嗨,我有一個可能是新手的問題,但我已經很久沒有碰過R了。
我有一個大的資料集,其中每一列是一天的測量結果(第1天、第2天等),而行是不同的處理重復。我已經設法制作了一個包含所有平均值的表格,并將資料縮減為:行是處理結果,列是每天的平均值。現在我想把這些資料繪制成散點圖或直線圖,但我似乎不知道該用什么作為aes(x=),是否有辦法用一個單一的代碼來繪制它們,而不是為每一天和處理添加每個geom_point()。
下面是一個例子,因為資料更長、更復雜(24天,28個治療,每個治療有10個重復)。
我如何才能將資料繪制成這樣(Excel圖片)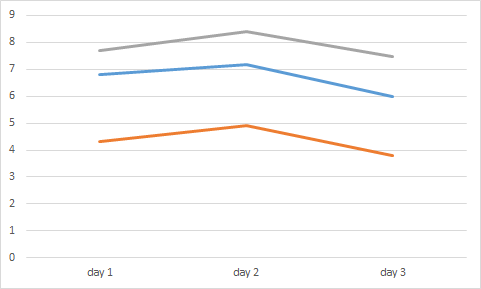 。
提前感謝大家,如果有任何幫助或反饋,我們將非常感激
。
提前感謝大家,如果有任何幫助或反饋,我們將非常感激
#df#
治療日 1 日 2 日 3
1 t1 7.524814 8.330983 6.639391
2 t1 6.056334 6.138648 5.439239[/span]。
3 t2 4.377818 4.964445 3.990593[/span]。
4 t1 6.834753 7.070450 5.895462[/span]。
5 t3 7.378768 8.375725 7.210010[/span]。
6 t2 4.104087 4.942359 3.589360[/span]。
7 t2 4.520651 4.775113 3.753422[/span]。
8 t3 7.875438 8.543303 8.101697[/span]。
9 t3 7.803648 8.232132 7.073342[/span
平均值<-合計(df[,2。 4]/span>。 list(df$treatment)。 mean)
sd<-aggregate(df[,2。 4]/span>。 list(df$treatment)。 sd)
#mean#。
組.1日1日2日3日
1 t1 6.805300 7.180027 5.991364
2 t2 4.334185 4.893972[/span> 3.777792[/span
3 t3 7.685951 8.383720 7.461683
ggplot() geom_point(mean。 aes(x=? ? ,y=mean$"day 1")
uj5u.com熱心網友回復:
你有幾種方法可以實作你的任務:
你的任務是什么?
ggplot()
版本1:
library(tidyverse)
df%>%
pivot_longer()
cols = -treatment,
names_to = "day",
values_to = "value"
) %>%
group_by(treatment,day) %>%
summarise(mean = mean(值)) %> %
ggplot(aes(x=day, y=mean。 color=treatment。 group=treatment))
geom_line()
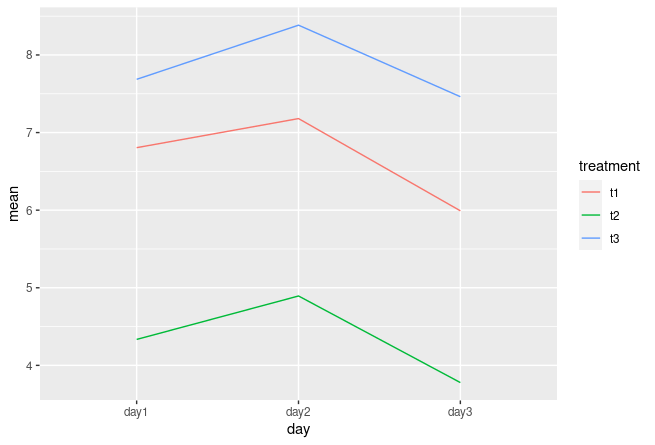
第2版
library(tidyverse)
df%>%
pivot_longer()
cols = -treatment,
names_to = "day",
values_to = "value"
) %>%
group_by(day) %>%
summarise(mean = mean(值)) %> %
ggplot(aes(x=day。 y=mean。 group=1)
geom_point()
geom_line(colour="red")
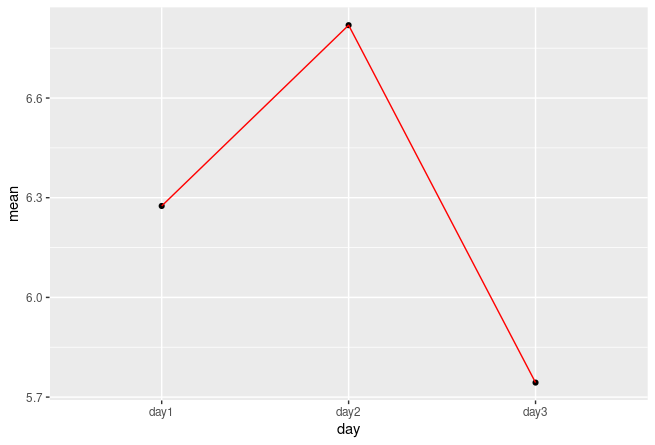
uj5u.com熱心網友回復:
ggplot喜歡 "長 "格式的資料。這里是一種對mean值進行處理的方法,你也可以對sd進行處理。
library(tidyverse)
df%>%
pivot_longer(cols = -treatment) %> %
group_by(treatment, name = factor(name。 unique(name)) %>。 %
summarise(value = mean(value), . groups = 'drop') %>% 。
ggplot(aes(name, 值,顏色=治療。 組=治療)) geom_line()
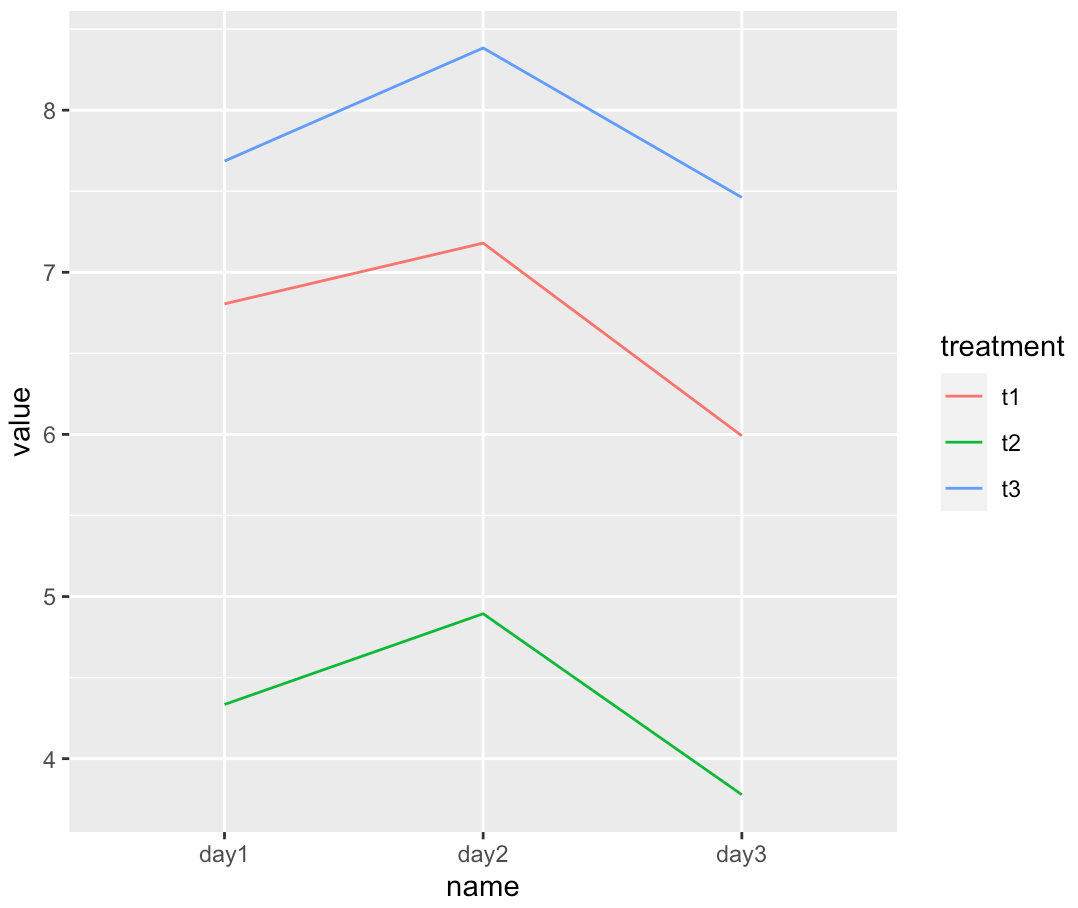
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/333022.html
標籤:
上一篇:Android:我怎樣才能知道什么依賴性需要某個mincompileapk?
下一篇:多色柱狀圖ggplot