這1個月有點忙,面試了10多個小廠和2、3個大廠,給我的感覺就是基礎不牢,地動山搖,一般的面試的邏輯就是面向簡歷,深挖細節,位元組的一面問了我一個半小時,反思一下,真的基礎非常的重要,一些中小廠可能會額外提到行業看法面、個人世界觀面等,本文主要還是針對專業技術面更多,
話不多說,基于我現在被問到的一些情況,也查看了全網諸多的面試題,我總結了一些在Android面中的Java題,
由于本人見識非常有限,寫的博客難免有錯誤或者疏忽的地方,希望各位人才們指點一二,
努力不辜,時光不負,繼續沖沖沖!
一、Java概述
1.JVM、JRE和JDK的關系
- JVM:Java虛擬機,Java程式需要運行在虛擬機
- JRE:Java虛擬機+Java程式所需的核心類別庫
- JDK:Java虛擬機+Java程式所需的核心類別庫(JRE)+Java開發工具包
2.談談你對類生命周期的認識?
jvm(java虛擬機)中的幾個比較重要的記憶體區域,這幾個區域在java類的生命周
期中扮演著比較重要的角色:
- 方法區: 在java的虛擬機中有一塊專門用來存放已經加載的類資訊、常量、靜態變數以及方法代碼的記憶體區域,叫做方法區,
- 常量池: 常量池是方法區的一部分,主要用來存放常量和類中的符號參考等資訊,
- 堆區: 用于存放類的物件實體,
- 堆疊區: 也叫java虛擬機堆疊,是由一個一個的堆疊幀組成的后進先出的堆疊式結構,堆疊楨中存放方法運行時產生的區域變數、方法出口等資訊,當呼叫一個方法時,虛擬機堆疊中就會創建一個堆疊幀存放這些資料,當方法呼叫完成時,堆疊幀消失,如果方法中呼叫了其他方法,則繼續在堆疊頂創建新的堆疊楨,
我們撰寫一個java的源檔案后,經過編譯會生成一個后綴名為class的檔案,這種檔案叫做位元組碼檔案,只有這種位元組碼檔案才能夠在java虛擬機中運行,java類的生命周期就是指一個class檔案從加載到卸載的全程序,一個java類的完整的生命周期會經歷加載、連接、初始化、使用、和卸載五個階段
3.談談你對面向物件和面向程序的理解
面向程序:分析出解決問題所需要的步驟,然后用函式把這些步驟一步一步實作
面向物件:把構成問題事務分解成各個物件,然后描述物件的行為
舉個例子:下五子棋:
- 面向程序的設計思路:1、開始游戲,2、黑子先走,3、繪制畫面,4、判斷輸贏,5、輪到白子,6、繪制畫面,7、判斷輸贏,8、回傳步驟2,9、輸出最后結果,
- 面向物件的設計思路:1、黑白雙方,這兩方的行為是一模一樣的,2、棋盤系統,負責繪制畫面,3、規則系統,負責判定諸如犯規、輸贏等,第一類物件(玩家物件)負責接受用戶輸入,并告知第二類物件(棋盤物件)棋子布局的變化,棋盤物件接收到了棋子的變化就要負責在螢屏上面顯示出這種變化,同時利用第三類物件(規則系統)來對棋局進行判定
4.面向程序和面向物件的優缺點
面向程序:
- 優點:性能比面向物件高,因為類呼叫時需要實體化,開銷比較大,比較消耗資源;比如單片機、嵌入式開發、Linux/Unix等一般采用面向程序開發,性能是最重要的因素,
- 缺點:沒有面向物件易維護、易復用、易擴展
面向物件:
- 優點:性能比面向物件高,因為類呼叫時需要實體化,開銷比較大,比較消耗資源;比如單片機、嵌入式開發、Linux/Unix等一般采用面向程序開發,性能是最重要的因素,
- 缺點:沒有面向物件易維護、易復用、易擴展
舉個例子:
面向程序的程式是一份蛋炒飯,面向物件的程式是一份蓋澆飯,
蛋炒飯的好處就是入味均勻,吃起來香,如果恰巧你不愛吃雞蛋,只愛吃青菜的話,那么唯一的辦法就是重新做一份青菜炒飯了,蓋澆飯更換一份蓋菜就可以了,蓋澆飯的缺點是入味不均,可能沒有蛋炒飯那么香,
到底是蛋炒飯好還是蓋澆飯好呢?其實這類問題都很難回答,非要比個上下高低的話,就必須設定一個場景,否則只能說是各有所長,如果大家都不是美食家,沒那么多講究,那么從飯館角度來講的話,做蓋澆飯顯然比蛋炒飯更有優勢,他可以組合出來任意多的組合,而且不會浪費,
蓋澆飯的好處就是"菜"“飯"分離,從而提高了制作蓋澆飯的靈活性,飯不滿意就換飯,菜不滿意換菜,用軟體工程的專業術語就是"可維護性"比較好,“飯” 和"菜"的耦合度比較低,蛋炒飯將"蛋”“飯"攪和在一起,想換"蛋”"飯"中任何一種都很困難,耦合度很高,以至于"可維護性"比較差,軟體工程追求的目標之一就是可維護性,可維護性主要表現在3個方面:可理解性、可測驗性和可修改性,面向物件的好處之一就是顯著的改善了軟體系統的可維護性,
5.Java和C++的區別
- 都是面向物件的語言,都支持封裝、繼承和多型
- Java不提供指標來直接訪問記憶體,程式記憶體更加安全
- Java的類是單繼承的,介面可以多繼承,C++支持多重繼承
- Java有自動記憶體管理機制,不需要程式員手動釋放無用記憶體
- Java可跨平臺運行,C++要關注平臺差異性
二、基礎語法
6.&和&&的區別
| 運算子 | 功能描述 | 說明 |
|---|---|---|
| && | 短路與 | 都為true才為true,從左到右依次判斷,節省計算機資源提高邏輯運算的速度 |
| & | 無條件與 | 全部都要判斷 |
|| | 短路或 | 全為false才為false,從左到右依次判斷,節省計算機資源提高邏輯運算的速度 |
| | 無條件或 | 全部都要判斷 |
7. "= =“和equals方法究竟有什么區別?
== 對基本型別和參考型別作用效果是不同的,如下所示:
- 基本型別:比較的是值是否相同;
- 參考型別:比較的是參考是否相同;
equals 默認情況下是參考比較,只是很多類重新了 equals 方法,比如 String、Integer 等把它變成了值比較,所以一般情況下 equals 比較的是值是否相等
8.關鍵字final和static是怎么使用的?
static關鍵字主要有兩種作用:
- 第一,為某特定資料型別或物件分配單一的存盤空間,而與創建物件的個數無關,
- 第二,實作某個方法或屬性與類而不是物件關聯在一起
static修飾方法/變數:static方法一般稱作靜態方法,由于靜態方法不依賴于任何物件就可以進行訪問,因此對于靜態方法來說,是沒有this的;根據Java中定義變數位置的不同,變數有兩大類:成員變數和區域變數,而成員變數里面根據有無static修飾又可分為類變數和實體變數
- 靜態方法中不能直接訪問非靜態成員方法和非靜態成員變數,非靜態成員方法可直接可以訪問所有成員方法/成員變數
- 同類可直接呼叫靜態方法/類變數,不同類則是類.靜態方法/類變數
- 同類非靜態方法呼叫非靜態方法/實體變數時,可直接呼叫方法名()/實體變數名;其它情況下呼叫非靜態方法均要實體化物件通過物件呼叫非靜態方法,類名 物件名 = new 類名(); 物件名.靜態方法名()/實體變數名;
- 靜態方法中,不能使用this關鍵字, this是相對于某個物件而言的,static修飾的方法是相對于類的,因此不能在靜態方法中用this
static修飾類:
- 實體內部類:直接定義在類當中的一個類,在類前面沒有任何一個修飾符,
- 靜態內部類:在內部類前面加上一個static,
- 區域內部類:定義在方法當中的內部類,區域類當中不能使用static變數,不能使用 public、protected、private 修飾,
- 匿名內部類:屬于區域的一種特殊情況,
final修飾方法/變數/類
- final有不可改變,最終的意思,可以用來修飾非抽象類、成員方法和變數
- 修飾類:該類不能再派生出新的子類,不能作為父類被繼承,因此,一個類不能同時被宣告為abstract 和 final,抽象類要被參考,所以不能用final修飾
- 修飾方法:該方法不能被子類重寫,
- 修飾變數:該變數必須在宣告時給定初值,而在以后只能讀取,不可修改, 如果變數是物件,則指的是參考不可修改,但是物件的屬性還是可以修改的,
9.switch陳述句后的控制運算式
- JDK1.0 - 1.4? ? 資料型別接受 byte short int char
- JDK1.5 ? ? 資料型別接受 byte short int char enum(列舉)
- JDK1.7? ? 資料型別接受 byte short int char enum(列舉), String,對應的包裝型別
10.成員變數和區域變數的區別
| 不同點 | 區域變數 | 成員變數 |
|---|---|---|
| 定義位置 | 方法內部 | 方法外部 |
| 作用范圍 | 方法當中 | 整個類 |
| 默認值 | 手動賦值 | 有默認值 |
| 記憶體位置 | 堆疊記憶體 | 堆記憶體 |
| 生命周期 | 方法進堆疊而誕生,方法出堆疊而消失 | 物件創建而誕生,物件被垃圾回收而消失 |
11.lamda運算式了解過?
Lambda的前提條件
- Lambda只能用于替換有且僅有一個抽象方法的介面和匿名內部類物件,這種介面稱為函式式介面
- Lambda具有背景關系推斷的功能,所以我們才會出現Lambda的省略格式
Lambda的使用場景
- 串列迭代:輸出串列的每個元素
- 事件監聽
- Predicate 介面
- Map 映射
- Reduce 聚合:對多個物件進行過濾并執行相同的處理邏輯
- 代替 Runnable:創建執行緒
12.正則運算式掌握過嗎,在專案里面怎么用到的
正則運算式是一種用來匹配字串的強有力的武器,用一種描述性的語言定義一個規則,凡是符合規則的字串,我們就認為它“匹配”了
使用場景:
- 資料有效性驗證:用戶注冊模塊是應用正則運算式最集中的地方,主要是用于驗證用戶帳號、密碼、EMAIL、電話號碼、QQ號碼、身份證號碼、家庭地址等資訊,如果填寫的內容與正則運算式不匹配,可以斷定填寫的內容是不合乎要求或虛假的資訊;
- 模糊查詢,批量替換:可以在檔案中使用一個正則運算式來查找匹配的特定文字,然后可以全部將其洗掉,或者替換為別的文字,
Android中正則運算式的用法:
- 核心類:
? ?Pattern:正則運算式的編譯后的物件形式,即正則模式: 將一個字串轉成正則匹配模式物件
? ?Matcher是正則模式匹配給定字串的匹配器,Pattern物件呼叫匹配器matcher()方法,查找符合匹配要求的匹配項
13.什么是拆箱 & 裝箱,能給我舉例子嗎?
