為什么以下非常相似的查詢會產生非常不同的計劃?
查詢1
SELECT *
FROM ACTORREPORTADO_RIESGO ars1
WHERE ars1.fechariesgo=
( SELECT MAX(fechariesgo) FROM actorreportado_riesgo ars2
WHERE ars2.idactorreportado=ars1.idactorreportado
)
AND COALESCE(nivelriesgo, ' ') NOT IN ('N', '')這是行的差異

查詢2
SELECT *
FROM ACTORREPORTADO_RIESGO ars1
WHERE ars1.fechariesgo=
( SELECT MAX(fechariesgo) FROM actorreportado_riesgo ars2
WHERE ars2.idactorreportado=ars1.idactorreportado
)
and nivelriesgo NOT in ('N',') 。 --這就是行的差異。
該表有15條記錄
CREATE TABLE ACTORREPORTADO_RIESGO (
IDACTORREPORTADO NUMBER(17) NOT NULL,
FECHARIESGO DATE NOT NULL,
NIVELRIESGO VARCHAR2(10)。
USUARIORIESGO VARCHAR2(50)。
OBSERVACIONES VARCHAR2(500)。
CONSTRAINT PK_ACTORREPORTADO_RIESGO PRIMARY KEY(IDACTORREPORTADO, FECHARIESGO)
)
uj5u.com熱心網友回復:
原因是COALESCE(nivelriesgo,' ')是一個必須對每一行進行評估的運算式,所以db不能在nivelriesgo上使用索引(如果它們存在的話),或者直接從表中使用nivelriesgo值。
如果你把它改成邏輯上的等價物,我估計你會得到兩個相同的計劃:
AND nivelriesgo IS NOT NULL
AND nivelriesgo NOT IN ('N',')
uj5u.com熱心網友回復:
tldr; 優化器不知道COALESCE(nivelriesgo,' ')是什么,所以不會做得很好。
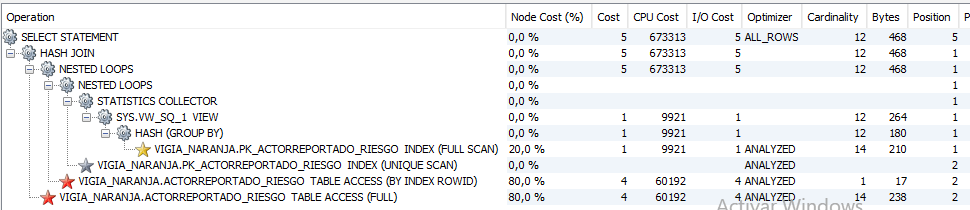
細枝末節。 這里最重要的是cardinality以及Oracle如何估計它。
COALESCE(nivelriesgo, ' ') NOT IN ('N',')
Oracle不知道運算式COALESCE(nivelriesgo,' ')的分布情況,所以它必須依靠一些硬編碼的猜測。對于NOT IN串列中的每個元素,Oracle將使用5%的選擇性。因此,兩個元素給了你5%和5%(因為運算式的值必須不是'N'也不是''),這給了你一個0.25%的選擇性。應用于你的基本cardinality(15):Oracle估計這個過濾器(本身)將給你帶來1行(從0.0375四舍五入)。
如果 Oracle 相信通過表掃描應用過濾器將回傳一條記錄,那么它將相信它只需要運行一次標量相關子查詢。這對優化器來說似乎很便宜,因為這個相關子查詢有一個支持索引。
當你將外部過濾器改為
時nivelriesgo NOT IN ('N',')
Oracle突然有了一些資訊作為估計的基礎--它知道你的表中有多少個不同的nivelriesgo的值(感謝統計),它知道這些值的范圍是什么,它甚至可能有一個分布的概念(如果你有一個直方圖)。
根據你的計劃,Oracle估計這個過濾器將回傳14條記錄(15條中的)。將標量相關的子查詢回圈14次顯然不如只回圈一次來得吸引人,所以這不是一個明顯的好主意。
它已經確定它可以重寫你的查詢,這樣它就可以有效地
。
select ars1.*
from ( select ars2.idactorreportado
,max(fechariesgo) max_fechariesgo
from actorreportado_riesgo ars2
group by ars2.idactorreportado
) ars2
join actorreportado_riesgo ars1
on ars2.idactorreportado = ars1.idactorreportado
and ars2.max_fechariesgo = ars1.fechariesgo
where ars1.nivelriesgo NOT IN ('N',');
因此,它不需要在每條記錄上執行一次標量相關的子查詢,它已經取消了嵌套,并將能夠只做一次作業。
現在,超級有趣的事情來了,Oracle對這個新的子查詢將回傳多少行并沒有100%的信心。如果有少量的結果,它將使用索引查找(使用主鍵),并保留該行,如果它與你的nivelriesgo過濾器相匹配(它認為這對大多數行來說是真的)。如果子查詢有大量的結果,它將只進行全表掃描(只回傳與你的nivelriesgo過濾器相匹配的行),并將其與子查詢結果進行哈希連接--這對于大型結果集來說通常是相當理想的。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/322136.html
標籤: