Swift 是如何管理協議型別與泛型型別的生命周期與方法呼叫?
協議型別在記憶體中的存盤形式是 Extential Container,Extential Container 占 5 個記憶體單元(也稱 詞),其作用如下:
- 3 個詞作為 Value Buffer,
- 1 個詞作為 Value Witness Table 的索引,主要用于管理生命周期,
- 1 個詞作為 Protocol Witness Table 的索引,主要用于管理方法呼叫,

泛型型別由于在呼叫時能夠確定具體的型別,所以不需要使用 Extential Container,在呼叫泛型方法時,只需要將 Value Witness Table/Protocol Witness Table 作為額外引數進行傳遞,
記憶體管理
泛型型別使用 VWT 進行記憶體管理,VWT 由編譯器生成,其存盤了該型別的 size、aligment(對齊方式)以及針對該型別的基本記憶體操作,其結構如下所示(以 C 代碼表示):
struct value_witness_table {
size_t size, align;
void (*copy_init)(opaque *dst, const opaque *src, type *T);
void (*copy_assign)(opaque *dst, const opaque *src, type *T);
void (*move_init)(opaque *dst, const opaque *src, type *T);
void (*move_assign)(opaque *dst, const opaque *src, type *T);
void (*destroy)(opaque *val, type *T);
}
當對泛型型別進行記憶體操作(如:記憶體拷貝)時,最侄訓呼叫對應泛型型別的 VWT 中的基本記憶體操作,泛型型別不同,其對應的 VWT 也不同,下圖所示為一個小的值型別和一個參考型別的 VWT,
- 對于一個小的值型別,如:integer,該型別的 copy 和 move 操作會進行記憶體拷貝;destroy 操作則不進行任何操作,
- 對于一個參考型別,如:class,該型別的 copy 操作會對參考計數加 1;move 操作會拷貝指標,而不會更新參考計數;destroy 操作會對參考計數減 1,

方法呼叫
上一節,我們介紹了泛型的記憶體管理,那么,泛型的方法呼叫又是如何實作的呢?
我們以如下一個泛型函式為例進行介紹,
func f<T>(_ t: T) -> T {
let copy = t
return copy
}
編譯器對上述的泛型函式進行編譯后,會得到如下代碼(以 C 代碼代替 LLVM IR),
// T: 泛型引數
void f(opaque *result, opaque *t, type *T) {
opaque *copy = alloca(T->vwt->size);
T->vwt->copy_init(copy, t, T);
T->vwt->move_init(result, copy, T);
T->vwt->destroy(t, T);
}
從生成的代碼中可以看出,方法運行時會傳入一個 *type T,很明顯,這是一個型別引數,描述泛型型別所系結的具體型別的元資訊,包括對 VWT 的索引資訊,
f 是一個對泛型型別進行拷貝的方法,囊括了上述介紹的記憶體管理的程序,下面我們來簡要分析其編譯后的原始碼:
- 區域變數是分配在堆疊上的,并且對于該型別,我們不知道要分配多少記憶體空間,所以需要通過 VWT 獲取到 T 的 size 才能進行記憶體分配,
- 記憶體空間分配完之后,通過 VWT 中的 copy 方法,以輸入值 t 來初始化區域變數,
- 區域變數初始化完畢之后,通過 VWT 中的 move 方法,將區域變數移到 result 緩沖區以回傳結果,
- 回傳時,通過 VWT 中的 destroy 方法銷毀區域變數,
上述泛型函式的實作中,*type T 是整個函式能夠順利運行的關鍵,那么 *type T 到底是什么呢?
Type Metadata
事實上,編譯器在會盡量在編譯時為每一個型別生成一個型別元資訊物件——Type Metadata,也就是上述的 type *T,
Type Metadata 攜帶的型別元資訊主要包含:型別的 VWT、型別的反射資訊,如下圖所示:
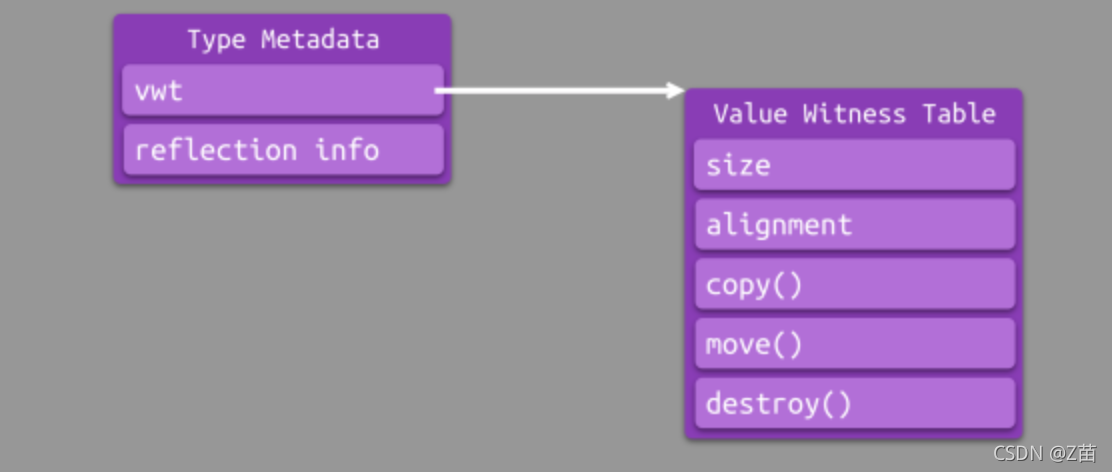
因此對于不使用 Extential Container 進行表示的泛型型別來說,通過 Type Metadata 也可以索引到 VWT,
class Drawable { func draw() }
class Point : Drawable {
var x, y:Double
func draw() { ... }
}
class Line : Drawable {
var x1, y1, x2, y2:Double
func draw() { ... }
}
let point = Point(x: 0, y: 0)
let line = Line(x1: 0, y1: 0, x2: 1, y2: 1)
var drawables: [Drawable] = [point, line]
for d in drawables {
d.draw()
}
我們再來看 OOP 是如何通過 virtual table 來實作動態派發的,如下圖所示
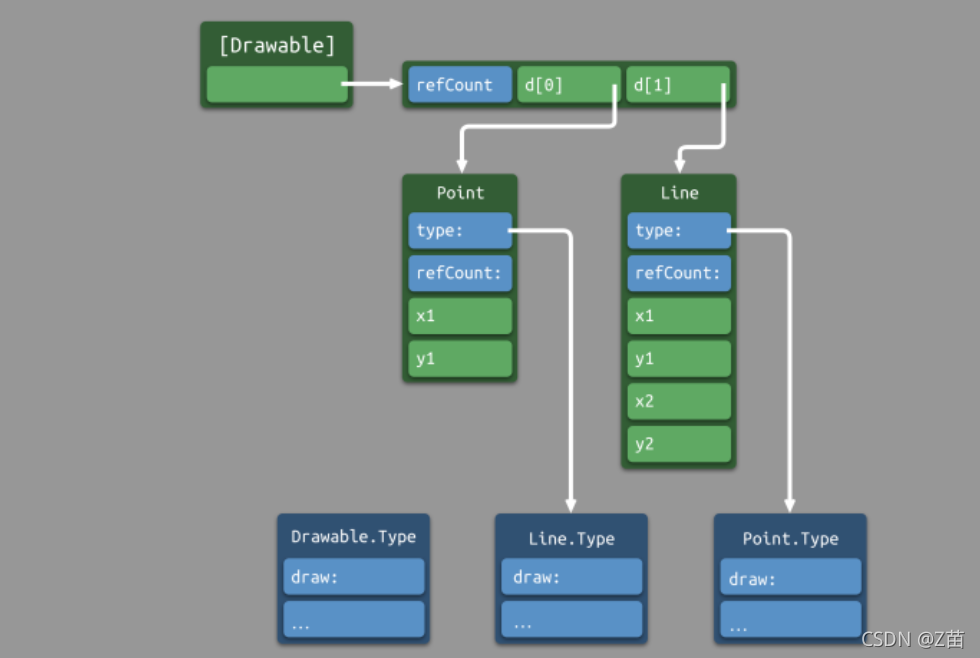
運行時執行 d.draw(),會根據 d 所指向的物件的 type 欄位索引到該型別所對應的函式表,最終呼叫正確的方法,
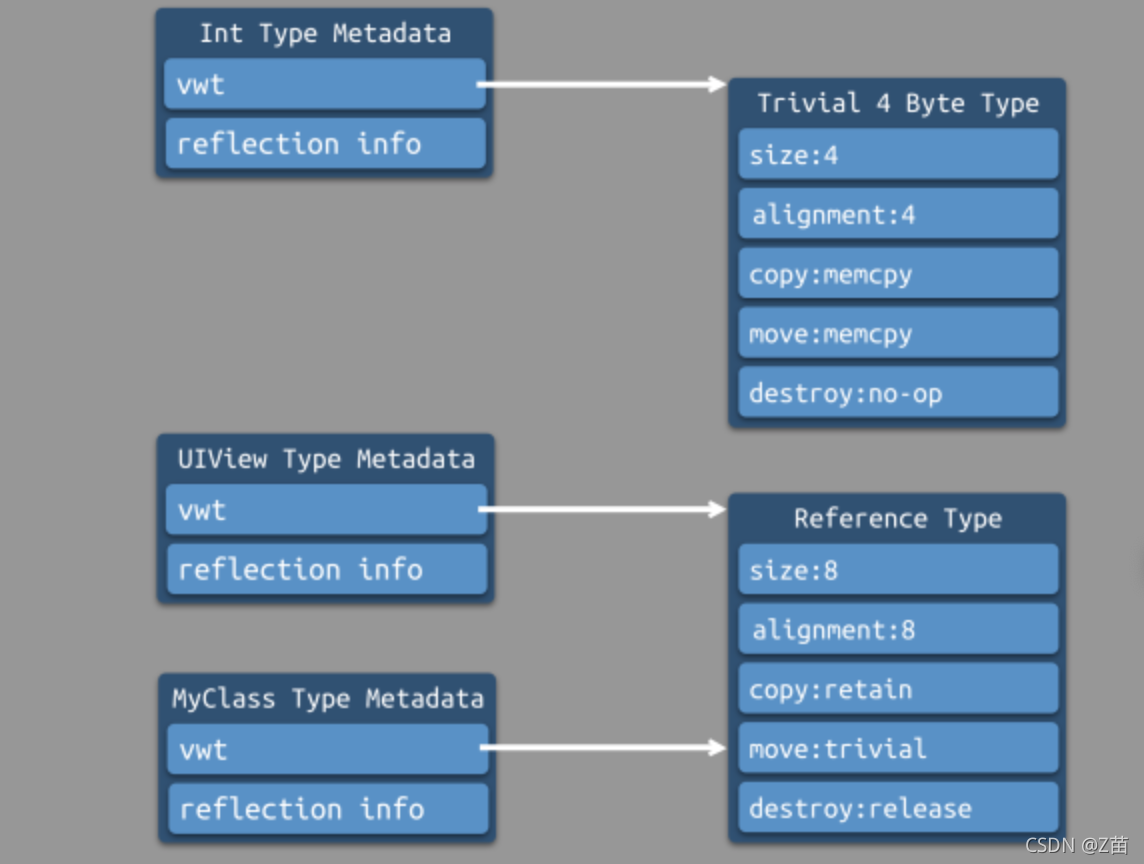
每一種型別,在全域只有一個 Type Metadata,供全域共享,
- 對于內建基本值型別,如:Integer,編譯器會在標準庫中生成對應的 Type Metadata 和 VWT,其中,VWT
是針對小的值型別 VWT, - 對于參考型別,如:UIView,編譯器也會在標準庫中生成 Type Metadata 和 VWT,其中,VWT 是針對參考型別的標準
VWT,
對于自定義的參考型別,Type Metadata 會在我們的程式中生成,VWT 則由所有參考型別共享,即上述針對參考型別的標準 VWT,
下面,我們再以上述 f 函式的具體呼叫來進行介紹編譯后的代碼是如何使用 Type Metadata 的,如下所示為兩種型別對 f 的呼叫,
struct MyStruct {
var a, b, c, d: UInt8
}
f(123)
