"黑產"識別演算法
- 前言
- 黑產的特性
- 通過業務特性識別
- 通過關聯關系識別(非監督學習)
- 通過行為相似度識別(非監督學習)
- 通過用戶畫像識別(分類、預測)
前言
我們討論的黑產識別,實務上并非單純演算法的問題,在更多的情況下,是一種基于經驗性、合規性對于業務全流程和每一個節點的風險控制手段,
黑產的特性
黑產即黑色產業,是利用非法手段獲利的行業或群體,
其中當下處在風口浪尖的便是“網路黑產”,但是黑產,并不單單是通過網路手段實時,傳統行業、生活中,我們都可能與黑產擦肩而過,受害、有時可能是受益于黑產帶來的結果,比如:勒索詐騙電話、黃牛等,
侵犯了國家和社會的利益,自然會有國家有關部門去控制,但很有意思有一些黑產專薅羊毛,似乎并沒有對社會人民造成多大損失,但對于一些公司和組織的發展,是極大隱患,
說了這么多,我們對黑產會有一點點感覺,總結來看,黑產具有以下幾個特質:
1. 模塊化、組織化、團伙操作,
“并不是一個人在戰斗”,如果只是一個人投機取巧,倒也容易識別,畢竟屬于一個極端例外的行為,而且個人作妖并不會考慮及其復雜的情況,極容易暴露,常見的例外識別手段即可,
但是大多數,黑產是一個高智商的團體,
2. 迷惑性、隱蔽性強,
這些高智商的團體懂得隱蔽,有時會分散收益,流向無數個“小號”,有時會利用無數虛擬ip操作,無法通過常規技術手段去定位,有時甚至開發虛擬機進行短時間內大規模作案,
3. 利益為導向、多方利益勾結,
不過“慶幸”的是,無論如何他們最終都會流向利益,從這個點出發總不會有錯,但問題是這條路如何走,
通過業務特性識別

黑產團伙一般受限于資源和任務的約束,有聚集性、短期高頻等特征,當然,不同的行業背景會有不同的表象,我們首先要明確梳理這個業務的全流程,每一個對于黑產可能產生利益流入的節點,以及它的前置和后置節點,再根據上述的一些特征,加以識別,
這本質上是一種運營的手段,舉個例子:
1.背景:某商家賣內褲,在微信公眾號發了一個廣告帖,只要你分享鏈接給你的一個好友,就可以得到3元紅包,不設上限,活動期限7天,
2.結果:不負眾望,在第一天該貼的瀏覽量就達到100w,去重訪問用戶數8w,按照歷史經驗,每一個用戶平均購買2.5條內褲來算,單價20元的內褲銷量預計將有2.5x20x80000 = 400w的毛收入,
3.思考: 事實上,該商家這次活動最終的收入只有100+w,原因調查后是因為被黑產薅羊毛了,
首先說這次的營銷活動策略是有嚴重漏洞的,很多商家為了裂變營銷,會不計成本的投入資金,搶占份額,但是對于這種日用品,是否真的有這個必要如此大費周章?
很多時候,黑產的出現會幫助商家公司完善自己的策略,比如不設上限的紅包是否可以用于商城內的購買?是否一定要現金紅包?紅包金額是否需要設計為遞減?