拆箱:包裝型別轉換為基本型別
裝箱:基本型別轉換為包裝型別
Integer i1 = 40;Integer i2= 40;進行比較時,基本型別int被裝箱為包裝型別Integer,在Java中,基本型別比較的是值,而封裝型別比較的是物件的地址,但是這兩個包裝類物件是同一個物件,因為Integer類,里面涉及到快取機制,如果給定的基本型別int值在-128到127之間的話,就會直接去cache陣列里取,如果不在這個范圍的話,那么就會創新的物件,
`平常我們在Java中使用的都是HashMap等來保存資料,但是有一個嚴重的問題就是HashMap里的key以及value都是泛型,那么就會不可避免的遇到裝箱和拆箱的程序,而這個程序是很耗時的,所以為了規避裝箱拆箱提高效率,于是誕生了SparseArray等集合類,但是SparceArray效率高也是有條件的,它適用于資料量比較小的場景,而在Android開發中,大部分場景都是資料量比較小的,在資料很大的情況下,當然還是hashmap效率較優,
三、實用類別庫
14.日期時間了解?談談做過那些業務?
切換時間格式,增加不同國家時設定功能,用到了TextClock、Calendar、SimpleDateFormat、AlarmManager類,
TextClock中setFormat24Hour方法設定24小時制度/12小時制
Calendar與SimpleDateFormat類,設定當前時間以及當前時間顯示的格式
AlarmManager中:setTimeZone(String timeZone)方法用來設定系統的默認時區,需要android.permission.SET_TIME_ZONE.權限:mAlarmManager = (AlarmManager) getContext().getSystemService(Context.ALARM_SERVICE);
15.字串的更改
當切換系統語言時,參考到一些的string的寫法會有不同,一般有以下三種方式選擇:
.字串的反轉
- charAt():通過String類的charAt()的方法來獲取字串中的每一個字符,然后將其拼接為一個新的字串
- toCharArray():通過String的toCharArray()方法可以獲得字串中的每一個字符并轉換為字符陣列,然后用一個空的字串從后向前一個個的拼接成新的字串,
- reverse():通過StringBuiler或StringBuffer的reverse()的方法
字串替換
- replace():替換字串中所有指定的字符,然后生成一個新的字串,原來的字串不發生改變
- replaceAll():字串中某個指定的字串替換為其它字串
replaceFirst():替換第一個出現的指定字串
ArrayMap的key-value改變字串
保證key值相同,選擇不同系統語言時,改變value值:
if(true){
arrayMap.put(“A”, “GB”);
}else {
arrayMap.put(“A”, “GA”);
16.String、StringBuilder、StringBuffrer的區別
- String類是不可變類,任何對String的改變都會引發新的String物件的生成;
- StringBuffer是可變類,任何對它所指代的字串的改變都不會產生新的物件,執行緒安全的,
- StringBuilder是可變類,線性不安全的,不支持并發操作,不適合多執行緒中使用,但其在單執行緒中的性能比StringBuffer高,
四、繼承
17.談一談對值傳遞和參考傳遞的理解
參考型別傳遞是堆疊地址的傳遞,操作任何一個參考變數都會影響到在堆記憶體中實際物件的值
簡單型別傳遞是具體值傳遞,如果在被傳遞函式中改變了這個傳進來的值,不會改變原始的值
18.super 和 this 的異同
指代上的區別
- super:是對當前物件中父物件的參考,
- This:指當前物件的參考,
參考物件上的區別
- super:直接父類中參考當前物件的成員(當基本成員和派生類具有相同成員時,用于訪問直接父類中隱藏父類中的成員資料或函式定義),
- This:表示當前物件的名稱(程式中容易出現歧義的地方,應該用來表示當前物件;如果函式的成員資料與該類中成員資料的名稱相同,應用于表示成員變數名稱),
呼叫函式上的區別
- super:在基類中呼叫建構式(是建構式中的第一條陳述句),
- This:在此類中呼叫另一個結構化的建構式(是建構式中的第一條陳述句),
五、多型
19.多載(Overload)和重寫(Override)的區別
方法的多載和重寫都是實作多型的方式,區別在于前者實作的是編譯時的多型性,而后者實作的是運行時的多型性,
多載:一個類中有多個同名的方法,但是具有有不同的引數串列(引數型別不同、引數個數不同或者二者都不同),
重寫:發生在子類與父類之間,子類對父類的方法進行重寫,引數都不能改變,回傳值型別可以不相同,但是必須是父類回傳值的派生類,即外殼不變,核心重寫!重寫的好處在于子類可以根據需要,定義特定于自己的行為,
| 重寫 | 多載 | |
|---|---|---|
| 是否同類 | 不能同類 | 可同類也可不同類 |
| 方法名的引數形式是否相同 | 必須相同 | 必須不同 |
| 回傳型別 | 必須相同 | 可同可不同 |
| 訪問修飾符 | 子類不能比父類權限小 | 無要求 |
| 方法體例外 | 不能拋出新的例外或例外不能范圍變大 | 無要求 |
| 構造方法 | 不能被重寫 | 可以被多載 |
| 多型實作方式 | 實作運行時多型 | 實作編譯時多型 |
20. 介面與抽象類的異同
相似點
- 兩者都可包含抽象方法,實作抽象類和介面的非抽象類必須實作這些抽象方法
- 兩者都不能用來實體化物件,可以宣告抽象類和介面的變數,對抽象類來說,要用抽象類的非抽象子類來實體化該變數;對介面來說,要用實作介面的非抽象子類來實體化該變數
- 兩者的子類如果都沒有實作抽象類(介面)中宣告的所有抽象方法,則該子類就是抽象類
- 兩者都可以實作程式的多型性
不同點
- 一個類只能繼承一個直接父類,但是可以實作多個介面
- 抽象類的子類使用 extends 來繼承;介面必須使用 implements 來實作介面,
- 抽象類可以有建構式;介面不能有,
- 抽象類可以有 main 方法,并且我們能運行它;介面不能有 main 方法,
- 介面中的方法默認使用 public 修飾;抽象類中的方法可以是任意訪問修飾符,
- 抽象類不能在Java 8 的 lambda 運算式中使用
- 介面體現的是一種規范(列印機和相機都有列印的功能),與實作介面的子類中不存在父與子的關系;抽象類與其子類存在父與子的關系(圓形和方形都是一種形狀)
六、 例外處理
21. Exception與Error的區別,RuntimeException
Error(錯誤):通常是災難性的致命錯誤,不是程式(程式猿)可以控制的,如記憶體耗盡、JVM系統錯誤、堆疊溢位等,應用程式不應該去處理此類錯誤,且程式員不應該實作任何Error類的子類,
Exception(例外):用戶可能捕獲的例外情況,可以使用針對性的代碼進行處理,如:空指標例外、網路連接中斷、陣列下標越界等,
RuntimeException類及其子類稱為非檢查型例外,Java編譯器會自動按照例外產生的原因引發相應型別的例外,程式中可以選擇捕獲處理也可以不處理,雖然Java編譯器不會檢查運行時例外,但是也可以去進行捕獲和拋出處理,RuntimeException類和子類以及Error類都是非受檢例外,
22.幾種例外型別
Java 的所有例外可以分為受檢例外(checked exception)和非受檢例外(unchecked exception),
受檢例外
編譯器要求必須處理的例外,Exception 中除 RuntimeException 及其子類之外的例外都屬于受檢例外,編譯器會檢查此類例外,也就是說當編譯器檢查到應用中的某處可能會此類例外時,將會提示你處理本例外——要么使用try-catch捕獲,要么使用方法簽名中用 throws 關鍵字拋出,否則編譯不通過,
非受檢例外
編譯器不會進行檢查并且不要求必須處理的例外,也就說當程式中出現此類例外時,即使我們沒有try-catch捕獲它,也沒有使用throws拋出該例外,編譯也會正常通過,該類例外包括運行時例外(RuntimeException及其子類)和錯誤(Error),
運行時例外
定義:RuntimeException 類及其子類,
特點:RuntimeException為Java虛擬機在運行時自動生成的例外,如被零除和非法索引、運算元超過陣列范圍、打開檔案不存在等,此類例外的出現絕大數情況是代碼本身有問題應該從邏輯上去解決并改進代碼,
RuntimeException類及其子類稱為非檢查型例外,Java編譯器會自動按照例外產生的原因引發相應型別的例外,程式中可以選擇捕獲處理也可以不處理,雖然Java編譯器不會檢查運行時例外,但是也可以去進行捕獲和拋出處理,RuntimeException類和子類以及Error類都是非受檢例外,
編譯時例外
特點: Exception中除RuntimeException及其子類之外的例外,該例外必須手動在代碼中添加捕獲陳述句來處理該例外,編譯時例外也稱為受檢例外,一般不進行自定義檢查例外,,
23. Java語言如何進行例外處理,關鍵字:throws、throw、try、catch、finally分別如何使用?
try陳述句中存放的是可能發生例外的陳述句,當例外拋出時,例外處理機制負責搜尋引數與例外型別相匹配的第一個處理程式,然后進入catch陳述句中執行,此時認為例外得到了處理,如果程式塊里面的內容很多,前面的代碼拋出了例外,則后面的正常程式將不會執行,系統直接catch捕獲例外并且處理
catch陳述句可以有多個,用來匹配多個例外,捕獲例外的順序與catch陳述句的順序有關,當捕獲到對應的例外物件時,剩下的catch陳述句不再進行匹配,因此在安排catch陳述句的順序時,首先應該捕獲最特殊的例外,然后一般化,catch的型別是Java語言定義的或者程式員自己定義的,表示拋出例外的型別,例外的變數名表示拋出例外的物件的參考,如果catch捕獲并匹配了該例外,那么就可以直接用這個例外變數名來指向所匹配的例外,并且在catch陳述句中直接參考,部分系統生成的例外在Java運行時自動拋出,也可通過throws關鍵字宣告該方法要拋出的例外,然后在方法內拋出例外物件,
final陳述句為例外提供一個統一的出口,一般情況下程式始終都要執行final陳述句,final在程式中可選,final一般是用來關閉已打開的檔案和釋放其他系統資源,try-catch-final可以嵌套,
throws關鍵字和 throw 關鍵字在使用上的幾點區別如下:
- throw 關鍵字用在方法內部,只能用于拋出一種例外,用來拋出方法或代碼塊中的例外,
- throws 關鍵字用在方法宣告上,可以拋出多個例外,用來標識該方法可能拋出的例外串列,呼叫該方法的方法必須包含可處理例外的代碼,否則也要在方法宣告中用 throws 關鍵字宣告相應的例外,
有4種特殊情況,finally塊不會被執行:
- finally陳述句塊中發生了例外
- 前面的代碼中執行了System.exit()退出程式
- 程式中所在的執行緒死亡
- 關閉CPU
24. 關于return和finally的關系
try中有return
無論在什么位置添加return,finally子句都會被執行
catch和try中都有return
當try中拋出例外且catch中有return陳述句,finally中沒有return陳述句,java先執行catch中非return陳述句,再執行finally陳述句,最后執行return陳述句,若try中沒有拋出例外,則程式不會執行catch體里面的陳述句,java先執行try中非return陳述句,再執行finally陳述句,最后再執行try中的return陳述句,
finally 中有return
finally中有return時,會覆寫掉try和catch中的return,
finally中沒有return陳述句,但是改變了回傳值
如果finally中定義的資料是基本資料型別或文本字串,則在finally中對該基本資料的改變不起作用,try中的return陳述句依然會回傳進入finally塊中之前保存的值;如果finally中定義的資料是是參考型別,則finally中的陳述句會起作用,try中return陳述句的值就是在finally中改變后該屬性的值,
七、輸入與輸出流
25.java 中 IO 流分為幾種?