f(MyStruct())
當使用 int 型別和 MyStruct 型別呼叫 f 時,編譯器生成的代碼如下所示:
int val = 123;
extern type *Int_metadata;
f(&val, Int_metadata);
MyStruct val;
type *MyStruct_metadata = { ... };
f(&val, MyStruct_metadata);
兩者的區別在于:
- int 型別使用標準庫中的 Type Metadata;
- 自定義型別則使用針對自身生成的 Type Metadata,
事實上,上述 Type Metadata
之所以能夠在編譯時生成,是因為我們在呼叫時就能通過型別推導得出其型別,如果,在呼叫時無法推斷其型別,則需要在運行時動態生成 Type
Metadata,
為了了解 Type Metadata 的動態生成,我們需要先了解 Metadata Pattern,
Metadata Pattern
事實上,對于泛型型別,編譯器會在編譯時生成一個 Metadata Pattern,Metadata Pattern 與 Type Metadata 的關系其實就是類與物件的關系,
以如下自定義泛型類結構為例,
struct Pair<T> {
var first: T
var second: T
}
對于運行時才能確定的泛型型別,運行時根據系結型別的 Type Metadata,結合 Metadata Pattern,生成最終的確定型別的 Type Metadata,如下圖所示:
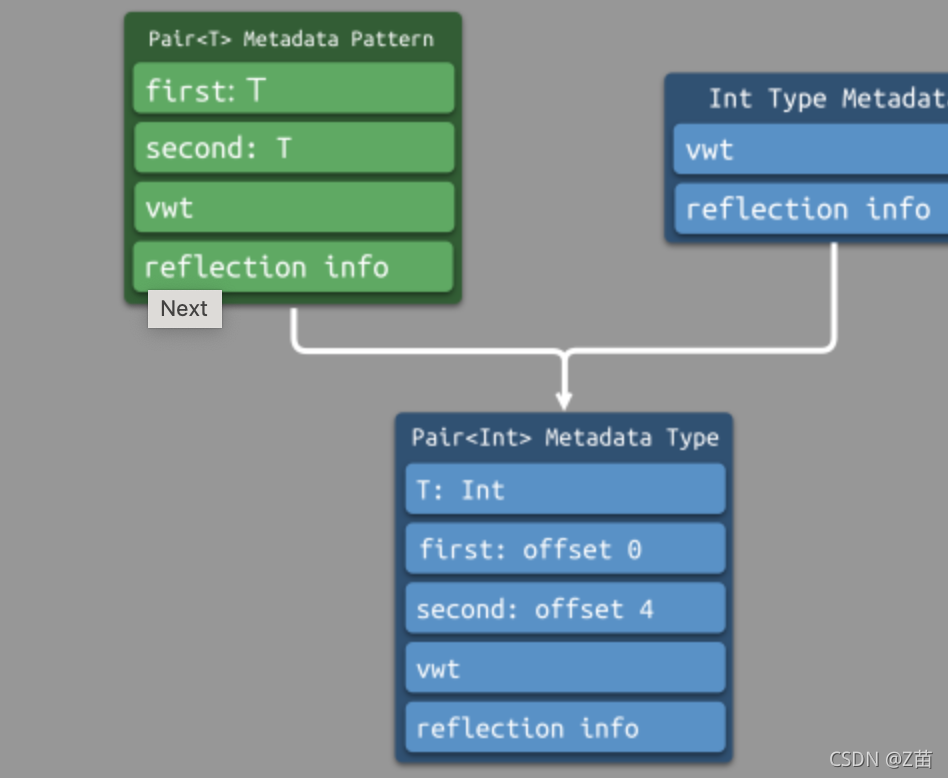
- 對于 Pair,運行時會計算 Pair 的 size,并計算出各個域的偏移,
下面,我們通過一個泛型屬性訪問的例子來看看運行時是如何使用 Metadata Pattern 來生成 Type Metadata,以如下代碼為例:
func getSecond<T>(_ pair: Pair<T>) -> T {
return pair.second
}
編譯器生成的代碼如下:
void getSecond(opaque *result, opaque *pair, type *T) {
type *PairOfT = get_generic_metadata(&Pair_pattern, T); // 實體化 type metadata
const opaque *second = (pair + PairOfT->fields[1]);
