我有一個使用 DataFrame 進行計算的代碼。
------------------------------------ ------------ ---------- ---- ------
| Name| Role|Experience|Born|Salary|
------------------------------------ ------------ ---------- ---- ------
| 甕?滴?┦附?┊?鈃?蠾綜??翨?... | охранник| 16|1960|108111|
| 擲鱫??琱?縭????????滜?... | повар| 14|1977| 40934|
| ????壚??????翧?梒靻駌?... | геодезист| 29|1997| 27335|
| ?????烸??????????紕... | не охранн. | 4|1999 | 30000|
... ... ...
我嘗試以不同的方式快取表。
def processDataFrame(mode: String): Long = {
val t0 = System.currentTimeMillis
val topDf = df.filter(col("Salary").>(50000))
val cacheDf = mode match {
case "CACHE" => topDf.cache()
case "PERSIST" => topDf.persist()
case "CHECKPOINT" => topDf.checkpoint()
case "CHECKPOINT_NON_EAGER" => topDf.checkpoint(false)
case _ => topDf
}
val roleList = cacheDf.groupBy("Role")
.count()
.orderBy("Role")
.collect()
val bornList = cacheDf.groupBy("Born")
.count()
.orderBy(col("Born").desc)
.collect()
val t1 = System.currentTimeMillis()
t1-t0 // time result
}
我得到了讓我思考的結果。
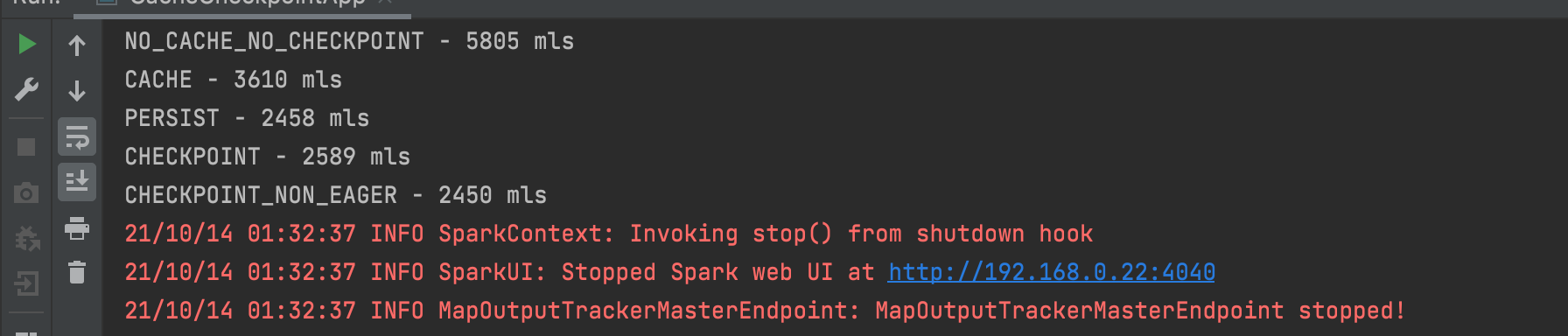
為什么 checkpoint(false) 比 persist() 更有效?畢竟,檢查點需要時間來序列化物件并將它們寫入磁盤。
PS我在GitHub上的小專案:https : //github.com/MinorityMeaning/CacheCheckpoint
uj5u.com熱心網友回復:
我沒有檢查過你的專案,但我認為值得討論一下。我希望您清楚地指出您沒有運行此代碼一次,而是平均多次運行,以確定此特定資料集的性能。(不是效率)Spark Clusters 可能有很多噪音,導致作業之間的差異,并且確實需要平均幾次運行才能確定性能。有幾個性能因素(資料位置/Spark Executors、資源爭用等)
我認為您不能說“高效”,因為這些功能實際上執行兩種不同的功能。由于他們所做的事情,他們在不同的情況下也會有不同的表現。有時您會想要檢查點、截斷資料沿襲或在計算成本非常高的操作之后。有時,重新計算譜系實際上比從磁盤寫入和讀取更便宜。
簡單的規則是,如果您要多次使用此表/DataFrame/DataSet,請將其快取在記憶體中。(不是磁盤)
一旦您遇到未完成作業的問題,請考慮可以調整的內容。從代碼角度/查詢角度。
在那之后...
當且僅當這與復雜作業的失敗有關并且您看到執行程式失敗時,請考慮使用磁盤來持久化資料。這應該始終是故障排除的后期步驟,而不是故障排除的第一步。
uj5u.com熱心網友回復:
堅持
使用 StorageLevel.DISK_ONLY 持久化或快取會導致 RDD 的生成被計算并存盤在一個位置,這樣該 RDD 的后續使用將不會超出該點重新計算行列。在persist 被呼叫后,即使它沒有呼叫它,Spark 仍然記住RDD 的血統。其次,應用程式終止后,清除快取或破壞檔案
檢查點
檢查點將 rdd 物理存盤到 hdfs 并破壞創建它的沿襲。即使在 Spark 應用程式終止后,檢查點檔案也不會被洗掉。Checkpoint 檔案可以在后續的作業運行或驅動程式中使用 Checkpointing 一個 RDD 會導致雙重計算,因為在執行計算和寫入檢查點目錄的實際作業之前,該操作將首先呼叫快取。您可能想閱讀這篇文章,了解 Spark 檢查點或快取操作的更多細節或內部原理。
Persist(MEMORY_AND_DISK) 將資料幀臨時存盤到磁盤和記憶體,而不會破壞程式的沿襲,即 df.rdd.toDebugString() 將回傳相同的輸出。建議在計算中使用persist(*),它將被重用以避免中間結果的重新計算:
df = df.persist(StorageLevel.MEMORY_AND_DISK)
計算1(df) 計算2(df)
請注意,快取資料幀并不能保證它會保留在記憶體中,直到您下次呼叫它為止。根據記憶體使用情況,可以丟棄快取。
另一方面,checkpoint() 會破壞沿襲并強制將資料幀存盤在磁盤上。與 cache()/persist() 的使用不同,頻繁的檢查點會減慢程式的速度。建議在以下情況下使用檢查點: a) 在不穩定的環境中作業以允許從故障中快速恢復 b) 當 RDD 的新條目依賴于先前的條目時存盤計算的中間狀態,即避免在失敗的情況下重新計算長依賴鏈
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/330073.html