我的資料框 loopsubset_created包含 45 個變數的 30 個觀察值。(下面你會找到str(loopsubset_created)一個dput(loopsubset_created)樣本)。
現在我想創建PdKeyT-Variable (y) 與五個帶值變數 ( BLUE, GREEN, RED, SWIR1, SWIR2) (x) 的散點圖
- 一個面板中的每個變數
- 所有面板排成一排
- 使用
PdKeyT變數作為公共 y 軸。
最后它應該基本上是這樣的:(
我用 ggscatter 做到了這一點,但出于靈活性的原因,我更喜歡基本上使用 ggplot)

現在我的問題是:
嘗試使用 ggplot 時,我沒有找到上述顯示安排的正確方法,因為我無法找出按變數分隔/分組的正確代碼。我找到了數百個通過變數中的多個類別值進行分面的教程,但沒有通過多個變數進行分面。
使用以下代碼
ggplot(loopsubset_created, aes(y = PdKeyT))
geom_point(aes(x = BLUE, col = "BLUE"))
geom_point(aes(x = GREEN, col = "GREEN"))
geom_point(aes(x = RED, col = "RED"))
geom_point(aes(x = SWIR1, col = "SWIR1"))
geom_point(aes(x = SWIR2, col = "SWIR2"))
我得出了這個基本結果
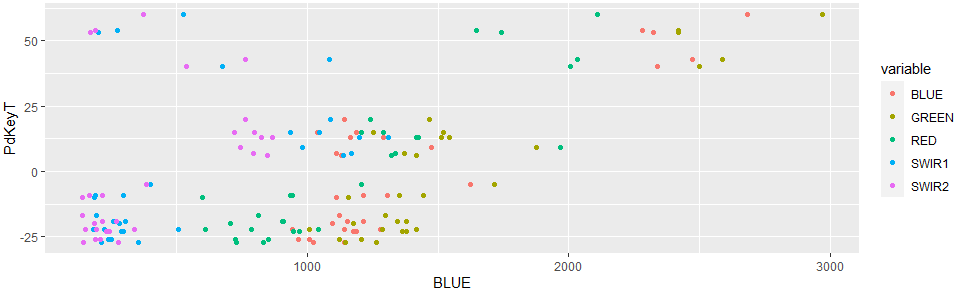
這里是基本問題:
現在,我想按照上面描述的方式將 5 層單獨排成一行 有人對我有想法嗎?
加上一些關于這個問題的資訊:
雖然以下方面不是我的問題的直接部分,但我想描述一下我對情節的最終想法(為了避免您的建議可能與進一步的要求發生沖突):
每個面板應包括
- Spearman corr value and according p-value (as shown above) and
- additionaly Pearson corr value and according p-value
- Linear regression with conf. interval (as shown above) or other type of regression line (not shown)
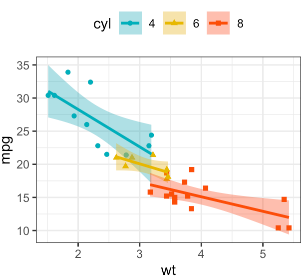
- Points should be couloured by variable (BLUE=bLue, RED= red; GREEN=green, SWIR1 2 by some other coulours, e.g. magenta and violet)
- later on points and regressionlines should be subdived by ranges of
PdKeyT(e.g. below -10, -10-to 30, and above 30) with using differnt brightness values of variable basic colours (blue, green, ...), analogouos to this:
- All panels should use ONE common y-axis at the left as explained
- And I would like to adpat the x-axes by the range of the respecitve variable (e.g. range for BLUE, GREEN and RED from 500 to 3000 and the SWIRs from 0 to 1500
edit 31.10.2021 referring to your answers:
- Would it furtheron be possible with your respective approaches to limit the x-axes individually as depicted in the 'further requirements' of my question (B-G-R ranging from 500 to 3000, SWIRs from 0 to 1500) with using
coord_cartesian(xlim = c(min,max))?
I am asking because I read some discussions with issues on limiting axes depending on the 'faceting approach'. But I'd like to control the x-axes, because I'll have many of these plots stacked on top of each other (My sample mirrored the data of just one sampling point out of 300). And i would be glad if getting them aligned. - I'd meanwhile prefer to discrete points and reglines just by gray scale colors (for all bands the same) and rather discretely coloring the panels by
theme(panel.background = element_rect(fill = "#xxxxxx"). Do you see an issue with that?
Finally some information and sample of my data
> str(loopsubset_created)
'data.frame': 30 obs. of 45 variables:
$ Site_ID : chr "A" "A" "A" "A" ...
$ Spot_Nr : chr "1" "1" "1" "1" ...
$ Transkt_Nr : chr "2" "2" "2" "2" ...
$ Point_Nr : chr "4" "4" "4" "4" ...
$ n : int 30 30 30 30 30 30 30 30 30 30 ...
$ rank : int 3 3 3 3 3 3 3 3 3 3 ...
$ Tile : chr "1008" "1008" "1008" "1008" ...
$ Date : int 20190208 20190213 20190215 20190218 20190223 20190228 20190302 20190305 20190315 20190320 ...
$ id : chr "22" "22" "22" "22" ...
$ Point_ID : chr "1022" "1022" "1022" "1022" ...
$ Site_Nr : chr "1" "1" "1" "1" ...
$ Point_x : num 356251 356251 356251 356251 356251 ...
$ Point_y : num 5132881 5132881 5132881 5132881 5132881 ...
$ Classification : num 7 7 7 7 7 7 7 7 7 7 ...
$ Class_Derived : chr "WW" "WW" "WW" "WW" ...
$ BLUE : num 1112 1095 944 1144 1141 ...
$ GREEN : num 1158 1178 1009 1288 1265 ...
$ RED : num 599 708 613 788 835 ...
$ REDEDGE1 : num 359 520 433 576 665 761 618 598 881 619 ...
$ REDEDGE2 : num 83 82 65 169 247 404 116 118 532 162 ...
$ REDEDGE3 : num 73 116 81 142 233 391 56 171 538 131 ...
$ BROADNIR : num 44 93 60 123 262 349 74 113 560 125 ...
$ NIR : num 37 70 66 135 215 313 110 135 504 78 ...
$ SWIR1 : num 187 282 184 225 356 251 240 216 507 197 ...
$ SWIR2 : num 142 187 155 197 281 209 192 146 341 143 ...
$ Quality.assurance.information: num 26664 10272 10272 10272 8224 ...
$ Q00_VAL : num 0 0 0 0 0 0 0 0 0 0 ...
$ Q01_CS1 : num 0 0 0 0 0 0 0 0 0 0 ...
$ Q02_CSS : num 0 0 0 0 0 0 0 0 0 0 ...
$ Q03_CSH : num 1 0 0 0 0 0 0 0 1 0 ...
$ Q04_SNO : num 0 0 0 0 0 0 0 0 0 0 ...
$ Q05_WAT : num 1 1 1 1 1 1 1 1 1 1 ...
$ Q06_AR1 : num 0 0 0 0 0 0 0 0 0 0 ...
$ Q07_AR2 : num 0 0 0 0 0 0 0 0 0 0 ...
$ Q08_SBZ : num 0 0 0 0 0 0 0 0 0 0 ...
$ Q09_SAT : num 0 0 0 0 0 0 0 0 0 0 ...
$ Q10_ZEN : num 0 0 0 0 0 0 0 0 0 0 ...
$ Q11_IL1 : num 1 1 1 1 0 0 0 0 0 0 ...
$ Q12_IL2 : num 0 0 0 0 0 0 0 0 0 0 ...
$ Q13_SLO : num 1 1 1 1 1 1 1 1 1 1 ...
$ Q14_VAP : num 1 0 0 0 0 0 0 0 1 0 ...
$ Q15_WDC : num 0 0 0 0 0 0 0 0 0 0 ...
$ PdMax : int -7 -19 -20 -22 -24 -25 -26 -25 -21 -15 ...
$ PdMin : int -13 -23 -24 -26 -28 -29 -29 -28 -24 -20 ...