可以說,上述策略某種程度上可以止損,但是勢必影響最初的目標:裂變, 畢竟用戶是要有動機去幫你拉新的, 所以這里,我們識別黑產(某種程度上講,例外用戶群體) 對于止損就顯得尤為重要了,因為這些例外用戶,勢必不會對你的業務產生長期價值,
方法:
梳理埋點事件
- 計算類似7天內在某事件(分享鏈接、購買按鈕點擊、頁面停留時長、事件時間等)相關指標,
- 設備or uid關聯超過xx個賬戶 (xx天內),
- 1天內某IP關聯超過xx個賬戶,
- 收益核算,
- …
我們簡單的filter,就可以把這些收益極高,行為例外的用戶篩選出來,
他們的特點可以用一句話概括:短時間內,高密度分享鏈接,集中在下午3點,但是從未發生購買行為,推薦的uid和decive id也無購買行為,頁面停留時間過短,瀏覽時間很長等,
這就是第一種識別的方法:業務規則篩選,
通過關聯關系識別(非監督學習)
通過連通子圖演算法識別出一個個連通的社區,如果社區規模較大,可能背后業務含義是黑產控制一批賬戶, 定義社區規模為score,通過調節閾值來控制誤殺、召回,
這里介紹一個演算法模型-社區檢測Girvan Newman,
參考鏈接:https://memgraph.com/blog/community_detection-algorithms_with_python_networkx
演算法邏輯
本質上是尋找親密關系的群體uid,
檢測社區的方法主要有兩種:
(1) Agglomerative Methods:
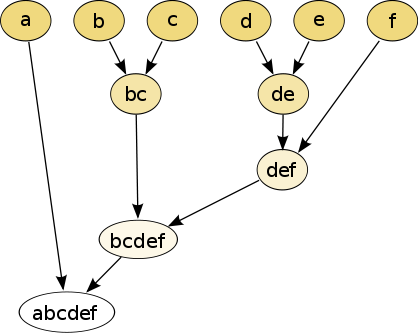
在凝聚方法中,我們從一個空圖開始,該空圖由原始圖的節點組成,但沒有邊,接下來,將邊一個接一個地添加到圖中,從強邊到弱邊依次添加,一條邊的強度,或邊的權值,可以用不同的方法計算,
(2) Divisive Methods:
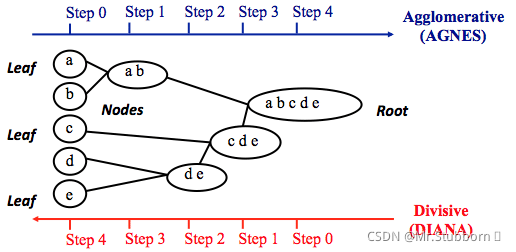
在分裂的方法中,我們走的是相反的道路,我們從完整的圖開始,迭代地取走這些邊,權重最大的邊緣先被移除,每一步都要重復計算邊權值,因為洗掉一條邊后,剩余邊的權值會發生變化,經過一定數量的步驟,我們得到密集連接的節點簇,Girvan-Newman(GN)演算法就是典型的分裂演算法,
步驟:
在格文-紐曼演算法下,根據圖的邊介數中心性(Edge Betweenness Centrality,EBC)值,通過迭代去除圖的邊來發現圖中的社區,邊介數中心性最大的邊最先被移除,
