
AnimationHitches 的運行原理
背景
在 Xcode12 中,Instrument 新增 AnimationHitches 檢測型別用以檢測卡頓,并去除 CoreAnimation 檢測方式,在支持 PromotionDisplay 的設備上幀率可調整至 120 幀,并且會根據當前用戶手勢和設備狀態進行動態調整,此時再繼續使用幀率來判斷性能的好壞及流暢度將會是一個錯誤的選擇,所以 AnimationHitches 主要用于代替幀率檢測,并且提出 卡頓時間比(Hitch Time Ratio) 的概念用于替代 FPS,由于目前關于 Hitch 相關的資料很少,而在 iPhone13Pro 之前 iPhone 螢屏最高重繪頻率仍為 60 HZ,所以很多同學都還未關注到該能力,所以本篇將主要介紹 Hitch(卡頓) 的概念、RenderLoop(渲染回圈) 的整體流程,卡頓型別及如何避免卡頓,
什么是卡頓?
? 概念
任何時候螢屏上出現晚于預計的幀都屬于卡頓,

? 實體
例如 滾動影片(Scroll)、點擊影片(Animation)、轉場影片(Transition),這些流暢的影片構建了一種用戶和螢屏內容的視覺連接感,而如果影片卡頓會導致影片畫面跳躍,打破這種連接感,用戶體驗會變得很差,

一個常見的例子,當用戶在操作一個滾動視圖上下滾動時,發生了卡頓,這是因為第四幀的延遲導致了第三幀占用了兩幀的時間,給用戶看到的就是卡頓掉幀的現象,
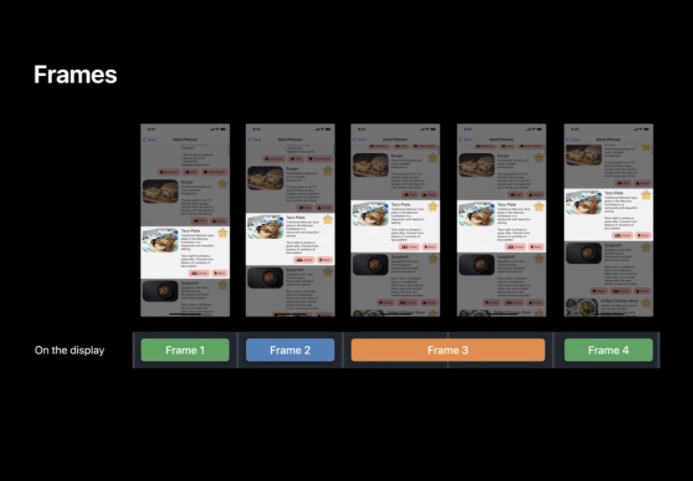
RenderLoop
? 概念
RenderLoop 是一個連續的程序,通過用戶手勢等將事件傳給 App,接著 App 向作業系統傳遞事件并最終回應事件,再將回應傳遞給用戶的程序,
RenderLoop 的時間隨著設備重繪頻率,在 iPhone13 Pro(Max) 以下的 iPhone 設備最大均為 60 幀,而 iPhone13 Pro(Max) 及 iPadPro 則最高支持 120 幀,也就是最短僅需每 8.33 毫秒就可以顯示一個新幀,
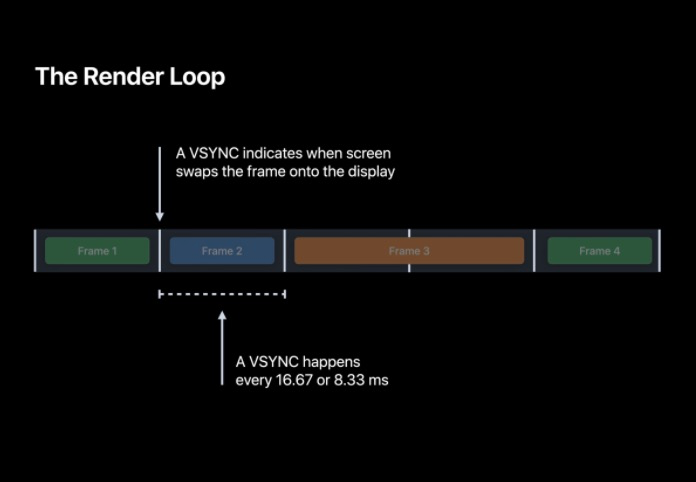
? 幀準備階段
