作者:jikecheng,miaoxie,HarmonyOS內核技術專家
HarmonyOS整體框架分為四個層級,如圖1所示,從上到下,依次為:第一層是應用層,主要涵蓋系統應用、Launcher、設定,以及三方應用,第二層是框架層,提供基礎UI框架、用戶程式框架以及能力模塊框架,第三層是系統服務層,讓HarmonyOS具有分布式流轉負載的能力,大家看到的高速多設備協同能力就是由該層級提供,
而承載整個作業系統,同時發揮芯片算力的基石就沉淀在第四層——內核層,宏觀來說,內核的主要作業包含芯片資源管理、軟體任務調度,以及銜接用戶空間與系統呼叫能力,
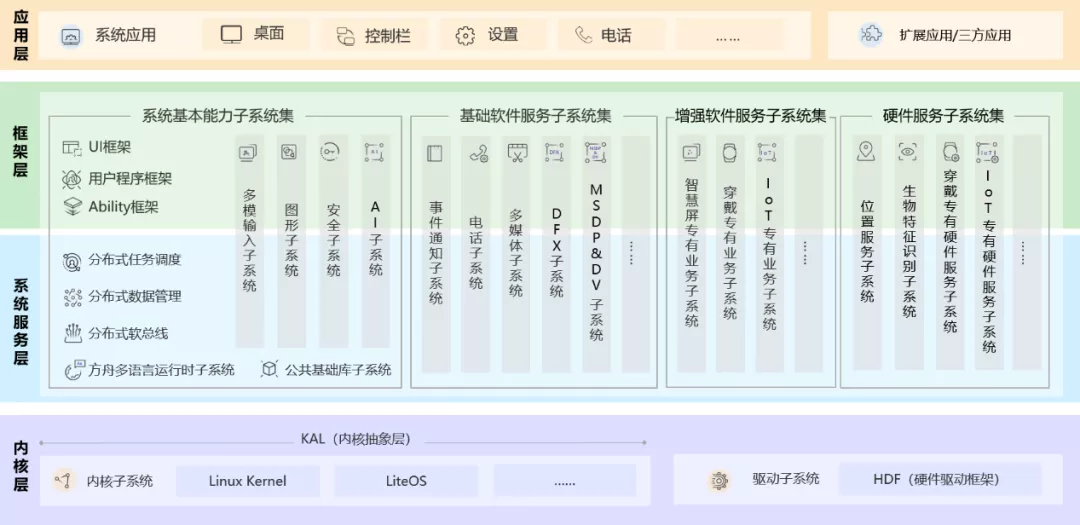
?圖1 HarmonyOS整體框架
本期,我們要重點給大家講一講HarmonyOS的內核層,
一、HarmonyOS內核構成
為了支撐HarmonyOS在多設備、多場景下的性能表現,內核主要由三部分組成,如下圖所示:
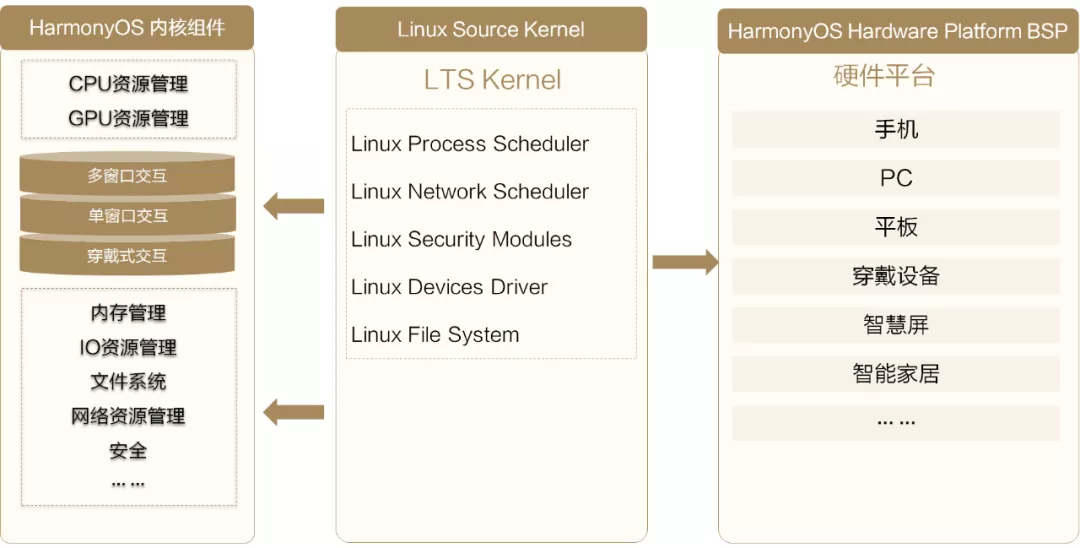
圖2 內核的組成
- HarmonyOS內核組件:具有智慧化資源管理能力的內核組件,包括CPU/GPU資源管理,記憶體管理,IO調度管理以及高效的檔案系統等,
- 標準的Linux內核:兼容了LTS Linux主線版本,做好外圍生態的對接,
- 硬體平臺BSP:面向各種不同芯片與硬體平臺(包含1+8+N的多種設備)的BSP(board support package,板級支撐包)基礎能力,
本期要為大家介紹的就是HarmonyOS內核組件的三項核心技術:高能效CPU資源調度、Hyperhold記憶體管理引擎和高效的檔案系統,下面為大家一一揭曉~
二、高能效CPU資源調度
業界多數的作業系統都是基于標準的Linux內核開發的,傳統的Linux內核,早期用于服務器和PC設備,與我們現在用于手機、平板等的互動式內核相比,它們的設計理念和資源管理方式有所不同,以CPU資源為例,傳統的Linux內核存在以下典型問題:
1. 同優先級的業務過多,每次調度都不一定選擇到關鍵行程,
傳統的Linux內核偏向于在多用戶的場景下公平地分配資源,比較明顯的特征是,多個用戶并發訪問,并發使用公共資源,由于同優先級的業務比較多,每次任務調度不一定能夠選擇到關鍵行程,舉個例子,當設備后臺存在多個應用或者服務任務時,系統中和用戶互動最敏感的渲染任務沒法即時得到調度資源,導致設備會高概率出現使用不流暢或者點擊無回應的現象,也就是咱們平時常說的隨機卡頓,
2. 選擇最優能效的CPU資源時間過長,CPU資源選擇過度,
傳統的Linux內核選擇算力的流程,是一個慢速爬坡的程序,任務調度必須經過選擇CPU核簇、負載均衡、選擇頻點等一系列流程,其漫長的程序,極易導致任務調度錯過調度視窗,出現算力供給不足的現象,
為了解決以上問題,HarmonyOS內核提供了全堆疊式的調度框架,如下圖所示:
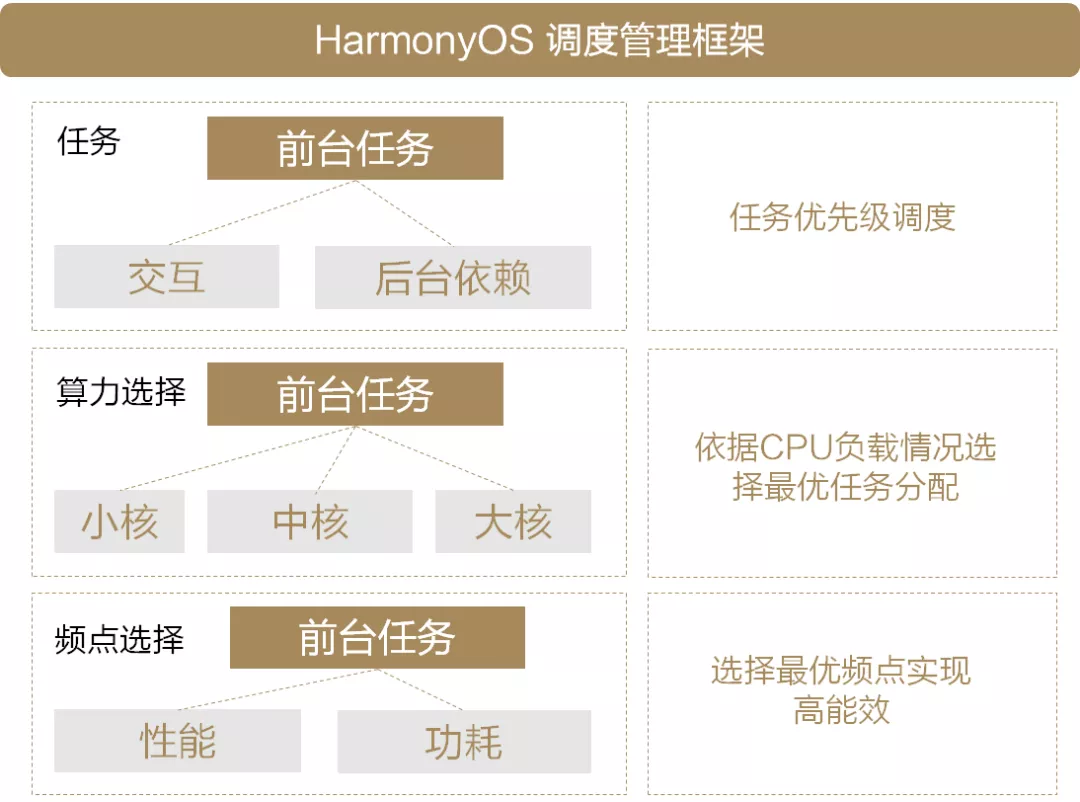
圖3 HarmonyOS調度管理框架
HarmonyOS調度管理框架有以下特點:
● 任務按優先級調度
對現有系統任務進行嚴格級別劃分,在線標記與用戶的操作體驗直接相關的關鍵行程和關聯任務,優先調度關鍵任務,
● 依據CPU負載情況選擇最優任務分配
我們會動態檢測不同CPU的負載,保證當前CPU有足夠的算力提供,
● 選擇最優頻點實作高能效
我們提供了頻點與性能、功耗之間的帕累托最優模型,每次任務,我們都能夠快速選擇系統最優的頻點組合方式,實作最優能效,
經過試驗,HarmonyOS的全堆疊式調度框架可以幫助用戶獲得在多場景(尤其是游戲場景)下持續且穩定的高幀率體驗,
三、Hyperhold記憶體管理引擎
對于記憶體管理,由于開源生態的不限制,導致應用開發的記憶體使用野蠻生長,設備長時間使用后,可回收記憶體越來越低,產生這個問題的原因有兩個:
1. 傳統記憶體資料冷熱管理,無法感知業務特性
盡管Linux內核提供了很多的記憶體回識訓制,然而每種記憶體回收都會有相應的系統代價,比如,回收檔案頁面后,如果系統需要二次加載這部分資料,需要從底層器件Flash里面把資料讀回來,這會引起Flash隨機IO讀的現象,對IO操作來說,Flash器件速度和當前讀取任務是隨機讀還是順序讀有著很強的相關性,隨機讀容易導致系統隨機卡頓,再比如,回收匿名頁面后,如果系統需要二次加載這部分資料,會觸發ZRAM解壓,消耗CPU,
另外,由于應用的記憶體負載越來越重,當系統冷熱資料識別不恰當,會導致系統的CPU負載長期處于高負載狀態,最終影響前臺應用的基礎性能,
2. 傳統共享式記憶體分配,無法感知資料重要性
從記憶體分配角度看,現在的作業系統基本采用統一介面的分配方式,使得手機里面多個行程或多個業務會共用一塊記憶體區域,資料回收時,會頻繁出現資料搬移,以及記憶體震蕩的現象,這個現象會加重內核管理記憶體的開銷,
為了解決傳統Linux內核的記憶體問題,HarmonyOS提供了Hyperhold記憶體管理引擎,Hyperhold記憶體管理引擎打通了上層系統到內核的呼叫堆疊,讓內核完整感知到應用的整個生命周期,并結合應用生命周期以及周期內的資料訪問特征,對每一塊記憶體資料做合理的記憶體管理,同時,為了降低內核管理記憶體的開銷,我們提出了自研的壓縮體系,包括多執行緒壓縮、自研的壓縮演算法,為了進一步擴大可用空間,我們在Flash器件上開出了一塊可交換區,結合自研的聚合換出和記憶體標記技術,充分利用Flash器件的性能,