邊介數中心性(edge betweenness centrality, EBC)可以定義為網路中通過一條邊的最短路徑的數量,根據圖中所有節點之間的最短路徑,給每條邊一個EBC評分,
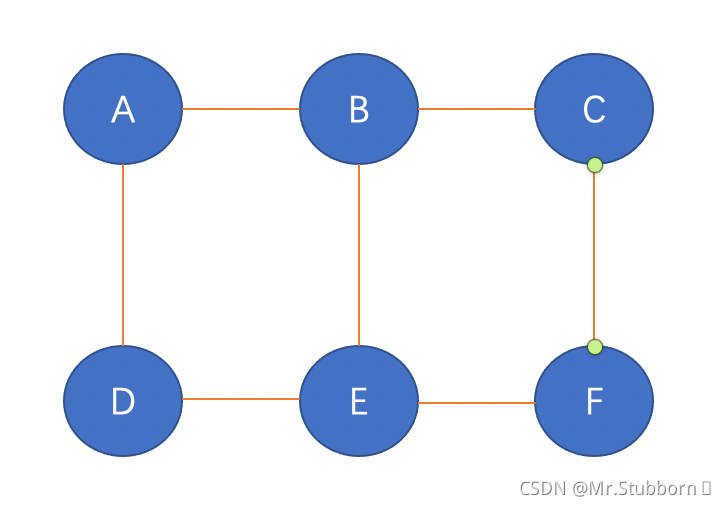
對于圖和網路來說,最短路徑是指任意兩個節點之間距離最小的路徑,讓我們舉一個例子來了解EBC分數是如何計算的,
EBC分數的計算是個迭代程序:
- 每次取一個節點,并繪制從選定節點到其他節點的最短路徑;
- 基于最短路徑,計算所有邊的EBC分數;
- 對圖中的每個節點重復這個程序,上圖中有6個節點,因此,這個程序將有6次迭代;
- 每條邊都有6個分數,將這些分數逐條邊加起來;
最后,每條邊的總分數除以2就是EBC得分了,
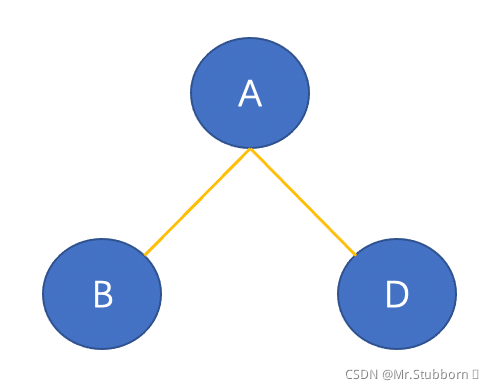
現在我們從節點A開始,與節點A直接連接的節點為節點B和節點D,那么從A到B和D的最短路徑分別為AB和AD,
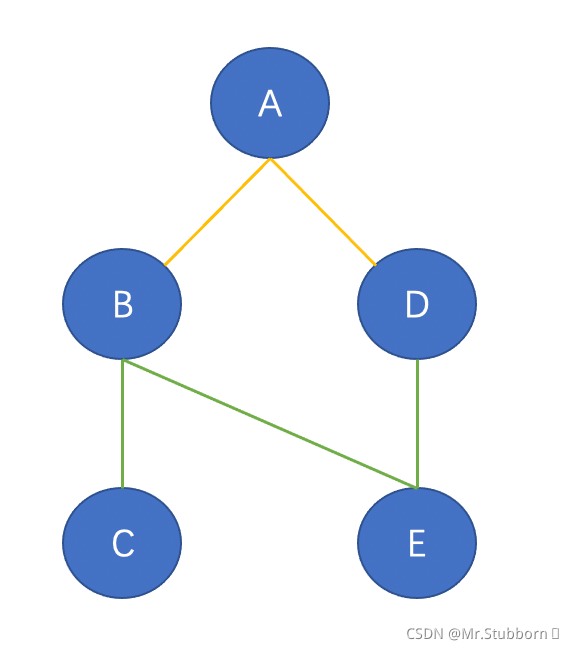
從A到結點C和E的最短路徑經過B和D,
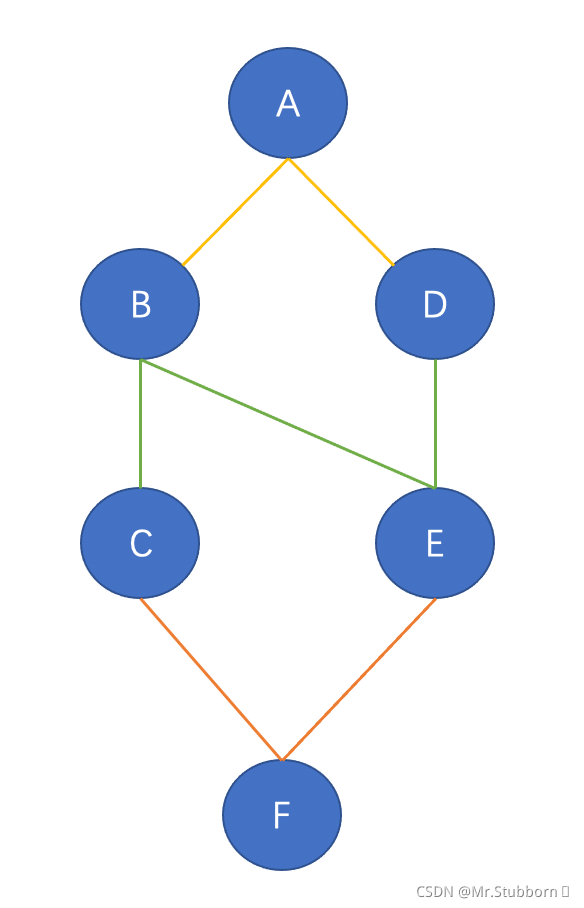
從節點A到最后一個節點F的最短路徑,經過節點B、D、C、E,
上面的圖只描述了從節點A到所有其他節點的最短路徑,現在我們來看看每條邊的得分,
在給邊打分之前,我們將給最短路徑圖中的節點分配一個分數,為了分配這些分數,我們必須從根節點遍歷圖,從節點A到最后一個節點(節點F),
給節點分配分數:
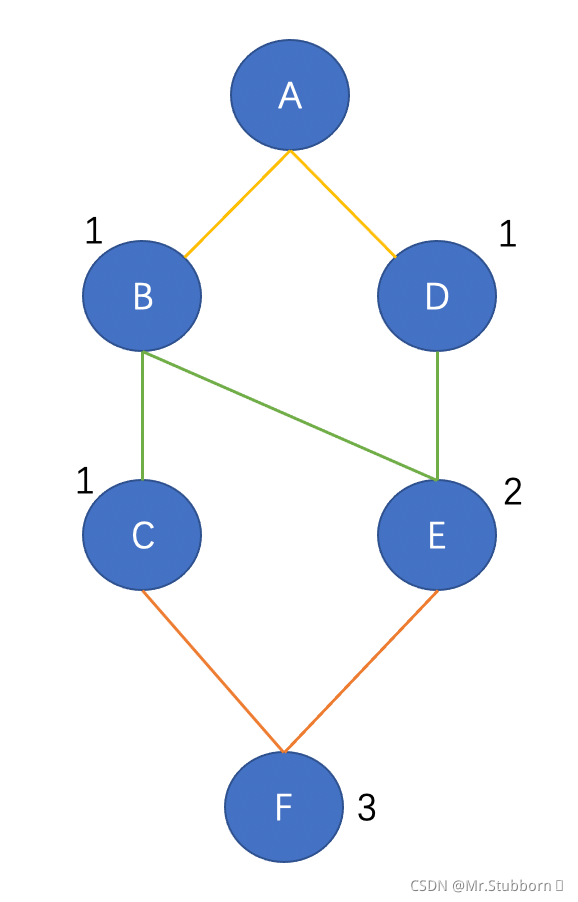
如圖所示,節點B和D的得分都是1,這是因為從結點A到任意一個結點的最短路徑只有1,出于同樣的原因,節點C被賦值為1,因為從節點a到節點C只有一條最短路,繼續到節點e,它通過兩條最短路徑連接到節點A,即ABE和ADE,因此,它得到了2分,最后一個節點F通過三條最短路徑ABCF、ABEF和ADEF連接到A,所以它得到3分,
計算每條邊的得分:
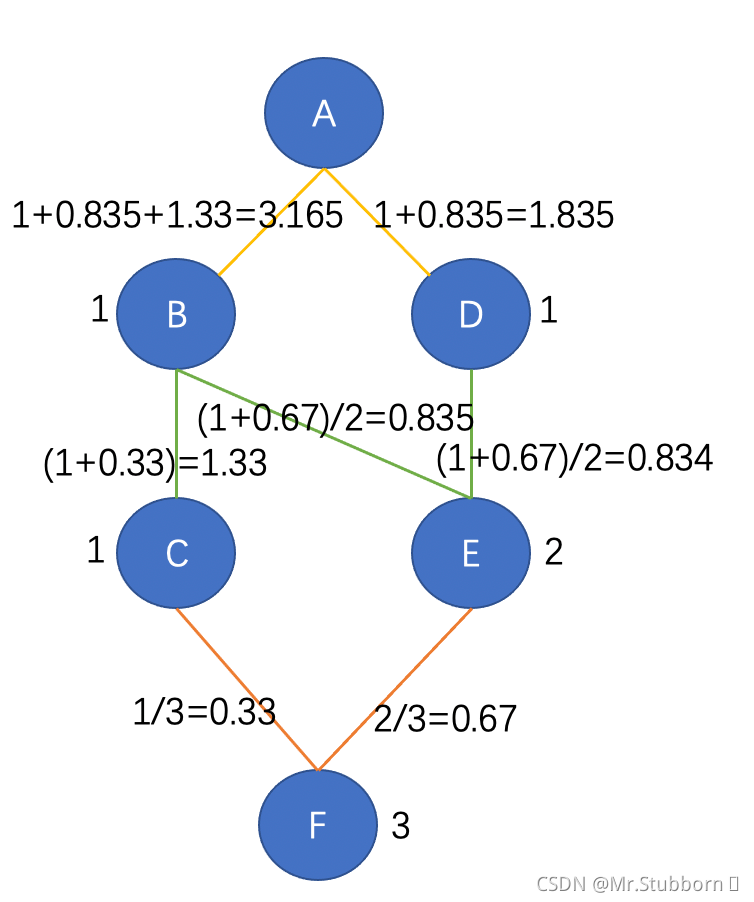
簡單講,每條邊的分數等于,
自下而上,(1+下面n邊的分數)/上面n條路徑
到目前為止,我們已經計算出了相對于節點A的最短路徑的邊緣分數,我們將再對剩下的5個節點重復同樣的步驟,最后,我們將得到網路中所有邊的6個分數,我們將這些分數相加,并將其分配到原始圖表中,如下圖所示:
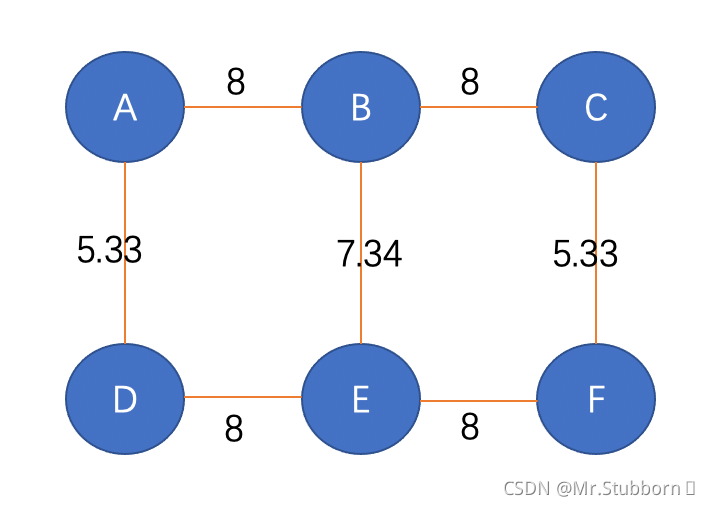
由于這是一個無向圖,我們將這些分數除以2,最終得到EBC分數:
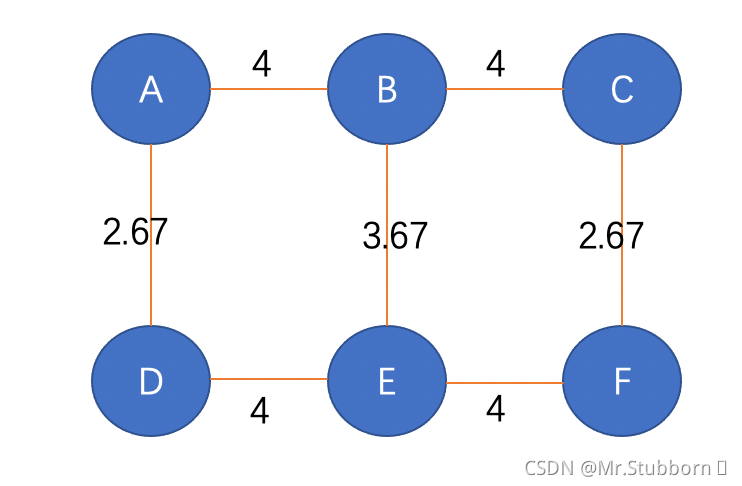
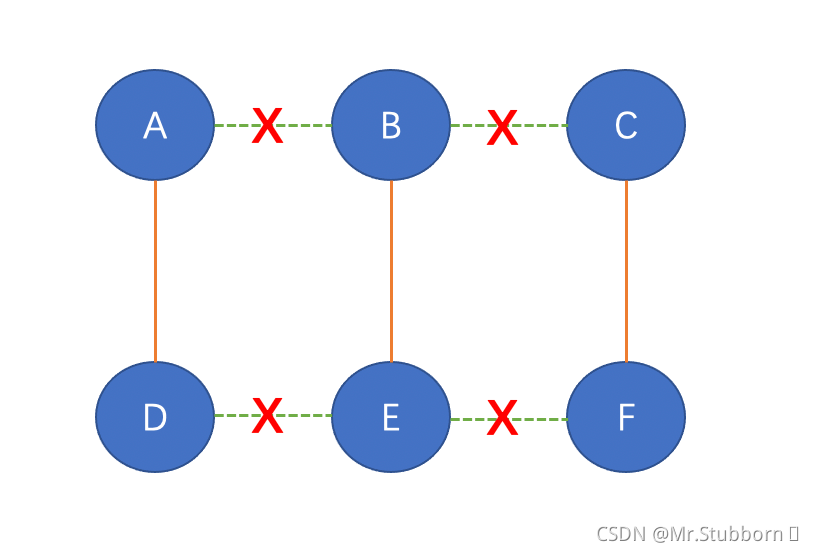
根據Girvan-Newman演算法,計算EBC得分后,去掉得分最高的邊,直到圖一分為二,因此,在上圖中,我們可以看到AB, BC, DE, EF這條邊得分最高,即4,我們把這些邊去掉,就得到了三個子圖,我們稱之為社區:
代碼實作
R
install.packages("igraph")
install.packages("tidyverse")
# Library
library(igraph)
library(tidyverse)
options(scipen=200)
set.seed(1)
data <- read_csv(file = 'xxxxxxxxx.csv',
col_types = c('c','c','n', 'c','c'))
data <- data %>% mutate(relat =case_when(activity_phase==101 ~ '加油',
activity_phase==120 ~ '呵呵'))
relations <- data.frame(from=data$uid,
to=data$tuid,
status=data$relat)
network <- graph_from_data_frame(relations, directed = TRUE, vertices = NULL )
print(network, e=TRUE, v=FALSE)
# Default network
par(mar=c(0,0,0,0))
#E(network)$size <- 0.5
# 社區檢測
ceb <- cluster_edge_betweenness(network) # 構造模型
dendPlot(ceb) # 可視化
# 將組別存盤
group = data.frame(uid=0,group=0)
for (i in (1:length(ceb))) {
tmp = data.frame(uid=ceb[i],group=i)
colnames(tmp) <- c('uid','group')
colnames(group) <- c('uid', 'group')
group <- rbind2(group,tmp)
}
group <- group[-1,]
png(file="graph_go.png",
width=8000, height=8000)