T->vwt->copy_init(result, second, T);
PairOfT->vwt->destroy(pair, PairOfT);
}
其步驟如下:
- 運行時,根據 Metadata Pattern,結合系結的型別 T 的 Type Medata(如 Int Type
Metadata)生成 Pair 的 Type Metadata 實體, - 根據 Pair 的 Type Metadata 獲得 second 在記憶體中的位置,
- 拷貝 second 躲在位置的記憶體到 result 快取區,
- 回傳前,銷毀區域變數,
編譯優化
上述代碼是在編譯時無法推斷出泛型型別的情況下生成的通用型代碼,然而,如果在編譯時就能推匯出泛型型別,編譯器則會進行優化,在真正運行時避免通過傳遞 Type Metadata 來查找各個域的偏移,從而提高運行性能,
如下代碼,就可以在編譯時進行型別推導,
func getSecond(_ pair: Pair<Int>) -> Int {
return pair.second
}
高階泛型函式
func apply<T>(value: T, fn: (T) -> T) -> T {
return fn(value)
}
編譯器編譯將得到如下代碼:
void apply(apaque *ret,
opaque *value,
void (*func_invoke)(opaque *ret, opaque *arg, void *context),
void *fn_context,
type *T) {
fn_invoke(ret, value, fn_context);
}
- 其中,func_invoke 是閉包的函式指標,由于閉包可以捕獲外部作用域,入參 context 就是用于傳遞作用域背景關系,
- 為了呼叫閉包,執行 fn_invoke(ret, value, fn_context) 就是呼叫函式執行,并將背景關系 fn_context 作為引數傳進去,
下面,我們來看一個呼叫 apply 的例子,
apply(0, { $0 + 1 })
由于能夠在編譯時推匯出型別,上述代碼就相當于如下代碼:
Int closure(Int $0) {
return $0 + 1;
}
apply(..., closure, NULL, ...);
// we have: Int (*func_invoke)(Int arg, void *ctxt)
// we need: void (*func_invoke)(opaque *ret, opaque *arg, void *ctxt)