圖4 Hyperhold記憶體管理引擎
經過試驗, Hyperhold記憶體管理引擎可以讓應用在后臺的駐留能力提升50%以上,用戶可以明顯感知到后臺應用的保活率有大幅提升,
四、高效的檔案系統
存盤處于整個快取體系下的最慢路徑,容易成為系統性能瓶頸,不僅如此,由于存盤器件碎片化的問題,存盤還容易出現越用越慢的難題,其次,隨著系統的發展,系統占用存盤越來越多,而在多設備流轉的場景下,分布式檔案系統的高效轉存能力顯得尤為重要,
為應對上述問題,HarmonyOS提供了高效的自研檔案系統體系,從第一代的eF2FS到最新的HMDFS,檔案系統逐步解決了碎片化問題、容量問題與多設備流轉問題,

圖5 HarmonyOS檔案系統
下面我們從第一代的eF2FS到最新的HMDFS,依次介紹HarmonyOS檔案系統的技術特點,
1. 第1代資料盤eF2FS:智能感知空間管理,改善越用越慢
面對存盤越用越慢的業界難題,我們通過資料型別感知的多流演算法和空間感知的分配演算法,減少碎片產生,同時,通過高效、業務感知的兩層智能垃圾空間回收,實作智能感知空間管理,
下面我們通過一個動圖,更好地了解HarmonyOS的空間管理機制,

2. 系統盤EROFS:變長壓縮,支持壓縮與性能雙贏
針對系統占用存盤越來越多的問題,業界其他作業系統也采取過改進措施,比如squashfs采用“定長輸入,變長輸出”的壓縮策略,但會存在讀放大的問題,而我們的EROFS(Extendable Read-Only File System,超級檔案系統)采用“變長輸入,定長輸出”的壓縮策略,盡可能地將不等長的檔案塊壓縮成一個等長的存盤塊進行存盤,這樣,我們訪問任何檔案塊,只需讀取一個存盤塊,減少了無效讀取,除此之外,我們在解壓性能和IO流程上也做了優化,