plot(ceb,network,
layout=layout.auto,
vertex.shape=c("circle","square"), # One of “none”, “circle”, “square”, “csquare”, “rectangle” “crectangle”, “vrectangle”, “pie”, “raster”, or “sphere”
vertex.size=1.5, # Size of the node (default is 15)
vertex.size2=0.5, # The second size of the node (e.g. for a rectangle)
vertex.label = NA,
edge.arrow.size=0.1,
edge.arrow.width = 0.1
#label = NA
)
dev.off()
python
pip install python-igraph
import igraph
""
讀取csv將關鍵欄位如uid,權重裝進串列
""
import csv
edges=[]
with open('test.csv','r') as f:
for row in csv.reader(f.read().splitlines()):
u,v,s=[i for i in row]
edges.append((u,v,s))
from igraph import Graph as IG
g=IG.TupleList(edges,directed=False,vertex_name_attr='name',edge_attrs=None,weights=False)
print(g)
commnities=g.community_edge_betweenness(directed=False,weights=None)
# print(commnities)
# print(g.vs['name'])
print(commnities)
print(g.vs['name'])
"""
walkstrp方法
"""
import csv
edges = []
firstline = True
with open('anti_test.csv','r') as f:
for row in csv.reader(f.read().splitlines()):
if firstline == True:
firstline = False
continue
u,v,weight = [i for i in row]
edges.append((u,v,int(weight)))
from igraph import Graph as IGraph
g = IGraph.TupleList(edges,directed = True,vertex_name_attr="name",edge_attrs=None,weights = True)
print(g)
#網路直徑:一個網路的直徑被定義為網路中最長最短路徑
print(g.diameter())
names = g.vs["name"]
print(g.get_diameter)
[names[x] for x in g.get_diameter()]
#嘗試下 "Jon"到“Margaery”之間的最短路徑
print(g.shortest_paths("6994301573845976066","6951976933169071105"))
print("---------------------")
print([names[x] for x in g.get_shortest_paths("6994301573845976066","6951976933169071105")[0]])
print("---------------------")
#看下“jon”
paths = g.get_all_shortest_paths("6994301573845976066")
for p in paths:
print([names[x] for x in p])
#度的中心性
print(g.maxdegree())
for p in g.vs:
if p.degree() > 15:
print(p["name"],p.degree())
#社區檢測(community Detection)
clusters = IGraph.community_walktrap(g,weights="weight").as_clustering()
nodes = [{"name":node["name"]} for node in g.vs]
community ={}
for node in nodes:
idx = g.vs.find(name=node["name"]).index
node["community"] = clusters.membership[idx]
if node["community"] not in community:
community[node["community"]] = [node["name"]]
