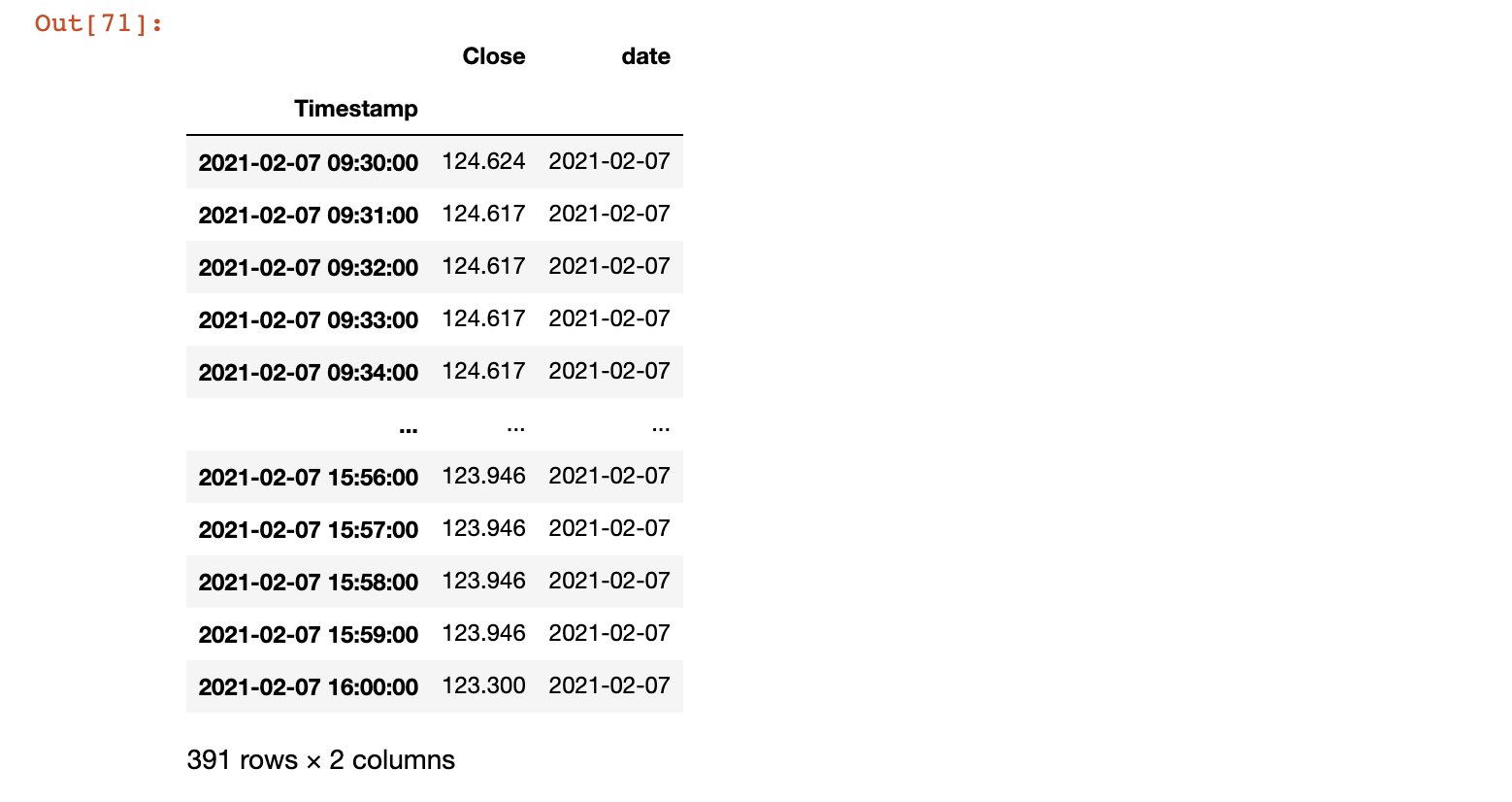
我有一個pandas資料框架,在時間序列中存在間隙。 它看起來像下面的內容:
示例輸入
--------------------------------------
時間戳關閉
2021-02-07 09:30: 00 124.624
2021-02-07 09:31: 00 124.617
2021-02-07 10:04:00 123.946[/span
2021-02-07 16:00:00 123.300[/span
2021-02-09 09:04:00 125.746
2021-02-09 09:05:00 125.646
2021-02-09 15:58: 00 125.235
2021-02-09 15:59: 00 126.987
2021-02-09 16:00: 00 127.124
期望的輸出
--------------------------------------------
時間戳關閉
2021-02-07 09:30: 00 124.624
2021-02-07 09:31: 00 124.617
2021-02-07 09:32: 00 124.617
2021-02-07 09:33: 00 124.617
'為每分鐘插入一行,直到下一個可用的
時間戳與最后一個可用的時間戳的關閉值。
2021-02-07 10:03:00 124.617
2021-02-07 10:04:00 123.946[/span
2021-02-07 16:00:00 123.300[/span
'我不希望在這里插入行。因為這個日期不在
在原始資料集中不存在(可能是一個非交易日
日,所以我不想填補這個空白)'
2021-02-09 09:04:00 125.746