Java IO流共涉及40多個類,這些類看上去很雜亂,但實際上很有規則,而且彼此之間存在非常緊密的聯系, Java IO流的40多個類大部分都是從如下4個抽象類基類中派生出來的,
- InputStream/Reader: 所有的輸入流的基類,前者是位元組輸入流,后者是字符輸入流,
- OutputStream/Writer: 所有輸出流的基類,前者是位元組輸出流,后者是字符輸出流,
- 按照流的流向分,可以分為輸入流和輸出流;
- 按照操作單元劃分,可以分為位元組流和字符流;
- 按照流的角色劃分,可以分為節點流和處理流,
26.BIO,NIO,AIO 有什么區別,如何理解同步和異步,阻塞和非阻塞
同步與異步
- 同步: 同步就是發起一個呼叫后,被呼叫者未處理完請求之前,呼叫不回傳,
- 異步: 異步就是發起一個呼叫后,立刻得到被呼叫者的回應表示已接收到請求,但是被呼叫者并沒有回傳結果,此時我們可以處理其他的請求,被呼叫者通常依靠事件,回呼等機制來通知呼叫者其回傳結果,
- 同步和異步的區別最大在于異步的話呼叫者不需要等待處理結果,被呼叫者會通過回呼等機制來通知呼叫者其回傳結果,
阻塞和非阻塞
- 阻塞: 阻塞就是發起一個請求,呼叫者一直等待請求結果回傳,也就是當前執行緒會被掛起,無法從事其他任務,只有當條件就緒才能繼續,
- 非阻塞: 非阻塞就是發起一個請求,呼叫者不用一直等著結果回傳,可以先去干其他事情,
- 阻塞和非阻塞的區別最大在于有沒有一直在干其他的活動,
BIO是什么
同步阻塞:舉個例子 : 我現在上廁所 現在廁所的坑已經滿了 我什么事情都不做 我就一直等(主動觀察)哪一個 坑沒人了 ,我就立馬去占坑 通過這個示例 可以理解這是同步阻塞的IO
NIO是什么
NIO : 同步非阻塞 New IO Non-Block IO 舉個例子: 我現在上廁所 現在廁所的坑已經滿了 這時候我不會像之前一樣 我會出去抽支煙 或者微信搖一搖 然后我會時不時回去廁所主動看看 看看有沒有人走 然后再占有坑
AIO是什么
異步非阻塞IO 舉個例子: 我沒有在廁所里面等著 而是在廁所外面玩手機,如果有人上完廁所他告訴我: 我好了 你去吧, 這時候我再回去廁所做我自己的事情
異步阻塞IO 舉個例子: 開發中非常少 我現在上廁所 現在廁所的坑已經滿了 這時候比較懶 什么也不做 就在坑旁干等著 等上廁所的人上好了之后告訴我 我好了 你去吧
它們之間的區別
BIO: 發起請求–>一直阻塞–>處理完成
NIO: Selector主動輪詢channel–>處理請求–>處理完成
AIO: 發起請求–>通知回呼,
八、集合(容器)
27.談談Java集合中那些執行緒安全的集合 & 實作原理
首先要明白執行緒安全就是說多執行緒訪問同一代碼,不會產生不確定的結果,撰寫執行緒安全的代碼是低依靠執行緒同步,
Vector、ArrayList、LinkedList
- Vector的方法都是同步的(Synchronized),是執行緒安全的(thread-safe),而ArrayList,LinkedList的方法不是,由于執行緒的同步必然要影響性能,因此,ArrayList的性能比Vector好
在一列資料的后面添加資料而不是在前面或中間,并且需要隨機地訪問其中的元素時,使用ArrayList會提供比較好的性能,而訪問鏈表中的某個元素時,就必須從鏈表的一端開始沿著連接方向一個一個元素地去查找,直到找到所需的元素為止,所以,當你的操作是在一列資料的前面或中間添加或洗掉資料,并且按照順序訪問其中的元素時,就應該使用LinkedList
HashTable,HashMap,HashSet
- Hashtable:基于哈希表實作的,同樣每個元素是一個key-value對,其內部也是通過單鏈表解決沖突問題,容量不足(超過了閥值)時,同樣會自動增長,
Hashtable也是JDK1.0引入的類,是執行緒安全的,能用于多執行緒環境中,- HashMap,HashSet不是執行緒安全的
- HashMap: 實作了Map介面,Map介面對鍵值對進行映射,Map中不允許重復的鍵,Map介面有兩個基本的實作,HashMap和TreeMap,TreeMap保存了物件的排列次序,而HashMap則不能,HashMap
允許鍵和值為null,HashMap是非synchronized的,但是HashMap可以通過Collections進行同步:Map m = Collections.synchronizeMap(hashMap);, 這樣多個執行緒同時訪問HashMap時,能保證只有一個執行緒更改Map,public Object put(Object Key,Object value)方法用來將元素添加到map中- HashSet: 實作了Set介面,不允許集合中有重復的值,物件存盤在HashSet之前,要先確保物件重寫equals()和hashCode()方法,這樣才能比較物件的值是否相等,以確保set中沒有儲存相等的物件,如果我們沒有重寫這兩個方法,將會使用這個方法的默認實作,public boolean add(Object o)方法用來在Set中添加元素,當元素值重復時則會立即回傳false,如果成功添加的話會回傳true,
28.HashMap和Hashtable的區別
Hashtable繼承自Dictionary類,而HashMap繼承自AbstractMap類,但二者都實作了Map介面,但決定用哪一個之前先要弄清楚它們之間的分別,主要的區別有:執行緒安全性,同步(synchronization),以及速度,
- HashMap幾乎可以等價于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受為null的鍵值(key)和值(value),而Hashtable則不行),
- HashMap是非synchronized,而Hashtable是synchronized,這意味著Hashtable是執行緒安全的,多個執行緒可以共享一個Hashtable;而如果沒有正確的同步的話,多個執行緒是不能共享HashMap的,Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的擴展性更好,
- 另一個區別是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器,不是fail-fast的,所以當有其它執行緒改變了HashMap的結構(增加或者移除元素),將會拋出ConcurrentModificationException,但迭代器本身的remove()方法移除元素則不會拋出ConcurrentModificationException例外,但這并不是一個一定發生的行為,要看JVM,這條同樣也是Enumeration和Iterator的區別,
- 由于Hashtable是執行緒安全的也是synchronized,所以在單執行緒環境下它比HashMap要慢,如果不需要同步,只需要單一執行緒,那么使用HashMap性能要好過Hashtable,
- HashMap不能保證隨著時間的推移Map中的元素次序是不變的,
29.HashSet和HashMap的區別
- HashMap實作了Map介面, HashSet實作了Set介面
- HashMap儲存鍵值對, HashSet僅僅存盤物件
- HashMap使用put()方法將元素放入map中, HashSet使用add()方法將元素放入set中
- HashMap中使用鍵物件來計算hashcode值, HashSet使用成員物件來計算hashcode值,對于兩個物件來說hashcode可能相同,所以equals()方法用來判斷物件的相等性,如果兩個物件不同的話,那么回傳false
- HashMap比較快,因為是使用唯一的鍵來獲取物件 HashSet較HashMap來說比較慢.
30.TreeMap和TreeSet的區別與聯系
相同點:
- TreeMap和TreeSet都是有序的集合(非執行緒安全的),也就是說他們存盤的值都是排好序
的,- TreeMap和TreeSet都是非同步集合,因此他們不能在多執行緒之間共享,不過可以使用方法Collections.synchroinzedMap()來實作同步
- 運行速度都要比Hash集合慢,他們內部對元素的操作時間復雜度為O(logN),而
HashMap/HashSet則為O(1),- 要求存放的物件所屬的類必須實作Comparable介面,該介面提供了比較元素的compareTo()方法,當插入元素時會回呼該方法比較元素的大小,
不同點:
- 最主要的區別就是TreeSet和TreeMap分別實作Set和Map介面
- TreeSet只存盤一個物件,而TreeMap存盤兩個物件Key和Value(僅僅key物件有序)
- TreeSet中不能有重復物件,而TreeMap中可以存在
- TreeMap的底層采用紅黑樹的實作,完成資料有序的插入,排序,因此它要求一定要有Key比較的方法,要么傳入Comparator實作,要么key物件實作Comparable介面,
31. ArrayMap和HashMap的區別
HashMap:
內部是使用一個默認容量為16的陣列來存盤資料的,而陣列中每一個元素卻又是一個鏈表的頭結點,所以,更準確的來說,HashMap內部存盤結構是使用哈希表的拉鏈結構(陣列+鏈表),HashMap獲取資料是通過遍歷Entry[]陣列來得到對應的元素,在資料量很大時候會比較慢,所以在Android中,HashMap是比較費記憶體的,
ArrayMap:
是一個<key,value>映射的資料結構,它設計上更多的是考慮記憶體的優化,內部是使用兩個陣列進行資料存盤,一個陣列記錄key的hash值,另外一個陣列記錄Value值,它和SparseArray一樣,也會對key使用二分法進行從小到大排序,在添加、洗掉、查找資料的時候都是先使用二分查找法得到相應的index,然后通過index來進行添加、查找、洗掉等操作,所以,應用場景和SparseArray的一樣,如果在資料量比較大的情況下,那么它的性能將退化至少50%,
HashMap和ArrayMap各自的優勢資料量比較小,并且需要頻繁的使用Map存盤資料的時候,推薦使用ArrayMap,
而資料量比較大的時候,則推薦使用HashMap,
- 查找效率
HashMap因為其根據hashcode的值直接算出index,所以其查找效率是隨著陣列長度增大而增加的,ArrayMap使用的是二分法查找,所以當陣列長度每增加一倍時,就需要多進行一次判斷,效率下降,所以對于數量比較大的情況下,推薦使用HashMap- 擴容數量
HashMap初始值16個長度,每次擴容的時候,直接申請雙倍的陣列空間,
ArrayMap每次擴容的時候,如果size長度大于8時申請size*1.5個長度,大于4小于8時申請8個,小于4時申請4個,這樣比較ArrayMap其實是申請了更少的記憶體空間,但是擴容的頻率會更高,因此,如果當資料量比較大的時候,還是使用HashMap更合適,因為其擴容的次數要比ArrayMap少很多,- 擴容效率
HashMap每次擴容的時候時重新計算每個陣列成員的位置,然后放到新的位置,
ArrayMap則是直接使用System.arraycopy,所以效率上肯定是ArrayMap更占優勢,這里需要說明一下,網上有一種說因為ArrayMap使用System.arraycopy更省記憶體空間,這一點我真的沒有看出來,arraycopy也是把老的陣列的物件一個一個的賦給新的陣列,當然效率上肯定arraycopy更高,因為是直接呼叫的c層的代碼,- 記憶體耗費
以ArrayMap采用了一種獨特的方式,能夠重復的利用因為資料擴容而遺留下來的陣列空間,方便下一個ArrayMap的使用,而HashMap沒有這種設計,由于ArrayMap只快取了長度是4和8的時候,所以如果頻繁的使用到Map,而且資料量都比較小的時候,ArrayMap無疑是相當的節省記憶體的,
32. Collection 和 Collections的區別?
Collection:
是集合類的上層介面,本身是一個Interface,里面包含了一些集合的基本操作,Collection介面時Set介面和List介面的父介面
Collections
Collections是一個集合框架的幫助類,里面包含一些對集合的排序,搜索以及序列化的操作,最根本的是Collections是一個類,Collections 是一個包裝類,Collection 表示一組物件,這些物件也稱為 collection 的元素,一些collection 允許有重復的元素, 而另一些則不允許,一些 collection 是有序的,而另一些則是無序的,
33. Map的遍歷方式有哪些?
在for-each回圈中使用entries來遍歷
在for-each回圈中遍歷keys或values,
使用Iterator遍歷
通過鍵找值遍歷(效率低)
九、Java并發
34. 什么是執行緒,什么是行程,兩者區別?
行程 :行程是并發執行程式在執行程序中資源分配和管理的基本單位(資源分配的最小單位),行程可以理解為一個應用程式的執行程序,應用程式一旦執行,就是一個行程,每個行程都有自己獨立的地址空間,每啟動一個行程,系統就會為它分配地址空間,建立資料表來維護代碼段、堆疊段和資料段,通常來說,應用中的 Activity、Service 等四大組件默認都位于一個行程里面,并且這個行程名稱的默認值就是我們給應用定義的包名,系統為每個行程分配的記憶體是有限的,比如在以前的低端手機上常見是 16M,現在的機器記憶體更大一些,32M、48M,甚至更高,但是,總是有限的,畢竟一個手機出廠之后RAM 的大小就定了,總是無法滿足所有應用的需求,所以,一個明智的選擇就是使用多行程,將一些看不見的服務、比較獨立而又相當占用記憶體的功能運行在另外一個行程當中,主動分擔主行程的記憶體消耗,常見如,應用中的推送服務,音樂類App 的后臺播放器等等,單獨運行在一個行程中,
執行緒: 程式執行的最小單位,每個行程都有自己的地址空間,即行程空間,在網路或多用戶換機下,一個服務器通常需要接收大量不確定數量用戶的并發請求,為每一個請求都創建一個行程顯然行不通(系統開銷大回應用戶請求效率低),因此作業系統中執行緒概念被引進,引入目的是為了減少程式在并發執行程序中的開銷,使OS的并發效率更高,
行程與執行緒的區別
- 調度:執行緒作為調度和分配的基本單位,行程作為擁有資源的基本單位;
- 地址空間: 同一行程的所有執行緒共享本行程的地址空間,而不同的行程之間的地址空間是獨立的,
- 資源擁有: 同一行程的所有執行緒共享本行程的資源,如記憶體,CPU,IO等,行程之間的資源是獨立的,無法共享,
- 執行程序:每一個行程可以說就是一個可執行的應用程式,每一個獨立的行程都有一個程式執行的入口,順序執行序列,但是執行緒不能夠獨立執行,必須依存在應用程式中,由程式的多執行緒控制機制進行控制,
- 健壯性: 因為同一行程的所以執行緒共享此執行緒的資源,因此當一個執行緒發生崩潰時,此行程也會發生崩潰, 但是各個行程之間的資源是獨立的,因此當一個行程崩潰時,不會影響其他行程,因此行程比執行緒健壯,執行緒執行開銷小,但不利于資源的管理與保護,行程的執行開銷大,但可以進行資源的管理與保護,行程可以跨機器前移,
行程與執行緒的聯系:
- 一個執行緒只能屬于一個行程,而一個行程可以有多個執行緒,但至少有一個執行緒;
- 資源分配給行程,同一行程的所有執行緒共享該行程的所有資源;
-處理機分給執行緒,即真正在處理機上運行的是執行緒;
-執行緒在執行程序中,需要協作同步,不同行程的執行緒間要利用訊息通信的辦法實作同步,
舉個例子更好理解:
假如我們把整條道路看成是一個“行程”的話,那由白色虛線分隔開來的各個車道就是行程中的各個“執行緒”了,這些執行緒(車道)共享了行程(道路)的公共資源(土地資源),這些執行緒(車道)必須依賴于行程(道路),也就是說,執行緒不能脫離于行程而存在(就像離開了道路,車道也就沒有意義了),這些執行緒(車道)之間可以并發執行(各個車道你走你的,我走我的),也可以互相同步(某些車道在交通燈亮時禁止繼續前行或轉彎,必須等待其它車道的車輛通行完畢),這些執行緒(車道)之間依靠代碼邏輯(交通燈)來控制運行,一旦代碼邏輯控制有誤(死鎖,多個執行緒同時競爭唯一資源),那么執行緒將陷入混亂,無序之中,這些執行緒(車道)之間誰先運行是未知的,只有在執行緒剛好被分配到CPU時間片(交通燈變化)的那一刻才能知道,
使用場景
- 在程式中,如果需要頻繁創建和銷毀的,使用執行緒,因為行程創建和銷毀開銷很大(需要不停的分配資源),但是執行緒頻繁的呼叫只是改變CPU的執行,開銷小
- 如果需要程式更加的穩定安全時,可以選擇行程,如果追求速度,就選擇執行緒,
35. 多執行緒的3種實作方式
1.繼承Thread類創建執行緒類
- 定義Thread類的子類, 并重寫該類的run方法, 該run方法的方法體就代表了
執行緒要完成的任務, 因此把run()方法稱為執行體,- 創建Thread子類的實體, 即創建了執行緒物件,
- 呼叫執行緒物件的start()方法來啟動該執行緒
2.通過Runnable介面創建執行緒類
- 定義runnable介面的實作類, 并重寫該介面的run()方法, 該run()方法的方法體同樣是該執行緒的執行緒執行體,
- 創建 Runnable實作類的實體, 并依此實體作為Thread的target來創建Thread物件, 該Thread物件才是真正的執行緒物件,
- 呼叫執行緒物件的start()方法來啟動該執行緒,
3.通過Callable和Future創建執行緒
- 創建Callable介面的實作類, 并實作call()方法, 該call()方法將作為執行緒執行體, 并且有回傳值
- 創建Callable實作類的實體, 使用FutureTask類來包裝Callable物件, 該FutureTask物件封裝了該Callable物件的call()方法的回傳值,
- 使用FutureTask物件作為Thread物件的target創建并啟動新執行緒,
- 呼叫FutureTask物件的get()方法來獲得子執行緒執行結束后的回傳值, 呼叫get()方法會阻塞執行緒
創建執行緒的三種方式的對比
- 采用實作Runnable、Callable介面的方式創建多執行緒時:
- 優勢
執行緒類只是實作了Runnable介面或Callable介面,還可以繼承其他類,在這種方式下,多個執行緒可以共享同一個target物件,所以非常適合多個相同執行緒來處理同一份資源的情況,從而可以將CPU、代碼和資料分開,形成清晰的模型,較好地體現了面向物件的思想,- 劣勢
編程稍微復雜,如果要訪問當前執行緒,則必須使用Thread.currentThread()方法,
- 使用繼承Thread類的方式創建多執行緒時
- 優勢
撰寫簡單,如果需要訪問當前執行緒,則無需使用Thread.currentThread()方法,直接使用this即可獲得當前執行緒,- 劣勢
執行緒類已經繼承了Thread類,所以不能再繼承其他父類,
runnable 和 callable 的區別
- Callcble是可以有回傳值的,具體的回傳值就是在Callable的介面方法call回傳的,并且這個回傳值具體是通過實作Future介面的物件的get方法獲取的,這個方法是會造成執行緒阻塞的;而Runnable是沒有回傳值的,因為Runnable介面中的run方法是沒有回傳值的;
- Callable里面的call方法是可以拋出例外的,我們可以捕獲例外進行處理;但是Runnable里面的run方法是不可以拋出例外的,例外要在run方法內部必須得到處理,不能向外界拋出;
- callable和runnable都可以應用于executors,而thread類只支持runnable
36.并發編程的三大概念:原子性,有序性,可見性
Java 記憶體模型 (JMM)關鍵技術點都是圍繞著多執行緒的原子性、可見性、有序來討論的,JMM 解決了可見性和有序性的問題,而鎖解決了原子性的問題,Java記憶體模型規定了所有的變數都存盤在主記憶體中,每條執行緒中還有自己的作業記憶體,執行緒的作業記憶體中保存了被該執行緒所使用到的變數(這些變數是從主記憶體中拷貝而來),執行緒對變數的所有操作(讀取,賦值)都必須在作業記憶體中進行,不同執行緒之間也無法直接訪問對方作業記憶體中的變數,執行緒間變數值的傳遞均需要通過主記憶體來完成,
原子性:即一個操作或者多個操作,要么全部執行,并且執行的程序不會被任何因素打斷,要么就都不執行,只有簡單的讀取、賦值(而且必須是將數字賦值給某個變數,變數之間的相互賦值不是原子操作)才是原子操作,Java記憶體模型只保證了基本讀取和賦值是原子性操作,如果要實作更大范圍操作的原子性,可以通過synchronized和Lock來實作,由于synchronized和Lock能夠保證任一時刻只有一個執行緒執行該代碼塊,那么自然就不存在原子性問題了,從而保證了原子性,
可見性:是指當多個執行緒訪問同一個變數時,一個執行緒修改了這個變數的值,其他執行緒能夠立即看得到修改的值,Java提供了volatile關鍵字來保證可見性,當一個共享變數被volatile修飾時,它會保證修改的值會立即被更新到主存,當有其他執行緒需要讀取時,它會去記憶體中讀取新值,而普通的共享變數不能保證可見性,因為普通共享變數被修改之后,什么時候被寫入主存是不確定的,當其他執行緒去讀取時,此時記憶體中可能還是原來的舊值,因此無法保證可見性,通過synchronized和Lock也能夠保證可見性,synchronized和Lock能保證同一時刻只有一個執行緒獲取鎖然后執行同步代碼,并且在釋放鎖之前會將對變數的修改重繪到主存當中,因此可以保證可見性,
有序性:即程式執行的順序按照代碼的先后順序執行,一般來說,處理器為了提高程式運行效率,可能會進行指令重排序,也就是對輸入代碼進行優化,它不保證程式中各個陳述句的執行先后順序同代碼中的順序一致,但是它會保證程式最終執行結果和代碼順序執行的結果是一致的,指令重排序不會影響單個執行緒的執行,但是會影響到執行緒并發執行的正確性,也就是說,要想并發程式正確地執行,必須要保證原子性、可見性以及有序性,只要有一個沒有被保證,就有可能會導致程式運行不正確,可以通過volatile關鍵字來保證一定的“有序性”,volatile關鍵字能禁止指令重排序,所以volatile能在一定程度上保證有序性,另外可以通過synchronized和Lock來保證有序性,很顯然,synchronized和Lock保證每個時刻是有一個執行緒執行同步代碼,相當于是讓執行緒順序執行同步代碼,自然就保證了有序性,
synchronized關鍵字是防止多個線程同時執行一段代碼,那么就會很影響程式執行效率,而volatile關鍵字在某些情況下性能要優于synchronized,但是要注意volatile關鍵字是無法替代synchronized關鍵字的,因為volatile關鍵字無法保證操作的原子性,
37.并行和并發有什么區別?