else:
community[node["community"]].append(node["name"])
for c,l in community.items():
print("community",c,":",l)
通過行為相似度識別(非監督學習)
上面關聯關系提到的演算法其實最終的結論不是黑產識別本身,而是幫我們識別出了一批關系最為緊密的一群人,但這群人可能只是來自同一個學校、同一家公司或者有著某種相同的淵源,
當黑產的技術十分“高超“時,它會使用輪換proxy_ip,會避開設備性指紋,會有多個”老鼠倉“,等等一系列手段去繞開現有風控策略,我們其實還有一種方法去識別,通過行為相似度,
要計算行為相似度,需要明確兩件事,1. 制作用戶行為資料集,行為畫像,當然也包括一些用戶屬性類特征,2. 明確計算什么樣的相似度,本質上計算相似度就是計算距離,
我們來舉個例子:
背景: 某游戲公司發布一個活動,分享你的戰斗視頻給好友or朋友圈,獲得虛擬金幣10枚(金幣可以購買武器裝備),分享的視頻附帶游戲下載鏈接,如果有人通過你的鏈接下載游戲并注冊激活,將獎勵你50元現金到賬,
資料集如下:
| 賬號id | 設備id | 注冊時間 | 拉新賬號id | 每榷訓躍時間 | 每日消耗金幣 | ip地址 | 手機型號 | 游戲等級 | 活動獲得金幣 | 活動獲得返現 | … |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1645346 | k11232 | 2020-10-09 | 66722334 | 2.5 | 286 | 999-232-111 | 蘋果12 | 18 | 200 | 0 | |
| 23423434 | k66777 | 2020-09-02 | 77802556 | 8,0 | 10 | 999-222-111 | 華為mate20 | 50 | 100 | 100 | |
| 632453 | k922003 | 2021-01-03 | 20094448 | 0.5 | 1.2 | 989-212-1e1 | oneplus | 20 | 30 | 2200 | |
| … | … | … | … | … | … | … | … | … | … | … |
真實情況可選特征遠比這個資料集要多,我們觀察一下資料,
黑產可能出現的特殊族群可能具備以下特點:
a. 同一個賬號id高拉新id,
b. 多賬號共用相似度較高的設備id或者ip地址,
c. 手機型號等系統資訊是否密度高?
