目的。 寫一個用戶定義的函式,使多個.csv檔案的整理程序自動化。
我有3個.csv檔案,即Finland_caucasian.csv, Mexico_hispanic.csv & Jamaica_black.csv。
以Finland_caucasian.csv為例,資料框架看起來像這樣:
date < - rep('1999'。 9)
cityID < - c(1001。 1001,1001, 1002。 1002,1002, 1005, 1005,1005)
國家 <- rep('FIN'/span>9)
名稱 < - rep('caucasian'。 9)。
prov_code < - c(1。 1,1, 2。 2, 3, 3, 2,3)
class < - c(1。 2,5, 1, 2,5,1。 2,5)
性別 < - c('M'。 'M','F', 'F'。 'F','M','F'。 'M','M')
savings_month1 <-c(/span>100. 12,105.11,109.11,94. 13,34.00, 201.91, 154. 39,212.76,233.48)
savings_month2 <-c(/span>110. 15,115.12,193.21, 194. 13,334.50,21.13,164. 19,292.67,235.85)
savings_month3 <-c(/span>109. 15,159.12,199.22,199. 18,339.59, 291.95, 169. 94,299.78,233.22)
data<- data. frame(date,cityID。 name,country,prov_code。 class,gender。 savings_month1,savings_month2,savings_month3)
資料
原始的整理程序(沒有用戶定義的函式)看起來像這樣 :
# template for the user-defined function- should import csv files in a folder
#############################################################################
data_wrangler <- function(input_multi_csvfiles){
# import each csv file.
for(files in filenames){
# wrangle process
}
}
# 測驗代碼
data_wrangler(files in folder path)
################################################################################################
# wrangling process的代碼 # wrangling process的代碼
library(dplyr)
#Step I: import all three files in R
data = read.csv("filepath//file_name. csv") # 'Finland_caucasian.csv', 'Mexico_hispanic.csv' and 'Jamaica_black.csv'
#Step II : 選擇需要的列名
df <- data%>%select(date: gender,savings_month1: savings_month3) # 我使用列索引`:`,因為其他csv檔案之間可能有不需要的列。
#Step III: 檢查唯一的prov_code, country,name, class。