在準備每一幀的程序中,可以總體分為三個階段,App、RenderServer 和 Display,其中 App 中主要進行一些用戶事件的處理,而 RenderServer 會進行真正的用戶界面繪制,這兩個階段都需要在下一個 VSNYC 到來前完成,最終到 Display 階段會將緩沖的幀展示出來,對這一幀進行雙幀處理我們把這稱之為雙緩沖,由于顯示幕是逐行掃描進行畫面顯示,雙緩沖和垂直同步機制避免了螢屏撕裂的現象,
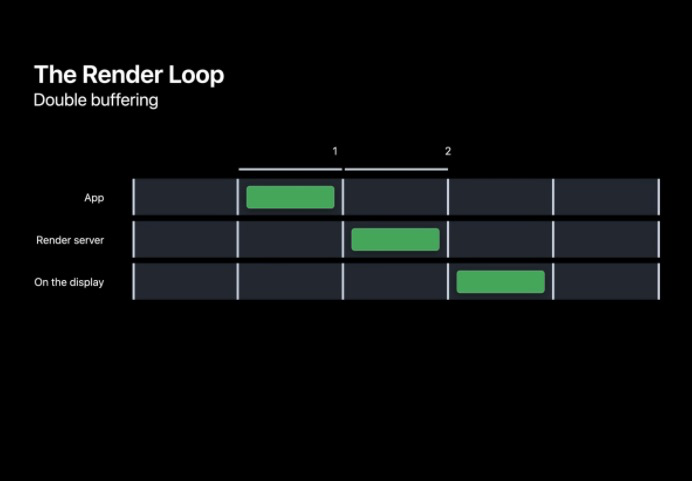
當然,系統也提供備用的三緩沖機制,為 RenderServer 提供額外的一幀進行渲染,該機制通常情況下不會開啟,
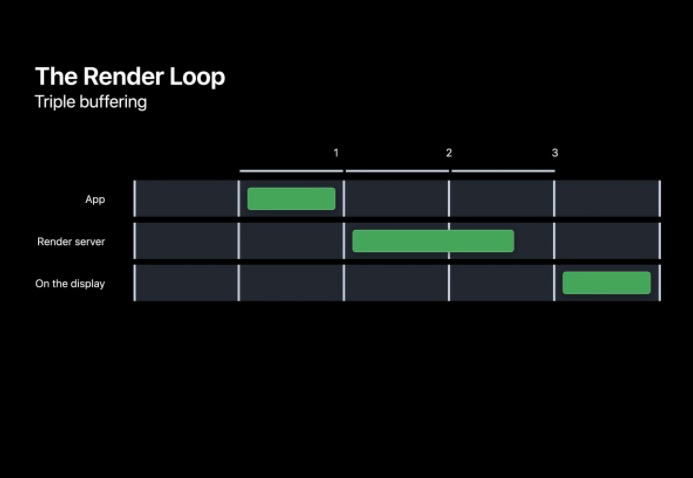
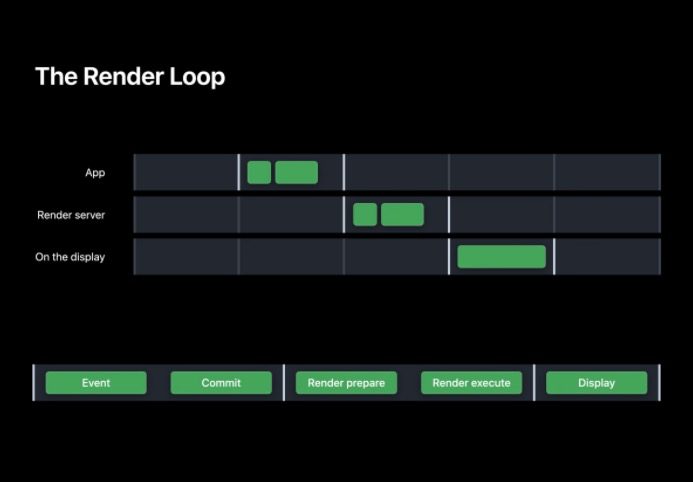
? 階段細節
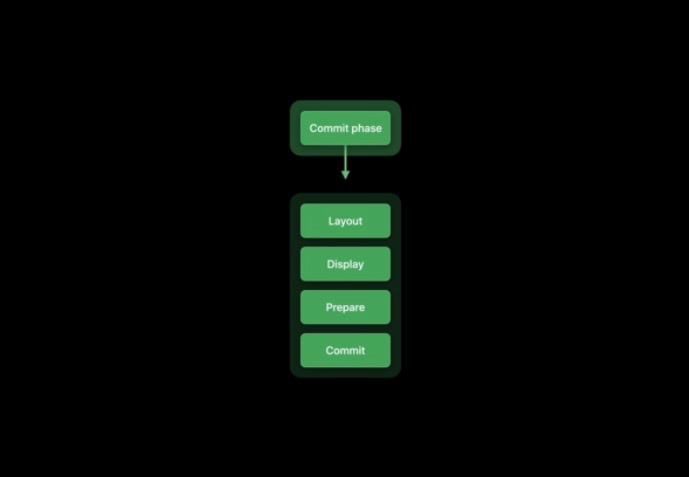
整個渲染回圈可細分為 5 個階段,其中在我們 App 中的為 Event,Commit 階段,而 Commit 階段可進一步細分為 Layout、Display、Prepare 和 Commit,
在事件階段通過 touch,timer 等事件決定用戶界面是否需要改變;
而在 Commit 階段 App 會向渲染服務器 RenderServer 提交渲染命令;
RenderServer 中的 Prepare,Execute 階段,在 Prepare 階段會為 GPU 的繪制做好準備,而在 Execute 階段會由 GPU 將用戶界面的影像繪制出來;
最后的 Display 階段會將緩沖幀交換到螢屏上顯示,
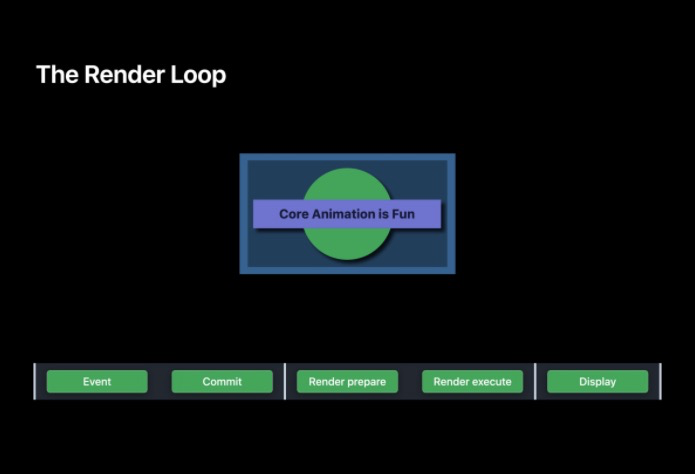
以一個帶有陰影的渲染圖形為例,觀察下 RenderLoop 中每一幀所做的作業
App
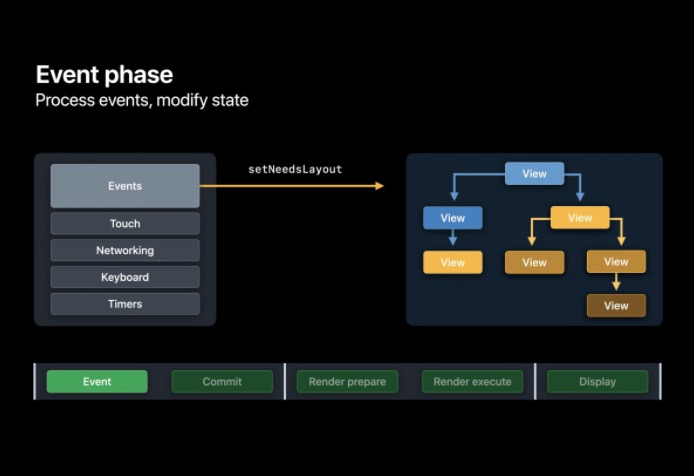
Event
在該階段表示 App 接收到了事件,比如 touch 事件、網路請求回呼、鍵盤和 Timer ,一個 App 可以通過改變其層級結構或是用任何其他方式回應這些事件,
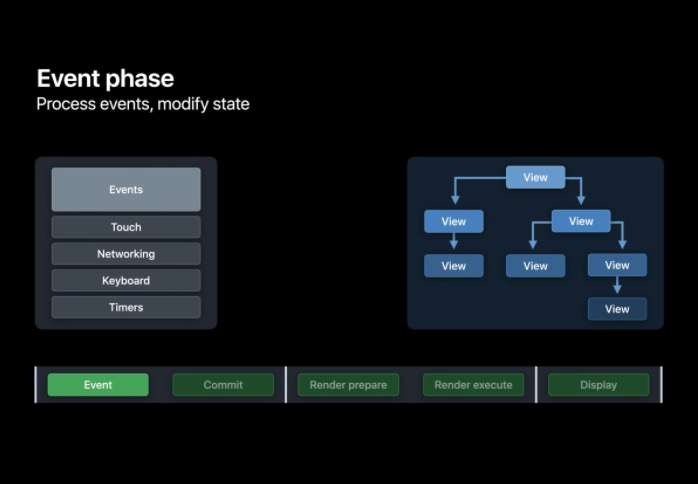
例如 App 能改變圖層的背景顏色,甚至能改變圖層的大小和位置,當 App 更新了圖層的限制范圍時, CoreAnimation 會同時會呼叫 setNeedsLayout,它能夠分辨哪些圖層必須要重新計算布局,系統會合并這些需要布局的請求并在 Commit 階段按順序執行,用以減少重復作業,
