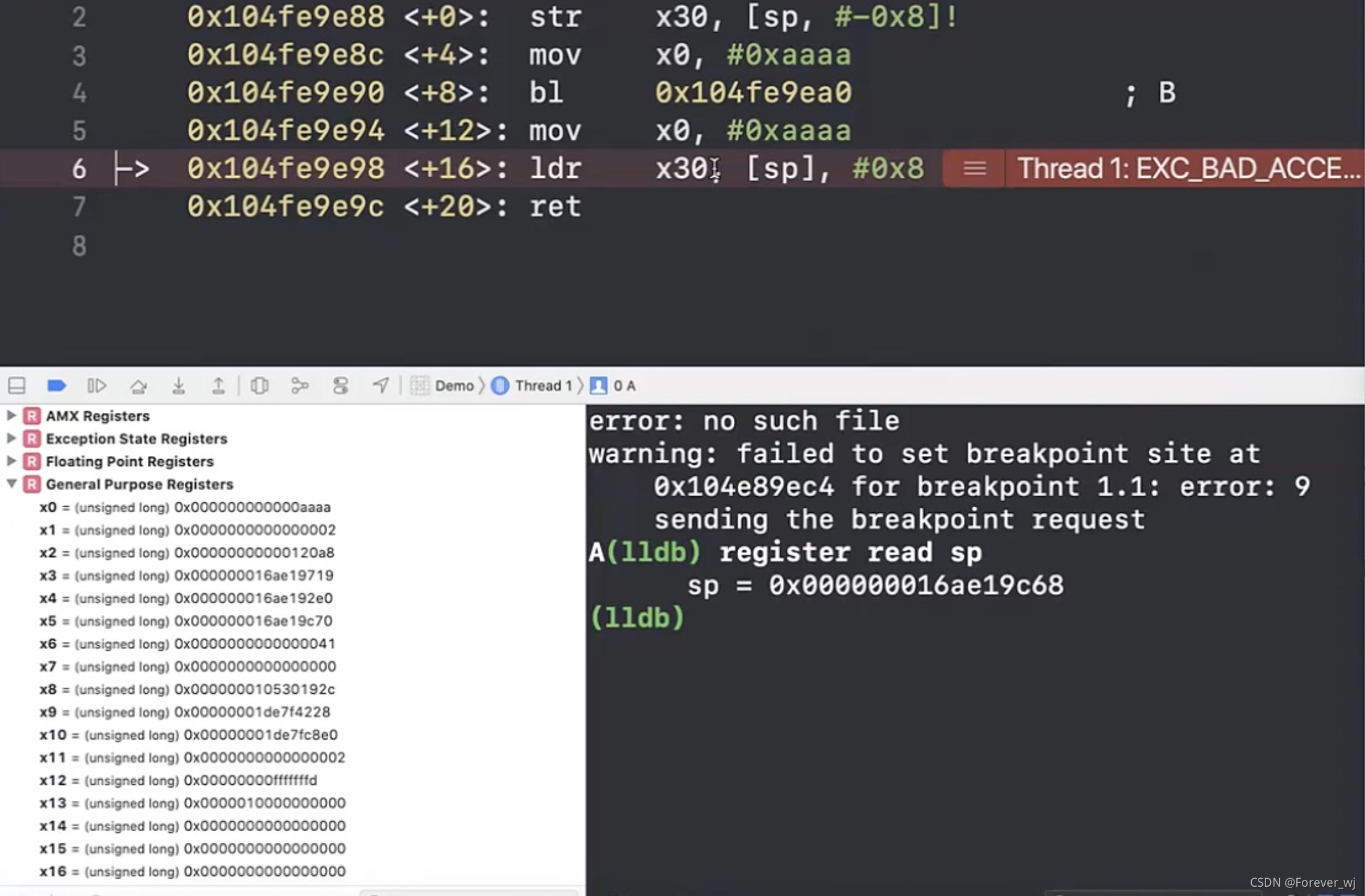
- 為什么是拉伸 16 位元組,而不是 8 位元組呢?通過手動嘗試,寫入沒問題,讀取時會崩潰:因為 sp 中,對堆疊的操作必須是 16 位元組對齊的,所以會在做堆疊的操作時就會崩潰(sp 堆疊里面的操作必須是 16 位元組對齊,崩潰是在堆疊的操作時發生):
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/299299.html
標籤:其他
下一篇:Kotlin 快速入門