我有以下字典
dict_map = {
'Anti' : {'Drug':('A','B','C')},
'Undef': {'Drug':'D','Name':'Type X'},
'Vit ' : {'Name': 'Vitamin C'},
'Placebo Effect' : {'Name':'Placebo', 'Batch':'XYZ'},
}
和資料框
df = pd.DataFrame(
{
'ID': ['AB01', 'AB02', 'AB03', 'AB04', 'AB05','AB06'],
'Drug': ["A","B","A",np.nan,"D","D"],
'Name': ['Placebo', 'Vitamin C', np.nan, 'Placebo', '', 'Type X'],
'Batch' : ['ABC',np.nan,np.nan,'XYZ',np.nan,np.nan],
}
我必須創建一個新列,它將使用串列中指定的列的資料來填充
cols_to_map = ["Drug", "Name", "Batch"]
最終結果應該是這樣的
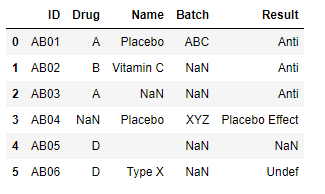
請注意,“結果”列的前 3 行填充了“抗”,盡管有“維生素 C”,而“安慰劑”是列“名稱”,這是因為“抗”在字典中排在第一位。我如何使用 python 實作這一點?dict_map 可以以任何方式重構以滿足這個結果。我不是 python 專業人士,我真的很感激一些幫助。
uj5u.com熱心網友回復:
首先為嵌套字典中元組的單獨值重塑嵌套字典:
from collections import defaultdict
d = defaultdict(dict)
for k, v in dict_map.items():
for k1, v1 in v.items():
if isinstance(v1, tuple):
for x in v1:
d[k1][x] = k
else:
d[k1][v1] = k
print (d)
defaultdict(<class 'dict'>, {'Drug': {'A': 'Anti', 'B': 'Anti',
'C': 'Anti', 'D': 'Undef'},
'Name': {'Type X': 'Undef', 'Vitamin C': 'Vit ',
'Placebo': 'PPL'}})
df = pd.DataFrame(
{
'ID': ['AB01', 'AB02', 'AB03', 'AB04', 'AB05','AB06'],
'Drug': ["A","B","A",np.nan,
"D","D"],
'Name': ['Placebo', 'Vitamin C', np.nan, 'Placebo', '', 'Type X']
}
)
然后按字典映射,按串列中列的順序排列優先級cols_to_map:
cols_to_map = ["Drug", "Name"]
df['Result'] = np.nan
for col in cols_to_map:
df['Result'] = df['Result'].combine_first(df[col].map(d[col]))
print (df)
ID Drug Name Result
0 AB01 A Placebo Anti
1 AB02 B Vitamin C Anti
2 AB03 A NaN Anti
3 AB04 NaN Placebo PPL
4 AB05 D Undef
5 AB06 D Type X Undef
cols_to_map = [ "Name","Drug"]
df['Result'] = np.nan
for col in cols_to_map:
df['Result'] = df['Result'].combine_first(df[col].map(d[col]))
print (df)
ID Drug Name Result
0 AB01 A Placebo PPL
1 AB02 B Vitamin C Vit
2 AB03 A NaN Anti
3 AB04 NaN Placebo PPL
4 AB05 D Undef
5 AB06 D Type X Undef
編輯:
df['Result1'] = df['Drug'].map(d['Drug'])
df['Result2'] = df['Name'].map(d['Name'])
print (df)
ID Drug Name Result1 Result2
0 AB01 A Placebo Anti PPL
1 AB02 B Vitamin C Anti Vit
2 AB03 A NaN Anti NaN
3 AB04 NaN Placebo NaN PPL
4 AB05 D Undef NaN
5 AB06 D Type X Undef Undef
uj5u.com熱心網友回復:
由于 dict 和預期結果之間的關系非常復雜,我將使用一個函式來應用您的 DataFrame。這使我們免于操作字典:
def get_result(row):
result = np.nan
for k,v in dict_map.items():
if row['Name'] in v.values():
result = k
if row['Name'] and type(row['Drug']) == str and 'Drug' in v.keys() and row['Drug'] in v['Drug']:
return k
return result
df['Result'] = df.apply(lambda row: get_result(row), axis=1)
print(df)
輸出:
ID Drug Name Result
0 AB01 A Placebo Anti
1 AB02 B Vitamin C Anti
2 AB03 A NaN Anti
3 AB04 NaN Placebo PPL
4 AB05 D NaN
5 AB06 D Type X Undef
在更新您的問題后,我將功能更改為通用。我不太確定它會涵蓋您的所有情況,因為您的輸出在新列中沒有太大變化:
col_to_maps = ["Drug", "Name", "Batch"]
def get_result(row, dict_map):
result = np.nan
for k,v in dict_map.items():
for i,col in enumerate(col_to_maps[:-1]):
if type(v)==dict:
if str(row[col]) and \
all(str(row[other_col])
and (not(str(other_col) in v.keys()) and str(col) in v.keys() and str(row[col]) in v[col]
or str(other_col) in v.keys() and str(row[other_col]) in v[other_col]
)
for other_col in col_to_maps[i 1:]
):
return k
elif str(row[col]) in v:
result = k
return result
df['Result'] = df.apply(lambda row: get_result(row, dict_map), axis=1)
print(df)
輸出:
ID Drug Name Batch Result
0 AB01 A Placebo ABC Anti
1 AB02 B Vitamin C NaN Anti
2 AB03 A NaN NaN Anti
3 AB04 NaN Placebo XYZ Placebo Effect
4 AB05 D NaN NaN
5 AB06 D Type X NaN Undef
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/331188.html