Commit
在一次事務的提交中共涉及四個不同的階段:布局階段、顯示階段、準備階段和最后的提交階段,
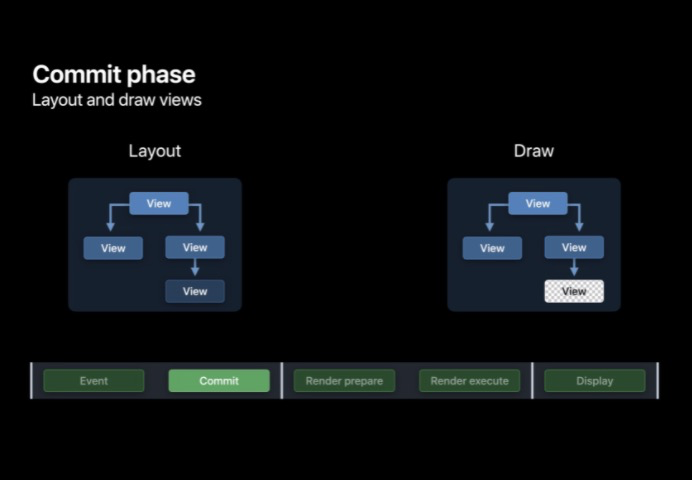
布局階段
在布局階段, layoutSubviews 會被所有需要布局的 View 呼叫,比如布局視圖(frame、bounds、transform),增加或移除視圖,亦或是直接呼叫 setNeedsLayout,注意這些布局操作并非立即執行,系統會合并這些布局請求,在 Runloop 休眠前統一執行這些操作,
顯示階段
在顯示階段,drawRect 會被每個需要被更新的 View 呼叫,比如 UILabel、UIImageView 或者只是任何重寫 drawRect 方法的類,他們必須呼叫 setNeedsDisplay 用以支持 View 的更新,在繪制時每個自定義的繪圖圖層都會接收到帶紋理的 CoreGraphics 的背景,他們將利用 CoreAnimation 進行繪制,這些圖層就變成了圖片,所以如果沒有必要則不要重寫 drawRect 方法,其不僅會額外開辟一塊記憶體用以存盤 bitmap,還會在 CPU 上進行繪制,增加了整體主執行緒時間占用,當自定義 drawRect 視圖較多時,對整體的記憶體壓力也比較大,
準備階段
在 Prepare 階段還沒有解碼的影像將會在這一步進行解碼,也就是我們需要優化的常見的圖片主執行緒解碼操作,
對于每個被解碼的影像, App 可能會持續存在大量的記憶體分配,這種記憶體分配與輸入影像的大小成正比,而與 FrameBuffer 中實際渲染的影像視圖的大小沒有必然聯系,當 App 占用越來越多的記憶體時,作業系統將會開始壓縮物理記憶體(physical memory),整個程序都需要 CPU 的參與,所以除了我們自己的 App 對 CPU 的使用外,還可能會增加無法控制的全域 CPU 使用率,最終,我們的 App 可能會消耗更多的物理記憶體,以至于作業系統需要啟動終止行程,它將從低優先級的后臺行程開始,如果我們的 App 對記憶體的消耗了達到了特定數量,可能會被終止,這也就是為什么經常會因為大圖的原因產生 OOM,