舉個例子:你吃飯吃到一半,電話來了,你一直到吃完了以后才去接,說明你不支持并發也不支持并行,
你吃飯吃到一半,電話來了,你停下來接了電話,然后繼續吃飯,說明你支持并發,(不一定是同時)
你吃飯吃到一半,電話來了,你一邊打電話一邊繼續吃飯,說明你支持并行,
并發的關鍵在于有處理多個事件的能力,不一定要同時,并行的關鍵在于有同時處理多個事件的能力,
兩個區別在于是否是同時,并發是輪流處理多個事件,并行是同時處理多個事件,
38.守護執行緒是什么?
定義: 指在程式運行時 在后臺提供一種通用服務的執行緒,這種執行緒并不屬于程式中不可或缺的部分,通俗點講,任何一個守護執行緒都是整個JVM中所有非守護執行緒的"保姆",
特點: 守護執行緒擁有自動結束自己生命周期的特性,而非守護執行緒不具備這個特點,當 JVM 中不存在任何一個正在運行的非守護執行緒時,JVM 行程即會退出,也就是說只要有任何非守護執行緒還在運行,程式就不會終止,當JVM中只有守護執行緒運行時JVM會自動關閉,JVM 中的垃圾回收執行緒就是典型的守護執行緒,
使用方法: 在Java語言中,守護執行緒一般具有較低的優先級,它并非只由JVM內部提供,用戶在撰寫程式時也可以自己設定守護執行緒,例如:將一個執行緒設定為守護執行緒的方法就是在呼叫start()啟動執行緒之前呼叫物件的setDaemon(true)方法,若將以上引數設定為false,則表示的是用戶行程模式,需要注意的是,當在一個守護執行緒中產生了其他的執行緒,那么這些新產生的執行緒默認還是守護執行緒,用戶執行緒也是如此,
應用場景:通常來說,守護執行緒經常被用來執行一些后臺任務,但是呢,你又希望在程式退出時,或者說 JVM 退出時,執行緒能夠自動關閉,此時,首選守護執行緒,
39.在 java 程式中怎么保證多執行緒的運行安全?
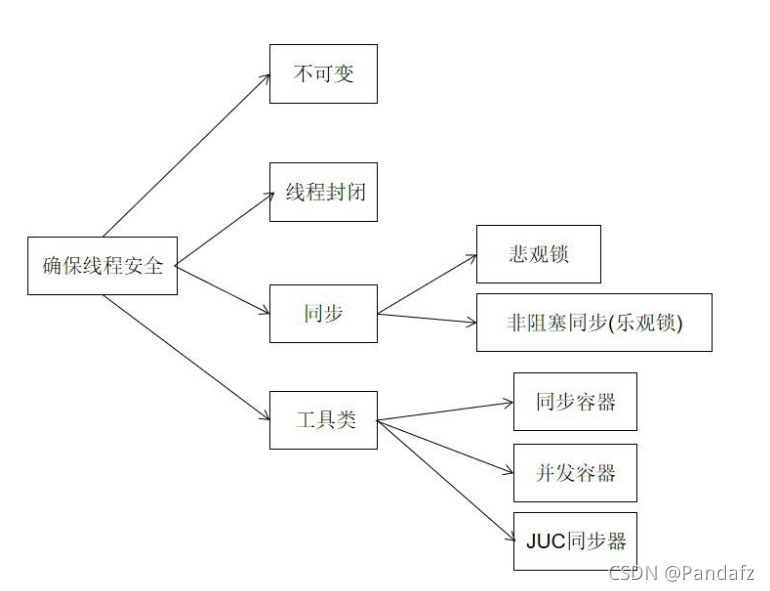
總體來說執行緒安全在三個方面體現:
原子性:提供互斥訪問,同一時刻只能有一個執行緒對資料進行操作,
(atomic,synchronized),
可見性:一個執行緒對主記憶體的修改可以及時地被其他執行緒看到,(synchronized,volatile),
有序性:一個執行緒觀察其他執行緒中的指令執行順序,由于指令重排序,該觀察結果一般雜亂無序,(happens-before原則),
導致原因:
- 快取導致的可見性問題
- 執行緒切換帶來的原子性問題
- 編譯優化帶來的有序性問題
解決辦法:
確保執行緒安全作用是讓程式按照我們預期的行為去執行
- JDK Atomic開頭的原子類(AtomicInteger,AtomicLong,AtomicBoolean等等)、synchronized、LOCK,可以解決原子性問題
- synchronized、volatile、LOCK,可以解決可見性問題
- Happens-Before 規則可以解決有序性問題,synchronized和Lock來保證有序性
- 使用java提供的安全類:java.util.concurrent包下的類自身就是執行緒安全的,在保證安全的同時還能保證性能;
Happens-Before 規則如下:
- 程式次序規則:在一個執行緒內,按照程式控制流順序,書寫在前面的操作先行發生于書寫在后面的操作
- 管程鎖定規則:一個unlock操作先行發生于后面對同一個鎖的lock操作
- volatile變數規則:對一個volatile變數的寫操作先行發生于后面對這個變數的讀操作
- 執行緒啟動規則:Thread物件的start()方法先行發生于此執行緒的每一個動作
- 執行緒終止規則:執行緒中的所有操作都先行發生于對此執行緒的終止檢測
- 執行緒中斷規則:對執行緒interrupt()方法的呼叫先行發生于被中斷執行緒的代碼檢測到中斷事件的發生
- 物件終結規則:一個物件的初始化完成(建構式執行結束)先行發生于它的finalize()方法的開始
40.說一下 synchronized 底層實作原理?
基于物件的監視器(ObjectMonitor),在同步方法執行前后,有兩個指令,進入同步方法前monitorenter,方法執行完成后monitorexit;
任意一個物件都擁有自己的監視器,當同步代碼塊或同步方法時,執行方法的執行緒必須先獲得該物件的監視器才能進入同步塊或同步方法,沒有獲取到監視器的執行緒將會被阻塞,并進入同步佇列,狀態變為 BLOCKED ,當成功獲取監視器的執行緒釋放了鎖后,會喚醒阻塞在同步佇列的執行緒,使其重新嘗試對監視器的獲取,
補充:一個synchronize鎖會有兩個monitorexit,這是保證synchronize能一定釋放鎖的機制,一個是方法正常執行完釋放,一個是執行程序發生例外時虛擬機釋放;
synchronized可以用在如下地方
- 修飾實體方法,對當前實體物件this加鎖
- 修飾靜態方法,對當前類的Class物件加鎖
- 修飾代碼塊,指定加鎖物件,對給定物件加鎖
41.synchronized 和 volatile 的區別是什么?
1、
volatile本質是在告訴jvm當前變數在暫存器(作業記憶體)中的值是不確定的,需要從主存中讀取;synchronized則是鎖定當前變數,只有當前執行緒可以訪問該變數,其他執行緒被阻塞住,
2、volatile僅能使用在變數級別;synchronized則可以使用在變數、方法、和類級別的
3、volatile僅能實作變數的修改可見性,不能保證原子性;而synchronized則可以保證變數的修改可見性和原子性
4、volatile不會造成執行緒的阻塞;synchronized可能會造成執行緒的阻塞,
5、volatile標記的變數不會被編譯器優化;synchronized標記的變數可以被編譯器優化
42.synchronized 和 Lock 有什么區別?
1、synchronized不需要手動釋放鎖,lock需要在鎖用完后進行unlock釋放鎖;
2、synchronized只能是默認的非公平鎖,lock可以指定使用公平鎖或者非公平鎖;
3、lock提供的Condition(條件)可以指定喚醒哪些執行緒,而synchronized只能隨機喚醒一個或者全部喚醒;
43.多執行緒鎖的升級原理是什么?
JVM優化synchronized的運行機制,當JVM檢測到不同的競爭狀態時,就會根據需要自動切換到合適的鎖,這種切換就是鎖的升級,升級是不可逆的,也就是說只能從低到高,不能夠降級,
鎖的級別從低到高:
無鎖 -> 偏向鎖 -> 輕量級鎖 -> 重量級鎖
鎖分級別原因:
沒有優化以前,synchronized是重量級鎖(悲觀鎖),使用 wait 和 notify、notifyAll 來切換執行緒狀態非常消耗系統資源;執行緒的掛起和喚醒間隔很短暫,這樣很浪費資源,影響性能,所以 JVM 對 synchronized 關鍵字進行了優化,把鎖分為 無鎖、偏向鎖、輕量級鎖、重量級鎖 狀態,
無鎖:沒有對資源進行鎖定,所有的執行緒都能訪問并修改同一個資源,但同時只有一個執行緒能修改成功,其他修改失敗的執行緒會不斷重試直到修改成功,
偏向鎖:HotSpot作者發現,大多數情況下,鎖不僅不存在多執行緒競爭,而且總是由同一執行緒多次獲得,當一個執行緒訪問同步塊并獲得鎖時,會在物件頭和堆疊幀中的鎖記錄里面存盤偏向的執行緒ID,以后該執行緒再進入和退出同步塊時不需要進行CAS操作來加鎖和解鎖,
輕量級鎖:Java SE 1.6 為了減少獲得/釋放鎖帶來的性能消耗,引入了“輕量級鎖”和“偏向鎖”,“輕量級”是相對于使用作業系統互斥量來實作的傳統鎖而言的,但是,首先需要強調一點的是,輕量級鎖并不是用來代替重量級鎖的,它的本意是在沒有多執行緒競爭的前提下,減少傳統的重量級鎖使用產生的性能消耗,在解釋輕量級鎖的執行程序之前,先明白一點,輕量級鎖所適應的場景是執行緒交替執行同步塊的情況,如果存在同一時間訪問同一鎖的情況,就會導致輕量級鎖膨脹為重量級鎖,
重量級鎖:指當有一個執行緒獲取鎖之后,其余所有等待獲取該鎖的執行緒都會處于阻塞狀態,重量級鎖通過物件內部的監視器(monitor)實作,而其中 monitor 的本質是依賴于底層作業系統的 Mutex Lock 實作,作業系統實作執行緒之間的切換需要從用戶態切換到內核態,切換成本非常高,
| 鎖 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|
| 偏向鎖 | 加鎖和解鎖不需要額外的消耗,和執行非同步方法比僅存在納秒級的差距 | 如果執行緒間存在鎖競爭,會帶來額外的鎖撤銷的消耗 | 適用于只有一個執行緒訪問同步塊場景 |
| 輕量級鎖 | 競爭的執行緒不會阻塞 ,提高了程式的回應速度 | 如果始終得不到鎖競爭的執行緒使用自旋會消耗CPU | 追求回應時間,同步塊執行速度非常快 |
| 重量級鎖 | 執行緒競爭不使用自旋,不會消耗CPU | 執行緒阻塞,回應時間緩慢 | 追求吞吐量,同步塊執行速度較長 |
44.什么是死鎖?
