我想轉換在 Sheet1 中收集的資料,使其看起來像 Sheet2。
Sheet1 - 從 Google 表單填充的資料。
此表包含哪些員工參加了特定課程的出勤率。
該作業表包含超過 50,000 行。
每行的類 ID 都是唯一的。
可以在多行中找到相同的員工 ID
- 注意 Employee ID "123456" 在類 X123456 和 ZZ974547 中找到
| 一種 | 乙 | C | |
|---|---|---|---|
| 1 | 日期 | 班級號 | 員工 ID |
| 2 | 2021/4/26 6:47:13 | X123456 | 123456 896779 835906 TMP880997 908613 882853 |
| 3 | 2021/4/26 17:18:57 | Y123456 | 227583 233482 218680 226955 225310 227569 227582 |
| 4 | 2021/4/26 18:01:30 | XYZ123456 | 201032 232863 232848 TMP232845 |
| 5 | 2021/4/27 12:24:29 | X123457 | 188809 224046 232861 232846 |
| 6 | 2021/4/28 10:56:28 | X123458 | 210975 |
| 7 | 2021/5/26 10:29:31 | ZZ974547 | 123456 955725 961714 956114 955986 959287 955748 |
Sheet2 - 使用公式的預期結果
- 結果按時間戳排序。
- 計算類 ID 中員工 ID 的數量。
- 然后將類 ID 復制相同的次數。
- 類 ID X123456 包含 6 個員工 ID,因此 X123456 重復 6 次(1/行)
- 類 ID Y123456 包含 7 個員工 ID,因此 Y123456 重復 7 次(1/行)
| 一種 | 乙 | |
|---|---|---|
| 1 | 班級號 | 員工ID |
| 2 | X123456 | 123456 |
| 3 | X123456 | 896779 |
| 4 | X123456 | 835906 |
| 5 | X123456 | TMP880997 |
| 6 | X123456 | 908613 |
| 7 | X123456 | 882853 |
| 8 | Y123456 | 227583 |
| 9 | Y123456 | 233482 |
| 10 | Y123456 | 218680 |
| 11 | Y123456 | 226955 |
| 12 | Y123456 | 225310 |
| 13 | Y123456 | 227569 |
| 14 | Y123456 | 227582 |
| 15 | XYZ123456 | 201032 |
| 16 | XYZ123456 | 232863 |
| 17 | XYZ123456 | 232848 |
| 18 | XYZ123456 | TMP232845 |
這是我嘗試過的當前公式...
Sheet2!A2 =TRANSPOSE(SPLIT(REPT(B2:B &" ",COUNTA(TRANSPOSE(SPLIT(C2:C," "))))," "))
Sheet2!B2 =TRANSPOSE(SPLIT(C2:C," "))
這些公式適用于第一個類 ID,但不適用于剩余的類 ID。我試著用它們包裹,ARRAYFORMULA()但沒有用。
uj5u.com熱心網友回復:
嘗試:
=INDEX(QUERY(SPLIT(FLATTEN(IF(IFERROR(SPLIT(D2:D, " "))="",,
C2:C&"×"&SPLIT(D2:D, " "))), "×"), "where Col2 is not null"))
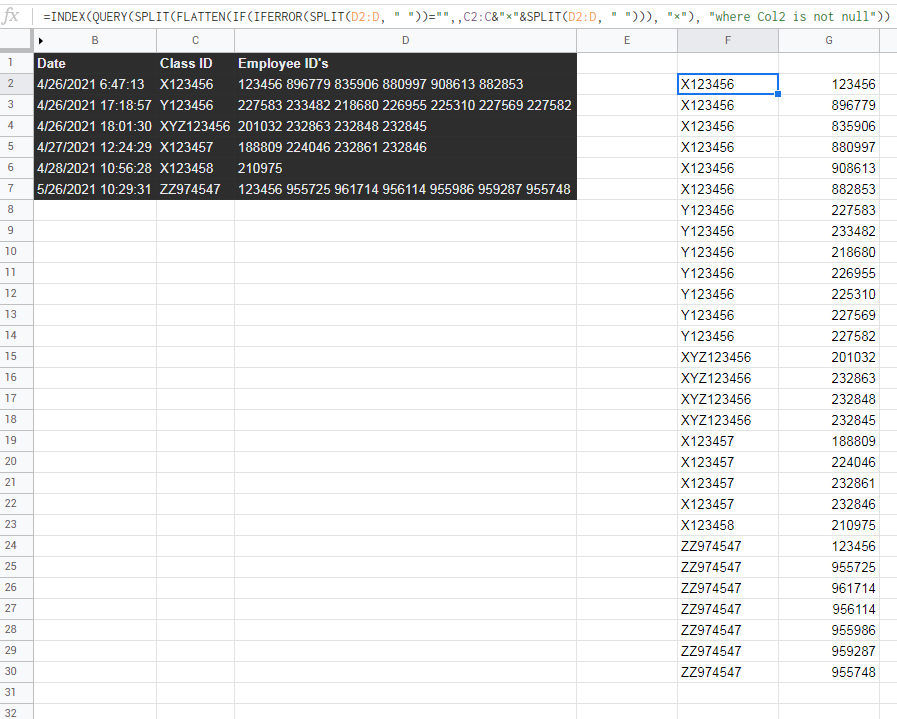
更新:
=INDEX(SUBSTITUTE(QUERY(SPLIT(FLATTEN(IF(IFERROR(
SPLIT(D2:D, " "))="",,C2:C&"×"&SPLIT(D2:D, " ")&"?")), "×"),
"where Col2 is not null"), "?", ))
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/369313.html