若某個影像的顏色格式 GPU 無法直接使用,也會在這一步進行格式轉換,這就要求對該影像進行 copy 操作,而不是直接使用指標,這樣會耗時更長及占用更多的記憶體,
提交階段
在提交階段中,視圖樹將會被遞回打包并發送到 RenderServer 中,所以當視圖層級較為復雜時,這個程序耗費的時間也會更長一些,所以需要盡量減輕視圖層級結構,
RenderServer
RenderServer 負責將我們的圖層樹轉換為真正可顯示的影像,RenderServer 有兩個階段:Prepare 和 Execute ,在 Prepare 階段我們的圖層樹被編譯成一系列簡單的指令,供 GPU 執行,幀影片也在此處進行處理,在渲染執行階段 GPU 將 App 的圖層繪制成最終影像,

下面來一個渲染實體,在下面這個實體中,圓形和長條周圍都有陰影,

Prepare
在準備階段, RenderServer 會廣度優先遍歷 App 的圖層樹,準備一個線性管線,這樣 GPU 就能按照順序執行命令進行繪制,從根圖層開始逐層遍歷,最終才有了 GPU 可以在下一個執行階段執行的整個管線,
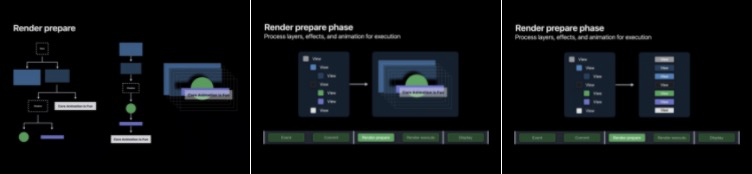
Execute
執行階段主要是由 GPU 根據前面 prepare 階段準備好的圖層樹進行頂點著色、形狀裝配、幾何著色、光柵化、片段著色與圖層混合,一旦 GPU 執行完會將渲染好的影像放入幀快取區中等待下一個 VSYNC 的到來并交換到螢屏上進行顯示,
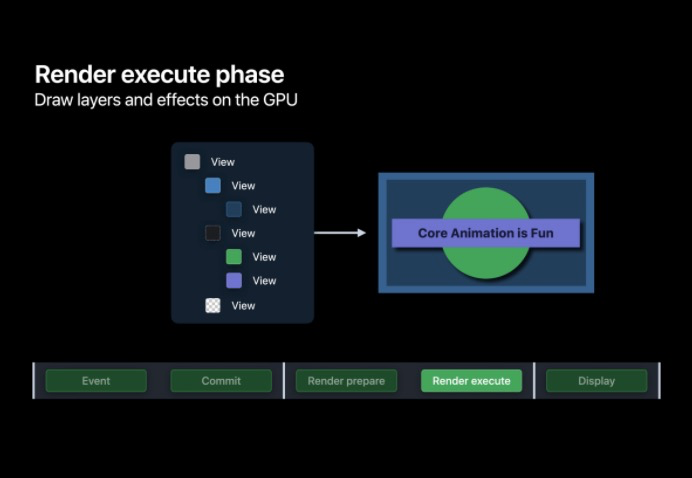
在該例中, GPU 的作業就是利用該管線將每一步都繪制成紋理并最終合成,最終在顯示階段會在螢屏上顯示該紋理,
從第一個藍色的圖層開始,它在指定的邊界內繪制顏色,然后深藍色被繪制在其邊界內,但是當前圓形和矩形中都有陰影,所以現在 GPU 必須先去繪制陰影,而陰影的形狀由還未繪制的兩層定義,所以需要先繪制圓形和矩形,為了避免這兩圖層被陰影遮擋,所以需要切換到不同的紋理先繪制陰影,對于這種情況我們稱之為“離屏渲染”,在這里需要額外開辟一塊記憶體用以繪制圓形和矩形,然后將該圖層變為黑色并且模糊來實作陰影的效果,
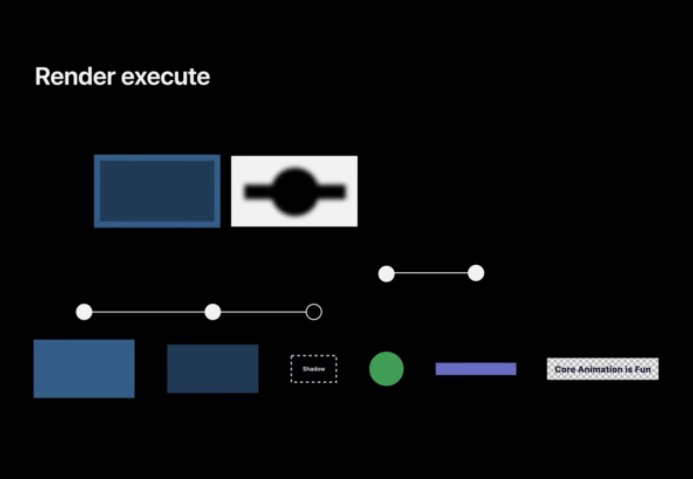
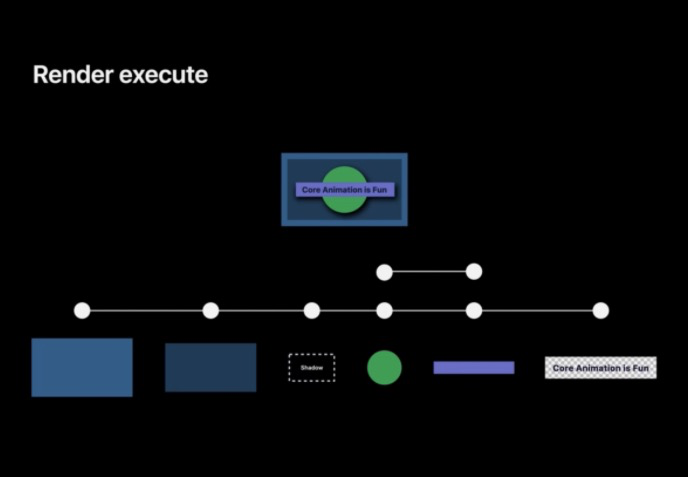