然而,事實上,我們不能將以推匯出的 Int (*func_invoke)(Int arg, void *ctxt) 閉包直接傳遞到 apply 中,而是需要將已確定型別的閉包轉換成 void (*func_invoke)(opaque *ret, opaque *arg, void *ctxt) 閉包的形式間接傳遞到 apply 中,
那么,在確定型別的情況下,這里為什么仍然要做一次間接的轉換與傳遞呢?
對此,我們需要首先介紹一個概念——重抽象(Reabstract),
重抽象(Reabstract)
Swift 中的所有型別都存在多個抽象級別,比如:一個 Int 值是一個具體型別,可以傳遞給確定型別的函式,但是 Int 值也可能傳遞給型別為泛型 T 的函式,此時該泛型函式希望能夠間接接收該引數,從而適應其他可能的泛型型別,如:Float、String 等,當 Int 值傳遞給泛型函式時,它被認為比其為 Int 時處于更高的抽象級別,這種在抽象級別之間進行轉化的程序被稱為是 重抽象,
計算機科學中的每個問題都可以用一間接層解決,
事實上,上述 apply 采用間接傳遞的思想,本質上就是為了實作對型別進行重抽象的一種抽象模式,
這里通過 thunk 來實作對閉包的值進行重抽象,從而匹配函式的抽象模式,
Int closure(Int $0) {
return $0 + 1;
}
void thunk(Int *ret, Int *arg, void *thunk_ctxt) {
// 1. 從 thunk 背景關系中獲取原始的 函式指標
Int (*fn_invoke)(Int, void*) = thunk_ctxt->...;
// 2. 從 thunk 背景關系中獲取原始的 context
void *fn_context = thunk_ctxt->...;
// 3. 在呼叫函式前,我們將需要間接的結果轉換為直接的結果,通過 *arg,
// 4. 最后將 fn_invoke 回傳的直接值轉換為間接值,通過 *ret =
*ret = fn_invoke(*arg, fn_context);
}
void *thunk_ctxt = allocate(..., closure, NULL); // allocate a context
apply(..., thunk, thunk_ctxt, ...);
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/306617.html
標籤:其他