死鎖是指兩個或兩個以上的行程在執行程序中,由于競爭資源或者由于彼此通信而造成的一種阻塞的現象,若無外力作用,它們都將無法推進下去,此時稱系統處于死鎖狀態或系統產生了死鎖,這些永遠在互相等待的行程稱為死鎖行程,是作業系統層面的一個錯誤,是行程死鎖的簡稱,系統發生死鎖現象不僅浪費大量的系統資源,甚至導致整個系統崩潰,帶來災難性后果,
45.怎么防止死鎖?
一般來說,要出現死鎖問題需要滿足以下4個條件:
- 互斥條件:一個資源每次只能被一個執行緒使用,
- 請求與保持條件:一個執行緒因請求資源而阻塞時,對已獲得的資源保持不放,
- 不剝奪條件:執行緒已獲得的資源,在未使用完之前,不能強行剝奪,
- 回圈等待條件:若干執行緒之間形成一種頭尾相接的回圈等待資源關系,
在JAVA編程中,有3種典型的死鎖型別:
- 靜態的鎖順序死鎖:a和b兩個方法都需要獲得A鎖和B鎖,一個執行緒執行a方法且已經獲得了A鎖,在等待B鎖;另一個執行緒執行了b方法且已經獲得了B鎖,在等待A鎖,解決方法是將所有需要多個鎖的執行緒,都以相同的物件順序來獲得鎖,
- 動態的鎖順序死鎖:指兩個執行緒呼叫同一個方法時,傳入的引數顛倒造成的死鎖,解決方案是使用System.identifyHashCode來定義鎖的順序,確保所有的執行緒都以相同的順序獲得鎖,
- 協作物件之間發生的死鎖:一個執行緒呼叫了A物件的a方法,另一個執行緒呼叫了B物件的b方法,此時可能會發生,第一個執行緒持有A物件鎖并等待B物件鎖,另一個執行緒持有B物件鎖并等待A物件鎖,解決方案是需要呼叫某個外部方法時不需要持有鎖,即避免在持有鎖的情況下呼叫外部的方法,
在寫代碼時,要確保執行緒在獲取多個鎖時采用一致的順序,同
時,要避免在持有鎖的情況下呼叫外部方法,
46.ThreadLocal 是什么?
ThreadLocal是什么:
JDK1.2的版本中就提供java.lang.ThreadLocal類,每一個ThreadLocal能夠放一個執行緒級別的變數, 它本身能夠被多個執行緒共享使用,并且又能夠達到執行緒安全的目的,且絕對執行緒安全,ThreadLocal是解決執行緒安全問題一個很好的思路,它通過為每個執行緒提供一個獨立的變數副本解決了變數并發訪問的沖突問題,在很多情況下,ThreadLocal比直接使用synchronized同步機制解決執行緒安全問題更簡單,更方便,且結果程式擁有更高的并發性,
47.Synchronized 和 ReentrantLock 區別是什么?
相似點:
這兩種同步方式有很多相似之處,它們都是加鎖方式同步,而且都是阻塞式的同步,也就是說當如果一個執行緒獲得了物件鎖,進入了同步塊,其他訪問該同步塊的執行緒都必須阻塞在同步塊外面等待,而進行執行緒阻塞和喚醒的代價是比較高的(作業系統需要在用戶態與內核態之間來回切換,代價很高,不過可以通過對鎖優化進行改善),
不同點:
- 語法區別:
Synchronized是java語言的關鍵字,是原生語法層面的互斥,需要jvm實作,ReentrantLock是JDK 1.5之后提供的API層面的互斥鎖,Synchronized可以修飾實體方法,靜態方法,代碼塊,自動釋放鎖,ReentrantLock一般需要try catch finally陳述句,在try中獲取鎖,在finally釋放鎖,需要手動釋放鎖,Synchronized鎖的范圍是整個方法或synchronized塊部分,ReentrantLock因為是方法呼叫,可以跨方法,靈活性更大
- 實作方式的區別:
Synchronized是重量級鎖,重量級鎖需要將執行緒從內核態和用戶態來回切換,如:A執行緒切換到B執行緒,A執行緒需要保存當前現場,B執行緒切換也需要保存現場,這樣做的缺點是耗費系統資源,這是一種被動阻塞悲觀鎖,狀態是blockReentrantLock是輕量級鎖,采用cas+volatile管理執行緒,不需要執行緒切換切換獲取鎖執行緒,這是一種樂觀的思想(可能失敗),這是一種主動的阻塞樂觀鎖,狀態是wait
- 公平和非公平
公平鎖,多個執行緒等待同一個鎖時,必須按照申請鎖的時間順序獲得鎖,
Synchronized只有非公平鎖,ReentrantLock默認的建構式是創建的非公平鎖,可以通過引數true設為公平鎖,但公平鎖表現的性能不是很好,公平鎖通過建構式傳遞true表示,
- 可中斷的
持有鎖的執行緒長期不釋放的時候,正在等待的執行緒可以選擇放棄等待
Synchronized是不可中斷的,ReentrantLock提供可中斷和不可中斷兩種方式,其中lockInterruptibly方法表示可中斷,lock方法表示不可中斷,這相當于Synchronized來說可以避免出現死鎖的情況,
- 條件佇列
同步佇列:多執行緒同時競爭一把鎖失敗被掛起的執行緒,
條件佇列:正在執行的執行緒呼叫await/wait,從同步佇列加入的執行緒會進入條件佇列,正在執行執行緒呼叫signal/signalAll/notify/notifyAll,會將條件佇列一個執行緒或多個執行緒加入到同步佇列,
等待佇列:和條件佇列一個概念,
Synchronized只有一個等待佇列,要么隨機喚醒一個執行緒要么喚醒全部執行緒,ReentrantLock中一把鎖可以對應多個條件佇列,通過newCondition表示,一個ReentrantLock物件可以同時系結對個物件,ReenTrantLock提供了一個Condition(條件)類,用來實作分組喚醒需要喚醒的執行緒
48.執行緒有哪些狀態?
- 創建(NEW):新創建了一個執行緒物件,
- 就緒(RUNNABLE):執行緒物件創建后,其他執行緒(比如main執行緒)呼叫了該物件的
start()方法,該狀態的執行緒位于可運行執行緒池中,等待被執行緒調度選中,獲取cpu 的使用權 ,- 運行(RUNNING):可運行狀態(runnable)的執行緒獲得了cpu 時間片(timeslice) ,執行程式代碼,
- 阻塞(BLOCKED):阻塞狀態是指執行緒因為某種原因放棄了cpu 使用權,也即讓出了cpu timeslice,暫時停止運行,直到執行緒進入可運行(runnable)狀態,才有機會再次獲得cpu timeslice 轉到運行(running)狀態,阻塞的情況分三種:
- 等待阻塞:運行(running)的執行緒執行
o.wait()方法,JVM會把該執行緒放入等待佇列(waitting queue)中,- 同步阻塞:運行(running)的執行緒在獲取物件的同步鎖時,若該同步鎖被別的執行緒占用,則JVM會把該執行緒放入鎖池(lock pool)中,
- 其他阻塞:運行(running)的執行緒執行
Thread.sleep(long ms)或t.join()方法,或者發出了I/O請求時,JVM會把該執行緒置為阻塞狀態,當sleep()狀態超時、join()等待執行緒終止或者超時、或者I/O處理完畢時,執行緒重新轉入可運行(runnable)狀態,
- 死亡(DEAD):執行緒run()、main() 方法執行結束,或者因例外退出了run()方法,則該執行緒結束生命周期,死亡的執行緒不可再次復生,
49.sleep() 和 wait() 有什么區別?
基本區別
- sleep是Thread類的方法,wait是Object類中定義的方法
- sleep方法可以在任何地方呼叫
- wait方法只能在synchronized方法或synchronized塊中使用
本質區別
- Thread.sleep是static靜態方法,不能改變物件的機鎖,當一個synchronized塊中呼叫了sleep() 方法,執行緒雖然進入休眠,但是物件的機鎖沒有被釋放,其他執行緒依然無法訪問這個物件,只會讓出CPU,不會導致鎖行為的改變
- Object.wait不僅讓出CPU,還會釋放已經占有的同步資源鎖
| 區別 | wait() | sleep() |
|---|---|---|
| 歸屬類 | Object類實體方法 | Thread類靜態方法 |
| 是否釋放鎖 | 釋放鎖 | 不會釋放鎖 |
| 執行緒狀態 | 等待 | 睡眠 |
| 使用時機 | 只能在同步塊(Synchronized)中使用 | 在任何時候使用 |
| 喚醒條件 | 其他執行緒呼叫notify()或notifyAll()方法 | 超時或呼叫Interrupt()方法 |
| cpu占用 | 不占用cpu,程式等待n秒 | 占用cpu,程式等待n秒 |
50.notify()和 notifyAll()有什么區別?
- 如果執行緒呼叫了物件的 wait()方法,那么執行緒便會處于該物件的等待池中,等待池中的執行緒不會去競爭該物件的鎖,
- 當有執行緒呼叫了物件的 notifyAll()方法(喚醒所有 wait 執行緒)或 notify()方法(只隨機喚醒一個 wait 執行緒),被喚醒的的執行緒便會進入該物件的鎖池中,鎖池中的執行緒會去競爭該物件鎖,也就是說,呼叫了notify后只要一個執行緒會由等待池進入鎖池,而notifyAll會將該物件等待池內的所有執行緒移動到鎖池中,等待鎖競爭
- 優先級高的執行緒競爭到物件鎖的概率大,假若某執行緒沒有競爭到該物件鎖,它還會留在鎖池中,唯有執行緒再次呼叫 wait()方法,它才會重新回到等待池中,而競爭到物件鎖的執行緒則繼續往下執行,直到執行完了 synchronized 代碼塊,它會釋放掉該物件鎖,這時鎖池中的執行緒會繼續競爭該物件鎖,
- 如果wait被呼叫之前notify的喚醒通知就來了,那么這個執行緒并不能保證被喚醒,有可能會導致死鎖問題,
51.執行緒的 run()和 start()有什么區別?
創建一個執行緒 Thread t1 = new Thread()
t1.run():run是用主執行緒執行,只是呼叫了一個普通方法,并沒有啟動另一個執行緒,程式還是會按照順序執行相應的代碼,必須是這個方法執行完了代碼才能往下走,t1.start():start是new了一個執行緒執行的,表示重新開啟一個執行緒,不必等待其他執行緒運行完,只要得到cup就可以運行該執行緒,有多個執行緒使用start方法開啟時,并不需要等待其中一個完成,所以他們的執行順序應該是并行的,
52.創建執行緒池有哪幾種方式?
