我正在使用 R 編程語言。我想到了以下我想測驗的問題:
- 假設有一枚硬幣有 5% 的機會落在正面,有 95% 的機會落在反面
基于計算機模擬,我想找出以下內容:
觀察 HEADS、TAILS、HEADS 之前的最小翻轉次數
觀察 HEADS、TAILS、HEADS 之前的平均翻轉次數
觀察 HEADS、TAILS、HEADS 之前的最大翻轉次數
我試圖用 R 撰寫一個模擬,將這個硬幣拋三遍,我稱之為“運行”。然后模擬執行 100 次“運行”:
results <- list()
for (i in 1:100){
response_i <- c("H","T")
response_i <- sample(response_i, 3, replace=TRUE,
prob=c(0.05, 0.95))
response_i <- as.factor(response_i)
iteration_i = i
run_i = data.frame(response_i, iteration_i)
results[[i]] <- run_i
}
這看起來如下(例如運行#22、#23、#24):
[[22]]
response_i iteration_i
1 T 22
2 T 22
3 T 22
[[23]]
response_i iteration_i
1 H 23
2 T 23
3 T 23
[[24]]
response_i iteration_i
1 T 24
2 T 24
3 T 24
我的問題:
我想修改上面的代碼,以便:
1)看到第一個 H、T、H 后模擬自動停止(現在,我運行了 100 次模擬,希望這足以觀察到至少一個 H、T、T)
2)一旦出現第一個 H, T, H 并且模擬自動停止,我想記錄發生的“運行”(即“迭代_i”的值是多少?)
3)然后我想重復整個模擬 100 次(100 次運行 * 100 次 = 10,000 次硬幣翻轉)
一旦完成,我將能夠制作直方圖,顯示在觀察到 H、T、H 之前的最小拋硬幣次數、平均拋硬幣次數和最大拋硬幣次數(使用“ggplot2”,我不'認為這不會太難)。
#sample data
number_of_runs_before_HTH_appeared = c(15,10, 11, 8, 12, 21, 32, 7, 9, 20, 22, 3, 16, 7 )
hist(number_of_runs_before_HTH_appeared, main = "Number of Runs before HTH")
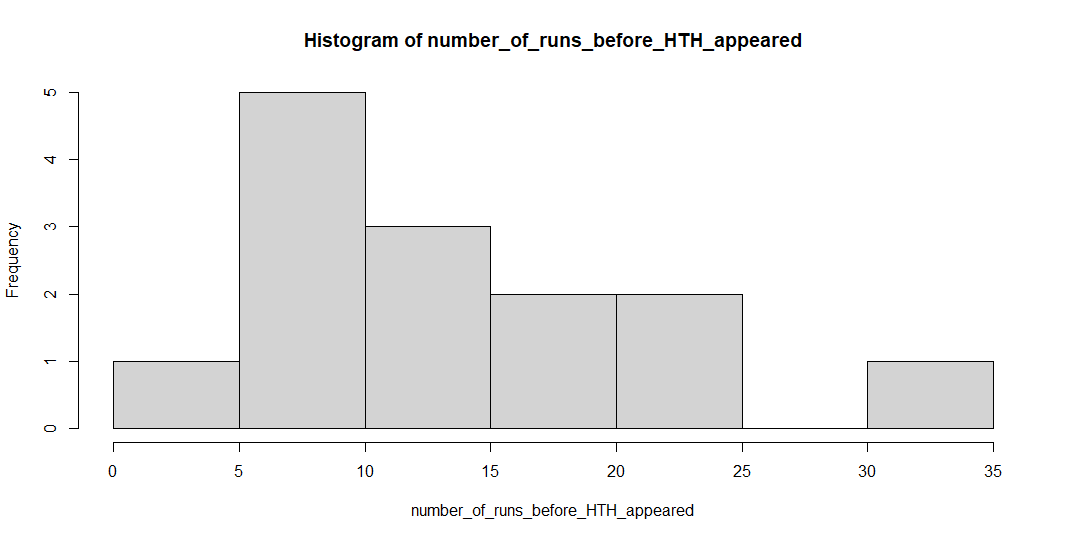
但是有人可以幫我格式化/修改我的代碼以簡化我想要實作的目標嗎?目前,我使用以下 R 代碼“整理”了第一次模擬中的 100 個“運行”:
results_df <- do.call(rbind.data.frame, results)
head(results_df)
response_i iteration_i
1 T 1
2 T 1
3 T 1
4 T 2
5 T 2
6 T 2
然后我手動重復了很多次,例如
results_df_1 <- do.call(rbind.data.frame, results)
results_df_1$index = 1
#re-run original simulation
results_df_2<- do.call(rbind.data.frame, results)
results_df_2$index = 2
#re-run original simulation (many times)
results_df_n<- do.call(rbind.data.frame, results)
results_df_n$index = n
final <- data.frame(results_df_1, results_df_2, results_df_n)
然后我將這個“最終”檔案匯入 Microsoft Excel 并嘗試手動折疊“最終檔案”來回答我的三個原始問題 - 但我希望有人可以通過修改我在 R 中的原始代碼來告訴我如何做到這一點。
有人可以幫我解決這個問題嗎?
謝謝!
uj5u.com熱心網友回復:
for 和 while 回圈的組合將滿足您的目的。
for回圈將運行您想要重復測驗的次數,而 while回圈將幫助您在第一個 HTH 組合發生時停止測驗。
下面是您可以使用的代碼并繼續執行進一步的步驟。
results <- list()
for (j in 1:100) {
response_i <- ''
i <- 1
while (response_i != 'HTH') {
response_i <- c("H","T")
response_i <- sample(response_i, 3, replace=TRUE,
prob=c(0.05, 0.95))
response_i <- paste(response_i, collapse = '')
iteration_i = i
if (response_i == 'HTH') {
run_i = data.frame(response_i, iteration_i)
results[[j]] <- run_i
}
i <- i 1
}
}
data <- do.call('rbind', results)
head(data)
response_i iteration_i
1 HTH 1206
2 HTH 46
3 HTH 116
4 HTH 1633
5 HTH 889
6 HTH 43
uj5u.com熱心網友回復:
這可能會讓你開始
library(data.table)
n <- 100
simulations <- 100
# build data.table with simulations
DT <- data.table(sim = rep(1:simulations, each = n),
step = 1:n,
flip = lapply(
lapply(seq.int(n * simulations),
function(x) sample(c("H","T"), 3, replace=TRUE, prob=c(0.05, 0.95))),
paste0, collapse = ""))
# sim step flip
# 1: 1 1 TTT
# 2: 1 2 TTT
# 3: 1 3 TTT
# 4: 1 4 TTT
# 5: 1 5 TTT
# ---
# 9996: 100 96 THT
# 9997: 100 97 TTT
# 9998: 100 98 TTT
# 9999: 100 99 TTT
# 10000: 100 100 TTT
DT
# find the first step where flip == "HTH" for each sim
DT[flip == "HTH", .(first_hth = min(step)), by = .(sim)]
# sim first_hth
# 1: 2 88
# 2: 6 30
# 3: 7 16
# 4: 19 38
# 5: 26 42
# 6: 28 91
# 7: 34 87
# 8: 36 96
# 9: 38 98
# 10: 45 74
# 11: 48 93
# 12: 51 46
# 13: 53 30
# 14: 60 70
# 15: 68 27
# 16: 69 53
# 17: 88 35
# 18: 91 88
# 19: 94 74
# 20: 95 100
# 21: 97 81
# 22: 98 24
# sim first_hth
uj5u.com熱心網友回復:
library(tidyverse)
set.seed(42)
coin_flip <- crossing(trial = seq_len(1000),
flips = 1:1000) %>%
mutate(heads = rbinom(n(), 1, .05)) %>%
group_by(trial) %>%
mutate(second_flip = lead(heads),
third_flip = lead(heads,2),
hth = heads & !second_flip & third_flip) %>%
summarise(first_hth = which(hth)[1] 2)
coin_flip %>% head()
#> # A tibble: 6 x 2
#> trial first_hth
#> <int> <dbl>
#> 1 1 46
#> 2 2 31
#> 3 3 114
#> 4 4 NA
#> 5 5 776
#> 6 6 292
coin_flip %>% ggplot(aes(first_hth))
geom_histogram()
#> `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
#> Warning: Removed 96 rows containing non-finite values (stat_bin).
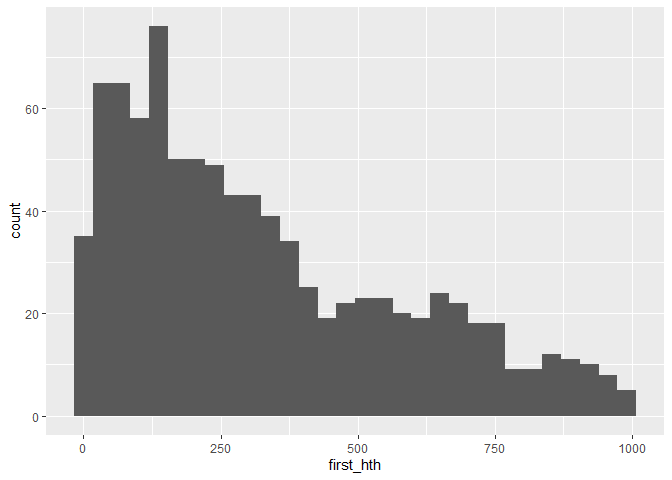
由reprex 包(v2.0.1)于 2021 年 11 月 22 日創建
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/364177.html