然后 GPU 可以將陰影的離屏渲染紋理復制到最終的紋理中,陰影圖層就完成了,下一步是再次繪制圓形和矩形,可以注意到的是,這里不僅開辟了一塊額外的存盤空間用以渲染陰影,圓形和矩形也被渲染了兩次,對性能損害極大,
而最后的文本是在 CPU 上完成繪制的, GPU 會通過復制 CPU 繪制的文本影像來完成,完成上述流程后,幀已經準備好進行顯示了,
需要注意在這個程序中我們不得不用離屏渲染來渲染陰影,導致渲染需要更長的時間,
離屏渲染
離屏渲染通道指的是 GPU 必須先在其它地方開辟一塊記憶體進行圖層渲染,然后再將其復制回來,就陰影而言,它必須繪制圖層,以確定最終形狀,

偶爾的離屏渲染對性能影響并不大,但離屏通道可能會積少成多,導致渲染出現卡頓,因此需要在 App 中監控并盡量避免,主要有四種主要型別的離屏通道可以優化:陰影、蒙版、圓角和毛玻璃,
Shadow:比如在實體中,如果不先繪制附加到圖形上面的陰影,GPU 就沒有足夠的資訊來繪制陰影,

Mask:當圖層或圖層樹需要被遮蔽時,GPU 需要渲染被遮蔽的子樹,它也需要避免覆寫被遮蔽形狀外的像素,因此它只會把最終需要顯示的像素復制回最終紋理,由于最終結果可能由多層渲染結果疊加,所以必須要利用額外的記憶體空間對中間的渲染結果進行快取,因此系統會默認來觸發離屏渲染,這種離屏渲染可能會導致渲染了許多用戶永遠不會看到的像素,

CornerRadius:由于 GPU 繪制時會先從根節點開始繪制,所以如果根節點上設定了圓角,并且設定了 maskToBounds 裁剪屬性,那就會需要一個額外的離屏渲染 buffer 用以快取中間的裁剪結果,并最終將圓角內的像素復制回來,組透明度等屬性都可能會觸發離屏渲染,

iOS8 中開始支持 UIBlurEffectView 控制元件用以支持模糊化和鮮亮化,要應用這些效果,GPU 必須用離屏通道將內容復制到另一個紋理中,然后對其進行模糊、縮放疊加等操作并將最終結果復制回來,

Display
Display 的程序實際上就是將幀快取區中的內容交換到顯示幕上進行最終顯示,這一程序我們參與不多,
? 總結
為了達到目標幀速率并且保持低輸入延遲,RenderLoop 的整個程序實際上是在每一幀中并行進行的,這樣管線就成了并行的,在系統渲染前一幀的同時 CPU 可以準備一個新幀,所以每幀的截止期都很重要,
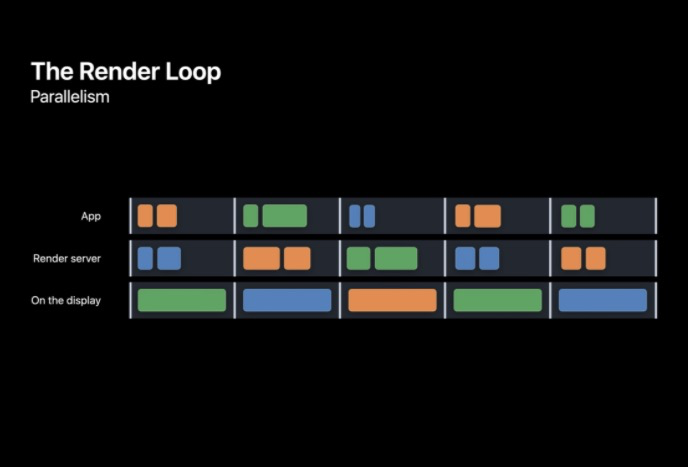