Executors類創建執行緒池,創建出來的執行緒池都實作了ExecutorService介面
newCachedThreadPool()方法可快取的執行緒池,如果執行緒池的容量超過了任務數,自動回收空閑執行緒,任務增加時可以自動添加新執行緒,執行緒池的容量不限制,比較適合處理執行時間比較小的任務,newFixedThreadPool()創建固定數目執行緒的執行緒池,每當提交一個任務就創建一個執行緒,直到達到執行緒池的最大數量,這時執行緒數量不再變化,當執行緒發生錯誤結束時,執行緒池會補充一個新的執行緒,可以用于已知并發壓力的情況下,對執行緒數做限制,newScheduledThreadPool創建一個支持定時及周期性的任務執行的執行緒池,多數情況下可用來替代Timer類,適用于需要多個后臺執行緒執行周期任務的場景,newSingleThreadExecutor創建一個單執行緒化的Executor,執行緒例外結束,會創建一個新的執行緒,能確保任務按指定順序(FIFO,LIFO,優先級)執行,可以用于需要保證順序執行的場景,并且只有一個執行緒在執行
53.執行緒池都有哪些狀態?
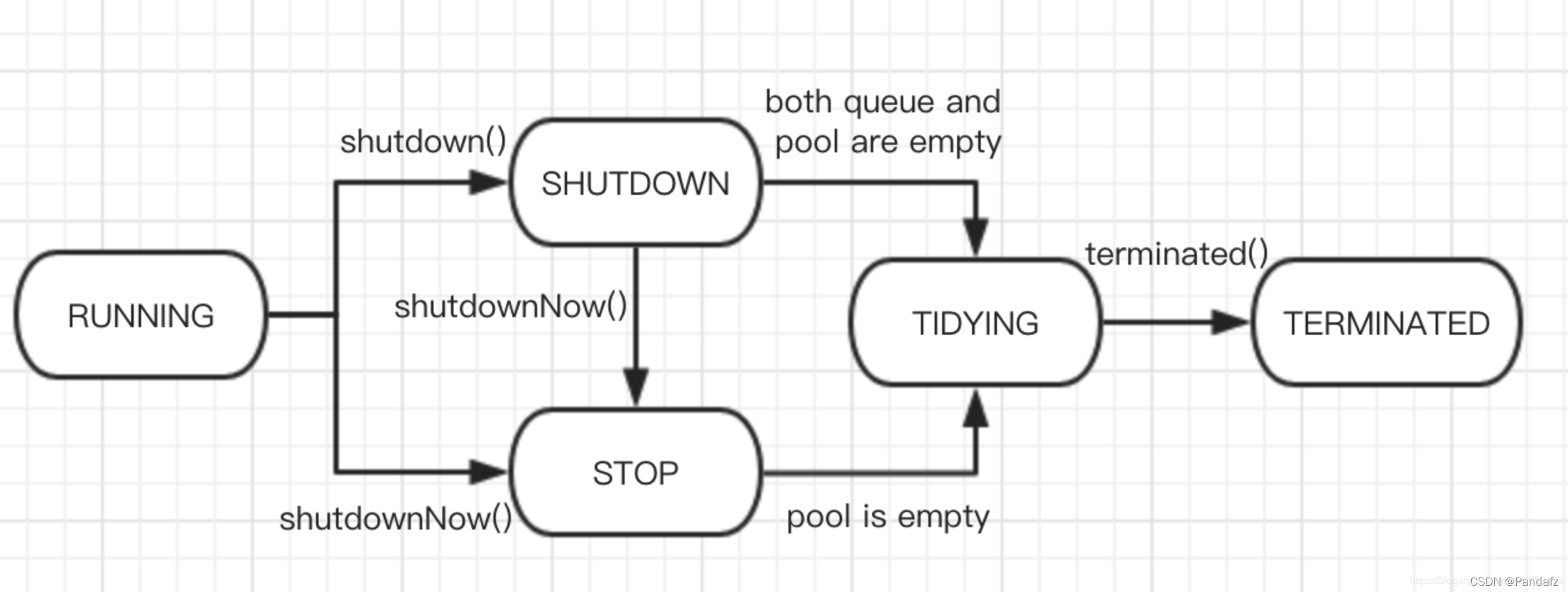
ThreadPoolExecutor是Executor底下的實作類,開發中常用的執行緒池就是它
執行緒池的5種狀態:Running、ShutDown、Stop、Tidying、Terminated,
Running
- 狀態說明:執行緒池處在RUNNING狀態時,能夠接收新任務,以及對已添加的任務進行處理,
- 狀態切換:執行緒池的初始化狀態是RUNNING,換句話說,執行緒池被一旦被創建,就處于RUNNING狀態,并且執行緒池中的任務數為0!
ShutDown
- 狀態說明:執行緒池處在SHUTDOWN狀態時,不接收新任務,但能處理已添加的任務,
- 狀態切換:呼叫執行緒池的shutdown()介面時,執行緒池由RUNNING -> SHUTDOWN,
Stop
- 狀態說明:執行緒池處在STOP狀態時,不接收新任務,不處理已添加的任務,并且會
中斷正在處理的任務,- 狀態切換:呼叫執行緒池的
shutdownNow()介面時,執行緒池由(RUNNING or SHUTDOWN ) -> STOP,
Tidying
- 狀態說明:當所有的任務已終止,ctl記錄的”任務數量”為0,執行緒池會變為TIDYING狀態,當執行緒池變為TIDYING狀態時,會執行鉤子函式terminated(),terminated()在ThreadPoolExecutor類中是空的,若用戶想在執行緒池變為TIDYING時,進行相應的處理;可以通過多載terminated()函式來實作,
- 狀態切換:當執行緒池在SHUTDOWN狀態下,阻塞佇列為空并且執行緒池中執行的任務也為空時,就會由 SHUTDOWN -> TIDYING,
當執行緒池在STOP狀態下,執行緒池中執行的任務為空時,就會由STOP -> TIDYING,
Terminated
- 狀態說明:執行緒池徹底終止,就變成TERMINATED狀態,
- 狀態切換:執行緒池處在TIDYING狀態時,執行完terminated()之后,就會由 TIDYING -> TERMINATED,
54.執行緒池中 submit()和 execute()方法有什么區別?
兩者都是執行任務的方法
execute()適用于不需要關注回傳值的場景,只需要將執行緒丟到執行緒池中去執行就可以了,
submit()方法適用于需要關注回傳值的場景
十、Java虛擬機
55.垃圾收集演算法/收集器
一切都是為了JVM運行效率
標記-清除演算法
- 機制: 首先標記出所有需要回收的物件,在標記完成后統一回收所有被標記的物件,
- 缺點
- 效率問題:標記和清除兩個程序的效率都不高
- 空間問題:標記清除之后產生大量不連續的記憶體碎片,可能會導致程式運行程序中需要分配較大物件時,無法找到足夠的連續記憶體而不得不提前觸發另一次垃圾收集動作,
復制演算法
- 機制:將可用記憶體按容量大小劃分為大小相等的兩塊,每次只使用其中的一塊,當一塊記憶體使用完了,就將還存活著的物件復制到另一塊上面,然后再把已使用過的記憶體空間一次清理掉,這樣使得每次都是對整個半區進行記憶體回收,記憶體分配時也就不用考慮記憶體碎片等復雜情況,現代的商業虛擬機都采用這種收集演算法來回收新生代,
- 缺點: 將記憶體縮小為了原來的一半,在物件存活率較高時,就要進行較多的復制操作,效率就會變低,,
標記-整理演算法
- 機制: 首先標記出所有需要回收的物件, 在標記完成后讓所有存活的物件都向一端移動,然后直接清理掉邊界以外的記憶體,
分代收集演算法
- 機制:把Java堆分為新生代和老年代,根據年代特點采用適當的收集演算法,在新生代中,每次垃圾收集時都發現有大批物件死去,只有少量存活,那就選用復制演算法,
在老年代中,因為物件存活率高、沒有額外空間對它進行分配擔保,就必須采用“標記-清除”或“標記-整理”演算法來進行回收,
56.判斷物件是否存活
- 判斷物件是否存活與“參考”有關
我們希望的垃圾回收器對它的回收時機的不同,對于一些比較重要的物件,我們希望垃圾回收器永遠不去回收它,即使此時記憶體空間已經不足了,因為一旦它被回收,將導致嚴重的后果,而對于一些不那么重要的物件,比如在做圖片快取的時候生成的大量圖片的快取物件,我們希望垃圾回收器只在記憶體不足的情況下去對它進行回收以提升用戶體驗,
Java中實際上有四種強度不同的參考,從強到弱它們分別是,強參考(Strong Reference),軟參考(Soft Reference),弱參考(Weak Reference)和虛參考(Phantom Reference),
強參考: 就是指在程式代碼之中普遍存在的,類似“Object obj = new Object()”這類的參考,只要強參考還存在,垃圾收集器永遠不會回收掉被參考的物件,
軟參考: 物件留在記憶體的能力不是那么強的參考,使用WeakReference,在系統將要發生記憶體溢位例外之前,將會把這些物件列進回收范圍之中進行第二次回收,軟參考非常適合于創建快取,當系統記憶體不足的時候,快取中的內容是可以被釋放的,
弱參考: 描述非必須物件的,被弱參考關聯的物件只能生存到下一次垃圾收集發生之前,當垃圾收集器作業時,無論當前記憶體是否足夠,都會回收掉只被弱參考關聯的物件,弱參考最常見的用處在哈希表中,當一個鍵值對被放入到哈希表中之后,哈希表物件本身就有了對這些鍵和值物件的參考,如果這種參考是強參考的話,那么只要哈希表物件本身還存活,其中所包含的鍵和值物件是不會被回收的,如果某個存活時間很長的哈希表中包含的鍵值對很多,最終就有可能消耗掉JVM中全部的記憶體,
虛參考: 一個物件無法通過虛參考來取得一個物件實體,就是形同虛設,與其他幾種參考不同的是,虛參考并不會決定物件的生命周期,如果一個物件僅持有虛參考,那么它就和沒有任何參考一樣,在任何時候都可能被垃圾回收器回收,虛參考主要用來跟蹤物件被垃圾回收器回收的活動,虛參考必須和參考佇列(ReferenceQueue)聯合使用,當垃圾回收器準備回收一個物件時,如果發現它還有虛參考,就會在回收物件的記憶體之前,把這個虛參考加入到與之 關聯的參考佇列queue中,
ReferenceQueue queue = new ReferenceQueue ();
//虛參考物件
PhantomReference pr = new PhantomReference (object, queue);
程式可以通過判斷參考佇列中是否已經加入了虛參考,來了解被參考的物件是否將要被垃圾回收,如果程式發現某個虛參考已經被加入到參考佇列,那么就可以在所參考的物件的記憶體被回收之前采取必要的行動,- 參考計數法判斷物件
給物件添加一個參考計數器,每當有一個地方參考它時,計數器值就加1;當參考
失效時,計數器值就減1;任何時刻計數器為0的物件就是不可能被再使用的,
主流的JVM里面沒有選用參考計數演算法來管理記憶體,其中最主要的原因是它很難解
決物件間的互回圈參考的問題,- 可達性分析演算法
十一、 網路
57.給我介紹5層網路模型
分為應用層,傳輸層,網路層,資料鏈路層和物理層
物理層:定義物理設備如何傳輸資料,簡單來說,物理層就是我們電腦的硬體,我們的網卡埠,網線,以及我們網線連出去之后要有條光纜來為我們把資料傳輸到互聯網,沒有物理,我們的軟體是沒有辦法去傳輸的,所以物理層,就是這些硬體設備相關的東西,
資料鏈路層:在通信的物理層間建立資料鏈路鏈接,兩臺機器,也要有一個軟體服務幫我們通過物理的設備去創建一個電路的鏈接,也就是說這兩邊可以傳輸資料,最基礎的就是電腦傳輸資料,
網路層:為資料在結點之間傳輸創建邏輯鏈路,比如說從我的電腦訪問百度的服務器,那么我們去尋找百度這臺服務器它所在的地址,它就是一個邏輯關系,那么這個關系是在網路層為我們去創建的,