print(unique(df$prov_code))
print(unique(df$country))
print(unique(df$name))
print(unique(df$class))
#Step IV: 根據'class'來過濾df
# 在這里,我想自動反映獨特的國家(FIN、MEX和JAM),而不是手動輸入三次國家,同樣,對于名字欄--高加索人、西班牙人和黑人。
country_name_df < -subset(df,country == 'FIN'/span> & 名稱 == 'caucasian' & class > = 1 & class < = 5) # 在其他csv檔案中,class的范圍是0到8,但我想只過濾1到5的class。
#Step V: Paste filtered class on each of the column names[/span]。
df10 < -過濾器(country_name_df。 class == 1)
#paste the filtered class condition to the column names
colnames(df10) < -粘貼('1'/span>。 colnames(df10)。 sep = '_')
df11 < -過濾器(country_name_df。 class == 2)
#paste the filtered class condition to the column names
colnames(df11) < -粘貼('2'/span>。 colnames(df11)。 sep = '_')
df12 < -過濾器(country_name_df。 class == 5)
#paste the filtered class condition to the column names
colnames(df12) < -粘貼('5'/span>。 colnames(df12)。 sep = '_')
#Step VI: column bind or merge df10, df11 and df12
df15 <- cbind(df10,df11,df12)
#check for content of class column of df15
unique(df15$`5_prov_code`)
#Step VII: 資料框架的最后整理作業
df20<- df15%>%select(`1_date`:`1_gender`)
df30 <-select(df15,contains("month")) # 選擇所有含有 "月 "字的列,例如 "1_savings_month1", "3_savings_month2 "等。
target <- df15$`1_prov_code'。
final_df <- cbind(df20,df30,target)
#步驟八:將每個final_df匯出為csv檔案
# wrangled_Finland caucasian.csv, wrangled_Mexico hispanic.csv, wrangled_Jamaica black.csv
write.csv(final_df,'wrangled_FIN caucasian.csv',row.names = FALSE)
我愿意接受其他想法。 謝謝
阿克倫的更新
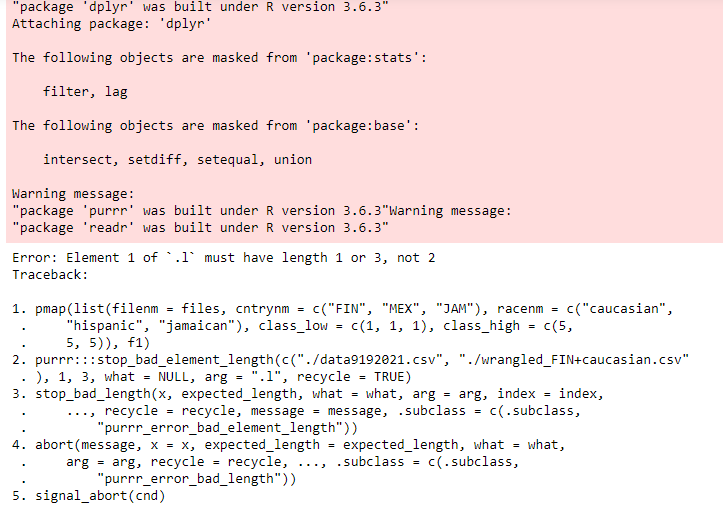
我運行了你的代碼(見下文)。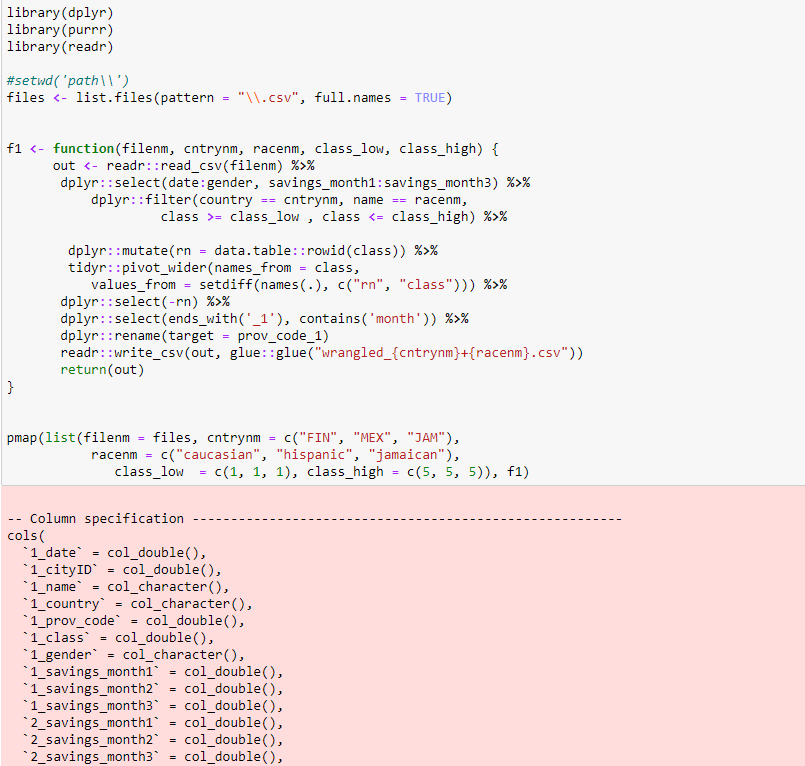
我得到了錯誤的資訊
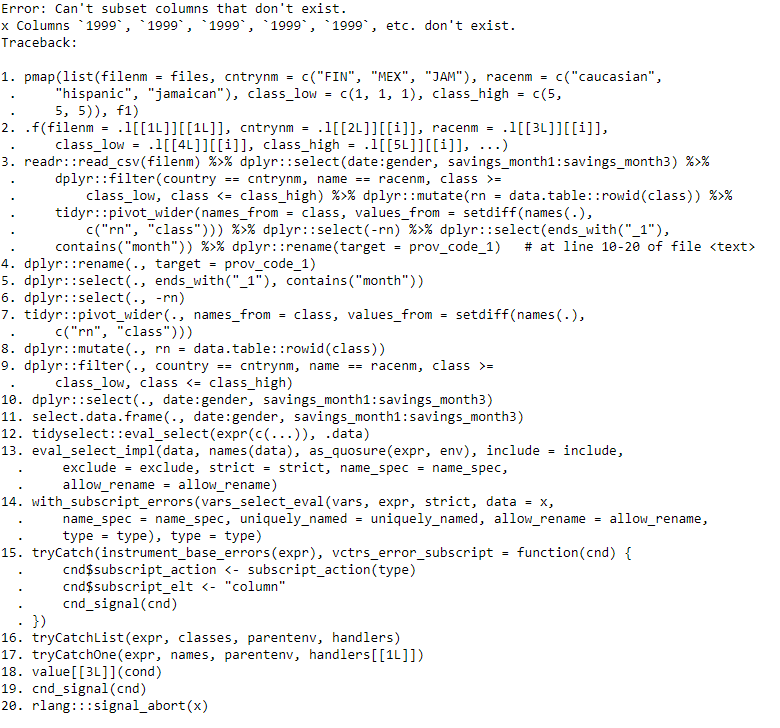