d. 注冊時間較為接近,
e. 游戲等級固定(比如必須達到某一個最小等級才可以分享戰績或者消耗金幣)
f. 拉新識訓現金很高,但是榷訓躍游戲時長極低,
g. 分享鏈接獲得金幣/成功注冊激活新用戶的現金獎勵,這個比值很低,說明分享的少,但是拉新卻很高,可能團伙作案或者虛擬機操作,
h. …
我們可以選擇聚類演算法,可以參考本野雞之前寫的聚類演算法篇😿 (非監督學習-聚類演算法概述與代碼實作(*K-means, k-modes, k-prototypes, DMSCAN密度聚類, GMM, 層次聚類))
這里需要注意,不同特征有的是連續變數,有的是分類變數,有的是Nominal,因此需要選擇不同計算距離的方法,比如對于Ip地址這種,最好選擇計算漢明距離,而非幾何距離,
我們這邊附一個DBSCN的代碼,因為有時我發現k-means,k-modes等傳統的partition-based的聚類演算法并不是很顯著,實務中如果更畸形可以選擇類似這種密度聚類,
# 匯入DBSCN訓練演算法
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
eps=0.007# 領域的大小,使用圓的半徑表示
MinPts=10# 領域內,點個數的閾值
model=DBSCAN(eps,MinPts)
# 資料匹配
data['type']=model.fit_predict(data[['xxxx','xxx','xxxxx']])
# 繪圖
plt.figure(figsize=(12, 8))
plt.scatter(
data['xxxx'],
data['xxxx'],
data['xxxxx'],
c=data['type'] # 表示顏色
)
plt.axis('off')
plt.show()
這里注意調整eps,MinPts兩個引數以達到最優效果,
最終用type欄位得分進行分簇,找到可能的黑產群體,這是基于行為等特征距離相似度計算的結果,
通過用戶畫像識別(分類、預測)
到了這一步,其實可以說某種意義上是最終末端了,我們想要預測和準確分類黑產群體,甚至識別個體,這個的大前提是:我們已經有明確的黑產、舞弊賬號id的記錄,我們才能選擇監督學習的方式去訓練模型,當下一個黑產id出現(前提是他們的手段特征不會改變),就可以及時預測診斷出它來,
資料集還是之前那個,可能特征惠更豐富,也需要增加一些高資訊含量的特征,搭建模型可以參考本野雞寫的 (利用XGBoost、Information Value、SHAP尋找“小北極星“指標與分層處理) 用XGB去試試,
但是現實中我不敢用這種方法,因為總管目前反舞弊行業,黑產們的技術手段和舞弊方式千變萬化,甚至不斷迭代更新,我不相信有什么模型可以有那么強的魯棒性一直長時間高準招地去預測黑產id,模型不斷訓練優化,成本也太高了,一旦黑產們“變”了,你的一模型基本上廢掉,問題是你也不知道他們什么時候變,變了什么…對吧…
因此非監督學習還是首選,畢竟,只要是黑產一定向“錢”看齊,那么他的行為一定會出現例外/不合群的地方!!!
但是最最優秀的方法,還是經驗判斷,給予你對自家業務深入細致的了解,對任何漏洞策略的敏感性,不斷完善漏洞,
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/326029.html
標籤:其他
上一篇:scratch接紅包游戲 電子學會圖形化編程scratch等級考試三級真題和答案決議2021-9
下一篇:unity3d 實作圓形小地圖