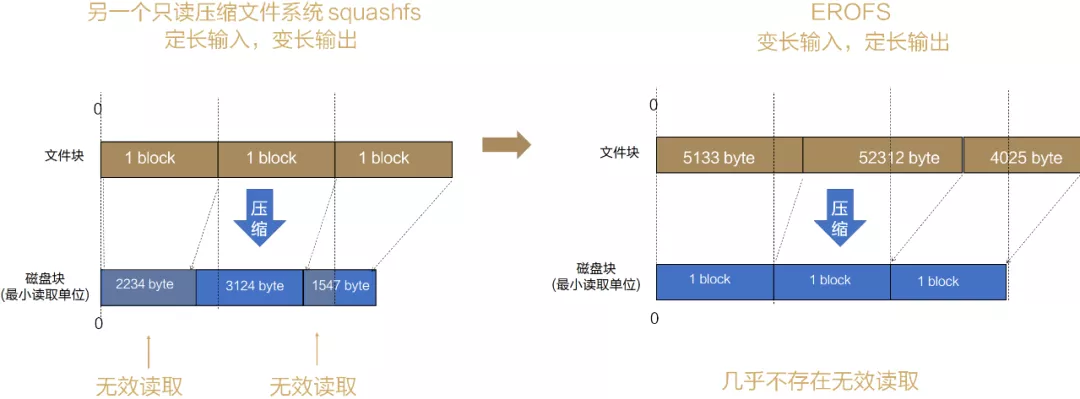
圖6 系統盤EROFS的變長壓縮
通過以上關鍵技術,系統盤EROFS的性能得到大幅提升:
- 隨機讀性能平均提升20%,
- 系統初始空間相比Ext4節省2GB,相當于用戶可以多存1000張照片或500首歌曲,
- 升級包大小下降約5%-10%,升級時間縮短約20%,
3. 跨設備HMDFS:“批流”結合的分布式檔案系統
HarmonyOS同一套系統能力、適配多種終端形態的分布式理念,就要求我們有一套資料流轉的底座——分布式檔案系統HMDFS,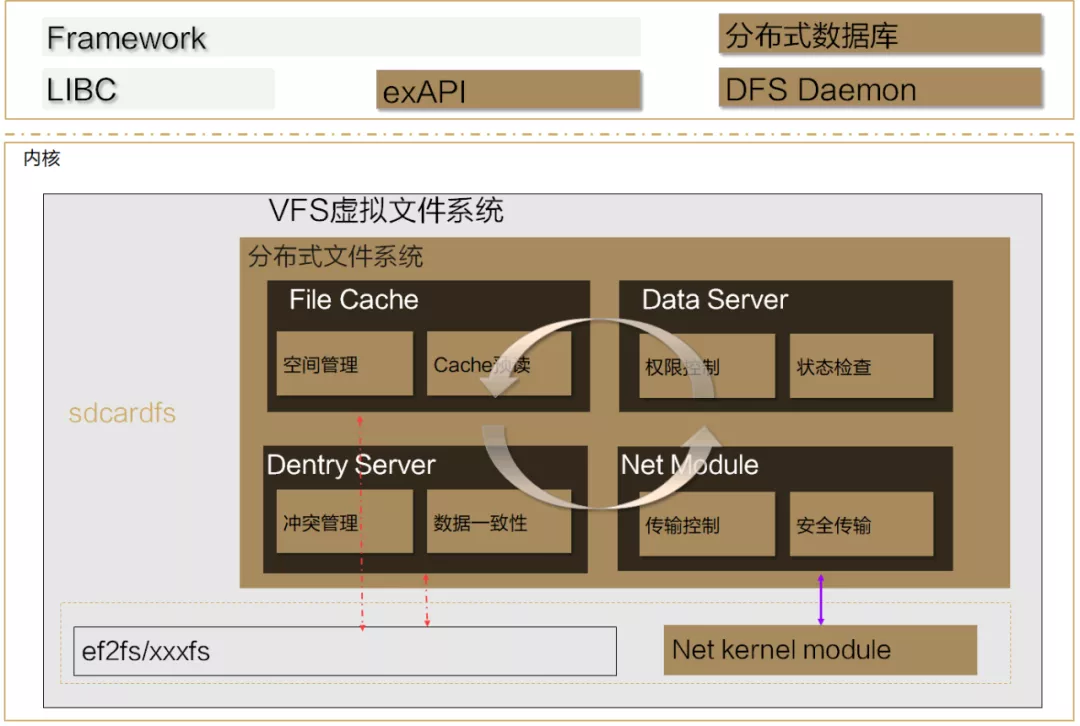
圖7 HMDFS
應對多設備流轉,HMDFS提供了多種檔案系統能力,包括:
- 檔案型別聚合
- 高效的快取管理
- 批處理介面
- 分布式的權限管控
- 高效傳輸
- 資料一致性管理
通過上述一系列技術的研發與集成,最終實作了現有的跨設備高效檔案系統,為用戶提供流暢的分布式體驗,
五、未來演進方向
上面就是我們本期要介紹的HarmonyOS內核核心技術內容了,未來還有很多方向值得我們繼續探索,下圖列出了HarmonyOS內核的未來演進方向,

圖8 未來演進方向
相信經過我們不斷的探索,我們能打造出更好的內核,為大家提供更流暢、體驗更好的HarmonyOS!

掃碼添加開發者小助手微信
獲取更多HarmonyOS開發資源和開發者活動資訊
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/374502.html
標籤:其他