$ PdKeyT : int -10 -20 -22 -22 -27 -26 -26 -27 -22 -17 ...
loopsubset_created <- structure(list(Site_ID = c("A", "A", "A", "A", "A", "A", "A",
"A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A",
"A", "A", "A", "A", "A", "A", "A", "A", "A", "A"), Spot_Nr = c("1",
"1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1",
"1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1",
"1", "1", "1"), Transkt_Nr = c("2", "2", "2", "2", "2", "2",
"2", "2", "2", "2", "2", "2", "2", "2", "2", "2", "2", "2", "2",
"2", "2", "2", "2", "2", "2", "2", "2", "2", "2", "2"), Point_Nr = c("4",
"4", "4", "4", "4", "4", "4", "4", "4", "4", "4", "4", "4", "4",
"4", "4", "4", "4", "4", "4", "4", "4", "4", "4", "4", "4", "4",
"4", "4", "4"), n = c(30L, 30L, 30L, 30L, 30L, 30L, 30L, 30L,
30L, 30L, 30L, 30L, 30L, 30L, 30L, 30L, 30L, 30L, 30L, 30L, 30L,
30L, 30L, 30L, 30L, 30L, 30L, 30L, 30L, 30L), rank = c(3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L,
3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L), Tile = c("1008",
"1008", "1008", "1008", "1008", "1008", "1008", "1008", "1008",
"1008", "1008", "1008", "1008", "1008", "1008", "1008", "1008",
"1008", "1008", "1008", "1008", "1008", "1008", "1008", "1008",
"1008", "1008", "1008", "1008", "1008"), Date = c(20190208L,
20190213L, 20190215L, 20190218L, 20190223L, 20190228L, 20190302L,
20190305L, 20190315L, 20190320L, 20190322L, 20190325L, 20190330L,
20190401L, 20190416L, 20190419L, 20190421L, 20190501L, 20190506L,
20190524L, 20190531L, 20190603L, 20190620L, 20190625L, 20190630L,
20190705L, 20190710L, 20190809L, 20190814L, 20190903L), id = c("22",
"22", "22", "22", "22", "22", "22", "22", "22", "22", "22", "22",
"22", "22", "22", "22", "22", "22", "22", "22", "22", "22", "22",
"22", "22", "22", "22", "22", "22", "22"), Point_ID = c("1022",
"1022", "1022", "1022", "1022", "1022", "1022", "1022", "1022",
"1022", "1022", "1022", "1022", "1022", "1022", "1022", "1022",
"1022", "1022", "1022", "1022", "1022", "1022", "1022", "1022",