傳輸層:基于資料鏈路層、網路層在建立起了從電腦到百度到服務器之間的這么一個鏈接之后,對于不同資料的傳輸方式是由傳輸層來實作的,比如使用http協議要傳輸一個資料,我們只需要在瀏覽器里面輸入一個url,他就會自動去發送相關的一個資料到服務器端,然后服務器端能夠決議這些資料回傳給我們的瀏覽器,然后把頁面顯示出來,那么我們輸入url這個程序,其實涉及到了一系列的資料的拼裝以及傳輸,但是我們不需要指導這些資料里面到底是怎么去分片,怎么去跟服務器創建一個鏈接的關系,因為傳輸層已經幫我們實作了,
應用層:為我們應用軟體提供了很多服務,寫網頁的時候,我們使用http協議去發送請求,我們是非常方便的,只要去new一個request請求,然后就可以去把一些資料,比如post,get的方式去發送到服務端,這是應用層在http協議上面,它幫我們實作了http協議,然后我們只需要去使用http協議相關的一些工具,就可以幫我們去傳輸一些資料,它是構建于tcp協議之上的,所以它傳輸的方式,都是要落實于tcp,ip協議上面,
58.HTTP協議和HTTPS協議區別
- HTTP 是明文傳輸協議,HTTPS 協議是由 SSL+HTTP 協議構建的可進行加密傳輸、身份認證的網路協議,比 HTTP 協議安全,
- HTTPS比HTTP更加安全,對搜索引擎更友好,利于SEO,谷歌、百度優先索引HTTPS網頁;
- HTTPS需要用到SSL證書,而HTTP不用;
- HTTPS標準埠443,HTTP標準埠80;
- HTTPS基于傳輸層,HTTP基于應用層;
- HTTPS在瀏覽器顯示綠色安全鎖,HTTP沒有顯示;
59.TCP和UDP協議作業在哪一層
傳輸層協議:TCP、UDP協議,傳輸層的協議+埠就可以標識一個應用層協議,TCP/IP協議中的埠范圍是從0~65535,我們知道,一臺擁有IP地址的主機可以提供許多服務,比如Web服務、FTP服務、SMTP服務等,這些服務完全可以通過1個IP地址來實作
網路層協議:IP協議
應用層協議:FTP、HTTP、SMTP
60.三次握手和四次揮手
TCP 和 UDP是網路協議的傳輸層上的兩種不同的協議,TCP的特點是面向連接的、可靠的位元組流服務,客戶端需要和服務器之間建立一個TCP連接,之后才能傳輸資料,資料到達之前對方就一直在等待,除非對方直接關閉連接,資料有序,先發先到,UDP是一種無連接、不可靠的資料發送協議,發送方根據對方的ip地址發送資料包,但是不保證接收發接包的質量,資料無序還容易丟包,雖然UDP協議不穩定但是在即時通訊(QQ聊天、在線視頻、網路語音電話)的場景下,可以允許偶爾的斷續,但是這種協議速度快,
TCP連接建立的前提,是通信的雙方都要知道本方和對方的發送和接收功能,都是正常的,也就是在TCP連接建立之前,有以下八個待確認項:服務端和客戶端都要知道服務端發送、服務端接收、客戶端發送、客戶端接收是正常的,
- 第一次握手:客戶端發送連接請求,服務端接收,所以服務端可以確認客戶端的發送功能,服務端的接收功能正常;
- 第二次握手:服務端收到連接請求報文段后,同意連接發送應答,客戶端接收到第二次握手報文后,客戶端能夠確認服務端發送、服務端接收,客戶端的接收功能和發送功能是正常的;但是此時服務端并不知道自己的發送功能,客戶端的接收功能是否正常,于是需要第三次握手
- 第三次握手: 客戶端收到連接同意的應答后,還要向服務端發送一個確認報文段,表示:服務端發來的連接同意應答已經成功收到,此時,服務端就可以確認自己的發送功能,客戶端的接收功能是正常的,
- 為什么要三次握手?
client發出的第一個連接請求報文段并沒有丟失,而是在某個網路結點長時間的滯留了,以致延誤到連接釋放以后的某個時間才到達server,本來這是一個早已失效的報文段,但server收到此失效的連接請求報文段后,就誤認為是client再次發出的一個新的連接請求,于是就向client發出確認報文段,同意建立連接,假設不采用“三次握手”,那么只要server發出確認,新的連接就建立了,由于現在client并沒有發出建立連接的請求,因此不會理睬server的確認,也不會向server發送資料,但server卻以為新的運輸連接已經建立,并一直等待client發來資料,這樣,server的很多資源就白白浪費掉了,
四次揮手是指終止TCP連接協議時,需要在客戶端和服務器之間發送四個包,揮手的前提是雙方中都知道對方沒有資料可以發送給對方了:
- 第一次分手:主機1(可以使客戶端,也可以是服務器端),設定SequenceNumber,向主機2發送一個FIN報文段;此時,主機1進入FIN_WAIT_1狀態;這表示主機1沒有資料要發送給主機2了;
- 第二次分手:主機2收到了主機1發送的FIN報文段,向主機1回一個ACK報文段,Acknowledgment Number為Sequence Number加1;主機1進入FIN_WAIT_2狀態;主機2告訴主機1,我“同意”你的關閉請求;
- 第三次分手:主機2向主機1發送FIN報文段,請求關閉連接,同時主機2進入LAST_ACK狀態;
- 第四次分手:主機1收到主機2發送的FIN報文段,向主機2發送ACK報文段,然后主機1進入TIME_WAIT狀態;主機2收到主機1的ACK報文段以后,就關閉連接;此時,主機1等待2MSL后依然沒有收到回復,則證明Server端已正常關閉,那好,主機1也可以關閉連接了,
- 為什么要四次分手?
TCP協議是一種面向連接的、可靠的、基于位元組流的運輸層通信協議,TCP是全雙工模式,這就意味著,當主機1發出FIN報文段時,只是表示主機1已經沒有資料要發送了,主機1告訴主機2,它的資料已經全部發送完畢了;但是,這個時候主機1還是可以接受來自主機2的資料;當主機2回傳ACK報文段時,表示它已經知道主機1沒有資料發送了,但是主機2還是可以發送資料到主機1的;當主機2也發送了FIN報文段時,這個時候就表示主機2也沒有資料要發送了,就會告訴主機1,我也沒有資料要發送了,之后彼此就會愉快的中斷這次TCP連接,
十二、、設計模式
61.請說說單例模式 & 你專案中常用的單例模式
顧名思義就是只有一個實體,并且她自己負責創建自己的物件,這個類提供了一種訪問其唯一的物件的方式,可以直接訪問,不需要實體化該類的物件,核心代碼:構造方法私有化,private,
五種寫法
- 懶漢式:顧名思義就是實體在用到的時候才去創建,“比較懶”,用的時候才去檢查有沒有實體,如果有則回傳,沒有則新建,有執行緒安全和執行緒不安全兩種寫法,區別就是synchronized關鍵字,
- 餓漢式: 從名字上也很好理解,就是“比較勤”,實體在初始化的時候就已經建好了,不管你有沒有用到,都先建好了再說,好處是沒有執行緒安全的問題,壞處是浪費記憶體空間,
- 雙檢鎖,又叫雙重校驗鎖,綜合了懶漢式和餓漢式兩者的優缺點整合而成,特點是在synchronized關鍵字內外都加了一層 if 條件判斷,這樣既保證了執行緒安全,又比直接上鎖提高了執行效率,還節省了記憶體空間,
- 靜態內部類:靜態內部類的方式效果類似雙檢鎖,但實作更簡單,但這種方式只適用于靜態域的情況,雙檢鎖方式可在實體域需要延遲初始化時使用,
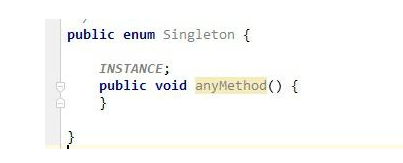
- 列舉的方式是比較少見的一種實作方式,但是看上面的代碼實作,卻更簡潔清晰,并且她還自動支持序列化機制,絕對防止多次實體化,
62.了解過的設計模式
創建型模式
對類的實體化程序進行了抽象,能夠將軟體模塊中物件的創建和物件的使用分離,為了使軟體的結構更加清晰,外界對于這些物件只需要知道它們共同的介面,而不清楚其具體的實作細節,使整個系統的設計更加符合單一職責原則,
- 簡單工廠模式(Simple Factory)
- 工廠方法模式(Factory Method)
- 抽象工廠模式(Abstract Factory)
- 建造者模式(Builder)
- 原型模式(Prototype)
- 單例模式(Singleton)
結構型模式
描述如何將類或者對 象結合在一起形成更大的結構,就像搭積木,可以通過 簡單積木的組合形成復雜的、功能更為強大的結構,
- 配接器模式(Adapter)
- 橋接模式(Bridge)
- 組合模式(Composite)
- 裝飾模式(Decorator)
- 外觀模式(Facade)
- 享元模式(Flyweight)
- 代理模式(Proxy)
行為型模式
是對在不同的物件之間劃分責任和演算法的抽象化,行為型模式不僅僅關注類和物件的結構,而且重點關注它們之間的相互作用,通過行為型模式,可以更加清晰地劃分類與物件的職責,并研究系統在運行時實體物件 之間的互動,在系統運行時,物件并不是孤立的,它們可以通過相互通信與協作完成某些復雜功能,一個物件在運行時也將影響到其他物件的運行,
- 職責鏈模式(Chain of Responsibility)
- 命令模式(Command)
- 解釋器模式(Interpreter)
- 迭代器模式(Iterator)
- 中介者模式(Mediator)
- 備忘錄模式(Memento)
- 觀察者模式(Observer)
- 狀態模式(State)
- 策略模式(Strategy)
- 模板方法模式(Template Method)
- 訪問者模式(Visitor)
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/374828.html
標籤:其他