如果之前有人問過這個問題,我深表歉意。我正在嘗試將中值添加到grouped密度圖的峰值(下面的示例)。
library(dplyr)
library(forcats)
Catalan_elections %>%
mutate(YearFct = fct_rev(as.factor(Year))) %>%
ggplot(aes(y = YearFct))
geom_density_ridges(
aes(x = Percent, fill = paste(YearFct, Option)),
alpha = .8, color = "white", from = 0, to = 100
)
labs(
x = "Vote (%)",
y = "Election Year",
title = "Indy vs Unionist vote in Catalan elections",
subtitle = "Analysis unit: municipalities (n = 949)",
caption = "Marc Belzunces (@marcbeldata) | Source: Idescat"
)
scale_y_discrete(expand = c(0, 0))
scale_x_continuous(expand = c(0, 0))
scale_fill_cyclical(
breaks = c("1980 Indy", "1980 Unionist"),
labels = c(`1980 Indy` = "Indy", `1980 Unionist` = "Unionist"),
values = c("#ff0000", "#0000ff", "#ff8080", "#8080ff"),
name = "Option", guide = "legend"
)
coord_cartesian(clip = "off")
theme_ridges(grid = FALSE)
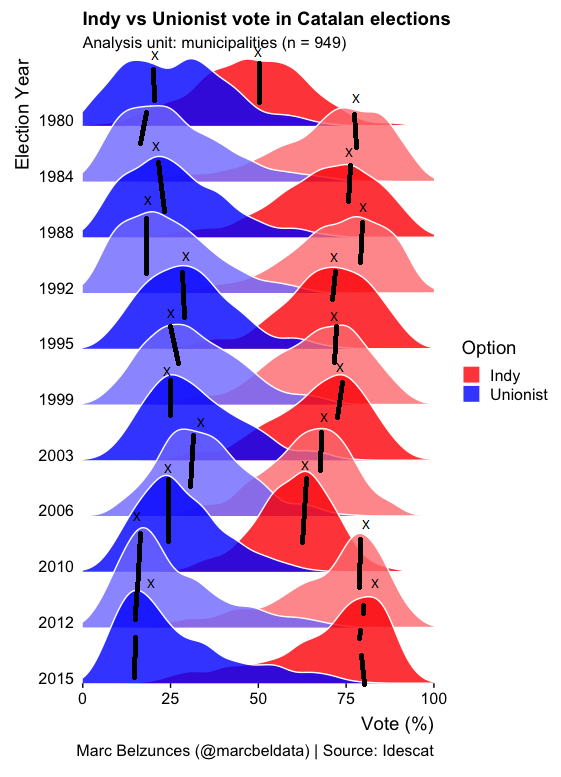
uj5u.com熱心網友回復:
編輯:
感謝您更新您的問題;我誤解并認為您想突出顯示中位數(直截了當),但聽起來您實際上想要峰值(更復雜)。我還認為這是您的代碼,而不是來自https://cran.r-project.org/web/packages/ggridges/vignettes/gallery.html的示例,所以我沒有意識到 Catalan_elections 資料集是公開可用的(例如來自 ggjoy 包)。
這是一個更相關的解決方案:
library(tidyverse)
library(palmerpenguins)
library(ggridges)
#install.packages("ggjoy")
library(ggjoy)
Catalan_elections_with_max_density <- Catalan_elections %>%
group_by(Year, Option) %>%
na.omit() %>%
mutate(max_density = max(density(Percent, na.rm = TRUE)$y),
which_max_density = which.max(density(Percent, na.rm = TRUE)$y)) %>%
mutate(which_max_x_intercept = density(Percent, na.rm = TRUE)$x[which_max_density])
Catalan_elections_with_max_density %>%
mutate(YearFct = fct_rev(as.factor(Year))) %>%
ggplot(aes(y = YearFct))
geom_density_ridges(
aes(x = Percent, fill = paste(YearFct, Option)),
alpha = .8, color = "white", from = 0, to = 100,
)
geom_segment(aes(x = which_max_x_intercept,
xend = which_max_x_intercept,
y = as.numeric(YearFct),
yend = as.numeric(YearFct) max_density * 48),