"1022", "1022", "1022", "1022", "1022"), Site_Nr = c("1", "1",
"1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1",
"1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1", "1",
"1", "1"), Point_x = c(356250.781, 356250.781, 356250.781, 356250.781,
356250.781, 356250.781, 356250.781, 356250.781, 356250.781, 356250.781,
356250.781, 356250.781, 356250.781, 356250.781, 356250.781, 356250.781,
356250.781, 356250.781, 356250.781, 356250.781, 356250.781, 356250.781,
356250.781, 356250.781, 356250.781, 356250.781, 356250.781, 356250.781,
356250.781, 356250.781), Point_y = c(5132880.701, 5132880.701,
5132880.701, 5132880.701, 5132880.701, 5132880.701, 5132880.701,
5132880.701, 5132880.701, 5132880.701, 5132880.701, 5132880.701,
5132880.701, 5132880.701, 5132880.701, 5132880.701, 5132880.701,
5132880.701, 5132880.701, 5132880.701, 5132880.701, 5132880.701,
5132880.701, 5132880.701, 5132880.701, 5132880.701, 5132880.701,
5132880.701, 5132880.701, 5132880.701), Classification = c(7,
7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7, 7,
7, 7, 7, 7, 7, 7, 7, 7), Class_Derived = c("WW", "WW", "WW",
"WW", "WW", "WW", "WW", "WW", "WW", "WW", "WW", "WW", "WW", "WW",
"WW", "WW", "WW", "WW", "WW", "WW", "WW", "WW", "WW", "WW", "WW",
"WW", "WW", "WW", "WW", "WW"), BLUE = c(1112, 1095, 944, 1144,
1141, 1010, 968, 1023, 1281, 1124, 1215, 1154, 1188, 1177, 1622,
1305, 1215, 2282, 2322, 2337, 2680, 2473, 1143, 1187, 1165, 1040,
1290, 1112, 1474, 1131), GREEN = c(1158, 1178, 1009, 1288, 1265,
1208, 1122, 1146, 1416, 1298, 1379, 1345, 1379, 1366, 1714, 1446,
1354, 2417, 2417, 2500, 2967, 2587, 1469, 1522, 1544, 1253, 1514,
1371, 1875, 1416), RED = c(599, 708, 613, 788, 835, 852, 726,
729, 1044, 816, 905, 908, 948, 970, 1206, 944, 935, 1648, 1741,
2004, 2109, 2032, 1241, 1290, 1419, 1206, 1424, 1339, 1969, 1321
), REDEDGE1 = c(359, 520, 433, 576, 665, 761, 618, 598, 881,
619, 722, 771, 829, 823, 937, 725, 759, 1327, 1395, 1756, 1718,
1753, 1533, 1528, 1683, 1335, 1605, 1499, 2016, 1592), REDEDGE2 = c(83,
82, 65, 169, 247, 404, 116, 118, 532, 162, 183, 218, 285, 200,
514, 182, 230, 568, 531, 1170, 780, 1101, 1192, 1174, 1250, 949,
1121, 1127, 1382, 1159), REDEDGE3 = c(73, 116, 81, 142, 233,
391, 56, 171, 538, 131, 205, 137, 321, 253, 503, 193, 214, 564,
527, 1192, 698, 1177, 1203, 1259, 1341, 1049, 1146, 1216, 1416,
1188), BROADNIR = c(44, 93, 60, 123, 262, 349, 74, 113, 560,
125, 121, 211, 325, 221, 480, 184, 178, 461, 435, 1067, 570,
1023, 961, 966, 964, 844, 764, 993, 1197, 834), NIR = c(37, 70,
66, 135, 215, 313, 110, 135, 504, 78, 115, 216, 197, 163, 462,
113, 165, 392, 349, 1006, 574, 1092, 1153, 1143, 1128, 961, 1033,
1027, 1164, 1086), SWIR1 = c(187, 282, 184, 225, 356, 251, 240,
216, 507, 197, 306, 260, 298, 290, 400, 190, 300, 275, 204, 678,
528, 1087, 1091, 1049, 1310, 935, 1199, 1169, 984, 1139), SWIR2 = c(142,
187, 155, 197, 281, 209, 192, 146, 341, 143, 271, 220, 246, 232,
387, 168, 217, 193, 173, 540, 374, 764, 766, 799, 869, 724, 827,
794, 745, 848), Quality.assurance.information = c(26664, 10272,
10272, 10272, 8224, 8224, 8224, 8224, 24616, 8224, 8224, 8224,
32, 8224, 8288, 24616, 8224, 8240, 48, 8208, 8240, 8192, 8192,
24648, 8192, 8192, 8192, 8192, 0, 8224), Q00_VAL = c(0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0), Q01_CS1 = c(0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0),
Q02_CSS = c(0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0), Q03_CSH = c(1,
0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0, 0, 0), Q04_SNO = c(0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0), Q05_WAT = c(1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0,
0, 1), Q06_AR1 = c(0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0), Q07_AR2 = c(0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0), Q08_SBZ = c(0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0), Q09_SAT = c(0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0), Q10_ZEN = c(0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0), Q11_IL1 = c(1,