Update 2: gender_1之后的列名順序應該是這樣的 savings_month1_1, savings_month1_2,savings_month1_5, savings_month2_1,savings_month2_2,savings_month2_5,savings_month3_1,savings_month3_2, savings_month3_5

更新3:改變savings_month1:savings_month3
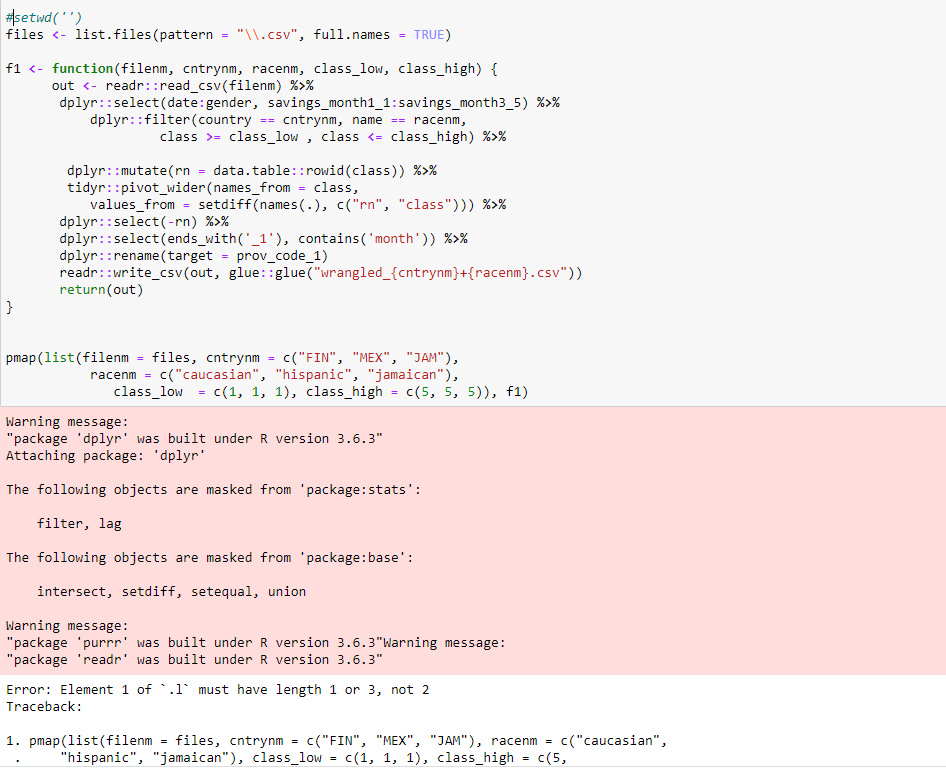
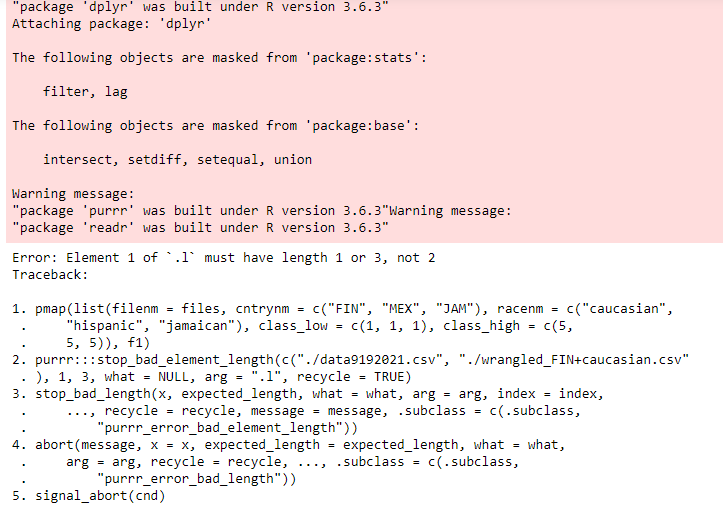
 uj5u.com熱心網友回復:
uj5u.com熱心網友回復:如果我們在作業目錄中有3個檔案,用map在list中讀取這些檔案,做select和filter步驟,并在'class'上使用group_by或split到一個list of data.fram
library(dplyr)
library(purrr)
library(readr)
files <- list.files(pattern = "/span>。 csv", full.names = TRUE)
df_list <- map(files, ~ read_csv(. x) %>%。
select(date:gender, savings_month1。 savings_month3) %>%
filter(country == 'FIN'/span>。 名稱 == 'caucasian',
class >= 1 ,/span> class < = 5) %>%
group_by(class))
如果我們需要一個帶引數的函式
f1 < - function(filenm, cntrynm, racenm, class_low, class_high) {
out <- readr::read_csv(filenm) %>%
dplyr::select(date: 性別,儲蓄_月1_1:儲蓄_月3_5) %>%
dplyr:: filter(country == cntrynm, name == racenm,)
class >= class_low ,/span> class < = class_high) %>%
dplyr::mutate(rn = data. table:: rowid(class) %>%
tidyr::pivot_wider(names_from = class,)
values_from = setdiff(names(. ), c("rn"/span>。 "class")) %> %
dplyr::select(-rn) %>%
dplyr:: select(ends_with('_1'>)。 包含('month')) %> %
dplyr::rename(target = prov_code_1)
readr::write_csv(out, glue: :glue("wrangled_{cntrynm} {racenm}. csv"))
return(out)
}。
然后,我們用pmap
pmap(list(filenm = files。 cntrynm = c("fin"。 "MEX", "JAM"), "JAM" ,
racenm = c("caucasian"。 "西班牙人", "牙買加人"),
class_low = c(1。 1, 1)。 class_high = c(5。 5。 5)),/span> f1)
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/332754.html
標籤:
上一篇:使用Nextjs創建網路服務是否需要Express?
下一篇:如何在單元測驗中使用敏感資料?