color = "white", size = 0.75, alpha = 0.1)
labs(
x = "Vote (%)",
y = "Election Year",
title = "Indy vs Unionist vote in Catalan elections",
subtitle = "Analysis unit: municipalities (n = 949)",
caption = "Marc Belzunces (@marcbeldata) | Source: Idescat"
)
scale_y_discrete(expand = c(0, 0))
scale_x_continuous(expand = c(0, 0))
scale_fill_cyclical(
breaks = c("1980 Indy", "1980 Unionist"),
labels = c(`1980 Indy` = "Indy", `1980 Unionist` = "Unionist"),
values = c("#ff0000", "#0000ff", "#ff8080", "#8080ff"),
name = "Option", guide = "legend"
)
coord_cartesian(clip = "off")
theme_ridges(grid = FALSE)
#> Picking joint bandwidth of 3.16
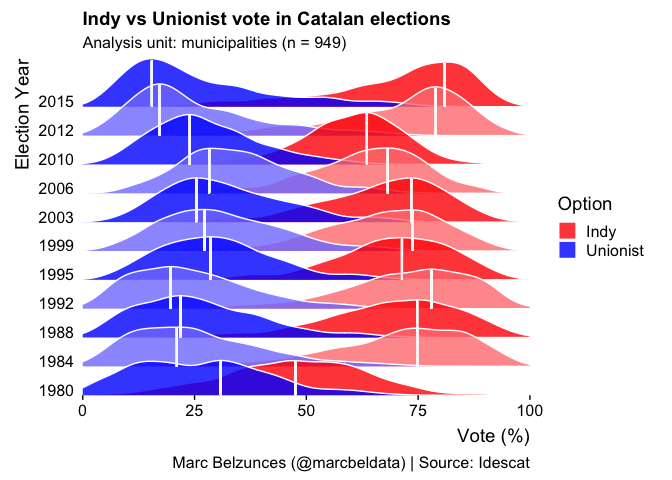
由reprex 包(v2.0.1)于 2021 年 12 月 14 日創建
注意。我不太明白 geom_density_ridges() 中的縮放是如何作業的,所以我使用“max_density * a constant”來使其大致正確。根據您的用例,您需要調整常數或計算峰值密度與繪圖的 y 坐標之間的關系。
原答案:
我沒有你的資料集“Catalan_elections”,所以這里有一個使用palmerpenguins 資料集的例子:
library(tidyverse)
library(palmerpenguins)
library(ggridges)
penguins %>%
na.omit() %>%
mutate(YearFct = fct_rev(as.factor(year))) %>%
ggplot(aes(x = bill_length_mm, y = YearFct, fill = YearFct))
geom_density_ridges(
alpha = .8, color = "white", from = 0, to = 100,
quantile_lines = TRUE, quantiles = 2
)
labs(
x = "Vote (%)",
y = "Election Year",
title = "Indy vs Unionist vote in Catalan elections",
subtitle = "Analysis unit: municipalities (n = 949)",
caption = "Marc Belzunces (@marcbeldata) | Source: Idescat"
)
scale_y_discrete(expand = c(0, 0))
scale_x_continuous(expand = c(0, 0))
scale_fill_cyclical(
breaks = c("1980 Indy", "1980 Unionist"),
labels = c(`1980 Indy` = "Indy", `1980 Unionist` = "Unionist"),
values = c("#ff0000", "#0000ff", "#ff8080", "#8080ff"),
name = "Option", guide = "legend"
)
coord_cartesian(clip = "off")
theme_ridges(grid = FALSE)
#> Picking joint bandwidth of 1.92
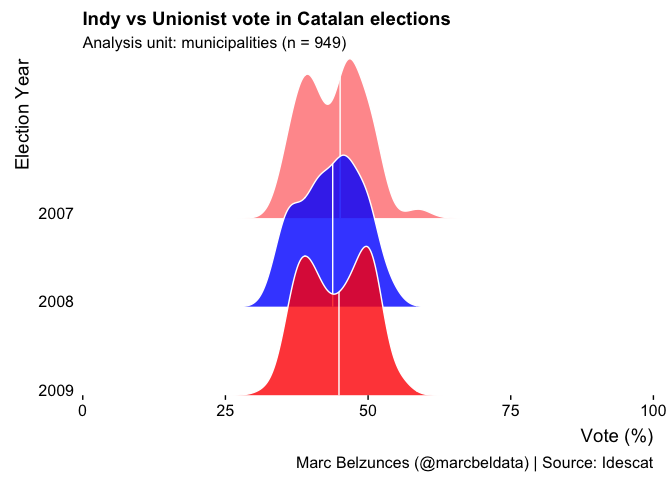
由reprex 包(v2.0.1)于 2021 年 12 月 13 日創建
轉載請註明出處,本文鏈接:https://www.uj5u.com/yidong/384684.html