1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0), Q12_IL2 = c(0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0), Q13_SLO = c(1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1,
0, 1), Q14_VAP = c(1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0), Q15_WDC = c(0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0), PdMax = c(-7L, -19L, -20L,
-22L, -24L, -25L, -26L, -25L, -21L, -15L, -19L, -17L, -23L,
-22L, -4L, -7L, -8L, 55L, 57L, 47L, 67L, 44L, 21L, 18L, 13L,
16L, 16L, 9L, 12L, 11L), PdMin = c(-13L, -23L, -24L, -26L,
-28L, -29L, -29L, -28L, -24L, -20L, -22L, -22L, -26L, -26L,
-7L, -11L, -11L, 46L, 47L, 36L, 52L, 37L, 17L, 14L, 9L, 11L,
9L, 5L, 5L, 2L), PdKeyT = c(-10L, -20L, -22L, -22L, -27L,
-26L, -26L, -27L, -22L, -17L, -19L, -19L, -23L, -23L, -5L,
-9L, -9L, 54L, 53L, 40L, 60L, 43L, 20L, 15L, 13L, 15L, 13L,
7L, 9L, 6L)), row.names = 198:227, class = "data.frame")
uj5u.com熱心網友回復:
更新:
為了完成你的最后一個任務,我可以使用來自 Allan Cameron 的代碼:添加另一列來設定剪切mutate(range = cut(PdKeyT, c(-Inf, -10, 30, Inf), c("Low", "Mid", "High"))) %>%(此代碼由 Allan Cameron 提供)
library(tidyverse)
library(ggpubr)
df_long_list <- loopsubset_created %>%
select(PdKeyT, BLUE, GREEN, RED, SWIR1, SWIR2) %>%
pivot_longer(
cols = -PdKeyT
) %>%
mutate(color = case_when(name=="BLUE" ~ "blue",
name=="GREEN" ~ "green",
name=="RED" ~ "red",
name=="SWIR1" ~ "magenta",
name=="SWIR2" ~ "violet"))%>%
mutate(range = cut(PdKeyT, c(-Inf, -10, 30, Inf), c("Low", "Mid", "High"))) %>%
group_split(name)
p <- ggplot()
for (i in 1:5) p <- p geom_point(data=df_long_list[[i]], aes(value, PdKeyT, color=color, alpha=range))
geom_smooth(data=df_long_list[[i]], aes(value, PdKeyT, group=range), method = lm, se=TRUE)
theme(legend.position="none")
stat_cor(data=df_long_list[[i]], aes(value, PdKeyT,
label=paste("Spearman",..r.label.., ..p.label.., sep = "~`,`~")), method="spearman",
# label.x.npc="left", label.y.npc="top", hjust=0)
label.x = 3, label.y = 70)
stat_cor(data=df_long_list[[i]], aes(value, PdKeyT,
label=paste("Pearson",..r.label.., ..p.label.., sep = "~`,`~")), method="pearson",