卡頓型別
上面已經描述了 RenderLoop 的整個作業流程,實際上主要是在 App 和 RenderServer 中進行,所以總共有兩種主要型別的卡頓:提交卡頓(發生在 App 中),渲染卡頓(發生在 RenderServer 中),

? 提交卡頓
概念
提交卡頓指的是 App 花費過長時間來處理或提交事件,
在提交中用了太長的時間而錯過了截止期,所以在下一個 VSYNC 中 RenderServer 沒有事情可以處理,必須等待下一個 VSYNC 到來后才能開始渲染,現在已經把幀傳送的時間推遲了一幀,以毫秒計時這將是 iPhone(60hz) 或 iPad 上的 16.67 毫秒,這個延遲時間就被稱為“卡頓時間(Hitch Time)”,如果提交作業花了更長的時間,比如通過了下一個 VSYNC 的起始時間,那么這一幀就晚了兩幀或者說是 33.34 毫秒,在這 33.34 毫秒中用戶都無法得到順暢的滾動,
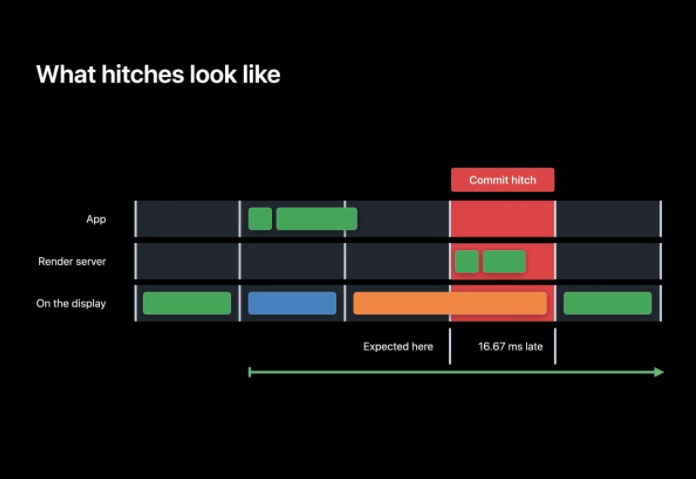
如何避免卡頓
保持視圖的輕量
為了保持視圖的輕量盡可能地利用CALayer 上 GPU 加速的可用屬性,如非必要需要避免使用 CPU 進行自定義繪制,
若非必要情況下不要重寫 drawRect 屬性,因為其會開辟額外的記憶體空間進行 CPU 繪制,并且在 CPU 上繪制會耗費更多的時間主執行緒,針對于文本、圖片等原本就在 CPU 上進行繪制的系統控制元件,我們可以嘗試使用其更底層執行緒安全的 CoreGraphics 能力,比如 TextKit、CoreText 等搭配多執行緒異步繪制減輕主執行緒壓力,
盡量復用視圖而不是頻繁的添加或移除視圖,
如果要把某一視圖從某一影片中移除,盡量使用 hidden 屬性,
對于 Prepare 階段,當我們的 UIImage 容器視圖的大小小于圖片本身時,我們通常可以使用 下采樣技術(downsampling) 來進行縮略圖的創建以節省部分記憶體空間,
避免復雜布局
減少代價過高且重復的布局,在需要更新布局時盡量只使用 setNeedsLayout,layoutIfNeeded 會消耗當前事務的生命周期也會造成卡頓,大多數時候你可以等到下一次 Runloop 執行時再更新你的布局,
嘗試使用最少的約束來完成布局,
視圖應該只能使自己或自己的子視圖無效,而不能使其同級視圖或父視圖無效,避免遞回布局,
