嘗試使用以下開放資料集繪制以下內容:
為了清楚起見,我試圖繪制以下資訊:
地理:加拿大
作業型別:全職
y= 兩性
組: 教育水平
任何指標都會有所幫助,謝謝!
uj5u.com熱心網友回復:
這產生的不僅僅是一個灰色方塊,但是,我懷疑它實際上是您所追求的:
library(tidyverse)
wages = read_csv('https://data.ontario.ca/dataset/1f14addd-e4fc-4a07-9982-ad98db07ef86/resource/7b325fa1-e9d6-4329-a501-08cdc22a79df/download/v0913_05.csv')
wages |>
subset(Geography == "Canada" & `Type of work` == "Full-time") |>
ggplot( aes(x=YEAR, y=`Both Sexes`, group=`Education level`, colour = `Education level`))
geom_line(alpha=0.6 , size=.5)
labs(title = "Wages for Full-Time employees by Education Level in Canada")
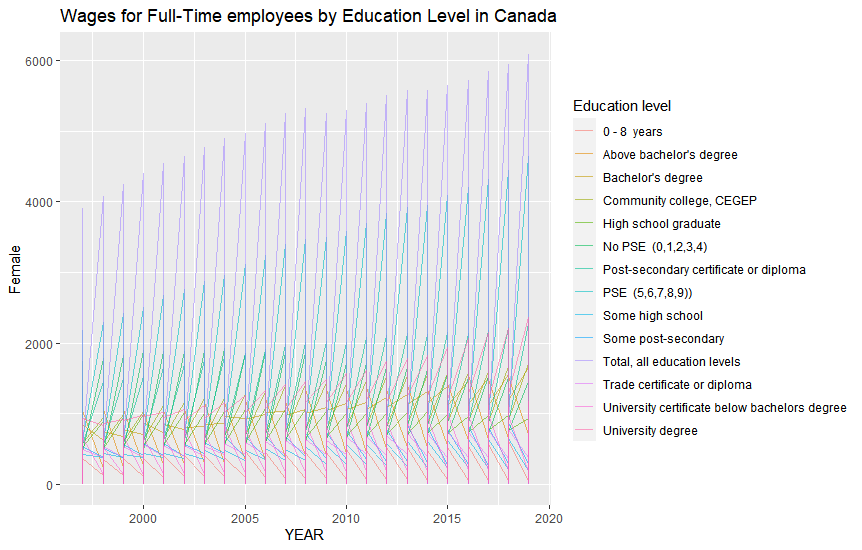 每年都有多行“教育水平”,因此需要某種摘要和/或進一步分組,例如:
每年都有多行“教育水平”,因此需要某種摘要和/或進一步分組,例如:
wages %>%
filter(Geography == 'Canada' & `Type of work` == 'Full-time') %>%
group_by(YEAR, `Education level`, `Age group`) %>%
summarise(`Both Sexes`= sum(`Both Sexes`, na.rm = TRUE)) %>%
ggplot(aes(x = YEAR, y = `Both Sexes`, group = `Education level`, colour = `Education level`))