# label.x.npc="left", label.y.npc="top", hjust=0)
label.x = 3, label.y = 65)
facet_grid(.~name, scales = "free")
theme_bw()
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
plot.margin = margin(120, 10, 120, 10),
panel.border = element_rect(fill = NA, color = "black"))
p

以下是您可以這樣做的方法:
- 選擇所有相關列
- 引入長格式
- 將顏色列添加到資料框
- 制作一個資料框串列
group_split - 使用 for 回圈遍歷串列中的 5 個資料幀中的每一個
- 在回圈中
stat_cor從ggpubr包中添加pearson 和 spearman - facet 并進行一些格式化
library(tidyverse)
library(ggpubr)
df_long_list <- loopsubset_created %>%
select(PdKeyT, BLUE, GREEN, RED, SWIR1, SWIR2) %>%
pivot_longer(
cols = -PdKeyT
) %>%
mutate(color = case_when(name=="BLUE" ~ "blue",
name=="GREEN" ~ "green",
name=="RED" ~ "red",
name=="SWIR1" ~ "magenta",
name=="SWIR2" ~ "violet"))%>%
group_split(name)
p <- ggplot()
for (i in 1:5) p <- p geom_point(data=df_long_list[[i]], aes(value, PdKeyT, color=color))
geom_smooth(data=df_long_list[[i]], aes(value, PdKeyT), method = lm, se=TRUE)
theme(legend.position="none")
stat_cor(data=df_long_list[[i]], aes(value, PdKeyT,
label=paste("Spearman",..r.label.., ..p.label.., sep = "~`,`~")), method="spearman",
# label.x.npc="left", label.y.npc="top", hjust=0)
label.x = 3, label.y = 70)
stat_cor(data=df_long_list[[i]], aes(value, PdKeyT,
label=paste("Pearson",..r.label.., ..p.label.., sep = "~`,`~")), method="pearson",
# label.x.npc="left", label.y.npc="top", hjust=0)
label.x = 3, label.y = 65)
facet_grid(.~name, scales = "free_y")
theme_bw()
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
plot.margin = margin(120, 10, 120, 10),
panel.border = element_rect(fill = NA, color = "black"))
p
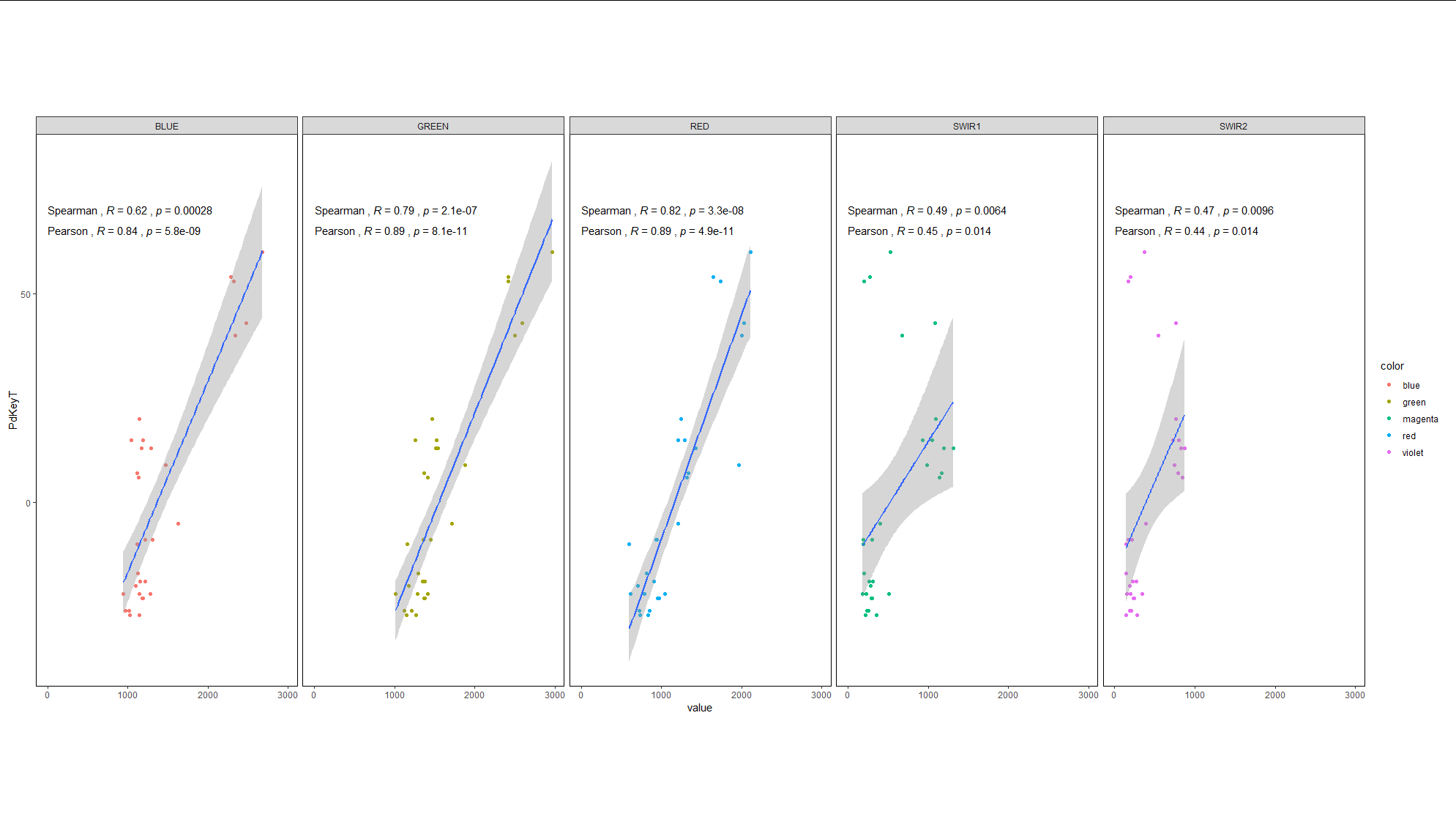
uj5u.com熱心網友回復:
我認為這滿足了您的大部分要求,除了相關注釋。如果,正如您在問題中提到的,您希望每個面板有 3 個回歸(三個范圍中的每一個PdkeyT),您還需要每個面板有 3 個相關系數和 p 值,這會很麻煩。
您沒有看到每個變數具有不同方面的教程的原因是這不是方面是什么。分面是一種顯示具有相同 x 軸和 y 軸但因某些其他分類變數而不同的資料的方式。它們的目的不是根據相同的 y 變數繪制不同的 x 變數。您所描述的是并排的 5 個不同的圖,而不是方面。
話雖如此,仍然可以通過創造性地使用方面來創建您正在尋找的情節。您首先需要將資料整形為長格式,以便不同 x 軸列的值堆疊到一個名為 的列中value,并name創建一個名為 的新列,以根據每個值最初來自哪個列來標記每個值。
然后我們可以使用新value列作為我們的 x 軸變數,并根據name列進行分面。
為了使其看起來更真實,我們進行了一些theme調整以確保刻面條類似于軸標簽:
library(dplyr)
library(tidyr)
library(ggplot2)
loopsubset_created %>%
select(PdKeyT, BLUE, GREEN, RED, SWIR1, SWIR2) %>%
pivot_longer(-1) %>%
mutate(range = cut(PdKeyT, c(-Inf, -10, 30, Inf), c("Low", "Mid", "High"))) %>%
ggplot(aes(value, PdKeyT, color = name))
geom_point(aes(alpha = range))
geom_smooth(aes(group = range), size = 0.1,
method = "lm", formula = y ~ x, color = "black")
labs(x = "")
facet_grid(.~name, switch = "x", scales = "free_x")
scale_color_manual(values = c("blue", "green", "red", "magenta", "violet"))
theme_bw()
theme(strip.placement = "outside",
strip.background = element_blank(),
plot.margin = margin(120, 10, 120, 10),
legend.position = "none")
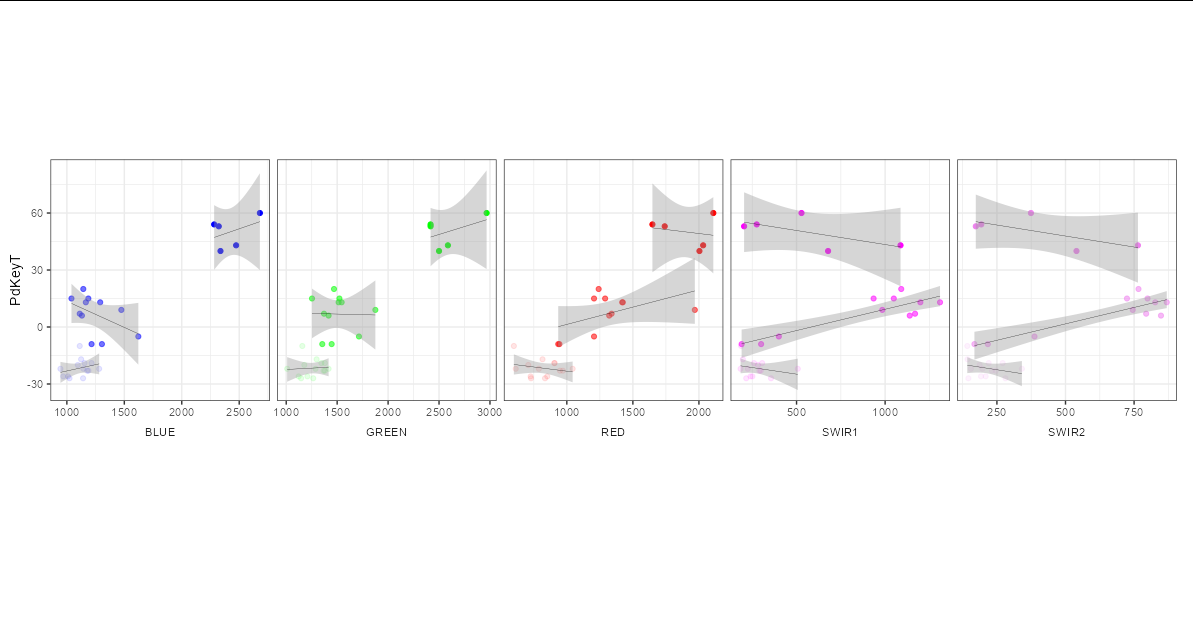
uj5u.com熱心網友回復:
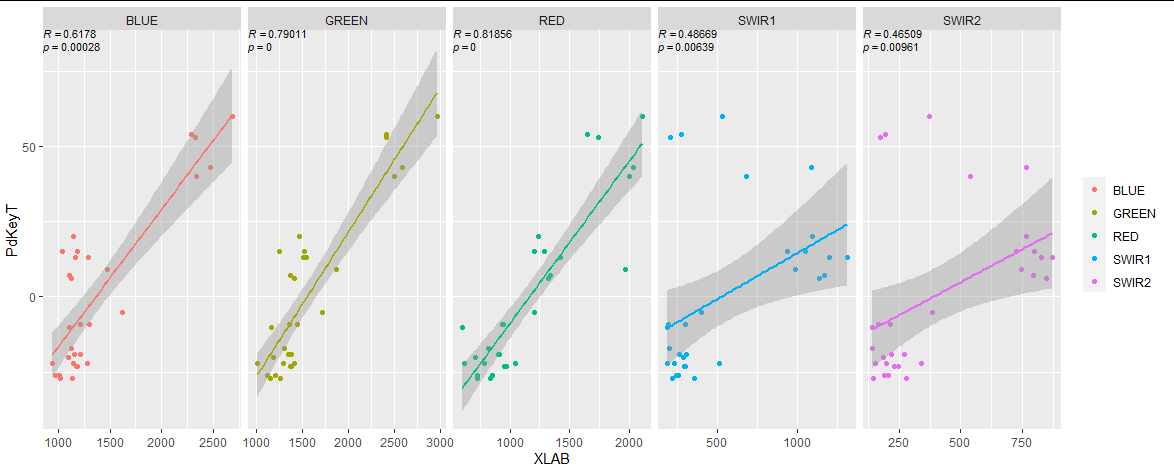
面板圖使用facet_wrap或facet_grid。此外,當您的資料為長格式時,通常 ggplot2 效果更好。這允許您將變數分配給美學,而不是像您那樣手動進行。
library(ggplot2)
library(tidyr)
library(purrr)
library(dplyr)
library(tibble)
# lengthen your data so variable names are in a column
df <- loopsubset_created %>%
pivot_longer(cols = c(BLUE:RED, starts_with("SWIR")))
# get correlation coef and pvalue
r <- map(split(df, ~ name), ~ with(.x, c(cor(PdKeyT, value, method = "spearman"),
cor.test(PdKeyT, value, method = "spearman")$p.value))) %>%
bind_rows() %>%
rownames_to_column("i") %>% # first row is coef, second row is p value
pivot_longer(-i) %>%
mutate(lab = ifelse(i == 1,
# formatted so will be parsed by geom_text
sprintf("italic(R) == %0.5f", value),
sprintf("italic(p) == %0.5f", value)),
x = -Inf, # left of panel
y = Inf, # top of panel,
vjust = ifelse(i == 1, 0.75, 2)) # put p-value below
df %>%
ggplot(aes(x = value, y = PdKeyT, color = name))
geom_point()
geom_text(data = r,
aes(x = x, y = y,
label = lab,
vjust = vjust),
size = 3,
parse = T,
inherit.aes = F)
geom_smooth(method = "lm",
se = T,
formula = y ~ x,
show.legend = F)
facet_grid(~ name,
scales = "free_x")
labs(color = element_blank(),
x = "XLAB")
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/343062.html
下一篇:重新創建資料框以使用for回圈