避免非必要的視圖層級創建,復雜的視圖層級會增加提交階段的整體耗時
合理多執行緒能力
學會利用 GCD 的多執行緒能力,充分利用 CPU 多核優勢,提前在子執行緒進行布局等 UI 無關操作,避免主執行緒掛起(hang),
避免主執行緒 IO 等磁盤相關操作,
而針對于常見的主執行緒解碼操作,在 iOS15 之前,我們通常都是自己封裝或是利用最常見的第三方庫 SDWebImage 替我們在子執行緒進行解碼操作,而在 iOS15 中,Apple 終于提供了官方的解決方案以解決該問題:UIImage 的 prepareThumbnailOfSize:completionHandler: 等新介面,
針對于必須在 CPU 上進行繪制的組件,嘗試結合多執行緒使用異步繪制能力減輕主執行緒壓力,
? 渲染卡頓
概念
渲染卡頓會在渲染服務器無法按時準備或者執行圖層樹時出現,這里顯然 Execute 的時長超過了 VSYNC 的界限,因此這一幀無法按時準備好,綠色的畫面比預期的晚了一幀于是有了 16 毫秒的卡頓
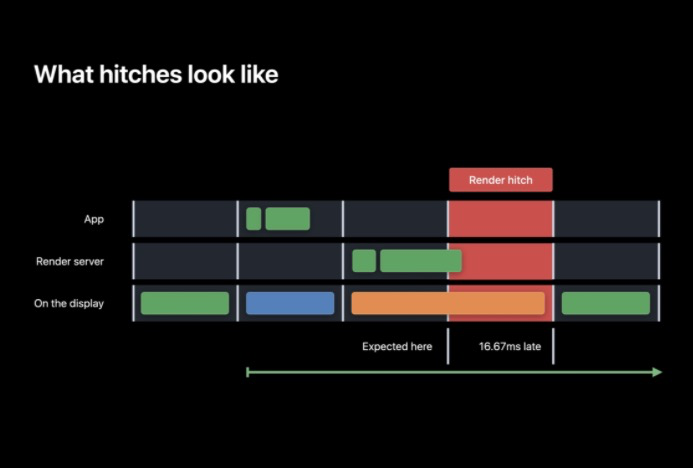
如何避免卡頓
準備階段我們影響較少,通常主要影響在于執行階段的離屏渲染,對于陰影來說,在設定陰影時,確保設定 shadowPath 以減少大量離屏通道,在圓化矩形時,使用 cornerRadius 和 cornerCurve 屬性避免用蒙版或角內容來構成圓角矩形,

優化整個 App 的 Mask,使用 masksToBounds 遮蔽為矩形圓角矩形或橢圓形的性能比自定義蒙版圖層好得多,重要的是用 Instruments 來對 App 進行分析并檢查圖層樹以獲得重要的技巧從而降低整體離屏計數,
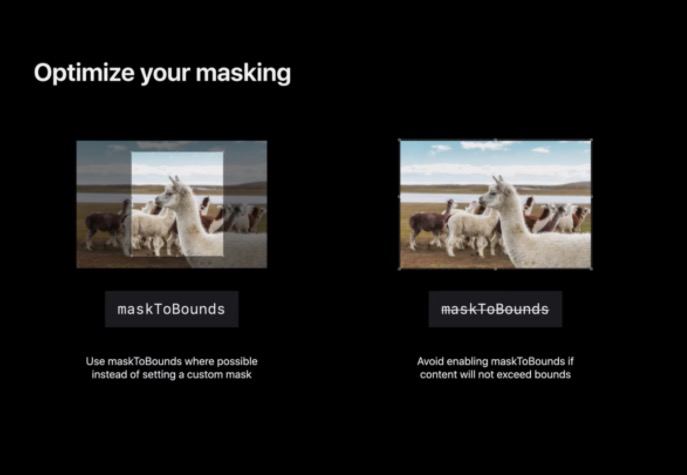
合理并謹慎的使用 shouldRasterize 屬性,它會對一塊圖層進行光柵化操作并進行快取,若針對于需要頻繁重繪的圖層使用該屬性反而對性能有著負面影響,
盡量使用非透明的圖層以盡量減少圖層混合,
檢測卡頓