geom_line()
facet_wrap(~`Age group`)
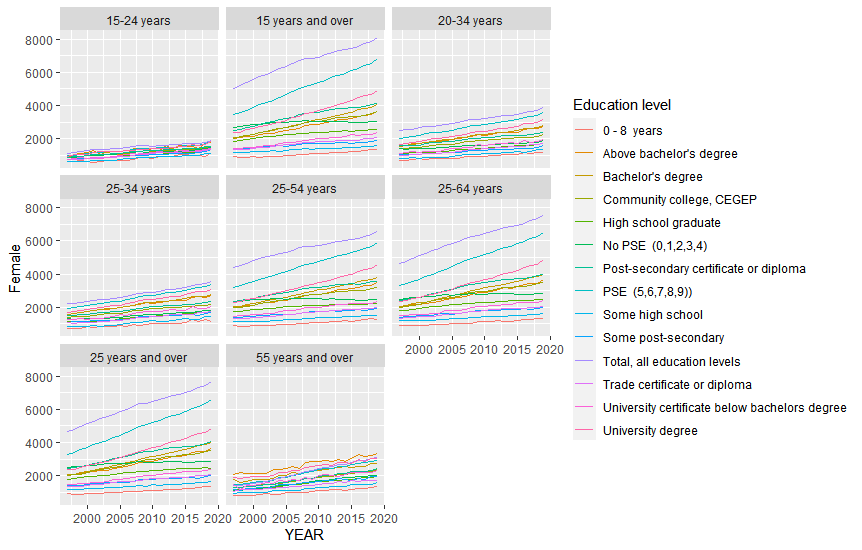
uj5u.com熱心網友回復:
我想你正在尋找這個:
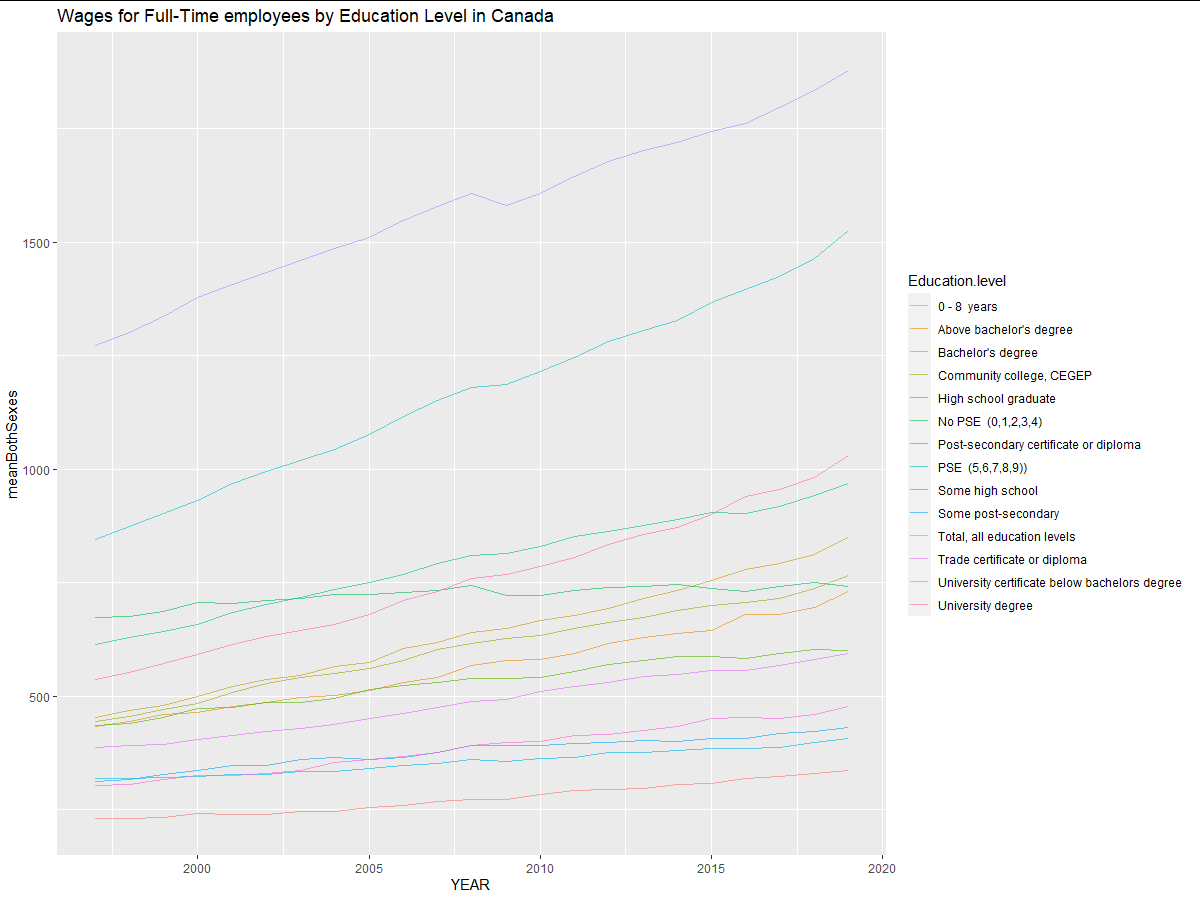
有一些事情需要考慮:
- 在原始資料集中有空格,例如
Type.of.work或Education.level用于str_trim洗掉。(這可能是第一個空白情節的原因! - 您的曲線呈鋸齒狀的原因是例如
YEAR在Both.sexes. 因此,例如 1997 年,您有多個值。我建議先求平均值,然后再作圖。
library(tidyverse)
df %>%
select(YEAR, Both.Sexes, Geography, Type.of.work, Education.level) %>%
as_tibble() %>%
filter(Geography == "Canada" & str_trim(Type.of.work) =="Full-time") %>%
mutate(Education.level = str_trim(Education.level)) %>%
group_by(YEAR, Education.level) %>%
summarise(meanBothSexes = mean(Both.Sexes, na.rm=TRUE)) %>%
ggplot( aes(x=YEAR, y=meanBothSexes, group= Education.level, color=Education.level))
geom_line(alpha=0.6 , size=.5)
labs(title = "Wages for Full-Time employees by Education Level in Canada")
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/368517.html
標籤:r
上一篇:將列的類寫入和讀取到csv