背景
這里有一個資料集,d:
d <- data. frame(ID = c("a"/span>。 "a","b"。 "b"),
product_code = c("B78"/span>。 "X31"。 "C12","C12"),
stringsAsFactors=FALSE)
它看起來像這樣:
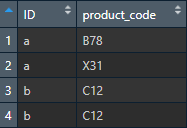
問題和期望的輸出
我試圖制作一個指標列multiple_products,對于有一個以上唯一的ID的,標記為1;對于沒有的,標記為0。
不過,我的嘗試還沒有成功。
我想要的是什么?
我所嘗試的 而這就是結果: 有什么想法嗎? uj5u.com熱心網友回復: 輸出 uj5u.com熱心網友回復: 用 輸出; uj5u.com熱心網友回復: 一個使用 給予
標籤: 上一篇:用開頭的模式替換字串末尾的模式
d <- d %>%
group_by(ID) %>%
mutate(multiple_products = if_else(length(unique(d$product_code)) > 1,/span> 1。 0)) %> %
ungroup()
d$應該被取出來,因為這將通過移除組屬性來提取整個列。 另外,還有n_distinct。 此外,沒有必要使用ifelse或if_else,因為邏輯值(TRUE/FALSE)可以直接強制為1/0,因為這些是存盤值,通過使用as.integer或 library(dplyr)
d %>%。
group_by(ID)%>%
mutate(multiple_products = (n_distinct(product_code)/span> > 1)) %>%
ungroup()
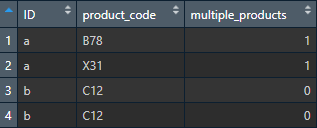
# A tibble: 4 x 3
ID product_code multiple_products
<chr> < chr> <int>/span>
1 a B78 1
2 a X31 1
3 b C12 0
4 b C12 0
data.table解決;library(data.table)
setDT(d)
d[,/span>multiple_products: =rleid(product_code)。 by=ID][/span>
,multiple_products。 =ifelse(max(multiple_products)> 1,/span>1。 0),by=ID】
d
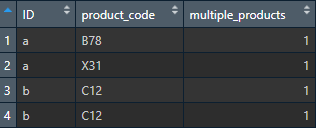
ID product_code multiple_products
<chr> < chr> <int>/span>
1 a B78 1
2 a X31 1
3 b C12 0
4 b C12 0
avetransform()
d,
multiple_products = (有(match(product_code。 唯一(product_code))。 ID, FUN = var) > 0
)
)
ID product_code multiple_products
1 a B78 1
2 a X31 1
3 b C12 0
4 b C12 0