當只著眼于一個卡頓或幾個卡頓時,卡頓時間是很有用的,但在像在滾動、影片或者是轉場等時長更長的事件時會變得很難處理,除非每次滾動或者影片用的都是完全相同的時間,這樣就會有相同的幀數,并且 iOS 設備并不總是更新螢屏,如果沒有事務發送到 RenderServer 上,新的一幀就不會被提交,通過測驗來比較卡頓時間就更難了,所以 Apple 提供了一種叫 “卡頓時間比(Hitch Time Ratio)” 的指標來衡量一段時間內的卡頓情況,
卡頓時間比就是一個區間內的總卡頓時間除以它的持續時間,因為它標準化為總時間,我們就能在不同的實踐中交叉比較,它是由每秒中的卡頓毫秒時間來測定的,所以代表著設備在每秒內出現卡頓的毫秒數,

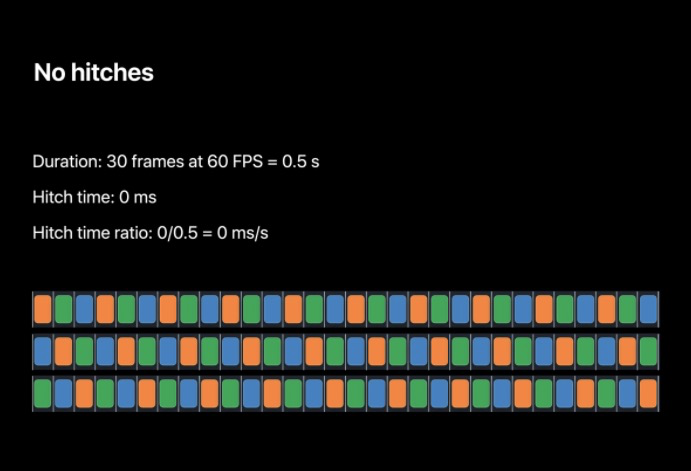
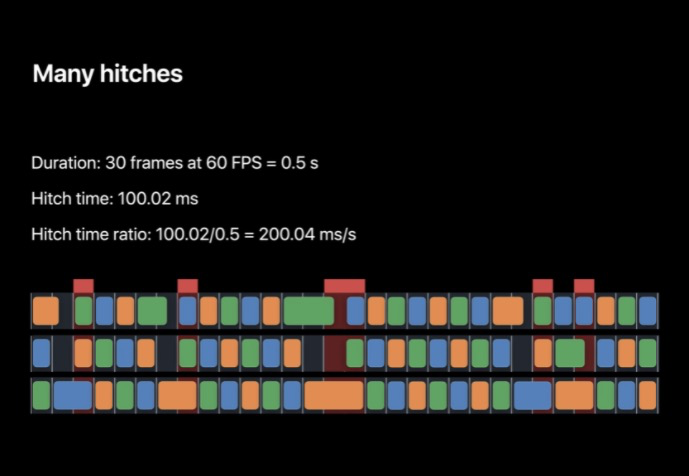
一個實體如下,在一臺 iPhone(60HZ) 上這是半秒的作業量,每一幀都在 VSYNC 到來前準備好了,所以用戶看不到卡頓,卡頓時間為 0,卡頓時間比也為 0,
第二個例子如下,在該例中有時是在提交階段的卡頓,有時是在 RenderServer 中造成了卡頓,將卡頓時間加起來結果就是 100.02 ms 半秒,我們就得到了每秒 200.04 ms 的卡頓時間比,
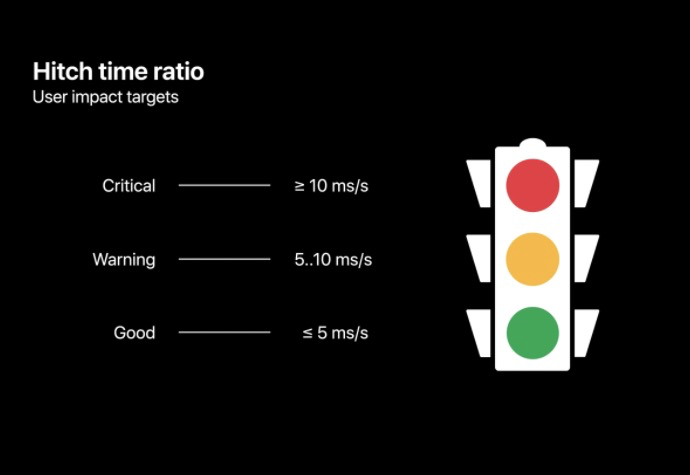
以下是蘋果建議的卡頓時間比目標,目標是 5 ms/s 以下的卡頓,是最不易被用戶察覺到的,5~10 ms/s 的卡頓用戶就會察覺到一些中斷,超過 10 ms/s 就會嚴重影響用戶體驗,
總結
本篇主要討論了 RenderLoop 以及新的一幀展現給用戶的整個流程,并且著眼于什么是卡頓,以及它的兩種型別:提交卡頓以及渲染卡頓,并最終定義了卡頓時間比用以測量當前 App 的卡頓程度和性能,相信大家對整個渲染回圈和卡頓型別有了更清晰的認識,在日常編碼中也可以盡量避免這些問題,
本篇主要介紹了一些原理相關的概念,那么具體的卡頓應該如何測量?下一篇將會通過實踐結合 Instrument 的 AnimationHitches 能力分析 DXSDK 作為卡片層面在日常資訊流的使用程序中在性能方面存在的一些問題,以及 DXSDK 上半年做的一些性能優化改進,
參考資料
WWDC 2020,2021
? 拓展閱讀


作者|嵐遙
編輯|橙子君
出品|阿里巴巴新零售淘系技術


轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/340457.html
標籤:其他