2021-02-09 09:05:00 125.646
2021-02-09 15:58: 00 125.235
'再次填補這里的空白,但只在09:30和16:00時間之間'。
2021-02-09 15:59:00 126.987
2021-02-09 16:00: 00 127.124
我所嘗試的是:
'# set the index column'
df_process.set_index('Exchange DateTime', inplace=True)
'#重新取樣并向前填充間隙'。
df_process_out = df_process.resample(rule='1T').ffill()
'#過濾并只回傳09:30和16:00之間的時間戳'。
df_process_out = df_process_out.between_time(start_time='09:30:00'/span>, end_time='16:00:00'/span>)
然而,如果我這樣做,它也會重新采樣并在原始資料框架中不存在的日期上生成新的時間戳。在上面的例子中,它也會在一分鐘內生成2021-02-08的時間戳。
我怎樣才能避免這種情況呢?
此外,是否有更好的方法來避免對整個時間進行重新取樣。
df_process_out = df_process.resample(rule='1T').fill()
這就產生了從00:00到24:00的時間戳,在下一行代碼中,我必須再次過濾掉大部分時間戳。 這似乎并不高效。
如果有任何幫助/指導,我們將非常感激
。
謝謝
編輯:
編輯:
按要求提供了一個小的樣本集
df_in:在一個小的樣本集中,有一個小的樣本。
df_in。輸入資料
df_out_error: 錯誤的輸出資料
df_out_OK: 輸出資料應該是什么樣子的
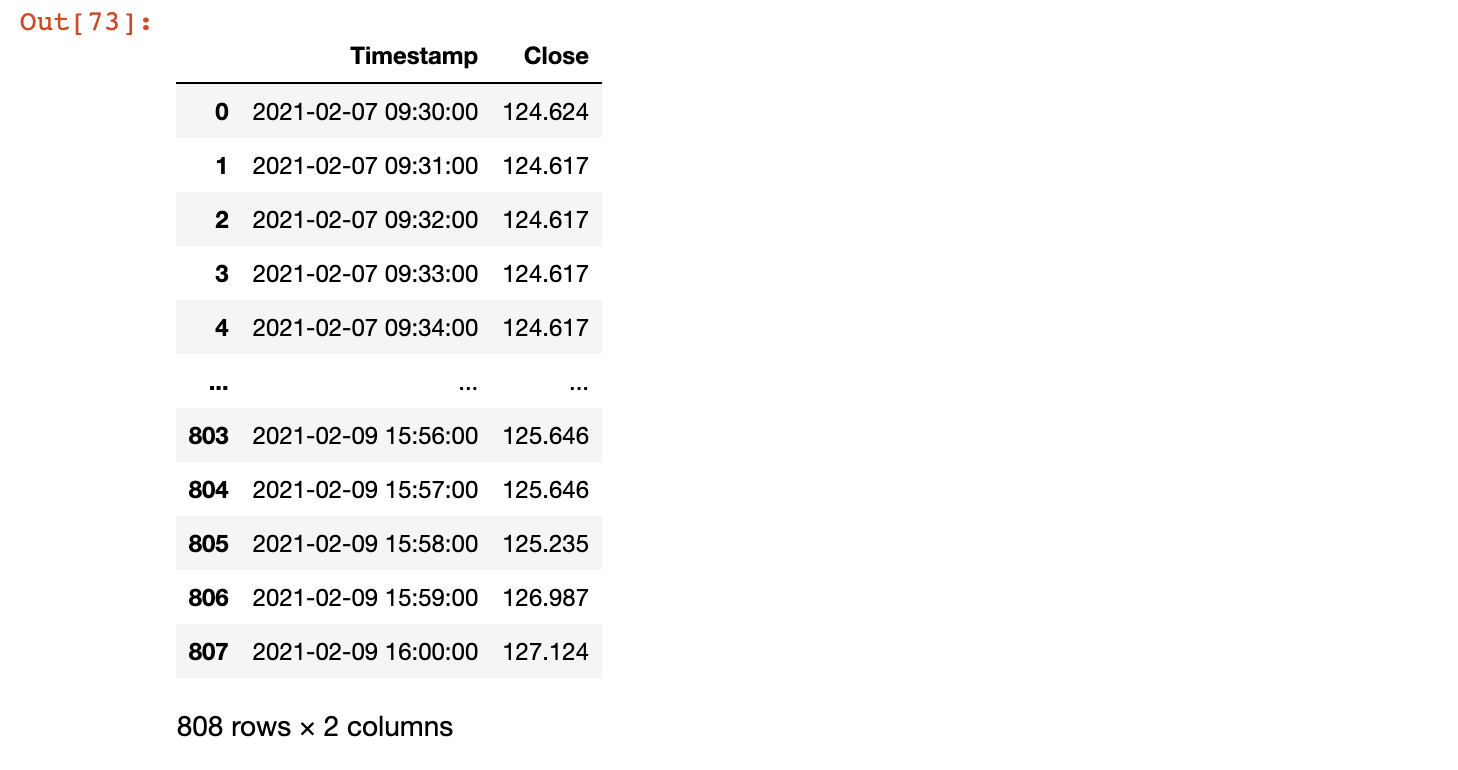
解釋
。1. 僅在有限的時間段內進行重采樣
。"此外,是否有更好的方法來避免在整個時間段內重新取樣。這將產生從00:00到24:00的時間戳,而在下一行代碼中,我必須再次過濾掉大部分時間戳。這似乎并不高效。"
就像上面的解決方案一樣,你可以重新采樣,然后使用 rule =
。1Min進行填充(或任何其他型別的填充)。這可以確保你不是從00:00到24:00重新取樣,而是只從你的資料中可用的開始到結束的時間戳重新取樣。為了證明這一點,我展示了應用于資料中的一個單一日期--#filtering for a single day。 ddd = df[df['date']==df.date.unique()[0] ] #applying resampling on that given day]。 ddd.set_index('Timestamp').resample('1Min').ffill()
注意給定日期的開始(09:30:00)和結束(16:00:00)時間戳。
2.只對現有的日期應用重采樣
。"在上面的例子中,它還會為2021-02-08生成以分鐘為單位的時間戳。我怎樣才能避免這種情況呢?"
正如上面的解決方案,你可以在日期組上分別應用重采樣方法。在這種情況下,我在將日期從時間戳中分離出來后,使用lambda函式應用該方法。所以重采樣只發生在存在于資料集中的日期
。df_new.Timestamp.dt.date.unique()array([datetime.date(2021, 2, 7], datetime. date(2021, 2, 9) ], dtype=object)注意,輸出只包含原始資料集中的兩個唯一的日期。
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/328887.html
標籤: